基于多尺度特征融合的舞蹈规范动作姿态估计方法
2022-02-03常丽萍
常 丽 萍
(1.温州大学,浙江 温州 325035;2.阜阳幼儿师范高等专科学校,安徽 阜阳 236015)
人体动作姿态估计技术[1]分为体育动作识别与生活动作识别两方面,其中体育动作包括射箭、足球、游泳等人体动作的估计,也包括一些生活动作如洗菜、切菜等人体动作的估计。然而对舞蹈动作姿态估计的研究却较少,这主要是由于舞蹈的表现形式十分复杂,有着多样化的肢体动作,不同舞蹈种类中动作差异又很大,同时舞蹈中的动作幅度也较大,很多动作都需要迅速完成,因此舞蹈动作姿态估计的难度很大。近年来,舞蹈成为一种十分热门的艺术,受到年轻人的喜爱,同时人体动作姿态估计的相关研究也在进行场景与复杂度方面的拓展[2],使舞蹈动作姿态估计问题受到多方关注。
舞蹈姿态估计方向的研究属于专业动作的研究,其研究能够实现人体动作姿态估计领域研究成果的补充,在该研究中,不同学者的研究方向有很大差异,包括帧序列分割、动作识别等。其中杨红红等[3]学者以关节点几何关系为依据提出一种层级姿态估计模型,经测试该模型的动作姿态估计效果较好。L.Truppa等[4]提出一种新的基于惯性测量单元的传感器融合算法,该算法包含一个自适应在线偏差捕获模块,在10名瑜伽专家练习者执行敬礼序列的过程中,对所提出传感器的运动捕捉准确性进行了测试。H.Ahn等[5]学者提出了能够为给定音乐生成一系列三维人体舞蹈姿势的框架,该框架由3部分组成:音乐特征编码器、姿势生成器和音乐流派分类器,实验结果表明,该方法可以根据给定的音乐生成舞蹈动作。考虑到舞蹈表现形式复杂,肢体动作较多,为优化舞蹈规范动作姿态估计效果,现综合以上研究成果,提出基于多尺度特征融合技术的舞蹈规范动作姿态估计方法。多尺度特征融合技术可以融合多方面的舞蹈规范动作特征,提高姿态估计效果。在研究过程中,在多尺度特征融合表示舞蹈规范动作的基础上,分割动作序列,分割视频前景后实现动作姿态估计,最后通过实验验证了此次研究具有较好的姿态估计效果。
1 舞蹈规范动作姿态估计
1.1 多尺度特征融合表示
在舞蹈动作过程中,人体的骨骼与关节尺度会出现大幅度变化,这就需要利用像素(pixel-wise)级关节点估计来完成舞蹈动作的姿态估计任务。在此过程中分别需要利用像素空间中的高层与低层特征,实现舞蹈动作中关节点定位,从而完成整个舞蹈动作的姿态估计过程。本文提出基于多尺度特征融合的舞蹈规范动作姿态估计方法,在姿态估计过程中有效适应关节大幅度变化,能够进一步提高舞蹈动作中姿态估计的准确率。
1.1.1 HRNet网络
利用HRNet骨干网络为主要网络,如图1所示,该网络主要由4个子网构成,4个子网均为并行的多分辨率,利用4个残差单元以及ResNet模块设计原则来完成子网络的组成。

图1 HRNet骨干网络
HRNet网络具有图像特征识别能力,能有效对图像的多分辨率特征进行提取,表达图像特征的能力出众,具有解决目标识别与检测、人体关键点估计以及图像分割等问题的能力。但HRNet网络存在仅利用高分辨率特征进行姿态估计的现象,导致中分辨率与低分辨率特征被遗弃,上述现象会在特征表示中丢失部分信息,在关节估计的精度方面受到一定影响。因此利用多尺度特征进行融合能够进一步提高姿态估计的特征表示能力。
1.1.2 序列多尺度特征融合
高分辨率的低层特征能够有效在图像特征表示过程中能够获取准确的信息位置,但存在语义信息较弱的现象,低分辨率的高层特征弥补了这一缺陷,虽然信息位置相对较为粗糙,但具有较为丰富的语义信息。基于此,通过对多分辨率特征进行有序融合来进一步提高网络特征表示能力。
如图2所示,在HRNet网络中提取其最后一个聚合单元进行,并利用序列多尺度特征融合方法完成整个输出过程,首先,获取4个具有不同分辨率的特征图;其次,利用卷积(convolution)、插值(interpolation)和反卷积(deconvolution)方法来处理上述特征图;最后,实现序列多特征从高分辨率到低分辨率的有效融合。

图2 序列多尺度特征融合模块(SMF)

