基于IFA-SVM的粮食霉变预测研究
2022-02-08郭利进许瑞伟李博仑
郭利进,许瑞伟,李博仑
(天津工业大学大学控制科学与工程学院,天津 300387)
民以食为天,食以粮为先,保障粮食安全是国家的战略需要[1]。据统计,我国因粮食霉变造成的损失约占粮食总产量的4%。为降低粮食损失,众多科研人员致力于粮食霉变研究。Wang等[2]通过比色传感器技术对捕获小麦不同发霉程度的气味信息,实现了小麦霉菌高精度检测。万立昊等[3]对稻谷储藏中霉菌菌落数、脂肪酸、丙二醛等品质指标检测,深入探究了稻谷霉变程度与品质指标的变化关系。以上研究成果侧重于霉变检测手段和霉变过程规律。而本研究侧重于粮食霉变发生的预测研究,以稻谷为例,根据稻谷含水量、储藏时间、温度等已知信息,建立基于IFA-SVM的粮食霉变预测模型,通过预测结果制定相应对策,对降低粮食霉变风险、减少粮食损失有着重大意义。
对于预测算法主要包括神经网络、支持向量机、灰色理论等方法。针对粮情霉变程度预测,国内学者不乏使用BP神经网络算法进行预测,BP神经网络属于监督式算法,具有若干个彼此影响的非线性单元处理器,具有良好的非线性映射能力[4]。但是因为该算法本质是依据梯度下降法,所以导致收敛速度较慢,在区间范围进一步扩大时,易出现陷入极值局部极小化现象。与BP神经网络算法对比,支持向量机(SVM)具有训练时间短、泛化能力强、预测精度高,并且克服了神经网络算法在小样本、非线性问题中的重复性差、过度拟合等不足,更适用于预测研究。然而SVM模型构建的关键是解决核参数δ和惩罚因子C的最优取值问题,初期算法参数选取多依赖于实验人员的主观经验,缺乏严谨的数学依据,所以引入萤火虫算法(FA)对 SVM 参数进行优化,同时提出一种基于高斯函数非线性变步长α的进化策略,改进FA算法寻优精度,有效提高模型的预测准确度。
1 材料与方法
1.1 实验设备
HPS-250 生化培养箱,HG-9246A 型电热恒温鼓风干燥箱,DJSFM-1粮食水分测试粉碎磨,SMART显微镜。
1.2 实验样本数据获取
将不同含水量的稻谷密封置于不同储藏温度(5、10、15、20、25、30 ℃)的生化培养箱模拟储藏环境下180 d,采样周期为10 d,每次检测水稻的水分和真菌孢子数。其中水分和真菌孢子数的检测方法分别依据GB 5009.3—2016《食品安全国家标准食品中水分的测定》[5]、 LS/T 6132—2018《粮油检测储粮真菌的检测孢子计数法》[6]。
