基于卷积自编码的图像降噪研究
2022-02-04龚志广刘晓柳尹慧敏
龚志广 刘晓柳 尹慧敏
(河北建筑工程学院,河北 张家口 075000)
0 引 言
本文先对椒盐和高斯噪声进行介绍,首先对我们的数据集图像加入高斯和椒盐噪声,对比传统的滤波器对这两种噪声的去噪的效果,然后重点采用神经网络的方法搭建卷积自编码器降噪模对原始图像加入不同程度高斯噪声,逐渐调整学率和迭代次数,使损失值降到最低效果最好.通过对比降噪后的图像和原始图像之间的差异来评估降噪模型的优劣.
1 噪声种类
图像带的噪音的类型也有许多,主要有椒盐噪音、泊松噪声、乘性噪音以及高斯噪声.通过专家们大量的试验研究,所拍摄获得的图像中大多带椒盐噪音和高斯噪声,所以本论文将重点阐述高斯噪声和椒盐噪音问题[2].
1.1 高斯噪声
图像噪声中高斯噪声占绝大一部分,它主要由于在拍照过中的产生的亮度不均匀,图像传感器长时间工作造成的发热等原因造成的,本文章加入符合正态分布的σ不同程度的高斯噪声来模拟现实中的图像噪声,高斯噪声的概率密度为正态分布,公式如下.
高斯分布(正态分布):
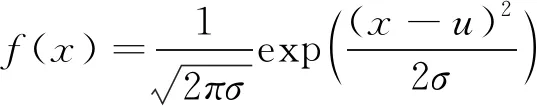
(1)
注:μ是高斯函数的偏移,σ是高斯函数标准差.
下面分别展示了对图像加入高斯为25和40的高斯噪声后的效果图.
陈远景副厅长到永嘉缙云调研(省厅执法监察局〈监察总队〉) ...................................................................12-12

图1 含高斯程度25的噪声 图2 含高斯程度40的噪声
1.2 椒盐噪声
椒盐噪声在图像上表现出来的形式是黑白点,椒盐噪声是拍摄过程中受到莫名而来的强烈干扰导致的,椒盐噪声用中值滤波的去除效果会相对来说比较好[3].下面是对图像加入30%的椒盐噪声后的效果图:

图3 含30%的椒盐噪声
2 传统降噪滤波器
在图像处理过程中噪声的存在带来了很多困难,所以对收集的图像需要滤波处理也就是降噪.在图像降噪之后才能更好的进行下一步的工作.降噪的任务也是非常关键的,决定了最后图像处理的成败.
2.1 中值滤波器
均值滤波器通过非线性的方式,用每个点的旁边像素点的中值来代表图像的所有像素点的值,这样它就更接近的真实值,来去除存在的噪声点[4].具体是通过一个滑动窗口,把滑动窗口内的像素值通过升序或降序的操作进行排序,最后用中值进行填充.中值滤波对椒盐噪声去除的效果比较好.中值滤波公式如下:
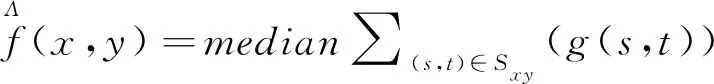
(2)
2.2 均值滤波器
均值滤波器通过线性的方式,平均了整个窗口区域内的所有图像值,但平均滤波器自身也存在着固有的缺点,就是它既无法很好地保留图像细节,在对图像去噪的同时又损害了图像的细节部分,因而使图象更加模糊不清,也无法很好地消除噪声点.对椒盐噪音的表现不好,对高斯噪声则比较好,因为高斯噪声服从正态分布所以对均值噪音为零可以用均值滤波器[5].均值滤波器公式如下:

(3)
下面是在图像中加入椒盐噪声和高斯噪声,然后用中值滤波和均值滤波进行降噪后的结果图:

图4 椒盐噪声原图 图5 中值滤波后结果 图6 均值滤波后结果

图7 高斯噪声原图像 图8 中值滤波后结果 图9 均值滤波后结果
可以看到用中值滤波器对椒盐噪声去除的结果,还是会有一些噪声点不能去除,去除的不是特别全面而且由于像素值要进行排序,所以运行的时间会很长.中值滤波器去除高斯噪声会改变原始图像的色调,可以看到用均值滤波器对椒盐噪声去除的结果,效果很差,噪声没有明显的去除,均值滤波器对高斯噪声的去除可以看出效果比较好但是使图像变得很模糊,所以本文采用卷积自编码对图像降噪.
3 卷积降噪自编码器
3.1 卷积自编码器的原理
用卷积自编码器来实现对图像进行降噪,充分利用卷积神经网络强大的学习能力获取图像的特征.卷积自编码就是将卷积神经网络和自编码相结合,其中卷积神经网络的卷积变换使用卷积层、最大池化层、上采样层和激活函数作为神将网络的主要组成部分,它是一种无监督的学习模型,由是由两部分构成,一部分是编码器,另一部分是解码器[6].编码器是对原始的输入图像进行特征压缩降维提取图像的特征信息.编码器一个逆向的神经网络会把压缩的图像特征进行还原.
降噪卷积自编码的原理就是把带噪声的数据集输入到自编码中,原始数据集作为输出,训练这个自编码器模型,反复训练迭代改变损失函数的误差项来使结果更精确[7].让模型通过卷积自编码器不断地学习和优化降噪的过程,通过迭代的次数和加入不同程度的高斯噪声训练模型不断的进行实验从而使降噪效果达到最优[8].
3.2 数据集预处理
通过爬虫技术在网页上爬取了3000张图片准备数据集,其中2000张为训练集1000张为验证集,对图像加入不同程度的高斯噪声,首先对图像进行预处理:把图像裁剪到指定像素范围内,所以把爬到的图片尺寸设置为固定的244*244像素,对图像进行归一化:使图像中每个像素点的数字值在0到1之间.然后把带噪声的图像输入到搭建的降噪自动编码器网络模型中进行训练.通过损失值对模型进行反向传播,就能达到降噪的模型.之后再通过100张图片对训练好的降噪网络模型的降噪效果进行测试.
3.3 训练模型
分别加入不同程度的高斯噪声,测试降噪自编码器模型的降噪效果,在梯度下降过程中使用损失函数的值来调整参数使网络优化,随着迭代次数的增加,损失值越来越低,但是当迭代次数到达一定值后效果会越来越差或者考虑到训练时间和耗费资源等其他的成本因素,比如300次的迭代效果和350次的迭代效果一样,那就可以训练300次就足够了.这个预测的效果就可以用损失函数的值来评估.
通过卷积自编码器对图像降噪,将降噪后的图像和原始图像做比较,来评估降噪模型效果.用均方误差损失函数来检测模型的预测结果和真实结果之间的误差,误差值越大那么预测效果越差.
均方误差神经网络中最常用的来评估模型效果的误差函数,它是预测值与目标值之间差值平方和的均值,使用梯度下降算法,随着误差的减小,梯度也在减小,利于约束[5].

(4)

3.4 模型的降噪效果
通过一些图像来验证模型的降噪效果左上角的图像是加入了σ=25的高斯噪声的效果,右上角的图像是输入到训练好的自动编码器模型经过迭代了30次的效果,左下角是迭代了60次的效果,右下角是迭代了100次的效果,最后的输出图像在效果上更好,图像更清晰.下面是针对高斯程度为25的噪声图像分别进行不同次数的迭代效果图.

图10 高斯程度为25噪声图像 图11 迭代30次恢复图像

图12 迭代60次恢复图像 图13 迭代100次恢复图像
下面向图片中加入σ=30的高斯噪声,分别迭代30次、60次、100次的训练降噪模型降噪后的效果图.