(1)
其中,conv表示卷积操作,Int和Dec分别表示插值和反卷积操作。
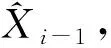
(2)

1.2 动作序列分割
设计一种主成分分析技术(principal components analysis,PCA)分割模型,通过PCA方法实现舞蹈规范动作的序列分割[6]。通过两种不同的人体动作类型有着不同的主元成分这一原理实现人体动作的区分。
在序列分割中,首先对某区间段中的舞蹈动作数据实施PCA处理,具体步骤如下:
1)用N表示舞蹈规范动作视频帧序列,用N1,…Ns表示最后的动作序列分割结果,利用S对舞蹈规范动作行为的边界和数量进行确定[7]。
2)通过指定时间中的关节旋转数据对各帧舞蹈动作视频进行表示。
3)对于各帧Xi(i=1,2,…,n),通过J代表其身体层次的实际关节数。对于各关节,直接为其指定一个四元数,即可将帧视为4*J维空间内的点,通过R4*J来表示[8]。
4)对于舞蹈运动序列与R4*J相对应的轨迹运动中心,将其定义为下式:
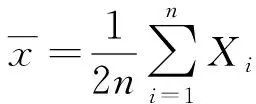
(3)
5)帧处于包含各帧的对应二维超平面上,因此认为4*J维数据始终处于高度相关状态,即能够提取所有关节点的关键数据。
通过r对维数进行表示,直接将帧近似为

(4)
式中,vr表示第r个线性子空间内形成的对应单位正交向量;αir代表第r个对特征帧进行确定的系数[9]。

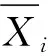

(5)
8)对E最小的r维超平面进行求取。
9)提取最小的r维超平面后,将其组织为n×56大小的矩阵,用D来表示,其中n≥56。
矩阵D的表达式具体如下:

(6)
式(6)中,U、V、Y指的是奇异分解矩阵。其中Y是一个对角矩阵,其大小为(4*J)×(4*J),对角线为非负奇异值σj的对应递减线[10]。
此时最优投影超平面上的帧为丢弃最大r后的全部奇异值,此时帧的投影误差可以用下式来表示:
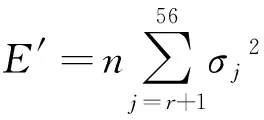
(7)
计算此时最优r维超平面内投影帧所保存的信息比率,具体如下式所示:

(8)
通过信息比率Er获取该区间段动作的主元成分。
接着对该区间的窗口长度进行增加,当增加至某数据帧时,提取出的主元成分跟前一个区间段中的成分存在很大差异,可以确定此时动作已经发生改变,实现动作序列分割[11]。
1.3 视频前景分割
对于各种动作的序列分割结果,基于HSV空间设计一种视频前景分割算法,分割其视频前景。设计的视频前景分割算法的具体运行步骤如下:
1)通过统计模型对背景中各像素p=(x,y)的颜色(h,s,v)实施时间轴变化建模。假设颜色中各分量均为独立分量,利用颜色的各个分量k∈(h,s,v)实施模型构建。也就是通过k∈(h,s,v)对颜色的标准差与均值进行计算,从而获取背景图像[12]。
其中颜色标准差的计算公式具体如下:
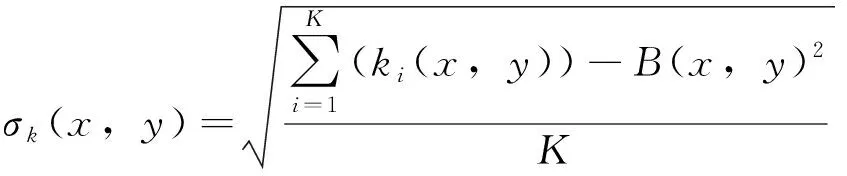
(9)
式(9)中,K指的是颜色中的分量个数;ki(x,y)指的是第i个分量;B(x,y)指的是像素点p=(x,y)全部样本值的均值[13]。
颜色均值的计算公式具体如下:

(10)
构建的背景图像模型可以通过下式来计算:
Bk(x,y)=ki(x,y)-K(σk(x,y),μk2(x,y))
(11)
2)通过构建模型实施统计推断,即通过背景图像模型对某帧像素点是否属于前景对象进行判断。
3)完成全部像素点的判断后,构建前景图像的屏蔽[14]。
4)以前景图像的屏蔽为依据,对背景图像模型进行更新,具体如下式所示:

(12)
式(12)中,t指的是前景图像的屏蔽;α指的是更新速率;RN指的是非阴影背景像素变化数量;Re指的是光线变化程度的衡量阈值[15]。
5)通过更新的背景图像模型对下一帧实施统计推断。
1.4 动作姿态估计
基于多尺度特征融合设计一种图像描述生成模型,生成舞蹈规范动作的图像描述,结合深度可分离卷积网络与级联金字塔网络构建一种舞蹈规范动作姿态估计模型,在其中输入描述图像特征文本,即可实现舞蹈规范动作姿态估计[16]。
设计的图像描述生成模型的运行步骤如下:
1)输入分割的视频前景图像数据集;
2)对各张图像第三层的尺度特征V3进行提取;
3)对各张图像第四层的尺度特征V4进行提取;
4)对各张图像第五层的尺度特征V5进行提取;
5)在生成注意力图模型中输入提取的V3、V4、V5,获取AT3、AT4、AT5这3个注意力图;
6)对注意力特征进行计算,具体公式如下:

(13)
式(13)中,C1、C2、C3指的是获得的注意力特征;
7)对注意力特征进行融合处理,获取注意力多尺度特征;
8)在语言模型解码器中输入第六层的对应全局特征与注意力多尺度特征;
9)利用交叉熵对损失进行计算;
10)对调整参数进行反馈;
11)输出描述图像特征文本。
构建的舞蹈规范动作姿态估计模型主要是将级联金字塔网络作为基础,通过深度可分离卷积网络对模型网络层级进行构造,以减少权值参数个数,实现模型估计效率的提升[17]。
该模型的结构设计如图3所示。
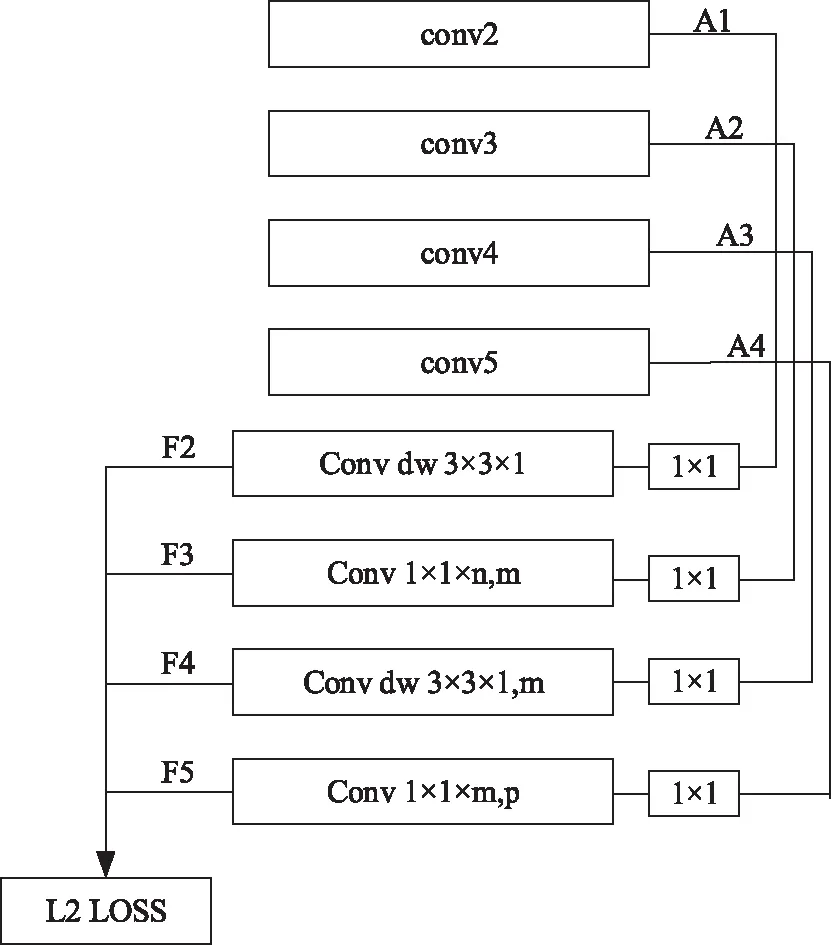
图3 舞蹈规范动作姿态估计模型设计
在该模型中,conv2到conv5层共同构成级联金字塔网络;Conv dw 3×3×1层到Conv1×1xm,p层共同构成深度可分离卷积网络[18]。A1、A2、A3、A4是级联金字塔网络输出的特征;F1、F2、F3、F4是深度可分离卷积网络输出的舞蹈规范动作姿态估计结果,需要对其实施L2损失的计算,以实现姿态估计偏差的纠正。
2 姿态估计测试
利用设计的基于多尺度特征融合的舞蹈规范动作姿态估计方法实施实验舞蹈规范动作的姿态估计,测试该方法的姿态估计性能。
2.1 实验数据集
在测试中从3个舞蹈数据库中抽取舞蹈规范动作数据,分别为拉丁舞数据库、爵士舞数据库、民族舞数据库。
拉丁舞数据库中既包括纽约3步跳法的拉丁舞舞蹈视频,也包括古巴跳法的拉丁舞舞蹈视频。在拉丁舞数据库中,抽取斗牛、桑巴、牛仔、恰恰以及伦巴的舞蹈规范动作视频数据作为实验数据集一。爵士舞数据库中含有FUNKY JAZZ、STREET JAZZ、RAGGAE等各种类型的爵士舞舞蹈视频,分别对各种舞蹈类别中的舞蹈规范动作视频数据进行抽取,将其作为实验数据集二。民族舞数据库中含有秧歌舞、孔雀舞等,在其中抽取10种民族的舞蹈视频,分别对各种民族舞蹈类别中的舞蹈规范动作视频数据进行抽取,将其作为实验数据集三。
2.2 测试项目
在测试中对姿态估计准确率进行测试,计算公式具体如下:

(14)
式(14)中,er指的是实验数据集中准确识别的舞蹈规范动作姿态数;et指的是实验数据集中总舞蹈规范动作姿态数。
2.3 测试结果分析
为验证本文所提方法姿态估计的准确性,选择三个数据集中某动作的舞蹈规范动作姿态,分别在3个数据集量为5 GB、10 GB、15 GB和20 GB时,对比独舞、群舞、明亮光线下以及阴暗光线下4种环境中舞蹈规范动作姿态估计准确率。其中,明亮光线和阴暗光线照度分别为25000LUX和3000LUX,标准的舞蹈规范动作姿态如图4所示。

(a)数据集一中某动作的姿态 (b)数据集二中某动作的姿态 (c)数据集三中某动作的姿态图4 某动作的舞蹈规范动作姿态
2.3.1 独舞与群舞下的测试结果分析
首先对不同数据集独舞与群舞的姿态估计准确率进行测试,其中独舞的测试结果如图5所示。群舞的姿态估计准确率测试结果如图6所示。

图5 独舞的姿态估计准确率 图6 群舞的姿态估计准确率
根据图5的姿态估计准确率测试数据,在独舞时,设计方法的姿态估计准确率较高。尽管随着数据量的增大,姿态估计准确率有一定下降,但降幅较小,整体来看姿态估计准确率高于95%。根据图6的姿态估计准确率测试数据,在群舞时,设计方法的姿态估计准确率仍较高,整体高于92%,但略低于独舞时的测试数据。其主要原因是本文设计了PCA分割模型,随着数据量增大,提取出的主元成分与前一个区间段中的成分存在较大差异,从而实现了独舞当前动作序列的分割,提高了姿态估计准确率。而由于群舞中的识别要素多于独舞,因此其准确率由95%降至92%。
2.3.2 明亮光线与阴暗光线下的测试结果分析
分别在两种光线下测试设计方法的姿态估计准确率,一种是明亮光线,一种是阴暗光线。其中明亮光线下的测试结果如图7所示。在阴暗光线条件下,设计方法的姿态估计准确率测试结果如图8所示。

图7 明亮光线下的姿态估计准确率 图8 阴暗光线下的姿态估计准确率
图7明亮光线下的姿态估计准确率测试数据表明,在明亮光线条件下,设计方法的姿态估计准确率整体高于93%。图8比较阴暗的光线条件下,可以看出设计方法的姿态估计准确率低于明亮光线下的姿态估计准确率测试数据,但整体高于86%,说明设计方法的姿态估计准确率会受到光线的影响。同时,数据集一和数据集二的姿态估计准确率明显低于数据集三的姿态估计准确率测试数据。这是由于数据集一和数据集二的节奏更快,而数据集三的节奏偏慢,在光线比较阴暗的情况下,舞蹈种类会对设计方法的姿态估计准确率造成一定影响。整体而言,无论是明亮光线还是阴暗光线,不同舞蹈种类的姿态估计准确率较高,其主要原因是本文方法在动作序列分割的基础上,分割了视频前景。依据构建的舞蹈规范动作姿态估计模型,实现舞蹈规范动作姿态估计,降低了光线对姿态估计的影响,提高了姿态估计效果。
3 结束语
在专业动作姿态估计的研究中,设计了一种应用多尺度特征融合技术的舞蹈规范动作姿态估计方法,实现了比较准确的舞蹈规范动作姿态估计。尽管该方法会在一定程度上受到环境因素的影响,但整体动作姿态估计结果还是比较准确的。在日后的研究中,将对其环境影响因素进行深入研究,争取尽量克服环境影响因素对动作姿态估计准确率的影响。