2 预测模型基本原理
2.1 支持向量机(SVM)
支持向量回归机(SVM)的核心思想是在高维映射空间中找到1个间隔超平面,其学习策略是令其间隔最大化转化为凸二次规划问题的求解。
针对二分类问题,设N个输入样本xi(i=1,2,…,n),且yi∈{-1,1}。其中xi作为预测模型的相关输入向量,yi为输出向量。在本研究霉变预测中,yi为1时可代表未发生霉变,为-1时可代表发生霉变。决策面可表示为式(1)。
f(x)=ωTφ(x)+b
(1)
式中:ω为决策面法向量;φ(x)为原始样本数据的非线性映射函数;b为偏置值。根据最小结构风险原则,最优超平面满足式(2)。
yi(ωTφ(xi)+b)≥1
(2)
引入松弛变量ξi,目的是将分类误差控制在一个有限范围内,则可建立式(3)。
(3)
式中:c为惩罚因子,惩罚因子c的取值影响到模型的结构风险,取值过大时,结构风险越大;取值过小,模型会过于简单化[7]。
引入拉格朗日乘子αi,将式(3)变换为对偶形式,见式(4)。
(4)
式中:K(xi,xj)=φ(xi)φ(xj)为核函数,其中核函数根据需要选取,本研究选用径向核函数,表达式见式(5)。
K(xi,xj)=exp(-(xi-xj)2/2σ2)
(5)
式中:σ为径向核函数的核参数,其取值大小也对模型的效果有所影响,取值过小会导致模型的泛化能力减弱,取值过大会令模型出现过拟合现象[8]。
因此,SVM模型构建的关键是解决核参数σ和惩罚因子c的最优取值问题。所以本研究引入萤火虫算法对SVM模型参数进行优化,提高模型预测性能。
2.2 萤火虫算法(FA)
萤火虫算法是一种启发式算法,是根据自然界中萤火虫的发光行为而提出的。在萤火虫算法中,空间里的每1个解就好比萤火虫种群里的每1只萤火虫,空间里的初始解可以理解为萤火虫种的初始位置,萤火虫通过互相之间的吸引来进行移动,完成位置的更新即完成解的更新[9]。
搜索过程涉及到萤火虫的发光亮度和相互吸引度这2个参数。这2个参数都与萤火虫之间的距离成反比,这与自然现象中光在空间传播时被传播介质吸收而逐渐衰减的特性相一致[10]。
