基于变分自编码器和随机森林的混合式学习风险预警框架
2022-02-03于海霞王家骐
于海霞,王家骐
(1.合肥职业技术学院 信息工程与传媒学院,安徽 合肥 230000;2.安徽大学 计算机科学与技术学院,安徽 合肥 230000;3.安徽工贸职业技术学院 计算机信息工程系,安徽 淮南 232001)
0 引 言
随着在线教育的普及,学习预警[1]研究受到广泛关注。Du等[2]提出潜在变分自编码器模型预测学习成绩;周剑等[3]基于BP神经网络根据学生提交的作业情况预测成绩;赵磊[4]等针对MOOC平台的学习数据,运用神经网络预测学生的成绩;沈欣忆等[5]通过对学生在线学习行为进行抽样逐步回归,以了解学生在线学习行为对其学习绩效的影响。然而,现有研究普遍存在两点不足,一是只对在线学习数据预测,而忽略了线下学习数据;二是未考虑不平衡样本数据预测误差问题,不平衡样本数据指在数据集中一类或多类的样本数量远远超过其他类的样本数量[6]。教育数据属于不平衡样本数据,传统分类算法使用不平衡数据时的分类结果性能较差。为了提高预测效果,需要对数据进行增强。变分自动编码器[7](variational autoencoder,VAE)可以用来生成与原始数据集相似的新数据。An等[8]、Xu等[9]、Chalapathy等[10]、马波等[11]、常吉亮等[12]证明了VAE在数据增强方面的可行性。
为了解决上述问题,提出基于VAE和随机森林的混合式学习风险预测框架VRFRisk(VAE random forest risk),框架使用VAE模型处理不平衡数据,利用处理后的数据集训练随机森林分类器,实现混合式学习风险的预测,通过多组对比实验验证了所提出的预测框架的有效性。
1 VRFRisk学习风险预警框架构建
预警模型架构如图1所示,模型由数据采集处理、数据增强、模型训练3部分模块组成。
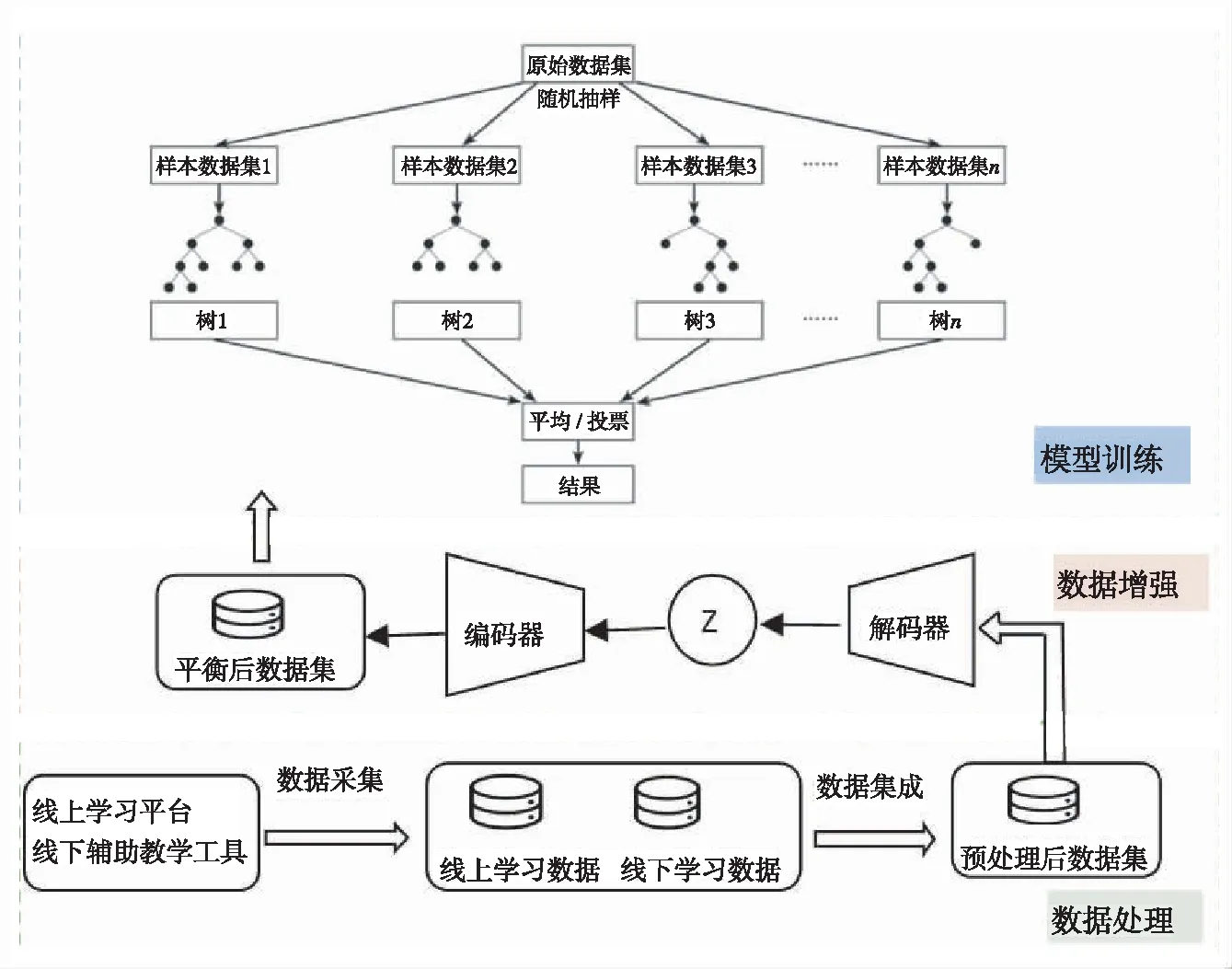
图1 混合学习风险预测框架
1.1 数据处理模块
从线上学习平台和线下辅助教学平台中采集所有学生的学习数据,得到的数据集中包括线上学习行为数据和线下课堂学习数据,如视频观看时长、作业得分、单元测试成绩、发贴回贴次数、课堂参与答题率及得分、课堂投稿数、小组得分、实验得分等。为了避免不同班级之间学生差异带来的影响,需要将数据进行归一化处理,使得数据具有可比性。
1.2 数据增强模块
对于教育数据集,不及格的学生的人数相对于及格的学生人数过少,为了提高模型性能,最大化分类精度,需要对数据集进行增强处理,增加不及格样本数量。利用VAE模型进行数据平衡运算,然后对平衡后数据进行标准化处理。VAE模型的框架图如图2所示。

