基于网页源码结构理解的自适应爬虫代码生成方法
2023-07-03刘耀,刘茹,翟雨
刘 耀,刘 茹,翟 雨
(1.中国科学技术信息研究所 信息技术支持中心,北京 100038;2.北京大学 软件与微电子学院,北京 102600)
0 引言
网络信息资源中存在着大量极具参考价值的学术信息、社会信息,大数据浪潮推动了网络资源的爆发式增长,使网络资源的分类、聚合、组织与展示形态以更具多样化的方式呈现,给网络信息的自动化采集与挖掘技术带来了挑战。一方面,现存面向单一语境的网页信息提取方法适应性和泛化能力较差,难以满足高度自动化的网页信息采集需求;另一方面,网页改版事件频繁发生,导致爬虫代码中网页实体抽取模块代码失效,需要大量人力进行修复和维护。
由于实体抽取模块代码基本以XPath(XML Path language)或CSS(Cascading Style Sheets)选择器代码为主,这部分代码反映了网页源码中目标实体的位置结构、文本标识等信息,是爬虫待获取的目标实体在网页源码中的直接反映。本文提出基于网页源码结构理解的自适应爬虫代码生成方法,从网页源码变动的泛化感知能力、自适应性生成爬虫代码能力方面对通用网络爬虫的自适应性展开研究,旨在针对网页改版实现网页信息自动化采集,提高爬虫系统的自适应能力。
本文的主要工作包括3 个方面:1)通过分析爬虫业务流程和面向网页改版事件的爬虫代码报错类型,揭示网页源码的结构变动类型和爬虫代码的适应性修改间的关联;2)依据网页源码变动的结构、内容特征、爬虫代码特征和目标实体文本特征,采用树节点分类、语义相似度等方法从自动生成和相似推荐两个角度提出基于网页源码结构变动程度的爬虫代码生成方案;3)提出用于表征网页源码变动的、编码器-解码器(Encoder-Decoder,ED)与网络表示学习相结合的嵌入表示方法,有效地提高了代码生成模型的准确率和对网页源码变动感知的泛化能力。
1 相关研究
爬虫研究在广义上指基于对网络通信和网页源码理解的自动化工具研究,通过一定的策略沿着由网页链接节点构成的拓扑网络中的信息采集工具。狭义上指面向单个网页的网页信息抽取技术。
爬虫软件的自适应性研究方面,一些以自适应为标题的研究[1-4]并未从自适应性系统的角度切入,仍停留在提出实现爬虫某一环节的自动实现方法研究阶段,如网页信息自动抽取、网页自动下载等。爬虫技术相关研究中,针对网页变动的爬虫研究较少。Cohen 等[5]提出针对网页变动从子树匹配的角度提出XPath 生成方法;Choudhary 等[6]从Web 应用自动化测试的角度对网页源码的变动进行研究,将变动前后的网页源码进行关联研究。目前较为主流且工程性的网页信息自动抽取方法仍多以XPath 路径表达式模板为主,因此针对XPath的自动生成研究也较多,如Cohen 等[5]提出DOM(Document Object Mode)树子树匹配的方法自动化地生成XPath 代码;Jundt等[7]提出基于规则生成XPath 后与检索词之间关联程度的排序机制;吴共庆等[8]同样对XPath 进行研究,提出了区分噪声的网页正文提取方法。