面向多元组关系-集值数据的脱敏方法
2022-02-15顾兆军刘春波钟安鸣
顾兆军,蔡 畅,+,刘春波,钟安鸣
(1.中国民航大学 信息安全测评中心,天津 300300; 2.中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
保证待发布数据安全的前提下,尽可能提高数据的可用性是当前数据脱敏研究的重点。匿名化技术是发布数据常用的脱敏技术[1-3]。基础匿名模型有K-匿名[4,5]、L-多样性[6]和T-接近[7]。在此基础上,衍生出不少相关模型,例如约束等价类中的敏感值的出现频率的(α,k)-匿名模型[8],和对个数进行约束的(K,L)-多样性匿名模型[9]等。
为满足匿名模型要求,学者们提出了很多匿名算法。传统的匿名算法仅考虑单元组数据的匿名,如基于局部泛化的Partition[10]、贪心匿名算法[11]等,但现实中的数据集大多是多元组数据,应用此类方法,由于准标识符泛化不统一,会导致信息泄露以及信息缺损。且很多匿名算法仅针对集值数据匿名,如基于格雷码的局部泛化算法[12],或仅对关系数据匿名,如基于有损分解的匿名算法[13]、基于聚类的LAC[14]等,无法直接应用到关系-集值数据中。关于关系-集值数据匿名,文献[15]对其进行了研究,但对等价类约束过于严格,导致信息损失较高,脱敏后数据不具有可用性。对此,Gong等[16]提出了1M-Generalization算法,融合两种基础匿名方法,对关系数据采用多维泛化Mondrain,泛化粒度缩小,使得脱敏后数据具有可用性,但随数据维度增加,导致信息缺损增加且算法效率较低。因此,本文基于(K,L)-多样性模型,提出了一种适用于多元组关系-集值数据的脱敏方法PAHI。将多元组数据转换成单元组数据,根据模型约束,按顺序来实现关系-集值数据的匿名。保证脱敏后数据的安全性,同时降低信息损失和时间开销。
1 相关概念
1.1 数据分类
一般根据数据属性将待发布的数据分为4类,标识符属性、准标识符属性、敏感属性和其它属性[1]。
(1)标识符属性(EID)[1]:一般指能够唯一确定一个用户的属性,例如个人的身份证号,航空公司的常客卡号等属性。
(2)准标识符属性(QID)[1]:通常指一组属性,可以通过结合外部表来唯一识别用户的属性集合。例如{性别,年龄,邮编},{年龄,客户标志,邮编}等属性集合。
(3)敏感属性(SA)[1]:通常指包含个人隐私信息的一类属性,例如婚姻状况、疾病状况、航班号等属性。
(4)其它属性(NSA)[1]:不需要脱敏的属性。
一般情况下,脱敏待发布的数据,需要删除标识符属性,并对准标识符和敏感属性进行脱敏处理。
根据属性值的类型,参考文献[15],本文将数据分为关系数据和集值数据。一般情况下,关系数据是指包含关系型属性的一类数据,其中,关系型属性是指可以构成数据集中的准标识符的属性。集值数据是指包含可以取多个值的属性的一类数据,属性可以举例描述,例如疾病情况属性,取值集合{心脏病,糖尿病,癌症}。通常情况下,很多敏感数据都是集值数据。在需要发布的数据集中,大部分的数据集都是关系-集值数据集。本文中,为了简化描述,将关系数据作为准标识符,集值数据作为敏感属性。同时,参考文献[16],假设数据集中只有一个敏感属性。
