点云目标检测残差投票网络
2022-02-11杨积升
杨积升,章 云,李 东
(广东工业大学 自动化学院,广东 广州 510006)
无人车、无人机、虚拟现实等技术正在潜移默化地改变着现代人的出行以及生活方式。谷歌、百度先后推出了自动驾驶无人车Waymo,Robotaxi。大疆等公司推出的无人机产品,也可以自动感知环境,并自主飞行。高德等地图软件,将虚拟现实融合进导航,方便用户更好地使用。上述产品或应用软件无一例外,都需要使用三维空间的目标检测来实现环境的感知。然而,目前的三维目标检测算法,精度仍然无法使无人车、无人机等产品安全、稳定、可靠运行。到2016年为止,谷歌无人车共发生了25起事故[1]。因此,高精度的三维目标检测是目前迫切需要的技术。
虽然深度学习技术已经在结构规则的二维图像任务上表现出优秀的能力,甚至在人脸检测、交通车检测等领域落地,但是,这些技术无法直接用于结构无序的三维点云。
近年来,使用深度学习技术进行三维点云目标检测成了研究热点[2-4]。现有的基于深度学习的三维点云目标检测算法,一般先后执行以下的部分或者所有步骤,如图1所示。特征提取是对点云的形状、颜色、反射强度等信息进行平滑与抽象,便于后续的聚类和最终预测;聚类与分组是为了将场景中的多个目标分离,使得每个分组对应单个目标;包围框回归是对已提取的特征进行解码,映射出目标包围框的参数。例如,VoxelNet[5]借鉴了YOLO[6]的思想,先将输入点云划分进体素网格,每个网格作为一个分组,并假定每个分组最多存在一个物体中心点。接着使用VFE(Voxel Feature Encoding,体素特征编码)模块对每个分组进行特征提取。最后使用RPN(Region Proposal Network,区域提案网络)模块进行包围框预测。而F-PointNet[7]使用二维图像作为辅助,利用二维图像检测器生成检测候选框,经过投影得到点云子区域,每个子区域作为一个分组,只包含一个目标物体。于是将点云多目标检测转化成了单目标检测问题,最后使用Pointnet[8]回归出物体包围框的参数。然而在实际应用中,并不是所有场景都有对应的二维图像,所以F-PointNet具有输入形式的局限性。为了解决这个局限性,VoteNet[9]在此基础上,巧妙地使用霍夫投票方法,产生若干只包含单目标的点云子区域,消除了对二维图像的依赖,直接使用点云数据生成分组。PV-RCNN[10]结合了体素和点输入的优势,使用体素卷积网络生成候选分组,使用PointNet模块对各个分组内的点集进行特征提取以及包围框回归。随着注意力机制被大量用于二维视觉神经网络上,并展现出良好的性能,也有学者尝试将注意力机制应用在三维物体检测上,并提出了TANet[11]。此网络同时利用了通道注意力、点注意力、体素注意力机制,在自动驾驶场景的数据集中展现出优异的性能。上述的方法都通过增加各种功能模块改善网络性能,而本文创新性地通过改进网络特征学习部分的多层感知机,简单且高效地提升了点云检测网络性能。
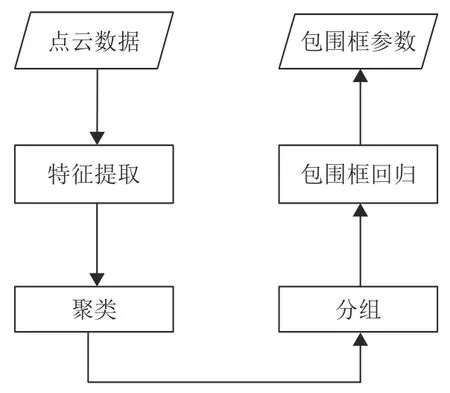
图1 三维点云目标检测技术流程图Fig.1 3D point cloud object detection technology flowchart
本文提出了一种高精度的三维点云目标检测网络ResVoteNet(Residual VoteNet),是对VoteNet[5]的改进。点云目标检测的可视化结果如图2所示。