图14 高斯程度为30噪声图像 图15 迭代30次恢复图像
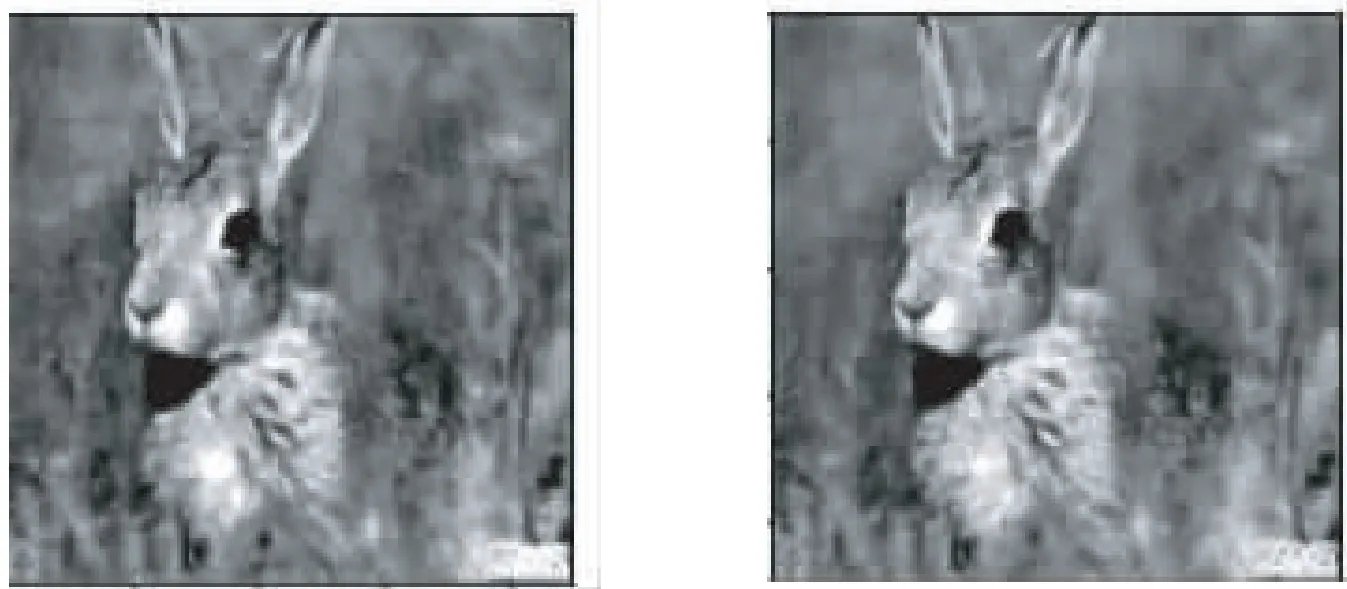
图16 迭代60次恢复图像 图17 迭代100次恢复图像
可以看出用卷积自编码器对加入了高斯噪声的图像进行降噪,迭代了100次之后效果无论加入多少的高斯噪声降噪效果都很好,既把图像噪声点去除了又很清楚.
3.5 训练集和测试集损失函数图
采用学习率为lr=0.003,迭代100次训练的结果,模型的loss随训练的轮数的增加缓慢下降然后趋于稳定,虽然在模型的训练的初始阶段,loss出现大幅度震荡变化,只要数据量足够,模型正确,迭代的次数足够长,最终模型会趋于约束的状态,接近最优值.可以看到训练的模型效果非常好,随着迭代次数的增加损失在逐渐的下降,迭代100次之后损失达到最低几乎接近于零.下面是训练集和测试集损失函数图.
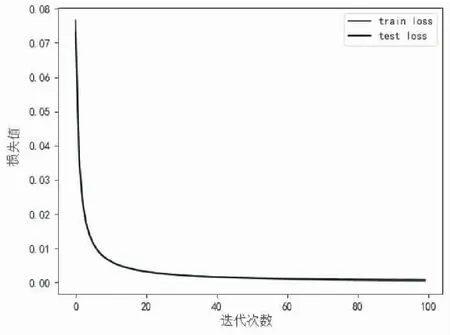
图18 训练集和测试集损失函数图
4 实验过程
本实验主要是通过python语言pytorch集成环境中完成.数据集的准备、模型搭建及训练,加入不同程度的高斯噪声,用随机梯度下降算法来更新网络参数.实验流程图,下面是整个卷积自编码器降噪的流程图.

图19 卷积自编码器降噪流程图
5 结 论
图像降噪在图像处理中起着关键的作用,本文展示了传统的均值滤波和中值滤波对图像中最普遍的噪声的降噪情况.包括以下情况:
(1)中值滤波器:对椒盐噪声去除的结果:效果很好但还会有部分噪声点不能完全去除.对高斯噪声去除的结果:会改变原始图像的色调.
(2)均值滤波器:对椒盐噪声去除的结果:效果很差,绝大多数的噪声都没去除.对高斯噪声去除的结果:是原始图像变得很模糊.
重点介绍了降噪自编码器对高斯噪声去噪.包括以下情况:
(1)分别加入了程度为25和30的高斯噪声,然后训练降噪自编码模型的迭代次数到100次训练的降噪效果最好.
(2)迭代30次、60次、100次的降噪效果以可视化视图更直观的展现出来.
(3)本文章只用了损失函数来评估模型的降噪效果.