定义1 多元组数据(multiple tuples data):在一个数据集中,一条记录是一个元组,将待发布的数据集中同一个用户含多条记录的数据集称为多元组数据集,记为DM。
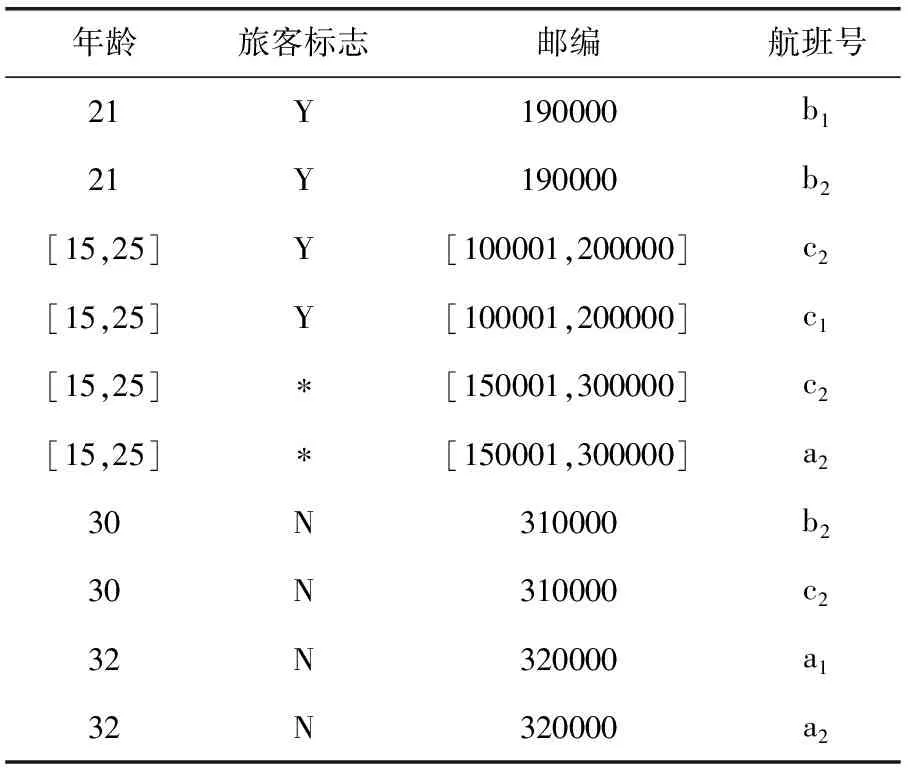
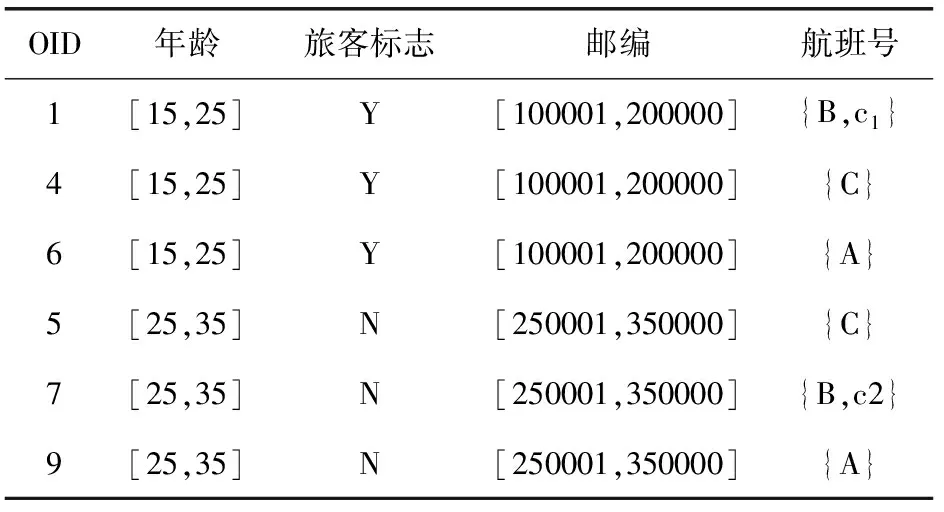
DM={QI1,QI2,…,QIm,S}, 其中, {QI1,QI2,…,QIm} 为准标识符 (m≥2),S为敏感属性, |DM|=n, 表示数据集中记录的总数。具体样例见表1,表1中给出了一个民航旅客多元组关系-集值数据集,航班号用编码代替,其中,属性姓名为标识符属性,属性年龄、旅客标志与邮编为准标识符属性,属性航班号为敏感属性。在数据集中,Sam拥有3条航班记录,Amyli拥有两条航班记录。
为了实现对多元组关系-集值数据的脱敏,防止信息泄露,本文采取二次数据划分策略,分步实行两种分组方法。根据关系数据和集值数据,将数据分为等价类和集值指纹桶。
定义2 等价类(Equivalence Class)[4]:对于多元组数据集DM,等价类是指在准标识符 {QI1,QI2,…,QIm} 上取值相同的记录的集合,记为EC。
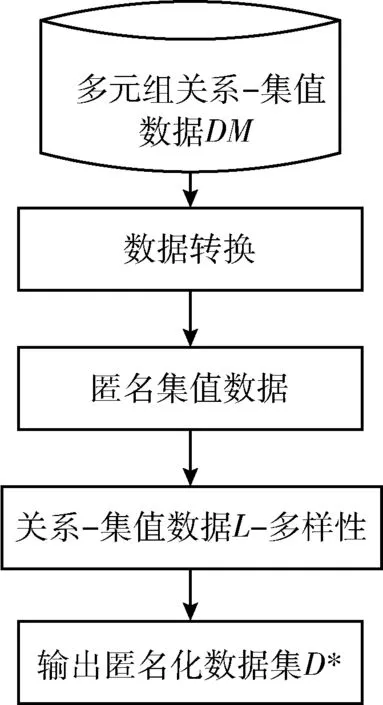
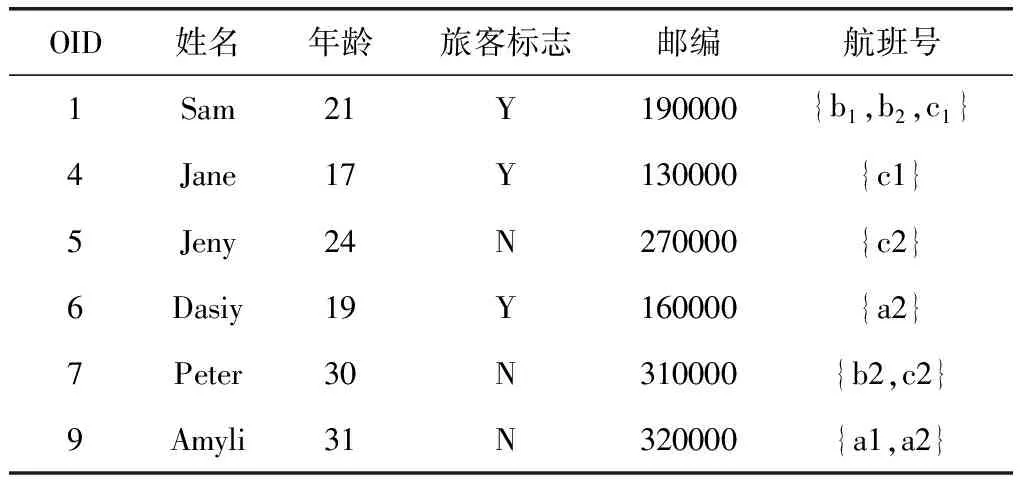
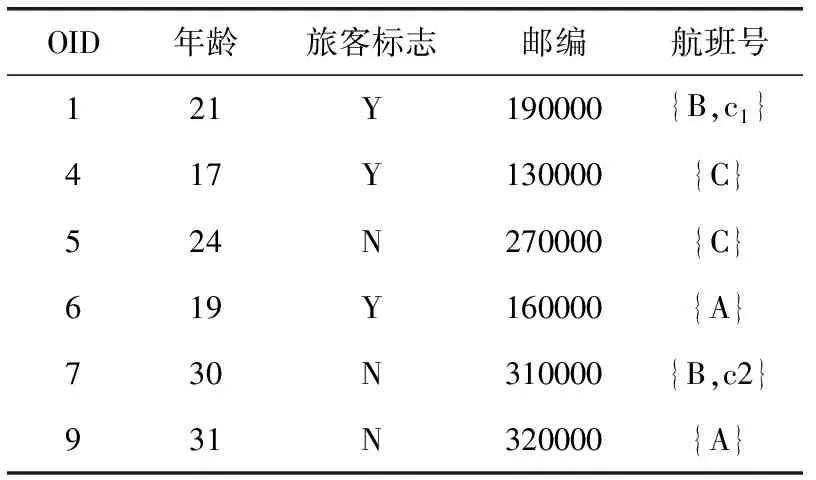
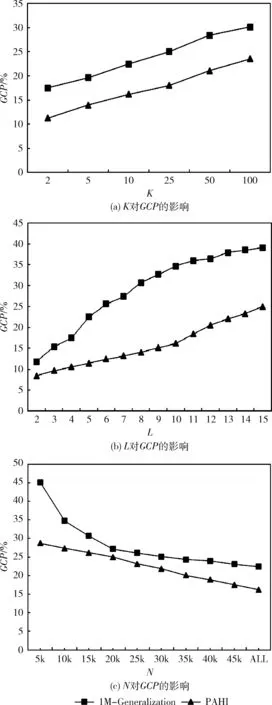
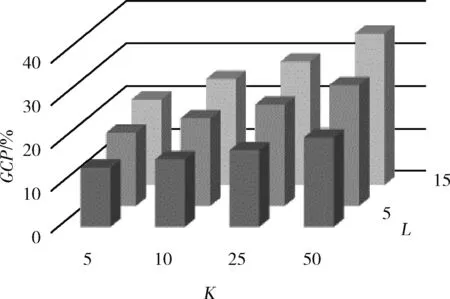
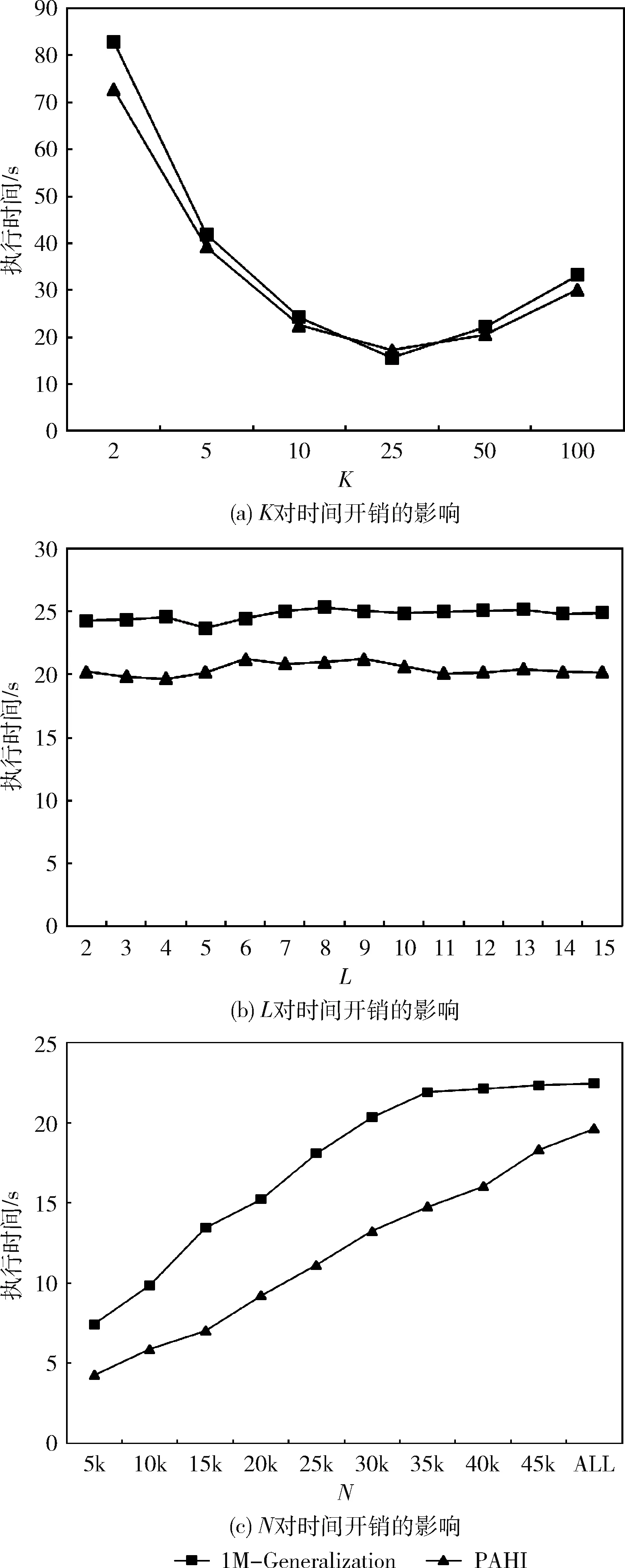
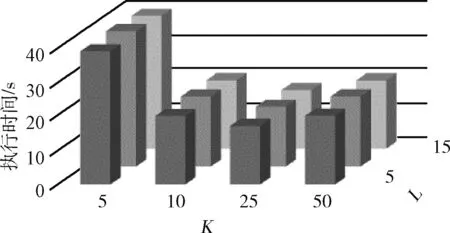
EC1∪EC2∪…∪ECt=DM,ECi∩ECj=∅, 其中t为DM中等价类的个数, 0 定义3 集值指纹(Set-valued fingerprint):对于多元组数据集DM,同一个用户具有多条记录,同一个用户的所有敏感属性值构成的集合称为集值指纹,记为SV。例如对于民航旅客数据集,A旅客的集值指纹为{航班1,航班2,航班3}。 定义4 集值指纹桶(SV_Bucket):对于多元组数据集DM,集值指纹取值相同的记录构成的集合称为集值指纹桶,记为SV_Bucket。 SV_Bucket1∪SV_Bucket2∪…∪SV_Bucketp=DM,SV_Bucketi∩SV_Bucketj=∅, 其中p为DM中集值指纹桶的个数, 0 匿名模型对脱敏后的数据质量具有重要的意义。本节将介绍K-匿名模型[4]、L-多样性模型[6]以及(K,L)-多样性模型[9]。 