基于决策树的知识融合关键技术研究
2022-02-03贾丙静张振强
贾丙静,张振强
(安徽科技学院信息与网络工程学院,蚌埠 233000)
0 引言
大数据时代,网络中每天都会产生大量的文本、图片和视频等数据,这些数据来源多、规模大、表述不规范,为人们获取知识带来了极大的挑战。知识图谱[1]以图的形式帮助人们组织现实世界中杂乱无章的数据,实现客观世界的知识映射。它的基本组成单位是三元组<实体,关系,实体>,其中实体表示真实世界中存在的客观事物,如人、国家和公司等;关系则表示不同实体之间的某种联系,如某个影视明星和某个电影之间的主演关系,某个教师和某个课程之间的讲授关系等。目前比较流行的知识图谱有Wikipedia[2]、Freebase[3]、复旦大学的CN-DBpeida[4]和清华大学的XLore[5]等。知识图谱能够为语义检索、智能问答和情感分析等提供知识支撑,然而,知识图谱普遍存在不完备的问题,现实世界中知识是不断变化的,人们对世界的描述也在不断更新和修正。因此,为了更好地满足系统应用的需求,必须不断地对知识图谱进行知识扩充。早期的知识图谱通常依赖人工构建和扩充,不仅效率低而且成本极高,针对上述问题,拟从实体链接的角度进行知识扩充,将文本中挖掘的新实体链接到已有的知识库中。为了提高实体链接的效果,首先研究如何学习多源、多模态和异质的数据表示,并对这些特征进行筛选和融合;然后使用ID3决策树算法对待链接数据进行深层次分析,实验结果表明该算法能够去除噪音,将实体链接到知识库正确的候选上,从而达到知识扩充的效果。
1 研究现状
知识扩充是提高知识图谱完整性的重要手段,已发展成为自然语言领域新的研究热点。其主要目标是将网络中获取的新知识与知识图谱中已有的知识进行关联,更新到知识图谱中。目前文本中获取的实体与知识图谱中的实体的关系类别有两种,一种是在知识图谱中能找到映射实体,即通过实体链接[6]方法就可以扩充知识图谱;另一种是在知识图谱中不存在映射实体,需要通过实体分类[7]的方法进行知识合并。其中,实体链接获得了研究人员的广泛关注,主要包括单实体链接和集成实体链接两种方法。单实体链接表示在把实体链接到知识图谱的过程中不考虑同一文本中其它实体对其的影响,MPME 模型[8]认为实体的歧义会影响相同语义空间的建模,对于字面表达相同的实体采用同一向量表示显然是不全面的,因此联合文本和知识图谱为不同含义的实体学习不同的特征。
EAT模型[9]把文本中的实体和知识图谱中的实体放在同一个文本序列中,来学习对象的统一表示,避免单独学习后的重新对齐。集成实体链接在实现的过程中综合考虑上下文待链接实体之间的语义相关性,进行联合推断。基于网状结构的图可以表示对象之间的复杂关系,为集成实体链接提供了新的思路。REL-RW 模型[10]认为当前的主流方法对一些不知名的实体指称可能并不适用,由此提出在构建图时不仅要考虑知识图谱中实体之间的直接关联,还要考虑它们的间接联系,在信息论的基础上综合考虑所有候选实体的相关度。PPRSim[11]模型通过个性化随机游走结合整篇文档的语义特征能过滤掉非正确候选实体带来的噪音。但是,有些模型只考虑了部分特征,没用充分利用不同粒度级别的信息,为了改善链接的效果,需要使用各层次的信息,并对这些信息进行筛选。因此,分别使用词向量、先验流行度和编辑距离来学习待链接实体的词语级别、统计级别和文档级别的特征,然后基于ID3决策树算法对这些特征进行筛选,并预测最终的链接结果。
