Text2DT: 面向临床诊疗文本的决策规则抽取技术*
2022-02-13李文锋王晓玲吴苑斌纪文迪汤步洲
李文锋 朱 威 王晓玲 吴苑斌 纪文迪 汤步洲
(华东师范大学 上海 200062) (哈尔滨工业大学(深圳)鹏城实验室 深圳 518055)
1 引言
作为人工智能在医学领域的重要应用,临床决策支持系统(Clinical Decision Support System,CDSS)受到研究者们的广泛关注[1]。CDSS可以辅助医务人员更加高效地做出诊疗决策,帮助医学生学习临床诊疗知识,或者为患者提供医疗建议[2]。作为CDSS的核心,诊疗决策规则指将给定的条件与医疗决策联系起来的,能够帮助医生、患者和其他利益相关者对特定的临床问题做出适当的管理、选择和决定的规则[3]。这种规则可以从临床诊疗指南与医学教科书中的文本中获取,通常被建模为诊疗决策树,见图1。然而,现有诊疗决策树构建依赖于医学专家手工标注[4],这种方法不但耗时费力,而且不能及时纳入最新研究成果。因此,探索如何从庞大且快速增长的临床诊疗文本中精确提取诊疗决策树的信息抽取技术,是构建、维护和发展大规模CDSS,实现临床诊疗智能化的基础支撑。

图1 癫痫全面强直阵挛发作患者选药的文本与其蕴含的诊疗决策树
本文提出一个全新的信息抽取任务,从临床诊疗文本中抽取诊疗决策树(Extracting Medical Decision Trees from Medical Texts,Text2DT)来探索面向临床诊疗文本的决策规则自动化抽取,其中临床诊疗文本是指来自临床诊疗指南或医学教科书中蕴含诊疗决策规则的文本,诊疗决策树则建模了文本中的诊疗决策规则。本文的主要贡献如下:一是现有的诊疗决策树缺乏统一的形式结构,导致对诊疗决策规则的理解可能产生歧义,因此对诊疗决策树进行了规范化和结构化。二是目前学界缺乏针对诊疗决策树抽取任务的基准数据集,在医学专家的帮助下构建了学界第1个从临床诊疗文本到诊疗决策树的数据集。三是设计诊疗决策树抽取方法,并与主流方法进行对比,为未来高效精确的诊疗决策树抽取算法开发奠定基础。
2 问题定义
2.1 Text2DT
Text2DT任务关注于从蕴含诊疗决策规则的临床诊疗文本中抽取出诊疗决策树,见图2。对于给定的含有n_text个字的临床诊疗文本序列X=[x1,x2,……,xn_text],Text2DT的任务目标是生成决策树中节点的前序序列T=[N1,N2,……,Nn_node]。

图2 从临床诊疗文本中抽取诊疗决策树
2.2 诊疗决策树
2.2.1 条件/决策节点 使用三元组与逻辑关系符号对诊疗决策树进行规范化和结构化,并使用二叉树结构来建模诊疗决策流程。诊疗决策树中节点可以被表示为N={C/D,L(t1,……,tn_tri)}。其中C/D表示该节点是一个条件/决策节点;t=(sub,rel,obj)是一个描述诊疗知识或临床信息的三元组,是诊疗决策关键信息的结构化表示;L表示多个三元组之间的逻辑关系(and,or,null,当三元组的个数小于等于1时逻辑关系为null);L(t1,……,tn_tri)表示条件判断或诊疗决策的内容。例如,{C,or((患者,临床特征,肌阵孪发作),(患者,临床特征,青少年肌阵孪癫痫))}表示做出条件判断:患者的临床特征是否为肌阵孪发作或青少年肌阵孪癫痫。