定义5K-匿名[4]:设数据集D*为多元组数据集DM脱敏后的匿名数据集,EC是D*中的任意一个等价类,若是EC中有不少于K条记录,则称等价类EC是满足K-匿名的,若数据集D*中所有的等价类都满足K-匿名,则称数据集D*是满足K-匿名。 表2是表1原始民航旅客多元组关系-集值数据集满足2-匿名的发布表。采用传统的K-匿名模型脱敏后的数据,可以防止身份信息的泄露。但是由于没有对敏感属性值进行处理,脱敏后的数据无法抵抗同质攻击和背景知识攻击[3]。L-多样性模型对K-匿名模型的缺点进行了改进。 表2 民航旅客多元组关系-集值数据集2-匿名 定义6L-多样性[6]:设数据集D*为多元组数据集DM脱敏后的匿名数据集,EC是D*中的任意一个等价类,若EC中不同集值指纹的个数不少于L(L≥2),则称等价类EC是满足L-多样性,若数据集D*中所有的等价类均满足L-多样性,则称数据集D*是满足L-多样性的。 L-多样性模型通过对等价类中集值指纹个数的约束,使得脱敏后的数据可以抵御同质攻击。但是L-多样性模型没有约束记录的数目,导致脱敏后数据可能遭受偏斜性攻击和相似性攻击,数据的安全性无法保证。 定义7 (K,L)-多样性[9]:设数据集D*为多元组数据集DM脱敏后的匿名数据集,SV_Bucket是D*中任意一个集值指纹桶,EC是D*中的任意一个等价类,若满足SV_Bucket中记录的条数不少于K,且EC中至少有L(L≥2)个不同的集值指纹,则称数据集D*是满足(K,L)-多样性的。 匿名算法的基础是对数据的划分,现有很多算法对数据执行一次划分。对于多元组关系集值数据,一次划分可能无法满足数据的安全需求。基于(K,L)-多样性模型的约束,在多元组关系-集值数据脱敏方法PAHI中,采取二次数据划分策略,即让集值指纹桶和等价类并存,对关系数据和集值数据分步进行匿名。PAHI算法的主要步骤分为3步,如图1所示,先根据准标识符,对数据进行转换处理,以保证后续准标识符统一泛化;然后使用信息增益比优化partition算法实现集值数据K-匿名;最后引入敏感度值建立集值指纹桶,并采用敏感度距离优化剩余元组的处理,实现关系-集值数据的L-多样性,得到匿名化的数据集D*。 图1 PAHI算法基本步骤 现实生活中,待发布的真实数据集大多是多元组数据集。例如病人病历数据集、超市的购物数据集、民航旅客数据集等等。很多匿名模型和匿名方法对于多元组数据的处理,通常有两种方法:一是把同一用户的多条记录删除,转化成单元组数据后再进行脱敏处理,这种转化方法会造成数据集较高的信息缺损;二是直接把它当作单元组数据处理。 由于方法一删除部分数据,会导致数据集产生较高的信息损失。使用方法二处理数据,会导致信息泄露。以表2中的数据为例说明方法二的弊端,表2中的数据是对表1中的多元组数据进行了K-匿名脱敏,脱敏后的数据符合K-匿名的约束要求。但是,如果敌人从其它数据中获得了Sam的准标识符信息,通过表2,即可获得Sam的航班号指纹 {b1,b2,c1}。 