2 ID3决策树算法
2.1 基本原理
ID3算法属于有监督学习,通过构建树模型将数据分类,每次通过信息增益来选择划分的属性,即每次选择信息增益最好的属性,体现了属性与标签之间的函数映射关系。信息增益和信息熵是ID3算法中描述样本集合纯度的一种常用指标,假设当前样本集合S中第i个样本所占的比例是Pi,则S的信息熵可以表示为
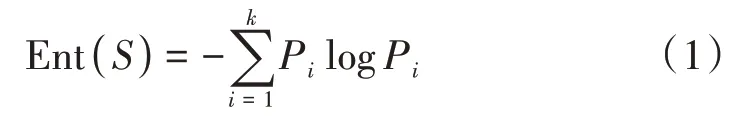
其中,k表示数据集S中样本预测结果的种类,Ent(S)越大,数据集S的纯度越高。
同样,设属性t还有W个可能的特征值t1,t2,…,tw,利用属性t对数据集S进行分类,将产生W个分支节点,其中第W个分支节点包含S中所有在属性t上取值为tw的样例,记为SW,然后根据公式(1)计算出信息熵。由于不同分支节点所包含的数据个数不同,给每个分支节点赋予一个权重 |S|,即数据个数越多的分支节点对预测性能影响越大,于是可以计算出属性t划分数据集S所获得的信息增益,其公式为
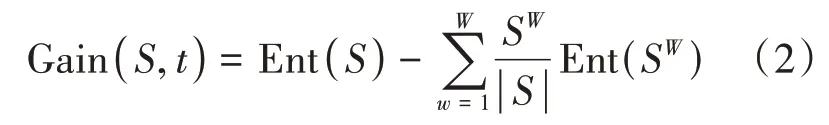
2.2 算法流程
对于给定数据集,每个样本上的属性可能有多个,不同属性对分类的作用有大有小,而决策树的实现过程就是不停地确定跟分类标签最相关的属性。ID3算法实现流程为:①对数据集进行预处理,初始化根节点包含所有的数据;②遍历所有的属性,选择信息增益最大的属性作为决策树的根节点,并将此属性删除;③根据根节点将数据分叉,在剩余的属性中递归地寻找每个分支的最优属性;④当决策树到叶子节点或者数据已经不需要再分,算法停止。
3 信息处理
3.1 实体嵌入
词嵌入通过词向量描述一个词,计算词与词之间的语义相似度。Le 等[12]认为如果一个词经常和另一个词一起出现,那么它们是相似的。然而,词嵌入模型忽略了短语或实体内在的意义。以Wikipedia 为例,候选实体之间是有关联的,锚文本和单词也可能同时出现在一篇文章中,这就为在同一连续空间中联合学习词和实体的嵌入提供了便利条件。最新研究表明通过学习实体和词的嵌入可以提高实体链接的效果,Yamada 等[13]先从Wikipedia中提取丰富的结构化信息,再设计Wikipedia2Vec 学习高质量的单词和实体嵌入。在训练词和实体向量时,从Wiki⁃pedia中抽取文本和锚文本,并基于链接结构测量候选实体对之间的关系,因此可以同时得到词和候选的嵌入。υ(m)和υ(e)分别表示文本中的实体向量和知识图谱中的候选实体向量,它们之间的相似度可以通过公式(3)的余弦相似度计算。
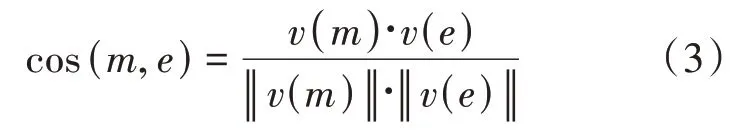
3.2 实体流行度