图2 VAE模型框架
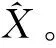

(1)
其中z是遵循标准正态分布潜在空间采样的隐向量,条件分布p(x|z)是具有均值μ(z)和方差σ(z)的高斯分布,p(z)是p(x|z)的权重。若希望生成的样本与原始样本具有相同的特征分布,p(x|z)应该最大化数据集中每个样本的概率p(x),这等价于求解关于x最大对数似然,即公式(2)所示。为了实现这个目标,VAE需要根据给定的样本x,通过神经网络学习最优潜在高斯分布q(z|x),使得p(x|z)可以代替q(z|x)。
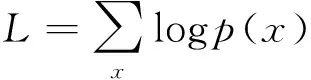
(2)
其中公式(2)中的logp(x)根据全概率定理和贝叶斯定理可以表示为公式(3):
(3)
公式(3)中的第二项即为q和p的KL散度,即KL(q(z|x)||p(z|x))。用Lb表示公式(3)中的第一项,则公式(3)可以写为
logp(x)=Lb+KL(q(z|x)||p(z|x))
(4)
因为KL散度大于等于0,所以Lb就是logp(x)的下界,即logp(x)≥Lb。为了让logp(x)越大,只要让Lb最大化即可。利用贝叶斯定理对公式(4)进一步变换可得公式(5):
Lb=-KL(q(z|x)||p(z))+Eq(z|x)(logp(x|z))
(5)
z=μ+ε×σ
(6)
其中,ε从标准正态分布中采样。
1.3 模型训练模块
随机森林是目前最常用的一种集成学习算法,相对其它分类算法具有很多优势:模型预测准确率高,即使存在部分数据缺失的情况,随机森林也能保持很高的分类精度,而且它能够评估各个特征在分类问题上的重要性,对当前研究分析影响学生成绩的因素有很大的帮助;对于不平衡的数据集来说,随机森林算法可以平衡误差;相对其他算法随机森林算法的运行效率高。
VRFRisk框架的学习风险预测采用随机森林算法,将平衡后得到的数据集输入到模型训练模块进行训练,并使用网格搜索进行参数优化,最后得到最优模型。
1.4 评估指标
用于预警的数据集通常是不平衡的,针对不平衡样本数据的特点,仅使用整体查准率(precision)来衡量模型的预测性能是不合适的,由于原始训练样本中正类样本数量过少,导致在测试时查准率很高但查全率(recall)很低。F1分数综合考虑了查准率和查全率,是2个衡量指标的调和平均。F1分数和查全率这两项指标往往能更准确地反映出少量样本的扩充效果。因此本文选择查全率和F1分数作为评价指标。利用混淆矩阵表示不平衡数据的分类结果见表1。