并且在第二个等价类中,敌人可以通过Sam的信息,推测第二组中另外一个人的准标识符情况,比如根据Sam的年龄21岁以及年龄的匿名区间,可以推测这位旅客的年龄小于20岁。由此造成信息泄露,这主要是准标识符泛化不一致造成的。 本文中根据准标识符,对多元组数据集进行转换。对于待发布的数据,在删除标识符属性前,首先按照数据集原有的数据集的顺序对每条记录进行编号,增加编号一列,命名为OID,此列只是为了标记,不参与匿名处理;然后遍历数据集,将准标识符相同的记录的敏感属性值进行合并,合并后保留一条数据,删除其它重复数据;最后转换结束,将标识符属性数据删除,再进行后续的脱敏处理。例如,将表1中的数据通过转换,得到表3。此转换方法可以使得数据在后续的匿名处理中保证转标识符的统一泛化。 表3 转换后的数据集 多元组关系-集值数据集DM,通过本文的转换方法得到数据集DS。转换之后,集值数据部分变成了变长的集值指纹。变长的集值指纹具有高维性,文献[17]中验证,高维数据具有“维度灾难”。为了降低数据缺损,本文采用基于局部泛化的Partition算法,并对它进行改进,来实现集值数据的K-匿名。 算法采用自顶向下的顺序进行泛化。核心步骤是节点的选择阶段,Partition算法以信息增益作为扩展节点的依据,但是信息增益存在偏向于选择子节点较多的节点的问题。本文对其进行改进,使用信息增益比对这一问题进行校正。对于集值属性泛化树,信息增益的定义为扩展节点展开前后的信息损失之差,即G(a)=ILbefore-ILafter。 故本文选择使用信息增益比最大的节点作为扩展节点。改进的Partition算法的具体思想是:递归分组,直到叶子节点。每次递归中,依据信息增益比选取扩展节点。然后根据层次结构原则和扩展节点来划分数据。每次划分结束后,对不满足约束要求的分组进行调整。最终形成集值指纹桶,其中,每个桶中具有相同集值指纹的记录条数不少于K,输出匿名中间表DS*。伪代码如下所示。 算法1: 改进的Partition算法 输入: 数据集DS, 层次结构原则ATree,k 输出:DS* (1) Anonynimze(partition,k); (2) If partition无法继续下钻 (3) 将分区增加到global并返回; (4) else (5) 根据信息增益比选取下钻的节点ENode; (6) for(partition中的每条记录g)do (7) 根据ATree, 扩展节点和g, 划分数据得到Rpartitions; (8) end for (9) 调整Rpartitions, 处理少于k条记录的Rpartitions; (10) for (Rpartitions中的每个Subpartition) do (11) Anonynimze(Subpartition,k); (12) end for (13) end if 集值数据部分本来不具有泛化层次结构,需要人为设定一个层次结构ATree,即集值属性泛化树。层次结构原则不同,匿名后的结果不同,此处本文根据给定的隐私要求确定集值属性泛化树的扇区f,扇区f决定了在集值属性泛化树中多少节点从该层推广到父节点层次。