基于机器学习的网页信息自动抽取方面,在利用机器学习或深度学习的爬虫技术研究中,有些学者利用了网页超文本标记语言(Hyper Text Markup Language,HTML)源码的强结构性特征,利用深度学习中的图论对网页源码进行表示学习,如Gogar等[9]提出基于卷积神经网络(Convolutional Neural Network,CNN)的DCNN(Deep CNN)图像分类器,结合机器视觉的方法进行网页信息抽取;Tan 等[10]提出将网页中的链接构建成网络,提取钓鱼网页的超链接文本特征,从而建立网络钓鱼检测的随机森林分类器,并通过对比支持向量机、朴素贝叶斯等分类器,验证了随机森林算法在图模型分类任务中效果相对最好。
代码表示学习大多采用word2vec(word to vector)、doc2vec(document to vector)或基于长短期记忆(Long Short-Term Memory,LSTM)的序列网络模型,如code2seq(code to sequence)方法[11]主要通过LSTM 网络对代码文本进行表示,对代码片段进行序列化向量表示。Li 等[12]提出的word2API(word to API)则通过词嵌入技术对自然语言中的词组与程序语言中的应用程序编程接口(Application Programming Interface,API)进行联合建模,以解决跨语言匹配过程中出现的词不匹配问题。但这些代码的语义表示方法通常只利用代码的浅层文本语义特征,未能结合代码本身的强结构性特征。文献[13-14]在网络表示学习方法上提出不同的改进机制,其中PGE(Property Graph Embedding)模型使用节点聚类以分配偏差区分节点的邻居,并利用基于邻居的有偏采样机制融合更多的属性信息,相较于DeepWalk 的基线模型提升了10 个百分点,比图卷积网络(Graph Convolutional Network,GCN)提升了3 个百分点。文献[15]提出对图模型之间的映射关系建模的Graph-to-Graph 算法。
网络表示学习的基本原理如图1,不同灰度用于区分不同节点,首先按需生成随机游走,将网络中的节点当作句子的词,节点的连接信息当作句子在模型中进行训练,最后获得每个节点地位稠密的向量表示。本文认为可通过构建代码的图模型,采用图神经网络研究中的网络表示学习模型对网页的HTML源码及爬虫的代码及XPath等结构表达式进行表示学习。
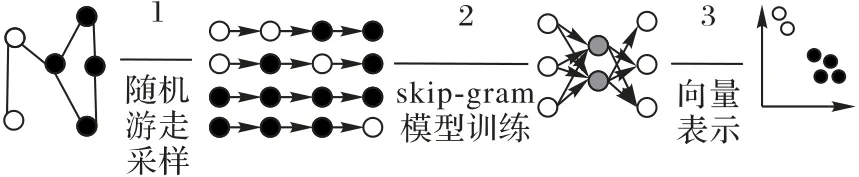
图1 网络表示学习原理Fig.1 Principle of network representation learning
本文结合自适应软件理论思想[16-17],提出了自适应爬虫可借鉴自适应软件的控制理论。一方面,通过建立深度结构化的源码知识库和代码决策库,将HTML 网页源码和爬虫代码各自表示为融合标签和语义结构信息的图嵌入表示;另一方面,针对网页源码的结构性变动特征进行表示学习,采用深度学习技术建立从HTML 源码的变动到爬虫代码间的映射生成模型,从而实现具备自适应感知、自适应代码生成更新及激活能力的自适应爬虫系统。并且连通自适应系统的各个环节,形成完整的“感知-决策-执行-评价”业务闭环,以有效解决真实的场景问题。