2.2.2 树结构 诊疗决策树表示简化的决策过程,即根据条件判断的不同结果做出下一个条件判断或决策。一旦做出决策,诊疗过程终止。因此,本文将诊疗决策树定义为由条件节点和决策节点组成的二叉树,二叉树中的非叶子节点为条件节点,叶子节点为决策节点。对于条件节点,当条件判断结果为“是”(“否”)时,则通过左(右)分支进入左(右)子节点进行下一个条件判断或决策。注意每个条件节点都有左、右子节点。如果条件判断的结果为“是”(“否”)后需要进行的后续操作未在文本中体现,则添加一个三元组为空的决策节点,表示下一步的行为未知。经以上操作后,一棵诊疗决策树可以用它的节点的前序序列唯一表示。前文图2中的诊疗决策树建模了如下诊疗决策规则,判断条件为“全身强直性发作患者的临床特征是否是丙戊酸适用”:如果条件判断的结果为“是”,患者丙戊酸适用,则进入左侧分支并做出相应的诊疗决策,使用丙戊酸作为患者的治疗药物;如果条件判断的结果为“否”,即患者丙戊酸不适用,则进入右侧分支,进行下一个条件判断,并根据条件判断的结果进入不同分支。
3 Text2DT数据集
3.1 数据集构建
Text2DT数据集的数据源为临床诊疗指南和医学教科书,是医务工作者做出临床诊疗决策的主要支撑。本文收集了2011—2021年由权威医疗机构出版的关于30个临床科室的100多部临床指南和由人民卫生出版社出版的本科临床医学教材来构建Text2DT数据集。
本文使用医学专家编写的模版与规则来定位数据源中蕴含诊疗决策规则的文本片段,并对定位到的文本片段进行人工标注。数据集的注释过程包括6名注释者和2名医学专家。本文采取了多轮标注的方法。一人标注完成后,另一人进行二次标注,两次标注不一致的地方交由医学专家进行讨论,形成最终的三标版本。对于无法在医学专家的讨论中达成一致或有歧义的语料将被丢弃。在此过程中,根据标注人员的反馈,本研究也在不断优化、更新标注规范,使其更加贴合语料自身特点。本文计算了三元组标注和决策树标注两个方面的科恩一致性系数(Cohen’s Kappa系数),以衡量两名注释者标注的一致性。其中,三元组标注的计算结果为0.83,表明三元组标注的一致性较高;诊疗决策树标注的计算结果为0.37,表明诊疗决策树的标注具有一定一致性。
3.2 数据集统计
Text2DT数据集共包含500例文本-决策树对。诊疗决策树的深度为2~4层,其中2层树有134棵,3层树有302棵,4层树有64棵。Text2DT数据集共包含1 896个有实义的节点,其中有934个条件节点,962个决策节点,476个逻辑关系为or的节点,367个逻辑关系为and的节点,1 053个逻辑关系为null的节点。Text2DT数据集中三元组关系的统计情况,见表1。Text2DT数据集中的三元组共有6种关系,其中关系“禁用药物”的三元组数仅占总三元组数量的2.57%,因此数据集存在长尾分布问题。
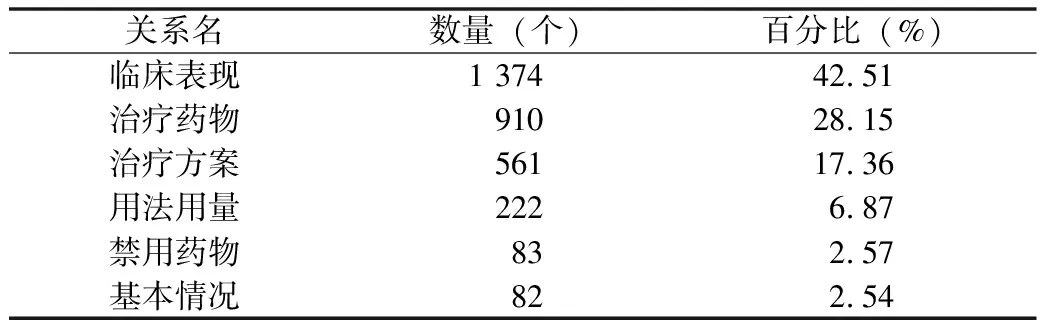
表1 Text2DT数据集三元组关系统计情况
4 模型结构
4.1 三元组抽取
三元组是诊疗决策树的主要组成部分,模型的第1部分首先进行三元组抽取,见图3。三元组抽取算法将输入的临床诊疗文本中蕴含的代表条件或决策的三元组提取出来,见公式(1)。
(1)
其中,ti=(subi,reli,obji)表示抽取的第i个三元组;TEModel是基于级联二值标注算法(CasRel)[5]、基于令牌对链接算法(TPLinker)[6]和实体关系联合抽取(UniRE)[7]等先进的三元组抽取方法。

图3 模型整体架构
4.2 双仿射模型
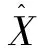
(2)
4.3 解码诊疗决策树
在获得概率张量P∈R|ntri|×|ntri|×|Y|后,模型的最后一步是将概率张量解码为诊疗决策树。本文的解码算法分为3步:节点解码、逻辑关系预测和树结构解码,见图4。