数据隐私要求高,树得层次高,扇区小,数据隐私要求低,树层次低,扇区大。在表4中展示了使用改进后的partition算法将表3中的集值数据K-匿名后的效果。 表4 集值数据K-匿名 通过改进后的partition算法对集值数据的处理,得到了中间数据集DS*,满足了(K,L)-多样性的一个约束。接下来实现对等价类的约束。基于Hilb算法,引入敏感度和敏感距离,提出了改进的Hilb算法。通过敏感度和敏感距离,使得在建立分组G时敏感属性分布更合理,对数据进行更好的保护。 参考文献[18],使用逆文档频率的思想来衡量集值指纹的敏感度。逆文档频率是指在数据集中出现频率高的属性值的敏感程度,要比出现频率低的属性值的敏感度低。本文将集值指纹的敏感度定义为 SV_sensitivity(h[i])=log(N/Num(h[i])) (1) 其中,Num(h[i]) 为数据集DS*中集值指纹值为h[i]的记录的条数,N为数据集DS*中所有记录的条数。进一步,本文对不同记录之间的敏感度距离进行定义 SV_distance(Ri,Rj)=|SV_sensitivity(h[i])-SV_sensitivity(h[j])| (2) 其中,SV_sensitivity(h[i]) 和分别是记录Ri和Rj的集值指纹的敏感度。 改进后的Hilb算法的具体思想是,根据敏感属性的敏感度值,按照贪心和回退的原则建立初始分组。然后通过敏感度距离,优化剩余记录的分配,最后得到匿名表D*。伪代码如下: 算法2: 改进的Hilb算法伪代码 输入: 中间数据集DS*,l 输出: 匿名表D* (1) 计算DS*每个集值指纹的敏感度并将记录的准标识符映射到一维; (2) while(DS*中非空桶的数量>l) (3) 取出每个桶内OID最小的元组放入集合F中, 按集值指纹的敏感度进行排序,将数据集规模|DS*|赋值给计数器Num, 将l值赋给计数器count; (4) while(Num>0) (5) do (6) 初始化一个空组Gi, 将集合F中集值指纹敏感度值最小的记录放到组Gi中; (7) count++; (8) 直到满足等价类要求或者count>m (9) If没有满足等价类要求 (10) 令count=l; (11) do (12) 将集合F中最后一个记录放到组Gi中; (13) 直到满足等价类要求 (14) end if (15) Num=Num-count+1; (16) i++; (17) end whie (18) end while //分配剩余的记录 (19) for(每个桶中剩余的记录) (20) 将记录按照敏感度, 将记录分配到敏感度距离最大的组G中; (21) end for (22) 泛化组Gi PAHI方法最后一步,使用改进后的Hilb算法实现关系数据的L-多样性,输出最后结果,见表5。 表5 关系数据L-多样性 通常的匿名算法中,K和L的值都是人为指定的,在这里本文引入辨别度度量标准(discernability metric,CDM)和信息熵,根据给定的隐私泄露阈值,分别来确定K和L的阈值,提高算法的实用性,更有利于数据的保护以及数据质量的保证。 