2 基于源码变动的爬虫生成模型
自适应代码生成之前需要经过网页源码(下文简称源码)解析及其变动感知过程,而对源码变动的感知建立在对源码结构及其语义特征深度理解的基础上,本章以HTML DOM 树和Java 抽象语法树为指导,通过源代码结构化解析方法实现网络资源获取过程中网站样式改版问题必需的资源深度解析任务。为了完成对资源的深层语义加工,为后续的源代码映射建模提供数据基础,首先需要在理解源码的基础上进行元素节点分类,其次需要完成结构相似度计算。待分类的对象是源码中的一个元素标签及其属性和文本,通常属于篇幅较小的短文本分类问题。考虑图表示学习算法可以对构建好的代码DOM 树进行向量训练,利用图神经网络中的节点分类算法更适合本文的研究任务。本文采用XGBoost(Extreme Gradient Boosting)梯度提升树[18]的改进算法。
2.1 源码变动特征研究
网页改版前后HTML 源码的变动特征与改版前的爬虫代码特征是修复停滞的爬虫业务流程、生成新爬虫代码的重要依据。本文从源码结构性变动程度、布局类型变动和局部节点变动(横向、纵向变动)这3 个层面对源码变动进行度量,将网页源码的变化特征结合其对应代码特征,将源码变化类型分为两种:1)父级元素不变化,目标元素在父级元素范围内的变化;2)父级元素发生改变的大规模源码变化。
如表1 所示,源码结构性变动以出错的目标实体为具体对象,变动程度分为结构性变动和非结构性变动。结构性变动又代表布局结构类型变动,意味着网页改版事件不仅导致某几处实体发生局部的横向或纵向移动或属性内容变化,而且整篇源码的结构和内容均发生多处改变,最直接的影响是原本的XPath 代码所对应的父节点与子节点均在新源码中找不到对应。区分方法以源码的结构性差异为特征,采用特征融合方法训练结构差异阈值,作为网页源码变动类型的判断依据。本文涉及的网页布局结构类型是基于对HTML 源码结构理解、目标实体在源码中分布的次序信息等先验知识的总结与归纳,对修剪后的网页源码DOM 树进行分类,从而得到布局结构的源码特征。
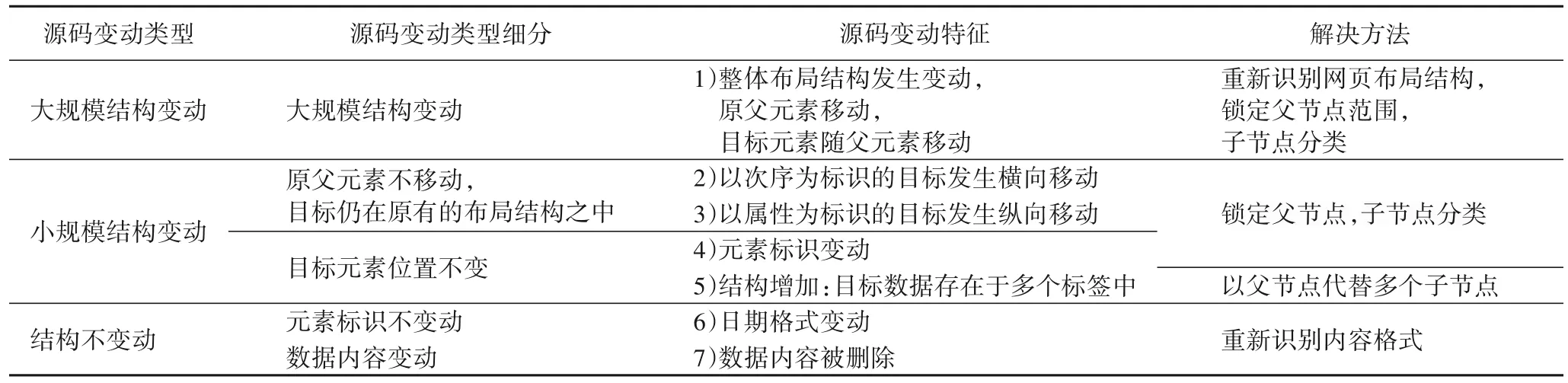
表1 源码的7种变动类型Tab.1 Seven change types of source code
2.2 基于源码变动的代码生成模型
对于爬虫代码的生成方式,实体抽取、实体解析代码分别采用不同的方法生成。实体抽取代码一方面依据源码的变动特征,可通过计算发生相似变动的源码集合推荐这些源码所对应的变动类型,进而确定源码变动范围;另一方面,可通过分类算法对源码中的节点进行分类预测,结合源码变动特征确定待分类的节点集合范围,从而得到分类为目标实体标签的元素对应XPath,最终经排序学习得到最准确的实体抽取代码。解析代码与实体抽取代码类似,可依据网页改版特征推荐最相似的变动类型所对应的代码变动类型,只不过需要广泛地从网络资源中获取相关代码,作为排序与推荐计算的数据基础。