图2 点云目标检测可视化Fig.2 Visualization of point cloud object detection
该算法以一种简单且有效的形式,将ResNet[12]设计成点云网络的多层感知机,提出残差特征提取模块以及残差上采样模块,并融合进VoteNet网络中,有效地增强了网络的表达能力,明显提高了目标检测的精度。本文的主要贡献有以下几点:
(1)提出了残差特征提取模块以及残差上采样模块,集成进VoteNet框架,形成高精度的端到端点云目标检测网络ResVoteNet。
(2)ResVoteNet在公共数据集SCANNET和SUNRGBD上,精度均明显超越当前点云目标检测的先进算法。
(3)使用消融实验分析了ResNet结构在点云卷积神经网络中的有效性。
1 VoteNet网络结构
本文的基线网络VoteNet的网络结构如图3所示。输入数据维度为N×3,3个通道代表坐标值(x,y,z)。经过特征学习模块后,将输入数据下采样到M个点,提取了尺寸为C的特征通道,并把点集相应的坐标通道进行保留。投票模块利用多层感知机对上一阶段的特征图进行学习,预测出各个点所在物体质心的坐标(xc,yc,zc),用这个方法将点云聚类到待检测物体的质心处。接着使用FPS(Farthest Point Sampling,最远点搜索法),将聚类后的点云分成K个分组。分组内的点集存在至多一个待检测目标,将多目标检测转化成了单目标检测问题。最后使用包围框回归网络,对每个分组的点云特征进行预测,得到单个目标物体的包围框参数Cout。3D NMS (3D Non-Maximum Suppression,三维非极大值抑制)作为网络的后处理,将得分低的、互相重叠的包围框过滤掉,得到最终K′个目标物体的检测结果。

图3 VoteNet网络结构Fig.3 Network architecture of VoteNet
2 ResVoteNet算法原理
本文在VoteNet算法的基础上进行改进,将在图像类卷积神经网络中表现优异的ResNet骨架融合进VoteNet中,形成更加高精度的网络ResVoteNet。具体来说,是将网络的多层感知机,构造成能处理点云数据的ResNet的形式,并分别提出残差特征提取模块以及残差上采样模块来代替原来的对应模块。本文2.3、2.4节将会详细讲解这两个模块。
2.1 点云卷积
对比起图形卷积,点云卷积有它的特殊性。二维图像与三维点云数据的表示形式不相同,图像是以位置关系为参考的规则的三维张量(W,H,C)表示,而点云是以二维矩阵(N,C)表示,具有无序性。图像卷积的卷积核尺寸一般为3、5、7等大于1的数值,这样可以在卷积的过程中增大感受野,同时提取图像的局部邻域信息。而由于点云数据表示具有无序性,无法使用卷积提取局部领域信息,只能提取单个点的信息,并通过max pool(最大值池化),average pool(平均值池化)等对称函数整合提取局部信息。因此,与二维图像卷积相比点云卷积的卷积核尺寸只能为1。
2.2 点云卷积残差块
了解完点云卷积的特点,这一节将介绍如何构造点云卷积残差块。图4(a),(b)分别是原始ResNet网络中的基础残差块和“瓶颈”残差块。“瓶颈”残差块通过卷积核尺寸的变化,增加网络的非线性以及减小计算成本。而考虑到点云卷积的卷积核尺寸只能为1,所以“瓶颈”残差块不适用于点云卷积。于是改造如图4(a)所示的基础残差块,将卷积核替换成1×1,并将输出通道大小改成相应需要的,得到如图4(c)所示的点云残差块。通过这种简单而实用的方法,便构造了适用于提取点云特征的点云卷积残差块。

图4 图像与点云残差块Fig.4 Residual block of images and point clouds
2.3 残差特征提取模块
该模块是对VoteNet的特征提取模块的改进,加入了点云残差块。该模块的作用包括:(1)通过点云残差块,学习点云的特征,从中提取出更加高阶的视觉信息;(2)下采样点云,减少计算量。
如图5所示,通过最远点搜索法(FPS),将输入的n个点,下采样到np个点。接着,利用下采样的np个点作为球心位置,r为半径,通过球查询算法,在点云特征中,对每个球内部采样出ns个点,形成大小为np×ns×m的组特征。组特征经过点云残差块,学习出新的组特征。最终使用对称函数max pool取消点云的无序性,得到模块的输出特征np×C。

图5 残差特征提取模块Fig.5 Residual feature extraction module
2.4 残差上采样模块
作为网络的特征学习部分的解码模块,残差上采样模块的作用包括:(1)恢复点的数量。经过残差特征提取模块,点的个数减少了,为了满足网络后续模块对点个数的需求,需要恢复点的个数。(2)融合高阶和低阶视觉信息。深的层学习出来的特征,更有利于分辨物体的分类信息,而浅的层学习到的特征,更有利于分辨物体的边缘等位置信息[13]。在目标检测任务中,需要兼顾物体分类信息以及位置信息,因此,有必要融合高阶和低阶的视觉信息。
如图6所示,需要将第N+1层的n1个点,上采样到n个点,并且位置与第N层的n个点一致。首先使用k近邻插值法,根据第N+1和第N层点的位置关系,将第N+1层的特征n1×C1上采样并插值,得到特征图n×C1。接着,上采样特征与第N层特征在通道这个维度进行拼接,得到大小为n×(C0+C1)的拼接特征。将该特征输入点云残差块,学习出融合了低阶与高阶视觉信息的特征,大小为n×C。