光强(I)与光源距离(r)的数学表达式见式(6)。
(6)
FA算法中萤火虫的发光强度公式见式(7)。
(7)
式中:当与光源的距离逐渐趋近或接近于零时,则发光亮度最为明亮即为I0。
由于光的传播中,不同的传播介质也会影响到光的亮度。吸收系数γ的改变可以理解为不同的传播介质,可以将其设置为常数;rij表示萤火虫i与萤火虫j之间的距离。萤火虫的吸引度见式(8)。
(8)
与萤火虫发光强度同理,当与光源的距离逐渐趋近或接近于零时,则吸引度最大即为β0。萤火虫i被吸引向萤火虫j移动的位置更新由式(9)决定。
xi=xi+β(xj-xi)
(9)
通常情况采用式(10)。
xi=xi+β(xj-xi)+α(rand-0.5)
(10)
式中:扰动项α(rand-0.5),α为步长因子,是介于0与1之间的常数;rand是[0,1]上服从均匀分布的随机因子,扰动项的加入是为了扩大寻优区域。
因此,步长α与寻优精度有较大影响,但α为固定参数导致在进化后期难以寻找全局最优。因此应对α采用递减的策略,在进化前期快速收敛,进化后期充分在局部进行寻优找到最优值。对于α进行线性递减在解决非线性问题上通常寻找不到最优解。结合上述思想,本研究设计一种基于高斯函数的非线性变步长的进化策略,步长α迭代关系如式(11)所示。
(11)
式中:αmax为初始权重;αmin为最终权重;t为当前迭代次数;T为最大迭代次数;k为固定参数。
2.3 IFA对SVM参数优化
用IFA算法优化SVM参数的过程,就是萤火虫寻找最佳位置X(c*,σ*)的过程,基本步骤为:
步骤一:对改进萤火虫算法参数初始化设置:萤火虫数量为M,初始吸引度β0,光强吸收系数γ,最大迭代次数T以及萤火虫的初始位置为(c,σ)。
步骤二:[c,σ]作为SVM的初始参数,也代表萤火虫的一个位置。将训练集样本作为SVM模型的输入,并输出预测集{y1,y2,…,yn}。
步骤三:将训练集的预测错误率作为IFA-SVM算法的适应度函数。
步骤四:判断终止条件:当前迭代次数大于设置的最大迭代次数。满足终止条件则执行步骤六,若不满足则执行下一步骤。
步骤五:根据萤火虫的相对亮度决定到下一个位置的移动方向并调整步长α,若目标位置劣于之前的位置,萤火虫位置保持不变,否则萤火虫进行位置的更新,产生新的[c,σ],返回步骤二。