虽然基于源码结构理解与源码变动类型判断的爬虫代码生成方法可以一定程度地提高代码生成与推荐的准确性(见3.3 节实验部分),但是这种多种传统自然语言处理手段叠加的方法在自适应感知与决策任务上仍存在一定的局限性,表现为缺乏灵活表征源码变动的能力,以及代码生成模型的有限生成能力,无法面向未知的源码变动情况自适应地生成爬虫代码。因此,本节在前文基础上提出一种泛化的、自适应的源码变动感知及爬虫代码自适应生成模型。
如图2 所示,首先以通用的、泛化的源码变动表示方法代替源码变动类型判定方法;其次基于深度学习模型中的端到端模型,将“变动前源码-变动后源码”的变动内容、变动前爬虫代码作为代码生成模型的嵌入层,以变动后代码为输出层,构建源码变动-代码的映射模型。

图2 源码变动下的自适应爬虫代码生成模型Fig.2 Adaptive Web crawler code generation model under source code changes
图2 中,W(t)代表t时刻节点;X1、X2和X3表示输入变量,分别对应模型提出的源码变动表征、源码表征和代码表征;Y1是输出变量,即要预测的代码对象。若将变化前源码记为A,变化后记为A',变化前代码记为B,变化后记为B',本文的目的即为构建{[(A-A')+(AA')+(A-B)]-B′}的关联映射模型。通过融合源码变动特征、源码自身结构语义特征、源码-代码关联映射这3 种特征,利用网络表示学习与ED 模型对源代码的双层表征,再利用Seq2Seq(Sequence to Sequence)模型以3 种特征为嵌入层,以爬虫代码为输出层,构建源代码映射的代码生成模型。
3 自适应爬虫代码生成技术及实验
爬虫代码生成任务可分解为网页改版类型判定与代码生成两部分。本章介绍源码变动程度计算以及代码生成技术,将前文提到的两种代码生成模型分别进行实验,展示传统自然语言处理方法叠加的爬虫代码生成与不区分变动类型的源代码映射代码生成模型结果。
3.1 基于源码变动的爬虫代码生成实验
表1 中3 种源码变动类型是基于源码结构性变动程度划分的。在源码结构性变动度量方面,针对大规模结构变动和局部(即小规模)结构变动,自然语言处理方法叠加的源码结构性变动程度计算与爬虫代码生成方法如下。
第一,源码变动程度计算方法。针对大规模结构变动,结合相似度计算、差异值计算的综合结构差异指标,并在源码结构表示的基础上对源码整体结构进行计算。其中,相似度计算由余弦相似度和KL 散度(Kullback-Leibler divergence)共同衡量,将二者相加作为综合结构差异指标。余弦相似度是数学空间中的两向量之间距离的衡量指标,以两个向量夹角的余弦值来衡量个体间的差异。KL散度又称相对熵,在信息论中,KL 散度可以有效地度量两个概率质量分布差异度,它在信息学、统计学和物理学等领域中得到了广泛的应用[19]。KL散度要求待对比的两个分布具有相同的样本数目,而本文待对比的对象是两个网页源码,两条数据中的节点数目即样本数目难以完全相同,因此需依据重要性对HTML 源码中的标签节点进行排序,选取相同数目的节点作为计算对象。本文采用PageRank 方法对DOM 树节点排序。