改进YOLOv4 的车辆图像检测算法研究
2022-02-07刘瑞峰孟利清
刘瑞峰,孟利清
(西南林业大学 机械与交通学院,昆明 650224)
0 引言
近年来,随着经济和社会的发展,机动车作为一种方便的交通工具得到大规模的使用,截至2022 年3 月底,全国机动车保有量达4.02 亿辆。然而众所周知的是,机动车辆事故也可能会给社会及个人带来严重危害。基于此,无人驾驶汽车的开发和推广对保障行车安全、提高通行效率发挥着重要作用[1]。自动驾驶日益受到广泛关注。目标检测作为自动驾驶环境感知中图像方面的关键技术,也吸引了众多学者参与研究[2]。丁乐乐[3]提出了一种深度学习与强化学习相结合的方法来对大巴车、轿车和货车进行分类。然而,由于缺乏有效训练数据集,即需进一步证明模型的适应性。余胜等人[4]提出了复杂场景下车辆识别方法,对漏标注、误标注的车辆进行重新标注,但是却没有关注到自动驾驶场景下的遮挡问题。在自动驾驶视角下,车辆目标往往会存在如目标间遮挡、环境背景遮挡等现实问题[5],会直接影响目标检测的准确度。在真实环境下对车辆检测的错误,会对自动驾驶造成不小的干扰,甚至引发后续安全问题。
因此,对于真实场景下因车辆间遮挡、环境背景遮挡而导致的车辆检测中产生的误检、漏检等问题,亟需研发能够在复杂场景中对车辆进行较为准确检测的车辆检测算法。研究可知,YOLOv4 算法有着检测准确率高和检测速度快的优点,能满足车辆检测对实时性和准确度的要求[6]。但是YOLOv4 算法应用于车辆检测时,也存在因复杂场景下车辆重叠遮挡和环境背景遮挡问题导致的误检和漏检问题[7]。
因此,本文提出了一个改进的YOLOv4 算法,在YOLOv4 网络的Neck 部分添加了CBAM 通道和空间注意力机制。并采用k-means 均值算法,生成合适的锚框应用于该网络,提升算法对真实环境下不同尺寸车辆的识别率。以期为自动驾驶车辆识别提供一个有效的方法。
1 改进的YOLOv4 算法
1.1 YOLOv4 算法
YOLOv4 的输入为固定大小。主干网络(Backbone)与YOLOv3算法相比,使用了CSPDarkNet 网络。CSPDarkNet 网络的整体CSP 结构是将原来的网络分为2 部分。一部分是原来的残差结构、另一部分通过运算后直接与前一部分的运算结果结合,有效提升了网络的学习能力。YOLOv4网络在保持一定轻量化的同时,拥有较高的识别精度。主干网络与颈部网络通过3 个尺寸的通道头进行连接。3 种尺度用以检测大、中、小型的物体。网络的颈部(Neck)采用了PANet 结构,用来进行特征融合。为YOLOv4 网络还提出了moasic 数据增强方法,使网络能够在有限的数据集上得到更好的效果。
1.2 注意力机制
CBAM 注意力机制包括通道注意力机制(Channel Attention Module,CAM)和空间注意力机制(Spartial Attention Module,SAM)[8]。CBAM 模块中,通道注意力模块的输出作为空间注意力模块的输入。CAM 模块中,输入特征图先经过一个全局平均池化和全局最大池化层,再经过Sigmoid激活操作,生成通道注意力特征Mc,再与该模块的输入相乘,得到空间注意力模块需要的特征图。通道注意力特征Mc计算公式可表示为:

其中,“σ” 为Sigmoid操作。
SAM 空间注意力模块中,输入特征图同时进入全局平均池化和全局最大池化,通过2 个池化层进行通道拼接,经过7*7 卷积层卷积操作后输入Sigmoid层,由此得到的空间注意力特征Ms与该子模块的输入做乘法,得到最终生成的特征。空间注意力特征计算Ms可由式(2)进行描述:

1.3 k-means 算法
聚类算法是能够通过数据的特点,将具有相似特征的数据分为同类的算法[9]。k-means 算法是通过选定K个中心点,再计算数据中每个例子到中心点的欧氏距离,将距离相近的数据划分到一类。分类后,重新计算同类数据的中心点,得到K个新的中心点后重复上述过程。当各类别中的数据划分不再变化时,最终确定K个中心点。k-means 聚类算法的损失函数具体如下:
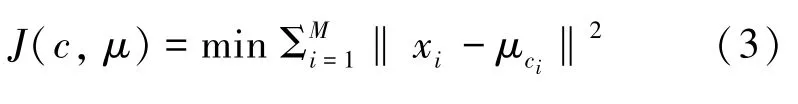
将K-means 聚类算法引入到锚框的选定上,可以提高检测的准确率[10]。通过k-means 算法计算锚框时,需要引入新的损失函数来评价锚框。采用IoU的损失函数见式(4):

其中,i为目标真实框的长宽;c为中心点的长宽;IoU是计算聚类中心与真实框交并比的过程。交并比是2 个框在图像上的交集与并集之比,交并比越接近1,说明2 个框的重合程度越高。因此,用1 减去交并比的差来作为本文聚类算法的损失函数,能够较为合理地评价锚框对于指定数据集的优劣。本文由BBD100K 数据集生成的anchor box 尺寸大小 为[6,2],[7,5],[10,4],[11,7],[17,6],[23,11],[42,17],[78,31],[165,72]。
1.4 改进的YOLOv4 算法
本文主要对YOLOv4 算法的网络结构、锚框生成进行改进。网络结构上,本文将CBAM 注意力模块分别添加在PANet 的3 个输入后面,再分别添加4 个CBAM 注意力模块到2 个上采样和2 个下采样模块上的输出上。注意力模块对输入的通道和空间位置进行加权后输出,不改变特征图的维度。改进后的YOLOv4 模块如图1 所示。同时,网络采用了由k-means 聚类算法在数据集上计算出的锚框,可以使锚框尺寸适合数据集中的物体。
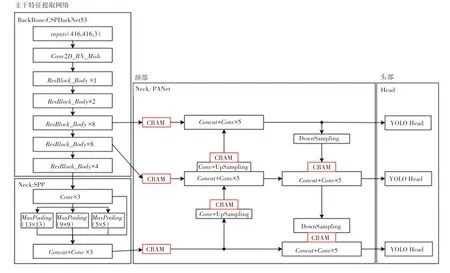
图1 改进的YOLOv4 目标检测网络Fig. 1 Improved YOLOv4 target detection network
2 实验
2.1 数据集和实验平台
数据集选用由加州大学伯克利分校发布的BBD100k 数据集,这是自动驾驶领域规模最大,场景最多样的驾驶视频数据集之一。数据集中包含晴天、阴雨天、夜晚等各种车辆行驶中采集的图像数据。本文从中选取了10 000 张图片作为数据集,其中2 000 张为测试集,1 600 张为验证集,6 400 张为训练集。本文删去原数据集的pedestrian、rider、train、motorcycle、bicycle、traffic light、traffic sign、trailer 类,将car、truck、bus 合并为vehicle 类。
实验平台为Windows10,GPU 为RTX3070,显存为8 G;CPU 为R9 5900hx,内存为16 G。
2.2 参数设置
消融实验中,优化器种类为Adam,初始学习率设为0.001,最小学习率为0.000 01,momentum设为0.937,学习率下降方式设为cos。epoch设为100,使用主干网络预训练权重,前50 个epoch冻结Backbone 训练,冻结时batch_size设为8,解冻阶段batch_size设为4。输入图片尺寸设为416×416,使用mosaic 数据增强方法。
对比实验中,优化器为Adam,学习率下降方式设为cos,epoch设为100,冻结训练50 个epoch后进行解冻训练。其他参数因各算法网络结构不同,选择各模型推荐参数进行训练。
2.3 消融实验
为验证改进网络的效果,进行消融实验。改进前后网络在测试集上的表现见表1。由表1 可知,添加了注意力机制后的网络在数据集上的准确率Precision达到了82.23%,比基线网络提高了4%。添加了k-means 算法生成的锚框后,准确率达到了83.24,比基线网络提高了5.3%。添加了注意力机制并采用k-means 算法生成锚框的模型与基线网络相比,准确率达到了82.62%,提升了4.54%;召回率达到了61.07%,提升了0.9%;AP值达到了70.52,提高了4.8%。
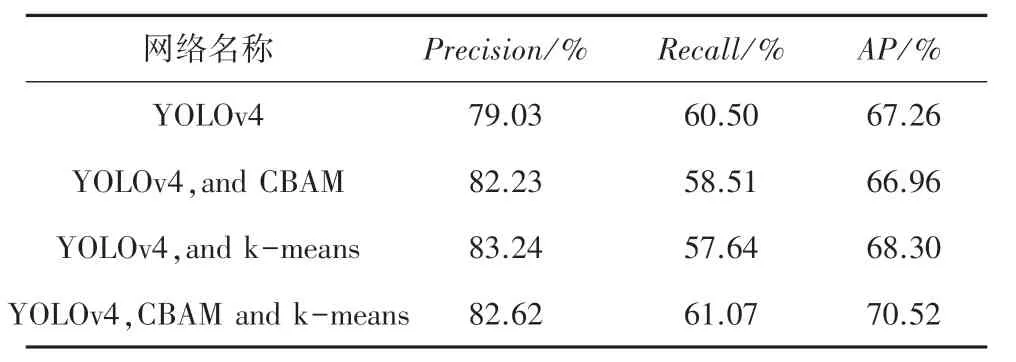
表1 消融实验Tab.1 Ablation experiments
2.4 多种检测方法对比
为检验方法的有效性,本文选取了YOLOv3、Faster R-CNN、GhostNet-YOLOv4、YOLOv5s_6.1 进行对比实验。首先使用上述网络分别在数据集中训练,然后使用测试集对上述训练过的网络进行测试,测试结果见表2。更直观的实验结果如图2 所示。具体来说,图2(a)为车辆行驶数据原图,图2(b)为Faster R-CNN 算法检测结果、图2(c)为GhostNet-YOLOv4 算法检测结果,图2(d)为YOLOv5s_v6.1算法检测结果,图2(e)为YOLOv3 算法的检测结果,图2(f)为YOLOv4 算法的检测结果,图2(f)为改进YOLOv4 算法的检测结果。