2.4.1K的阈值 根据(K,L)-多样性模型的约束条件,匿名后集值指纹桶中记录的条数不少于K,即参数K的决定着匿名后集值指纹桶的大小。K值越大,集值指纹桶越大,泛化的范围也越大,匿名后集值数据的质量越差,但是数据的安全性高。K值越小,集值指纹桶越小,需要匿名的集值数据越少,匿名后数据的可用性高,不可避免地是数据的安全性低。所以需要权衡数据的安全性和可用性,来确定K的阈值。 本文参考文献[18],引入了辨别度识别度量标准来确定K的阈值。辨别度度量标准可反映匿名后数据集中集值指纹桶的规模和分布情况。辨别度度量标准定义为 (3) 2.4.2L的阈值 根据(K,L)-多样性模型的约束条件,匿名后数据集D*中每个EC中,至少有L(L≥2)个不同的集值指纹。L值越小,等价类中集值指纹的个数越少,抵抗同质攻击和背景攻击的能力弱,但是数据的质量高。L值越大,等价类中集值指纹个数越多,数据的安全性高,但是数据缺损会增加。同样,权衡数据的安全性和可用性,来确定L的阈值。 属性的信息熵可以反映出属性值分布的不确定性。敏感属性的信息熵越大,则在同一等价类中,敏感属性值的分布越平均,数据泄露的难度越大。在数据集DS*中,集值指纹S为所有集值指纹中出现频率最高的指纹,根据文献[19]中信息熵与L的关系,计算信息熵的公式为 (4) 其中,p(Ei,S) 为在每个等价类ECi中,集值指纹S出现的频率, 其中t为DM中等价类的个数。通过推导得到 (5) 本方法对多元组数据转换处理,避免了同一准标识符匿名不一致的情况,为后续准标识符的统一泛化奠定了基础,减少了信息泄露的风险。并且采用了(K,L)-多样性模型,攻击者通过集值数据唯一识别数据集DM中任意用户的信息的概率不高于1/K,通过关系数据唯一识别数据集DM中任意用户的信息的概率不高于1/L。因此,通过在集值数据上的K-匿名约束和关系数据的L-多样性约束来保证了数据集中用户数据不被泄露,用户的隐私得到了保护。所以,本文的方法在3个基本环节上能够保证脱敏后数据的安全性。 本次实验采用了民航旅客订座数据集PNR(passengers name record),它反映了旅客的航程,航班座位占用的数量及旅客信息,共48 288条记录。在某一时间范围内,同一个旅客存在有多条订座记录的情况,所以PNR数据集为多元组关系-集值数据集。选取数据集的6个属性{年龄,性别,旅客标志,邮编,代理人代码,航班号}作为实验对象,其中年龄是有序属性,其它属性均为无序属性。实验中,选取{年龄,性别,旅客标志,邮编,代理人代码}作为关系属性,{航班号}作为集值属性。 本实验将本文所提的PAHI方法与文献[16]中所提的1M-Generalization算法从信息损失和效率两方面进行比较分析。实验编程语言为Python 2.7,在 Intel-Core i5-4590 CPU 3.30 GHz 处理器上进行,内存为8.0 G,使用64位Windows10操作系统。 