首先,通过源码属性名称白名单对网页源码进行语义信息的删减、合并源码中的最小结构体,从而排除网页内容的语义差异和非HTML 语言的外部信息,构建修剪后的DOM 结构树;其次,利用树编辑距离指标衡量源码结构的变化程度,用余弦相似度和KL散度综合计算变化前后源码的相似程度;每个网站训练出一个平均阈值代表对结构变动的容忍值,当某一时刻,两个网页源码之间的树编辑距离值大于该阈值时,则认为源码发生了较大的结构差异。网页源码的非结构性变动即为源码差异小于阈值时的情况,表现为网页结构变动幅度较小,则实体抽取代码失效的原因在于元素的属性标识发生变化,在原父节点的子节点集合中重新识别目标实体。
第二,代码生成方法。XPath 代码的本质是通过一系列规则符号、针对目标实体的、对源码中目标实体的位置属性标识等特性的逻辑表达,因此网页改版事件导致的源码文本及结构变化中,与目标实体关联的部分直接映射在了XPath代码中,只要掌握了源码的变动方向,再通过局部源码的分类与判定如DOM 树节点分类方法,即可得到目标实体的位置、属性标识等一系列特征,通过这些特征又可直接转换为XPath 模板代码,重新激活爬虫流程,爬取更多的网页数据。
爬虫原始资源基本分为网页源码资源、爬虫代码资源、日志数据这3 方面资源,这些资源达成了本文所面向的自适应感知、爬虫生成以及决策激活的目标。具体包括网页HTML 源码、系统内爬虫项目代码、外部网络资源中的爬虫代码、爬虫日志数据库的资源。
爬虫完成获取网页源码的原始资源数据后,将网页源码连同它对应的获取和解析代码共同存储在Mongo 数据库(MongoDB)中,以时间戳标记源码及代码的入库时间,以便统计网页改版事件引起的网页源码变动特征。网页源码资源库充分结合了语料特点和爬虫业务目标,一方面依据HTML 的DOM 树结构特征存储树状的资源结构,另一方面按照网页源码特点存储网页布局结构字段,以及爬虫待获取的目标实体字段。代码资源库则利用抽象语法树(Abstract Syntax Tree,AST)一方面从Java 代码中提取树状结构语义,以及核心的方法名、类名、依赖等文本语义信息;另一方面则结合爬虫业务特点,设置了爬虫下载器、解析器、调度器、存储管道等字段。代码资源库的资源由爬虫采集各大网络博客网站所构成。通过人工数据清洗与信息抽取,获取网页中的代码片段及自然语言描述。爬虫日志数据库记录的是以网页为单元的每个爬虫线程在爬虫业务链条各阶段的行动轨迹,包括线程停止时的运行状态、出错类型、捕获异常、获取到的中间数据等单个爬虫线程的全部生命历程。
本节所提出的源码变动特征标引与实体抽取代码生成方法重点在于:1)通过节点分类方法识别目标实体,自动生成XPath 代码;2)通过计算源码结构变化阈值特征,锁定目标节点的变动范围,缩减待分类节点的候选集合;3)通过定位父级元素、合并最小结构体等DOM 树修剪方法,缩减待分类的节点范围,提高代码生成效率。
爬虫代码生成实验的具体步骤如下:
步骤1 数据准备。依据网页源码资源库,即标引好源码及其XPath 抽取代码对应关系的数据库,可进一步标引DOM 树中节点的分类标签。
步骤2 预训练向量准备。采用网络表示学习算法对HTML 源码进行表示学习,得到源码中各个节点对应的向量表示。