图6 残差上采样模块Fig.6 Residual up-sampling module
3 实验
首先介绍使用的数据集、评价指标、实验细节;然后将本文提出的方法与其他点云目标检测的先进算法进行比较;最后,通过消融实验证明本文提出的点云残差模块的有效性以及分析其他因素的影响。
3.1 数据集
本文使用了2个公共点云数据集—ScanNet[14]和SUN RGB-D[15]。ScanNet是一个利用RGB-D视频重建的大型室内点云数据集,它包含1 513帧标注的点云数据。SUN RGB-D也是一个大型的室内点云数据集,重建点云方法与ScanNet的类似,它包含10 335帧标注的点云数据。与基线网络VoteNet一致,ScanNet数据集被划分成包含1 201帧的训练集和包含312帧的校验集;Sun RGB-D数据集被划分成包含5 285帧的训练集和包含5 050帧的校验集。
3.2 评价指标
本文使用文献[15]提出的评价指标,评估预测的物体检测框的准确性。通过对比预测的物体检测框和真实的物体检测框,计算网络对各个分类的预测结果的准确率AP(Average Precision)及所有分类准确率AP的平均值,得到综合准确率mAP(mean Average Precision)。首先,对所有预测的检测框和实际检测框,计算它们两两之间的IoU,称为一个匹配对(pair)的IoU,然后对所有匹配对的IoU进行得分降序排列。接着,选择IoU值最大的检测框匹配对,并将这两个检测框标记为不可见。重复此过程,直到IoU低于一个阈值τ(文献[15]中τ使用0.25)。对于每个预测框和真实框匹配对,比较它们的分类标签,以便知道预测的分类正确与否。令|M|为IoU大于τ的匹配对的数量,|P|为预测框的数量,则阈值为τ的AP计算公式AP@τ如式(1)所示。表1~表3的数据,均用百分数表示,即(|M|/|P|)×100。

3.3 实验细节
本文的实验在Ubuntu16.04操作系统中部署。编程语言是Python3.6,深度学习框架为Pytorch1.4。使用GPU加速工具CUDA9.2。硬件配置主要包括以下:CPU×1,型号为Intel(R)Xeon(R)Gold 6271C CPU @2.60 GHz;GPU×1,型号为Tesla V100-SXM2 16 GB。网络一共训练180个轮次。最小化loss的优化器使用Adam。学习率初始值为0.001,随着训练进行分段常量衰减,分别在第80,120,160个轮次,衰减为原来的0.1倍。L2惩罚系数初始值为0.5,每训练20步,衰减为原来的0.5倍,直到减小到0.001,便停止衰减。所有训练方式与基线模型VoteNet保持一致。
3.4 与其他先进算法对比
本文提出的算法在数据集SCANNET和SUNRGBD上实验论证,并与其他有代表性、且性能表现领先的目标检测算法对比。DSS[16]和3D-SIS[17]的网络都融合了3D体素输入和2D图像输入,提出了基于区域候选框的双阶段目标检测网络。不同的是,DSS在输出阶段,通过全连接层进行3D体素信息和2D图像信息的通道连结;而3D-SIS将2D图像提取出的特征,映射到3D体素,进行体素形式的通道连结。相比DSS,3D-SIS在候选框生成和目标框回归阶段,都使用了3D和2D融合的信息作为输入,因此具有更好的性能表现。2D-driven[18]和F-PointNet[7]都使用2D图像检测器生成2D物体候选框并映射到三维空间,得到只包含一个物体的截锥3D候选框,并对候选框内的物体进行目标检测框回归。Cloud of Gradients[19]设计了3D HoG(3D Histogram of Oriented Gradients,三维方向梯度直方图)特征,并提出了基于移动窗口的检测器。MRCNN 2D-3D直接将Mask-RCNN[20]的实例分割结果映射到三维空间,并根据三维空间的实例分割结果获得目标检测框。GSPN[21]使用生成网络模型获取候选检测框,提出了一个框架类似Mask-RCNN,而网络骨架是Pointnet的点云检测网络。VoteNet[9]是本文参考的基线网络,先利用PointNet++[22]作为骨架产生物体中心投票点,再依据投票点的位置进行分组,每个组作为一个物体的候选位置,使用PointNet++的特征提取模块,进行目标检测框的参数回归。
从表1和表2可知,本文提出的方法ResVoteNet在数据集SUN-RGBD和SCANNET上,平均精度mAP均超越了所有当前先进方法,达到59.9%,和61.1%,比当前所有算法提高了至少2.2%和2.5%。在SUN-RGBD数据集中,70%类别的检测精度高出当前所有先进方法。图7是ResVoteNet与基线网络VoteNet检测结果的可视化。

表1 不同方法在SUN-RGBD上精度AP@0.25的对比Table 1 AP@0.25 comparison of different methods on SUN-RGBD %