步骤六:将输出的最优解代入SVM预测模型,获得SVM模型的最佳参数(c*,σ*)。
3 粮食霉变预测研究
3.1 粮食霉变分类
研究选取稻谷水分、储藏温度、储藏时间这3个特征变量作为FA-SVR预测模型的输入,稻谷霉变情况作为预测模型的输出。稻谷霉变程度共分为5个等级:{安全、临界、危害、严重危害},分别与霉变等级{Ⅰ、Ⅱ、Ⅲ、Ⅳ}相映射,划分依据见表1。

表1 储粮安全分类标准
3.2 数据处理
选取的样本数据(稻谷水分、储藏温度、储藏时间)通常不直接使用,因为不同类型的数据其量纲单位也不同,样本数值波动较大时,不利于SVM模型的学习训练,为了消除特征向量间的量纲影响及保证模型运行速度,应把训练样本数值进行归一化处理,会改善SVM的学习效果,提高最终的预测精度,将数据映射到[0,1]空间,可通过归一化公式实现,见式(12)。
(12)
式中:x为任意一组样本的某一维数据;max(x)为最大值;min(x)为最小值。
3.3 IFA-SVM建模流程与模型验证
采用IFA-SVM算法进行粮食霉变分类预测的结构图如1所示。
建模方法:选取实验台原始数据,进行预处理。实验共收集水稻样本936,将“Ⅲ级-危害”作为判断是否霉变的标准,将未发生霉变样本用“1”标记,已发生霉变样本用“-1”标记。随机选取其中500组样本作为预测模型的总样本,将所选取的总样本集按9∶1的比例划分为训练集和测试集,其中随机选取450组实验台生化培养箱数据对模型进行训练,将剩余50组样本数据进行测试本研究的IFA-SVM预测模型效果。
设置IFA算法的初始参数,萤火虫数目M=100,光强吸收系数γ=1.0,初始吸引度β0=0.8,步长因子设置为0.5,最大迭代次数T=100。对SVM进行离线参数寻优,得到最优核参数σ*=0.560 6,惩罚因子c*=46.068 5,从而建立最优的SVM预测模型结构,见图1。
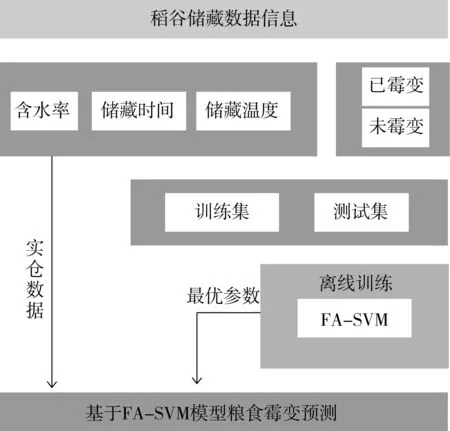
图1 基于FA-SVM的粮情霉变预测结构图
根据训练集数据对得到的SVM预测模型进行训练,当到达理想训练精度后,输入测试集进行验证,并对输出结果进行评估。
根据建模过程与初始参数,在MATLAB R2018b环境下借助支持向量回归机工具箱及运行IFA-SVM模型,算法训练的适应度曲线如图2所示。