步骤3 分类模型训练。从网络表示学习得到的doc2vec 向量中提取对应节点的向量矩阵,输入XGBoost 监督学习的分类模型。
步骤4 XPath 自动生成。对网页源码中的节点进行分类,得到候选节点集合,每个节点自动生成其XPath 代码。
本文从源码库81 393 条结构化解析完毕的源码数据中,按照网页信息抽取代码的差异统计网页源码样式种类,自2019年7月爬虫平台上线以来,统计来自190个网站的526种样式,其中包含有效XPath代码的样式506种。本文依据样式类型每种样式随机选取50 条源码,从25 300 条源码数据中再依据结构化的分类体系提取各分类标签对应的源码中节点文本。经网络表示学习训练后,得到融合源码拓扑结构信息、节点的语义信息以及节点的分类信息的300 维向量表示,以此训练得到节点分类器模型。本文依据爬虫日志数据库记录的错误数据展开统计,选取2021 年连续7 d 内的每日报错数据作为实验对象,以检验本文提出的实体抽取规则代码生成方法的有效性,具体数据以及实验结果如表2所示。
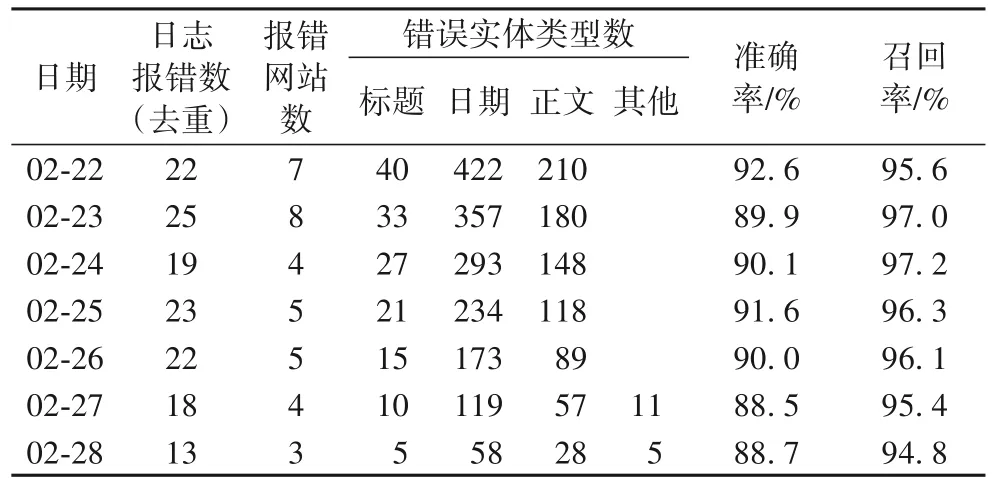
表2 爬虫日志库的数据统计Tab.2 Data statistics of Web crawler log database
从表2 可知,爬虫自适应生成实体抽取代码方法整体表现出了较强的修复能力,在标题、日期、正文这3 个目标实体的抽取代码生成上具有较好的适应性;在分类模型准确率方面,XGBoost 模型在验证集上的准确率达到88%左右,系统平台中真实预测的准确率平均在82.9%。基于布局结构判定和子节点分类得到的目标元素及其父节点在XPath 代码的转换率方面表现良好,基本维持在90%以上(如表3所示),主要出错原因在于部分元素的标识不唯一,转换的XPath 代码常常难以定位到目标元素。
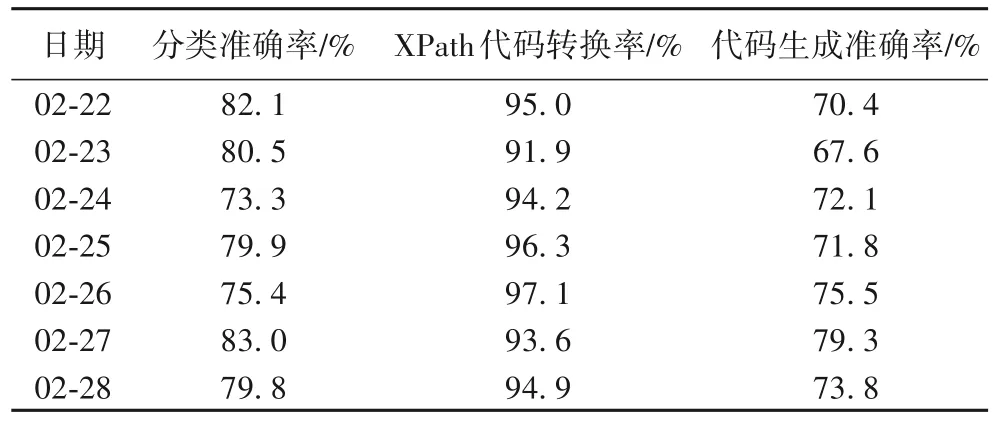
表3 自适应生成实体抽取代码方法的准确率Tab.3 Accuracy of adaptive entity extraction code generation method
通过上述正文错误类型感知及正文抽取代码生成实验,本节所构建的错误感知器在实体抽取错误感知方面,对于捕获为空的情况具有良好的感知能力,但对于捕获内容正误的感知能力比较一般;因此后续可以训练噪声分类器模型对爬虫流程中的错误类型作出进一步判断。就实体抽取代码生成能力而言,源码变动类型判定与子节点分类造成的错误累积,使得最终代码生成平均准确率在78%。源码的节点分类模型仍有提升空间。
虽然实验生成了可用的推荐代码结果,但基于多种传统自然语言处理叠加的方法一方面可能造成误差累积,降低代码生成的准确率;另一方面,传统的自然语言处理手段虽然可以建立源代码间的知识关联,但在自适应感知与决策任务上仍存在一定的局限性。因此,下文的实验中引入了自适应感知器以及多层源码特征表示手段,实现泛化爬虫代码生成过程。
3.2 源码改版自适应感知器