通过计算阈值,设置K和L的默认值分别为10和5。实验分为4组,3组对比实验和一组PAHI方法自身测试。实验设置见表6。 表6 实验变量设置 本次实验从信息损失和执行时间两方面对算法进行对比分析。其中算法效率的评价指标采用算法执行时间。 信息损失的评价指标,即数据可用性的评价指标。采用匿名化技术来脱敏数据,会造成信息损失,信息损失越小,数据可用性越高。所以,匿名化的目标是找到满足匿名模型约束的最优转换,同时最小化信息损失,以达到保证数据可用性的目的。因此,需要一个度量标准来衡量匿名数据的信息损失。早期的信息损失度量函数有分类度量和差别度量,前者对信息损失的计算主要基于元组之间的关系,不适合应用到通用程序中;后者主要是度量等价类的基数,不适合整个数集的计算。现在,又有学者提出广义损失度量[20],归一化确定惩罚(NCP)[20]和全局确定惩罚(GCP)[21]。根据本文的算法特点,选用GCP作为信息损失度量标准,对GCP定义如下: 设数据集D*为多元组数据集DM脱敏后得到的匿名数据集,其中H是D*的一个属性,g是D*中的一条记录,g[i]是记录g对应属性H的一个值,则g[i]的信息损失为 (6) |ugi| 是g[i]泛化范围,若g[i]是数值型,则 |ugi| 对应的是一个区间长度,若g[i]是离散型,则 |ugi| 对应的是g[i]所在的泛化子树对应的叶子节点的数量。 |H| 代表属性H泛化的范围。 记录g的信息损失为 (7) d为D*所有属性的维数,wj是第j个属性对应的权重,本文按照每个属性的属性值的数量分配权重,属性值多的属性权重大。所以,D*的全局确定惩罚可以定义为 (8) 其中,N为D*中所有记录的总数。GCP取值越小表示信息损失越小,即脱敏后数据的有用性越高。 固定L=5,图2(a)中给出了随着K值变化,两种算法的GCP的变化。可以发现,随着K值的变大,1M-Generalization算法和PAHI算法的GCP均随之线性增大。这是由于对集值指纹K-匿名的时候,当K值变大,要使得更多的集值指纹保持相同的值,不可避免地造成一定的信息损失。但是PAHI算法的GCP整体低于1M-Generalization算法。因为PAHI算法在对集值指纹K-匿名的时候,对partition算法优化了选取扩展节点的规则,使得数据的缺损保持较低的水平。 图2 对比实验的信息损失度量分析 固定K=10,图2(b)中展示了两种算法对于不同的L值,GCP的相应变化。随着L值的增大,两个算法的信息损失也随着增大。这是因为,随着L值增大,相应的建立的等价类的规模也变大,匿名准标识符会带来一定的信息损失。但是PAHI算法表现得比1M-Generalization算法好。在实现关系集值数据的L-多样性时,PAHI算法根据敏感度距离对剩余元组进行分配,使其分组更加合理,信息损失相对较少。 为了测试使用两个算法脱敏后,数据的质量是否受到数据集规模的影响,实验固定K=10,L=5,N以5000条记录为单位进行变化。图2(c)中,改变数据集的规模,对算法进行测试。