实体流行度表示实体的流行程度,它是基于知识图谱的一种统计特征。根据知识图谱中候选实体的超链接信息计算得到,在不知道上下文的情况下,观察候选实体是文档中实体链接对象的概率。例如,“李白”有90%的概率指向“李白(唐代著名浪漫主义诗人)”,10%的概率指向“李白(李荣浩演唱歌曲)”,参照文献[14]中的方法计算实体流行度。
3.3 实体上下文
实体本身的名字包含的字符信息比较少,表层特征差异性比较大,无法提供足够的证据进行链接。而围绕实体的上下文中含有一些关键信息,比如当实体“李白”的周围出现“诗词”或者“唐代”等信息时,就暗示该实体链接的对象是诗人“李白”而不是歌曲“李白”。另外,候选实体所在的背景知识图谱也提供了丰富的文本信息,可以基于编辑距离对待链接实体和候选实体的上下文语义关联度进行分析。编辑距离表示一个字符串转化为另一个字符串需要的最少编辑次数,可进行的操作有:替换、插入和删除,距离越小说明它们越相似,实体m和待链接候选实体e之间的上下文相似度可以通过公式(4)计算得到,其中max len(m,e)表示二者中的较长者。
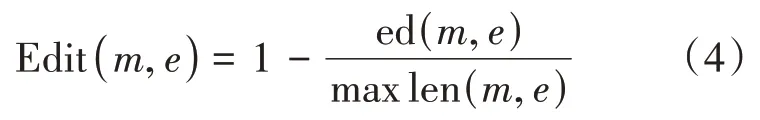
4 实验结果
背景知识图谱采用Wikipedia 官方网站提供的2016 年4 月版本,里面包含丰富的上下文描述文本,链接信息和类别信息等。同时,利用词向量工具wikipedia2vec 学习实体嵌入,维度是300。选择在AIDA 标准数据集上验证模型效果,它是Hoffart 等[15]在CoNLL2003 的基础上重新标注的,整个数据集包含1393 篇新闻文档,被划分为训练集AIDA-Train,验证集AIDA-A和测试集AIDA-B三部分。
利用精确率、召回率和F1 值来客观评估实验结果,只考虑在背景知识图谱中能找到对应链接对象的实体,假设T表示测试数据集中所有待链接实体在知识图谱中的正确结果集合,O表示决策树算法的输出结果,可根据公式(5)、(6)和(7)计算决策树算法在该数据集上的精确率(P)、召回率(R)和F1值。

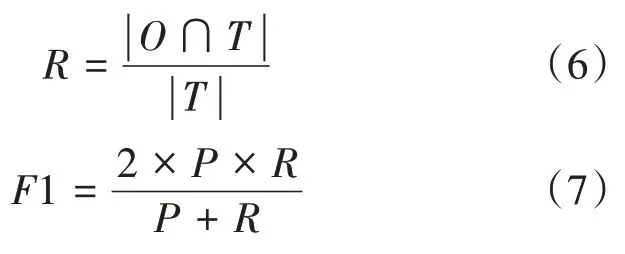
ID3是一种贪心算法,在构造决策树的过程中,除了计算特征的信息增益外,还要考虑树的深度影响,在用sklearn 包实现该算法的过程中,比较不同树深度下的精确率、召回率和F1值,结果如图1 所示,树的深度默认从3 开始,当深度为14 时整体效果最好,这时精确率P为0.74,召回率R为0.78,F1值为0.76。
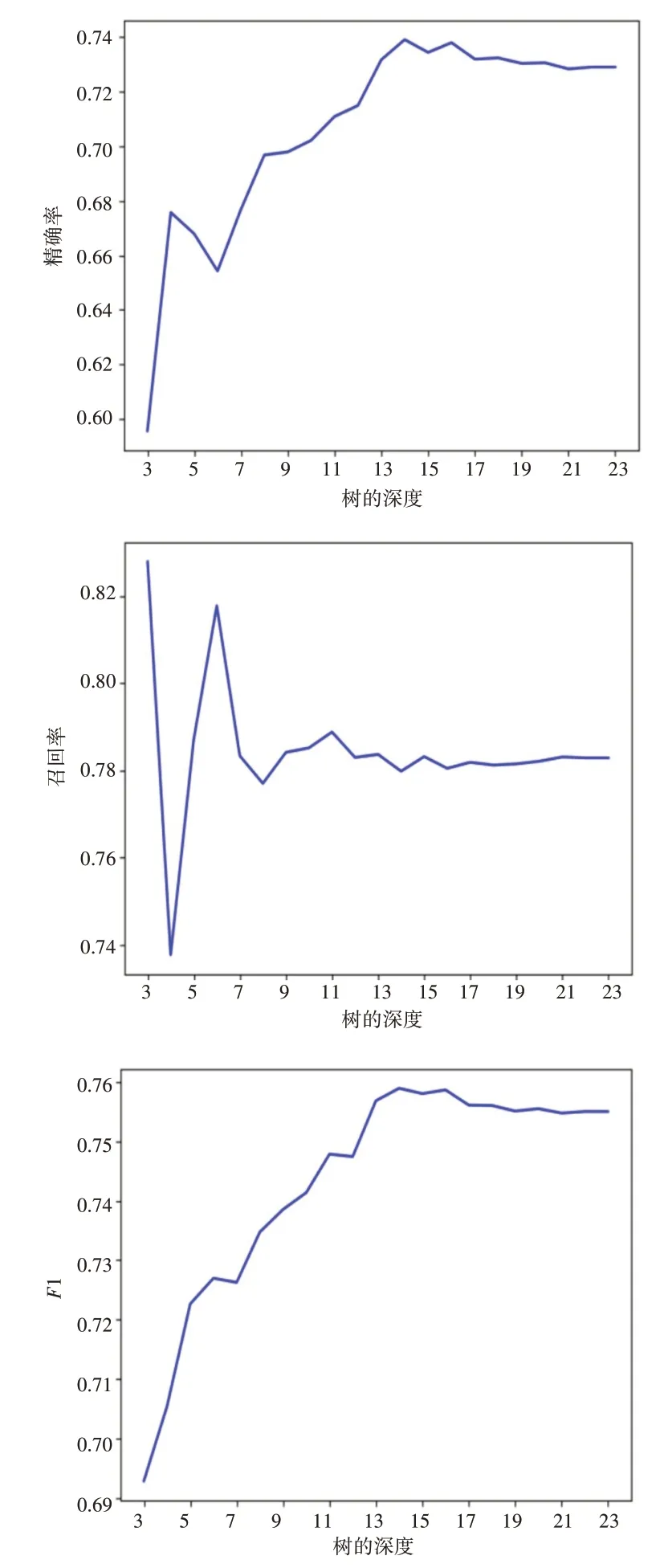
图1 不同树深度下的精确率、召回率和F1值对比
5 结语
随着人工智能和大数据的发展,网络上每天都会涌现新的知识,知识融合将新知识链接到已有的知识图谱中去,从而解决知识图谱不完整问题。ID3算法的核心思想就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行划分,该算法采用自顶向下的贪婪搜索遍历可能的决策空间。在此算法的基础上,研究实体嵌入、先验流行度和实体上下文特征如何将文本中的实体链接到知识图谱对应候选中去,从而完成新知识的融合。