图2 不同目标检测算法与改进算法实验结果Fig. 2 Experimental results of different target detection algorithms and improved algorithms

表2 多种模型对比评价Tab.2 Comparative evaluation of multiple models %
从表2 中可以看到,YOLOv5s 和本文的模型准确率最高,分别达到了92.54%和82.62%;Faster RCNN 和本文模型召回率最高,分别达到了66.84%和61.07%;本文算法的AP高于其他算法,达到了70.52%。
图2 中,图2(g)的第一张图片表明,只有本文模型检测到了被树木遮挡的车辆,其他模型均出现了漏检的情况;对于图2 的第4 张夜晚的情景,图2(e)和图2(g)中均检测到了左方的车辆,而图2(c)和图2(d)均未能检测出左方车辆,图2(b)虽然检测到了左方车辆,但是却出现了误检情况。从图2中可以看出,改进算法能够适应不同光照条件,与文中的其他参照算法相比,不易出现漏检和误检情况。由图2(f)和图2(g)可看到,YOLOv4 算法对被环境遮挡的车辆无法进行准确识别,而改进算法在车辆被严重遮挡的情况下,依然能够准确识别出车辆。
3 结束语
复杂外部环境下的车辆检测算法对于自动驾驶车辆的安全和实时控制至关重要。虽然已经取得了一些研究成果,然而这些研究对于车辆拍摄角度下的车辆遮挡、环境遮挡问题还未能提供有效解决方案。针对这种情况,本文对自动驾驶汽车行驶过程中的车辆图像检测问题展开研究,选用了对于主流目标检测算法具有很大的挑战性的数据集BBD100k,数据集是由车辆在实际路面中采集而来,其中包含了晴天、夜晚等各种行驶场景下的图像。从该数据集中选取10 000 张图片作为实验的数据集,并对原数据集中的类别进行合并和调整,删去了和车辆无关的类别。本文选择YOLOv4 网络作为基线网络进行改进,在网络的7 个位置添加了CBAM注意力机制,添加通道注意力机制使网络忽略不重要的通道,添加空间注意力机制使得网络忽略遮挡部分的特征,提升网络对被遮挡车辆识别准确率。利用k-means 聚类算法生成适合该数据集的锚框,提升对不同尺寸大小车辆的检测能力,并通过实验进行验证。实验证明,改进的YOLOv4 网络在该数据集上的AP值达到了70.64%,比基线网络提高了5%,证明改进的YOLOv4 算法在自动驾驶中对车辆检测具有更高的精度,该方法适用于复杂条件下的自动驾驶场景。