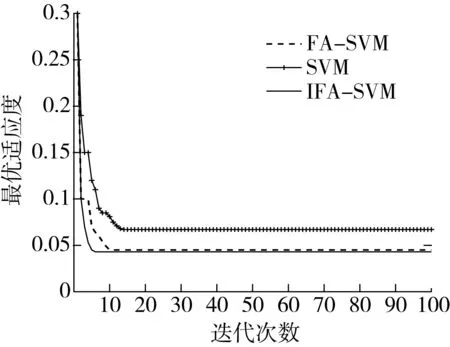
图2 不同模型参数的适应度曲线对比
算法收敛速度越快,代表所建立的预测模型表现能力越好。图2表明,FA算法对SVM的参数寻优速度很快,迭代次数在第10次时已经收敛,体现了FA-SVM良好的收敛性。动态变步长的IFA-SVM在第6次就已经收敛,但收敛的最优适应度仅比FA-SVM降低了0.004,说明通过动态调整步长可以有效地缩短收敛时间,在最优解的适应度上与FA算法结果相差不大,但具有参考意义。二者相比单一的SVM算法,引入的FA算法优化了c与σ这2个参数,大大降低了参数值选择的随机性。
选取了50组样本数据进行测试,结果节选见表2。
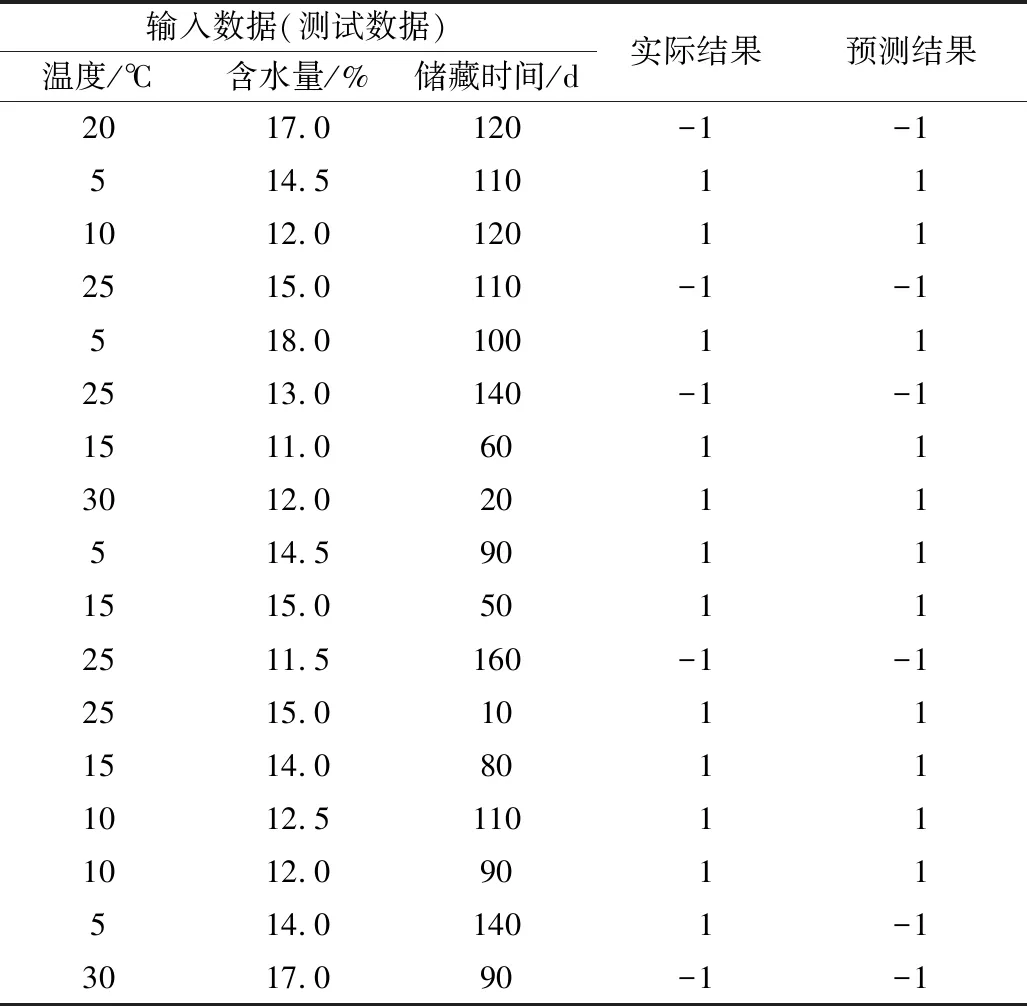
表2 测试数据结果节选
图3为50组测试样本的霉变分类预测结果,可看出IFA-SVM预测模型的预测结果和实际结果基本符合,仅有2份数据的预测结果与实际不符,准确率高达96%。
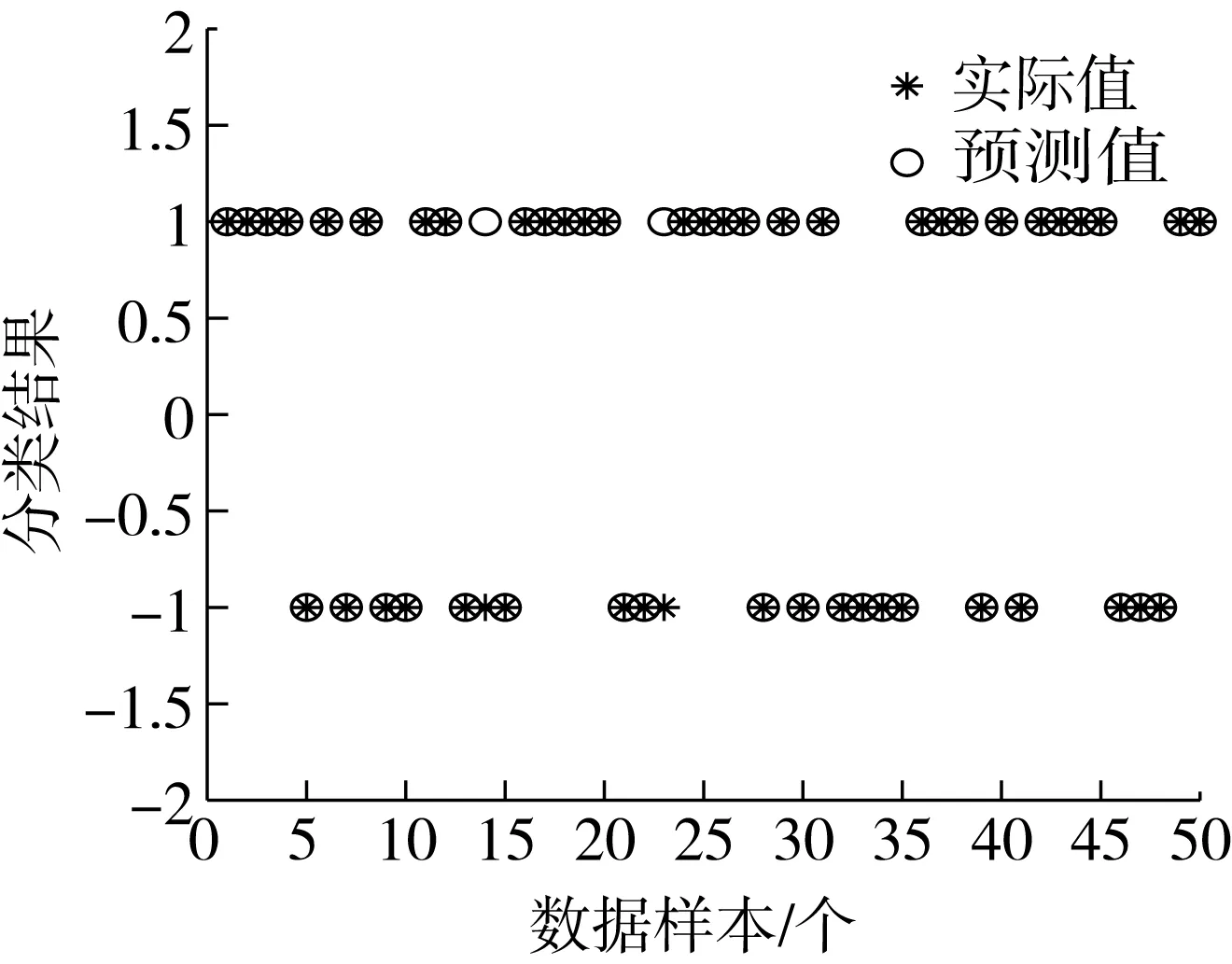
图3 IFA-SVM预测结果图
为验证IFA-SVM模型的优越性,使用相同的样本数据,对比研究BP模型、SVM模型和FA-SVM的粮食霉变预测效果。不同算法预测准确率对比见表3。由表3可知,本研究所采用的IFA-SVM算法有较高的预测准确率,在粮食霉变预测领域具备一定可行性。
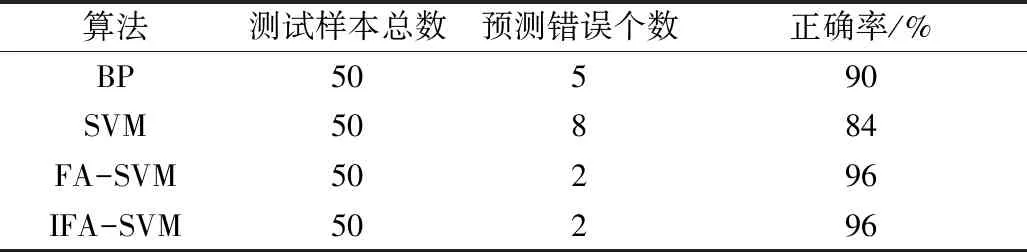
表3 不同算法预测准确率对比
4 结论
本研究利用MATLAB建立了基于FA-SVM的粮食霉变预测分类模型。通过理论研究和实验数据,利用生化培养箱对真实储藏环境进行模拟,将IFA-SVM模型运用到生化培养箱进行存储预测。相比BP神经网络、普通SVM模型,IFA-SVM泛化能力强、预测准确率高;相比于传统FA-SVM模型,IFA-SVM寻优时间降低,在预测准确率上二者相差不大,但为改进FA算法提供一定的参考。对于生化培养箱数据,IFA-SVM模型准确率高达96%。IFA-SVM模型的提出为实际粮食储藏的霉变预测提供了一种新思路,具有一定实际应用意义。