自适应爬虫系统的核心是基于深度感知、自动判别的服务模型,通过构建智能化工具定时监控爬虫应用的内外部环境,实现网页源码与爬虫代码两类资源的交互与协同计算,如表4。前文对实体抽取与解析代码生成的技术探讨,此节将不再区分源码变动的具体类型,而是从受到影响的目标实体、出错的爬虫节点两方面自适应感知源码变动。

表4 网页源码变动事件判定的内外部依据Tab.4 Internal and external basis for judging webpage source code change events
排除网络通信条件等硬性外部环境,本文所研究的爬虫应用的外部环境主要指网站的软件运行状态及数据内容更新情况;爬虫的内部环境则来自于对爬虫日志信息的读取和统计、爬虫运行状态的监督。外部环境的变化一方面直接体现在实体抽取模块的XPath 代码上,因为XPath 本质上是对HTML 源码信息的表达,XPath 代码是否成功解析直接反映出网页源码是否发生变动;另一方面,通过结合内外部信息,对比网站实际更新数目、爬虫捕获成功并存储在Redis(Remote dictionary server)缓存池中的链接数,以及爬虫实际解析成功存储在MongoDB 的链接数,也是判断网页源码变动与否的重要依据。网页源码变动事件判定的内外部依据见表4。
例如,网页样式变化导致信息抽取代码失效,当爬虫日志数据库中读取的数据满足条件“status=‘ERROR’ AND type≠‘DOWNLOADER’ AND message ‘content str is empty’”时,判定目标实体“正文”所对应的信息抽取代码失效,未能在源码中定位出“正文”对应的元素标签。
3.3 自适应爬虫生成实验及其系统应用
本文以源码变动前后两条源码数据即两个DOM 树结构中、同一分类标签的两个节点为一组训练数据,对变动前后的一组源码数据进行DOM 树结构化解析、网络表示学习,抽取发生变动的节点对应的向量,构成一组变动前后的节点对,作为ED 模型的输入。爬虫代码的变动特征以同样的思路得到表征代码变动的映射模型。
在ED 模型训练至第20 次时,模型损失值最低为49.905,BLEU(BiLingual Evaluation Understudy)值最高 为55.58,测试数据的准确率达到92.3%。
实验从前文针对源码变动的代码生成结果中抽取来自121个不同网站,236次变动记录,由不同版本的网页源码构成7 813 组源码变动记录数据,包含源码版本信息、变动前后源码、变动前后代码、变动实体类型等。与仅用TriDNR(Tri-party Deep Network Representation)网络表示学习作为嵌入层的实验结果对比,发现利用源代码表征、源码变动作为双层嵌入的方法的实验结果中有一定的提升,具体实验结果如表5。
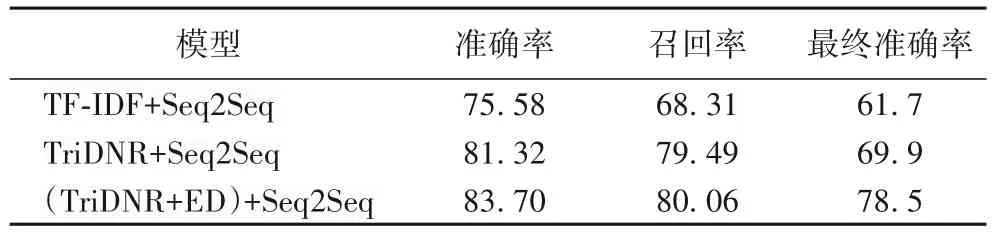
表5 自适应爬虫代码生成结果 单位:%Tab.5 Results of adaptive Web crawler code generation unit:%