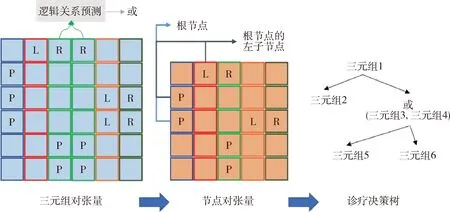
图4 诊疗决策树解码算法
4.3.1 节点解码 节点解码的关键在于处于同一节点的三元组,与其他任意三元组在诊疗决策树中的关系都是相同的,因此在概率张量P中对应的行或列应该是相似的,反之则亦然。计算张量P中两列(两行)的余弦相似度,相似度大于阈值的两行(两列)对应的三元组属于同一节点。根据实验结果取余弦相似度阈值为0.7。
4.3.2 逻辑关系预测 如果多个三元组属于同一节点,需要预测多个三元组之间的逻辑关系。将属于同一节点的三元组拼接在临床诊疗文本后,通过预训练语言模型和线性层来预测逻辑关系。
4.3.3 树结构解码 本文将三元组对的概率张量P转换为节点对的概率张量Pnode。类似于P,Pnode中的第j列第i行的单元格的标签表示其对应的节点Ni和Nj在诊疗决策树中的关系。Pnode的计算方式,见公式(3)。
(3)
其中,Pnode∈R|nnode| ×|nnode| ×|Y|,n-trii和n-trij表示节点Ni和Nj中三元组的数量。|tri|表示三元组tri在P中对应的索引。在得到Pnode后,为每个单元格分配概率最高的标签。
解码的最后阶段是将Pnode转化为诊疗决策树。如果能找到诊疗决策树的根节点,非叶子节点的左右子节点,以及叶子节点,则可以很容易地完成决策树的解码。首先寻找根节点:根节点不作为任何一个节点的子节点,只需计算Pnode中每一列的标签只为P或N的概率,选择概率最大的一列对应的节点作为根节点。接着寻找非叶子节点的左右子节点:Pnode中与非叶子节点的关系为L(R)的节点即为左(右)子节点。最后寻找叶子节点:Pnode中没有标签P的一列所对应节点即为叶子节点。
5 实验
5.1 评估指标
节点是诊疗决策树的重要组成部分,本文将节点抽取的F1分数作为一项评价指标。当抽取的节点与标注节点完全一致时认为这个节点是正确的。诊疗决策树抽取的准确率作为本文最严格的评估指标。当抽取的诊疗决策树与标注完全一致时认为这棵诊疗决策树是正确的。本文从不同的角度提出以下两项评估指标。一是决策路径的F1得分:将树从根节点到叶子节点的路径称为决策路径。一棵诊疗决策树包含多个决策路径。完整的决策路径对临床诊疗决策是有意义的,因此本文使用决策路径的F1得分作为一项评价指标。二是诊疗决策树的编辑距离:与字符串的编辑距离类似,诊疗决策树中的编辑距离是指从一棵树转换到另一棵树所需的最小树编辑操作数。
5.2 实验设置
本文的代码是用Pytorch实现的。线性层的维度设置为150,并使用GELU作为激活函数。模型优化使用Adam优化器,学习率设置为1e-5。对于超参数设置,dropout值设置为0.5,训练批次大小为8。在训练过程中,需要100个轮次来训练模型。Text2DT数据集被随机分为训练集(60%,300对)、验证集(20%,100对)和测试集(20%,100对)。
5.3 对比方法
诊疗决策树的抽取分为三元组的抽取和树结构的生成,本实验主要使用UniRE作为三元组抽取算法,着重比较树结构的生成方法。比较方法使用序列解码(Seq2Seq)[9]或树形解码器(Seq2Tree)[10]在每个时间步骤生成节点表示,并使用多层感知机来匹配节点和三元组。将PCL-MedBERT[11]、BERT-wwm-ext[12]和RoBERTa_wwm_ext[13]作为预训练语言模型。
5.4 实验结果与分析