N为数据集的规模,随着N的增大,算法的信息损失会有所下降,这是因为,随着数据集的增大,会更加容易满足(K,L)-多样性约束,所以GCP会随之降低。并且,PAHI采用的基础算法Hilb,在信息损失方面会优于1M-Generalization的基础算法Mondrian,所以,使得PAHI算法的GCP低于1M-Generalization算法。 针对PAHI算法,测试不同的K、L值对GCP的影响。在图3中可以看出,K值和L值对GCP都有影响,并呈正相关。随着K值变大,GCP不断地变大。随着L值变大,GCP也不断地变大。 图3 PAHI中K和L对GCP的影响 从图2中我们可以看到,PAHI算法的信息损失低于1M-Generalization算法,即PAHI算法脱敏后的数据的可用性高。 接下来,将从算法执行时间方面对算法进行测试。如图4(a)所示,两个算法随着K值的增大,运行时间都会缩短。这是由于随着K值的变大,形成集值指纹桶的过程中分割次数会减少。两个算法的执行时间类似。在图4(b)中,展示了L值对两个算法运行时间的影响。随着L值的增大,两个算法的执行时间变化微弱。但是,1M-Generalization算法保持在25 s左右,PAHI算法保持在20 s左右。因为在匿名关系数据时,PAHI方法采用的比Mondrain更高效的Hilb算法。在图4(c)中,PAHI算法的运行时间随着数据集规模的增大线性增加。因为随着数据规模的增大,在集值指纹事务桶的规模和等价类的规模都会变大,所以执行时间也会相应的增加。 图4 对比实验的时间效率分析 所以,从图4中我们可以看到,PAHI算法的运行效率高于1M-Generalization算法。 针对PAHI算法,测试不同的K、L值对算法执行时间的影响。在图5中,可以看出,K值对算法执行时间有明显的影响,而L值对算法运行时间的影响微弱。 图5 PAHI中K和L同时对时间开销的影响 对于脱敏待发布的多元组关系-集值数据存在的脱敏后数据的信息缺损高以及可能产生信息泄露的问题,本文基于(K,L)-多样性模型,提出了一种适合多元组关系-集值数据的脱敏方法,来保证脱敏后数据的安全性和可用性。对比现有的方法,实验结果表明,PAHI方法降低了信息缺损,即提高了数据的可用性;在时间开销方面,PAHI方法算法执行时间较低,占有一定的优势。综上验证了基于(K,L)-多样性的多元组关系-集值数据的脱敏方法的可行性。 另外,该方法主要针对考单个敏感属性情况下,多元组关系-集值数据的脱敏问题。因此,多个敏感属性的脱敏方法将是笔者下一步研究的重点。1.2 匿名模型
2 多元组关系-集值数据的脱敏方法
2.1 数据转换
2.2 匿名集值数据
2.3 关系-集值数据L-多样性
2.4 K和L阈值的计算方法
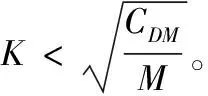
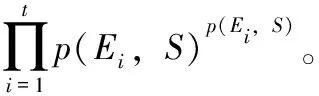
2.5 算法安全性分析
3 实验分析
3.1 实验环境及设置

3.2 实验指标
3.3 信息损失分析
3.4 效率分析
4 结束语