使用传统Seq2Seq模型的代码生成方法中,输入为网页源码,输出为XPath选择器,由此生成的代码形如XPath表达式如“time/@text” “*/@text”等,这样的代码能够获取网页中的元素,但大部分不是爬虫待获取的目标元素。原因在于,基于TF-IDF(Term Frequency-Inverse Document Frequency)+Seq2Seq的生成模型仅利用词袋模型为特征,这样训练出的模型依赖于词袋中的语料,当新的源码输入时,难以依据新源码中的标签属性等词汇生成针对性的爬虫代码,这样的基线模型存在较大的缺陷。
结合本文的研究目标——针对网页源码变动的爬虫代码生成这一任务,可从两方面进行评价本节提出的(TriDNR+ED)+Seq2Seq 模型:源码变动的表示和代码生成的有效性。对比前文划分具体变动类型的方法发现,不区分变动类型,只对变动进行抽象表示的方法,在代码生成准确率上略有降低,但在泛化性有一定的提升。另外在代码的准确率方面,即生成的XPath 代码正确获取到爬虫的目标元素的准确程度方面,本节的模型表现较优,原因在于网络表示学习模型对网页源码的结构语义表征具有良好的效果,日期、正文等实体在源码中的布局结构、与其他元素相关联的拓扑结构信息等都得到了有效表示,因此模型在预测这些实体的能力上表现出一定的优越性。
在系统应用方面,爬虫代码生成的过程激活以网页改版事件为触发,连通自适应系统感知、决策、响应等核心决策元件,以成功获取与存储数据为终点,构成自适应系统完整闭环。由于自适应爬虫生成的结果是包含实体抽取与解析两部分核心代码在内的Java 方法体,爬虫代码更新涉及以groovy 脚本为载体的Java 类代码集成、与以数据库存储为方法的XPath 代码集成,而爬虫激活则主要指自适应生成代码完毕后的爬虫线程启动工作。基本流程如图3 所示。
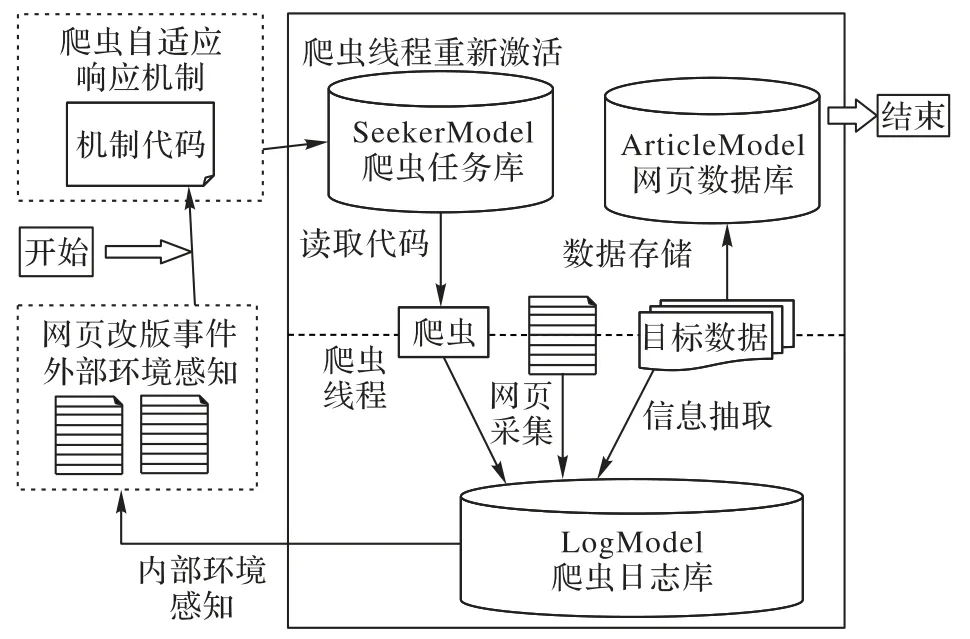
图3 爬虫代码更新与激活流程Fig.3 Flow of Web crawler code update and activation
以USCC 网站局部源码结构性变动为例,USCC 网站发生日期元素结构性变动,日期元素从<div class=”field--type--datetime”>变为<time>。对此,自适应爬虫系统正确定位了新的日期元素,并转换为XPath 代码发送给校验平台。在存储至爬虫数据库正式启动爬虫前,对自适应修改的爬虫代码进行自动测试和人机交互校对,从而有效降低人工识别错误、人工修改爬虫代码的系统运维成本,自适应修改的代码以及校对界面。
4 结语
本文在源代码资源结构及内容语义理解的基础上,探讨了针对源码变动的代码生成模型,并以源码结构变动为出发点,对问题进行建模,提出相应的代码生成或推荐模型,实现了针对错误类型的爬虫代码自动生成,并且在此基础上提出一种泛化的、自适应的源码变动感知及爬虫代码自适应生成方法,解决了爬虫技术面临的网页频繁改版导致代码失效的实际问题。但本文解决的是源码局部结构性变动,大规模源码结构变动的感知与爬虫代码生成方案则有待研究;此外,本文研究目标网站大多属于智库网站,因此所提出的特征或许存在一定的领域独特性,有待其他类型网站布局结构的补充。
