基于环视图的车位检测算法研究
2022-02-07饶启鹏翟树龙
饶启鹏,凌 铭,王 鑫,刘 畅,翟树龙
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引言
随着Xavier、Atlan、Orin 等车载芯片的发展,其算力将应用于L4 及L5 级别自动驾驶,与此同时人们对高级辅助驾驶的需求也在增加,完全支持ADAS 自动泊车功能被量产。然而,户外长时间使用的公共停车位除了本身可能出现的照明不足、遮挡严重等现象,甚至还会存在掉漆、灰尘污染、腐蚀等问题,如图1 所示。

图1 某地车位经过使用前后对比Fig. 1 Comparison of a certain parking space before and after use
综上所述,这些问题就容易导致装配了环视摄像头的自动泊车系统出现漏检。面对这一状况,现已相继提出了一些神经网络算法,比如针对小目标的目标检测[1]、注意力机制、以及伪装目标检测(Camouflage Object Detection,COD)等。研究可知,生物学术语中有背景匹配伪装(background matching camouflage)一词,变色龙就是诠释该词含义的一个最好的例子,即为了安全起见而使自己的身体看起来和周围的环境无异。然而一般户外公共的车位线经过反复使用后,就会出现与周围地面背景匹配的现象,只有人眼依稀能看见的车位线。因此本文将其视作背景匹配伪装,并设计了相应的检测算法。原本白色的车位线在经由车辆、行人造成的灰尘脏污后看上去与灰色的水泥路面融为一体,甚至会出现车位线之间的材料被磨掉的现象,这对于自动泊车系统研究来说无疑就是一个技术难点。因此也给针对显著性目标和通用目标的伪装检测提出了不小的挑战。伪装检测不仅可以应用于自动驾驶检测,目前也已广泛应用于搜救工作、医学图像分割、稀有物种的发现和艺术创作等方面。
1 相关工作
1.1 伪装目标检测
根据目标的状态可分为普通目标、显著性目标和伪装目标。针对伪装目标检测,SINet[2]根据自然界捕食者特点设计了搜索模块和辨认模块,PFNet[3]针对实验分析过程中出现的难例问题,设计网络结构时在聚焦模组(Focus Module,FM)中添加了逐元素加减操作以达到增强前景假阴性部分或抑制背景假阳性部分,这种方法明显削弱了假阳性的干扰。
1.2 车位检测
Hough 和Radon[4]变换作为传统的车位线检测线段特征,DeepPS[5]和DMPR-PS[6]采用了方形描述子检测直角车位顶点,但缺点是对斜向停车位检测性能会下降许多,PSDet[7]则改用圆形描述子来形容并提高对多种类型车位线的检测鲁棒性,VHHFCN[8]对斜向停车线设计的冗余模块导致了性能的下降。文献[9]和VSP-NET[10]则针对不同形状、不同角度的停车位,利用二阶或一阶的深度卷积网络同时检测车位入口的角特征与线特征。随着语义分割的流行,相比基于检测方法的网络模型来说,SPFC[11]的检测精度和实时性要更高,因此本文采用基于分割的方法进行车位检测。
2 车位检测网络模型
2.1 网络结构
本文采用超像素网络与伪装检测网络的并行设计,为了进一步提高模型的效率,使用逆残差块(Inverted Residual Block,IBN)替代残差块,输出的单级特征图经过RF(Receptive Field)模块,RF 模块的结构是根据人类视觉系统来设计的,因此本文用SINet[2]中的RF 模块代替膨胀卷积编码器。研究给出的车位检测网络结构如图2所示。

图2 车位检测网络结构Fig. 2 Parking space detection network structure
2.2 主网络
采用改进的YOLOF(You Only Look One-level Feature)[12]作为特征提取网络,网络仅仅输出单级特征图,同时为了进一步提高模型效率,主干网络使用EfficientNet-B0[13],输出单级特征图(C5),如图3所示。

图3 主干网络提取特征图Fig. 3 The backbone extraction feature map
通过输出的单级特征图一路经过4 个级联的RF 得到不同尺度的特征图,另一路输入搜索注意力(Search Attention,SA)模块。SA 模块接受C5 和部位解码组件(Partial Decoder Component,PDC)计算的特征图作为输入,由PDC 解码输出的特征图直接与标注的真值作为损失函数的输入。
2.3 辅助网络
车位检测网络下采样等操作造成了原来图像的细节损失,从而导致定位精度降低。因此添加超像素网络实时处理低像素图像。超像素网络主要由残差块组成,残差学习的设计特点是在原来的卷积模块中加入了跳转连接(Skip Connection)结构,低层的网络可以直接连接到高层网络中,很多超像素的相关工作都借鉴了这一点[14]。考虑到效率问题,利用IBN 模块代替残差块,除了局部连接外,额外加入了全局连接融合各残差块,详见图2。
2.4 损失函数
训练的损失函数为交叉熵损失函数(Cross Entropy Loss,CEL),损失函数定义如下:

其中,Ccsm、Ccim分别表示2 张检测到的车位掩码图,G为真值标签。除了CEL外,还添加了局部对象损失(Objet-aware Loss)。具体来说,所提方法为每个训练图像生成相应的车位掩码。在大多数像素点为零的每个掩码中,收集车位区域中的损失函数定义如下:

其中,f表示输出的掩码与真值图像相乘而得到相应的车位区域。因此总体损失函数定义如下:

3 模型训练及结果分析
3.1 实验数据集
目前,用于自动泊车的数据集有:PSV 数据集[8]、ps2.0 数据集[5]、PSDD 数据集[7]。其中,ps2.0由4 颗鱼眼相机拼接后的图片制作而成,600×600像素对应实际上10 m×10 m 的地面范围,数据均属于停车场景,训练集约10 000张,测试集不到5 000张。PSV 数据量较小,训练集2 550张,验证集425张,测试集1 274张。PSDD 数据集则涉及了更多场景和更丰富的停车位几何形状。
与当前流行的车位检测数据集不同,本算法构建数据集的目标是提供视觉上更具挑战性、却也与现实特殊情形最贴近的数据集。作为一个伪装目标检测数据集,实验分别从当前各流行的车位检测数据集中精心选择近似伪装的图片,并加入了一些数字处理手段:
(1)图片经下采样操作变成300×300,将这些低像素值图片作为输入,经过本文所提出的检测器输出600×600 的图片。
(2)模糊化和随机旋转等操作,用来增强检测器的检测精度和鲁棒性。
经处理后,一共得到了10 000张图片(6 000 张用来训练,4 000 张用于测试)。并按照伪装目标检测的标准进行标注,作为实验的训练集和测试集。
3.2 训练策略与参数
实验执行的算法在Linux18.04 64 位操作系统上实现,使用设备为Intel(R)Core(TM)i7-10510U CPU@1.80 GHz 32 G 内存、显卡为NVIDIA GeForce 1080Ti、PyCharm2019 社区版、PyTorch 深度学习框架。在训练阶段,批大小设置为36 张图片,学习率设为0.001,循环次数设为500,利用自适应矩估计(Adam)优化器,该优化器可以自动调节学习率,加速模型训练过程,减少模型参数调整数目等优点。
3.3 对比实验
为验证所提方法的有效性,在服务器工作站上进行了实验。图4 为同等条件下,所提方法与其他3 种方法在数据集上经过训练后求出的val_loss最低的权重进行预测后,得到的效果图。从图像的对比可以看出,所提方法比一般的基于分割的方法更能精确定位出车位线位置,提升了对车位线目标的捕捉能力,从而使得包含空车位鉴别等后处理任务在内的整体检测精度有了提升。
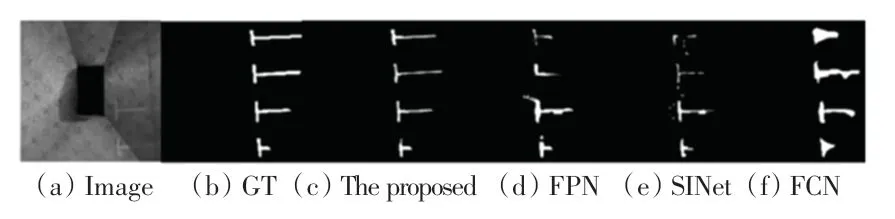
图4 在数据集上的分割效果Fig. 4 Segmentation effect on the dataset
实验使用MAE、Fβ、交并比(IoU)作为性能评估标准进行定量分析,先对所提出方法与其他3 种方法用相同的性能指标进行比较,并且采用相同的训练和测试方法,得到在本文数据集上检测结果,定量分析结果见表1。针对分割任务,基于自然界的捕猎方法设计的车位检测器更利于检测到近似伪装的目标,IoU值为82.1,Fβ值为88.4,MAE值为0.045。对于车位线预测较好,但对于隐蔽性较强的特征分类能力仍有进步空间。

表1 数据集上不同分割算法性能对比Tab.1 Performance comparison of different segmentation algorithms on the dataset proposed in this paper %
YOLOF 框架下不同主干网络对性能的影响见表2。由表2 可知,YOLOF 框架下EfficientNet-B0相比EfficientNet-B1 性能并未下降多少,且在降低模型尺寸的条件下提高了网络运行的效率。

表2 数据集上不同主干提取网络性能对比Tab.2 Performance comparison of different backbone extraction networks on the dataset proposed in this paper %
4 结束语
基于自然界捕食者捕捉原理,设计出一种紧凑而高效的神经网络模型。先对目标区域进行搜索,再进行边界框的精确定位;基于建立的数据集,提出的车位检测算法能实现高精度的同时满足实时性的性能要求;通过超像素并行模块,实现对目标的更精确定位。实验证明,所提出的网络模型擅长在遮挡、阴影、灰尘污染等难以辨认的环境中对车位线进行精确识别并回归出位置。今后会采用生成对抗网络(Generative Adversarial Networks,GAN)方法生成更多近似伪装的车位线图片并做成数据集,从而增强模型的鲁棒性,提高检测精度。