表2 不同方法在SCANNET上AP@0.25的对比Table 2 AP@0.25 comparison of different methods on SCANNET %

图7 ResVoteNet与基线网络VoteNet检测结果可视化Fig.7 Visualization of the detection results of ResVoteNet and the baseline network VoteNet
3.5 消融实验
为了探索网络结构中不同配置对网络整体检测精度的影响,本文进行了消融实验,分别讨论残差特征提取模块、残差上采样模块(如2.3,2.4节所描述)、ResNet结构和卷积层数对网络检测精度的影响。首先,分别控制残差特征提取模块与残差上采样模块的引入,探索由此带来的网络检测精度的改变。接着探索整体加入ResNet结构,即同时使用残差特征提取模块和残差上采样模块对网络检测精度的影响。最后,改变网络中卷积层的数量,探索最佳的卷积层个数。其中,由于VoteNet的特征提取模块和采样模块一共有7组卷积层,共19个卷积(其中,每个特征提取模块有3个卷积,每个上采样模块有2个卷积),为了保证网络结构的对称性,本文以7为步长,对网络的卷积层数量进行增减变化。
如表3所示,残差特征提取模块与残差上采样模块,都对网络检测精度的提升有贡献。其中,残差上采样的模块对精度提升的贡献较小,在SCANNET和SUN-RGBD两个数据集中,提升的幅度都小于1%;而残差特征提取模块的贡献较大,在两个数据集中,都将检测精度提高了超过1.5%。两个模块贡献的差异,可归因于网络结构中两个模块的覆盖度,如图3所示,网络只有2个上采样模块,而有5个特征提取模块。
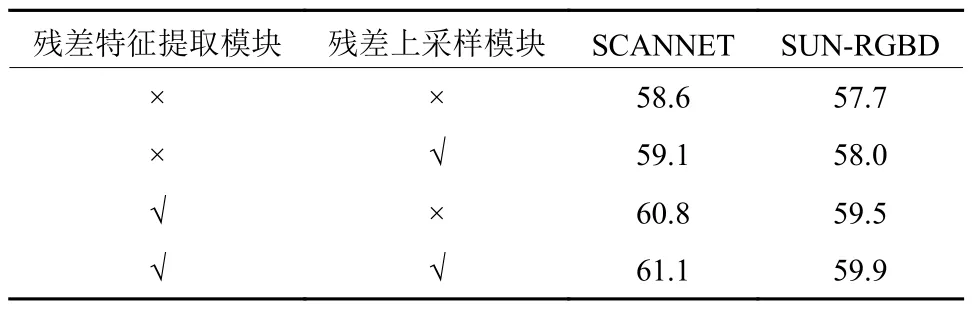
表3 残差模块实验精度mAP@0.25对比Table 3 mAP@0.25 comparison of different Residual modules %
如图8和图9所示,对本文网络增减ResNet结构和改变卷积层数配置,并在数据集SCANNET和SUN-RGBD上进行实验,记录实验结果并绘制了折线图。其中,wres表示本文提出的方法ResVoteNet,即融合了ResNet结构的VoteNet,w/o res表示无ResNet结构的网络,即基线网络VoteNet。由图8和图9可知,ResNet结构使网络具有鲁棒性,不管是在不同的数据集中,还是使用不同的卷积层个数配置,ResNet都能使网络的精度维持在较高水平,并明显超越没有ResNet结构的基线网络VoteNet。此外,19层是网络的最佳卷积层数量,不论是在ResVoteNet还是在VoteNet数据集中,增加或者减少卷积层的数量,都会使网络的检测精度有不同程度的下降。

图8 SCANNET数据集实验结果Fig.8 Experiment results for SCANNET

图9 SUN-RGBD数据集实验结果Fig.9 Experiment results for SUN-RGBD
4 结论
本文通过改进算法VoteNet,提出了一种融合残差网络的高精度点云目标检测方法ResVoteNet。该方法设计了适用于点云数据的残差块,基于点云残差块构造出检测网络的残差特征提取模块以及残差上采样模块,并集成进基线网络框架中,提高网络的特征提取与学习的能力。ResVoteNet在大规模点云公共数据集SCANNET和SUN-RGBD上的平均精度mAP@0.25分别达到61.1%和59.9%,超越了当前最先进算法至少2.2%和2.5%,这对于点云检测深度学习网络在自动驾驶、机器人控制等领域的落地具有重要意义。此外,本文还通过消融实验,证明了残差特征提取模块、残差上采样模块在检测网络中的有效性;证明了残差网络ResNet在点云深度学习的有效性,并探索了本文使用的网络ResVoteNet的最佳深度。本文只通过引入ResNet结构提升点云检测网络的精度,未来将引入更多2D检测网络中的优秀思想,进一步提升点云检测的精度。