表1 学习风险预测混淆矩阵
根据表1,可以将各衡量指标的计算公式表示为如公式(7)、公式(8)所示:

(7)

(8)
2 实验和分析
2.1 实验数据
研究以某高职院校C语言程序设计课程的学习数据构建数据集。数据采集于雨课堂和学习通平台,其中线上学习数据来源于超星学习通平台,线下学习数据来源于雨课堂辅助教学平台,共采集3个学期每学期615名学生的学习数据。对采集数据进行梳理汇总,消除相同的语义数据和对预测无关的数据后,最后确定21个特征列,各特征内容见表2。其中,综合成绩是根据学习通上的学习成绩和雨课堂中的成绩按一定比例计算得到。根据综合成绩的值得到学习风险的值,如果综合成绩大于60,学习风险列的值标记为0,否则标记为1。

表2 数据集特征描述
将获取的数据进行整合得到数据集共有1 845条数据,其中不具有学习风险的样本(负类)1 640条,具有学习风险的样本(正类)205条。将得到的样本按7:3的比例划分为训练集和测试集,得到训练集共1 291条记录,包含正样本134条;测试集554条,其中正样本71条,负样本483条。在训练集中,负样本的数量是正样本数量的9倍之多,根据不平衡数据集的标准,当前的数据集是一个高度不平衡数据集,如果直接在这个数据集上进行训练模型,那么模型识别出具有学习风险的学生性能会很低,因此,需要进行数据增强处理。我们使用VRFRisk框架中的数据增强模块对训练集进行数据增强处理,使得正样本的数量与负样本的数量相当。
2.2 实验设置
VRFRisk框架使用随机森林作为分类器,其中分类器的评价标准采用信息增益;评估器的数量范围从50到150,步长为50;树的最大深度范围是从5到20,步长为5;使用网格搜索和5折交叉验证确定最优模型。
2.3 实验结果与分析
使用逻辑回归(logistic regression),支持向量机(support vector machine)、AdaBoost几种分类算法作为基线方法,分别使用SMOTE及VAE两种数据增强方法对训练集进行数据平衡处理,然后将数据输入VRFRisk框架和基线方法训练预测模型,训练完成后使用测试集进行验证,各种分类方法和VRFRisk的验证结果见表3。

表3 VRFRisk和各种分类算法的验证结果对比
表3中前4行的结果是在原始不平衡训练集上训练得到的模型预测结果,4种分类算法的预测性能表现都很差。中间4行和最后4行是分别使用SMOTE和VAE技术对原始训练集进行数据平衡处理后训练模型预测的结果,很显然两种数据平衡方法匀有益于预测性能的提升,但相对SMOTE,VAE的效果更胜一筹,尤其是使用随机森林算法的VRFRisk框架在查全率和F1值上,均高于其他方法。这说明,VRFRisk框架在混合式学习风险预警方面是有效的。
框架运用随机森林算法对数据特征重要性进行分析,按照重要程度进行排序并可视化,如图3所示。对成绩影响最大的前10个学习行为中,包括5个线上行为、4个线下行为和1个阶段性考核结果。与实际相符,线上学习投入时间长,作业优秀,积极参与线上线下教学互动的学生,成绩就会比较优秀,反之,就可能会存在不及格的学习风险。

图3 各种特征列对成绩影响的重要性
3 结 论
本研究提出了一种用于混合式学习风险预测的框架VRFRisk,框架使用VAE模型进行数据增强处理,以缓解教育数据集不平衡情况带来的预测准确率低的问题;使用随机森林分类器为具有学习风险的学生提供早期风险预警,使得具有风险的学生能够及时调整学习状态,教师也可以及时调整教学策略,从而最大限度保证学习效果。通过与几种基线算法的对比实验,证明了框架的有效性;对各特征重要性进行分析,给出各特征对成绩影响程度的排序结果,对学生和教师调整学习方法与教学指导策略具有一定的现实指导意义。但由于实验所使用数据集数据量相对偏小,对预测性能的提升会有一定的影响。缺乏可用公共数据集,是学习预警研究工作中普遍面临的一个难题,因此,整理公共数据集,也是未来工作的方向之一。