对于三元组的抽取,UniRE算法在使用不同预训练语言模型作为编码器时的F1得分如下。PCL-MedBERT:0.917 6,BERT-wwm-ext:0.936 0,RoBERTa_wwm_ext:0.938 2。PCL-MedBERT虽然在预训练阶段引入医学知识,但由于引入的医学语料有限,其性能表现不及使用更大规模的预训练语料BERT-wwm-ext与RoBERTa_wwm_ext。由于使用了动态遮蔽策略以及对预训练任务进行了优化,RoBERTa_wwm_ext的性能表现略优于BERT-wwm-ext。因此,本文使用UniRE算法在预训练模型RoBERTa_wwm_ext下的结果作为下一步诊疗决策树生成的基础。
诊疗决策树抽取的实验结果,见表4。本文提出的方法在所有指标上明显优于传统方法,甚至于本文提出的方法使用表现较差的PCL-MedBERT获得的结果都远优于Seq2Seq与Seq2Tree使用表现较好的RoBERTa_wwm_ext获得的结果。Seq2Seq与Seq2Tree在每一时间步生成一个节点,当前节点的生成依赖于上一个时间步生成的节点,因此会由于训练和测试阶段的差异产生暴露偏差。而本文提出的方法在进行三元组在诊疗决策树中关系的预测时使用的是一个一阶段的模型,保证训练与测试一致性,避免暴露偏差的产生。对于预训练语言模型,RoBERTa_wwm_ext在总体上取得最佳的性能表现,BERT-wwm-ext与RoBERTa_wwm_ext相近,PCL-MedBERT表现最差。虽然PCL-MedBERT使用了医学文本作为预训练数据,但BERT-wwm-ext与RoBERTa_wwm_ext采用了更多的预训练数据以及更有效的预训练策略,因此取得远优于PCL-MedBERT的性能表现。

表4 主要实验结果
6 讨论
6.1 错误分析
本文抽取诊疗决策树方法的错误及其分布为:三元组抽取错误(45.5%)、节点解码错误(20.3%)、诊疗决策树结构错误(18.4%)、三元组间的逻辑关系错误(15.8%),其中,三元组抽取错误所占比例最大。本文提出的抽取方法是一个多阶段方法,作为诊疗决策树抽取的第1步,三元组抽取错误会导致错误级联,影响后续节点和诊疗决策树的生成,以及逻辑关系的判断。虽然现有的三元组抽取方法已经在Text2DT数据集上取得很好的效果,但错误级联导致三元组抽取错误占据较大比例。通过对逻辑关系预测错误的数据进行分析,本文发现部分三元组之间的逻辑关系判断需要借助外部知识,例如,如果两个三元组代表的决策是互斥的(互斥判断无法从文本中获得,需要借助医学知识和经验),则这两个三元组之间逻辑关系应为or而非and。因此引入医学背景知识能够帮助模型进行三元组间逻辑关系判断。
6.2 局限性
本文是对从临床诊疗文本中自动抽取诊疗决策树的首次探索,难免存在一些局限性。首先,节点的逻辑表达能力是有局限的。节点中三元组之间的逻辑关系仅有“和”,而在更复杂的场景中,三元组之间的逻辑关系会存在“和”的多种组合。其次,临床诊疗文本的长度是有限制的。本文关注于从一段文本中抽取诊疗决策树。事实上,完整的诊疗决策规则需要基于多个段落甚至章节进行抽取。这些局限将在未来的工作中得到完善。
7 结语
本文提出了一个全新的自然语言处理任务Text2DT,其目的是从临床诊疗文本中自动提取诊疗决策树。在医学专家的参与下,构建自然语言处理社区的第1个临床诊疗文本-诊疗决策树对的数据集。提出一个树结构生成方法,即预测三元组在决策树中的关系并利用解码算法获得最终的决策树。实验表明,本文提出的方法与同类方法相比有明显改进,为未来诊疗决策树的自动抽取与大型临床决策支持系统自动化构建奠定了基础。
