一种基于自注意力深度知识追踪和协同过滤的C++教学辅助方法
2022-02-03陈晨,刘娟,沈恂,郭城
陈 晨,刘 娟,沈 恂,郭 城
(蚌埠学院计算机与信息工程学院,蚌埠 233030)
0 引言
本校已开展C++慕课(MOOC)和网络习题平台作为教学辅助手段多年,新冠疫情更是让慕课和网课迅速发展,成为2020 年后的主流教学方式。教学过程中发现的主要问题有:学生知识水平不一,缺乏课堂教学实时反馈,教师难以根据薄弱环节及时调整,学生不易发现自己的知识薄弱点并有针对性地进行加强巩固。因此,急需一种可以帮助学生迅速定位知识薄弱点的方法。针对此种情况,我们在C++课程教学中引入了一种基于自注意力深度知识追踪和协同过滤的C++教学辅助方法,利用一种改进后的自注意力深度知识追踪算法SAINT-Lite 发现知识薄弱点,再结合协同过滤(Collaborative Filtering,CF)进行个性化习题。本文将这种方法称为SAINT-Lite-CF。
1 相关工作
知识追踪(Knowledge Tracing)是一个时间序列问题,根据学生过去的习题作答情况,预测未来的答题正确率,反映学生对知识点的动态掌握情况。贝叶斯知识追踪(Bayesian Knowl⁃edge Tracing,BKT)[1]是经典的非深度知识追踪方法。深度知识追踪(Deep Knowledge Tracing,DKT)[2]开创了深度知识追踪方法,主要结构为循环神经网络(RNN)和长短时记忆网络(LSTM),随后动态键值对记忆网络(Dynamic Key-Value Memory Networks,DKVMN)[3]之类的改进均基于RNN和LSTM。扇贝、英语流利说等大量网络教学平台广泛应用基于LSTM 的DKT算法进行知识追踪。DKT 的不足是需要海量数据,RNN和LSTM依次处理时间序列数据,训练时间长,难以应用到高校专业课程这种小规模教学上。Transformer[4]提出自注意力机制,对小数据集也有很好的性能,Transformer 结构实现了时间序列数据的并行处理,可以一次处理数十个甚至上百个时刻数据,大大提高训练和执行效率。SAKT(Self-Attention Knowledge Tracing)[5]是基于自注意力的第一篇知识追踪论文,使用习题(Exercise)和答案(Result)成对组成的交互(Interaction)信息,随后的SAINT(Separated Self-Attention Neural Knowledge Tracing)[6]和SAINT+[7]相对SAKT 的主要改进是引入编码器(Encoder)和解码器(Decoder),习题和答案信息分别进入编码器和解码器处理,实验表明这种方式性能更佳。本文工作主要基于SAINT展开。
2 方法
2.1 问题定义
令习题库总习题数为M,某学生从t1时刻到ti时刻做题序列定义为{I1,I2,I3,…,Ii},Ii为{Ei,Ri},其中:I 是Interaction(交互),表示在第i时刻学生的一次做题行为,E 是Exercise(习题),表示习题库中一道习题;R 是Result(答案),表示对应习题学生答案。知识追踪的任务是根据t1到ti时刻序列预测ti+1时刻学生回答所有习题正确概率,表示为一个M维向量,每1 位取值区间为[0,1]。
2.2 SAINT-Lite-CF模型介绍
相比DKT 论文中常用的Synthetic、ASSIST和STATICS 数据集,本文实际处理数据集规模较小,为避免模型过拟合和难以收敛,我们对SAINT 模型进行裁剪,将其称为SAINT-Lite。后续实验和实践证明,裁剪后的模型在处理小数据集时,可以获得较好性能。本文提出方法的整体结构见图1。

图1 SAINT-Lite-CF 主要结构
总体结构包括编码器、解码器和最后的全连接层。编码器的输出作为解码器的输入,解码器的输出作为线性层的输入。
编码器由一个习题嵌入层(Exercise Embed⁃ding Layer)和多个编码器层组成,习题和位置信息经过嵌入表示后分别生成d_model 维度向量,这些向量相加并输入习题嵌入层。每个编码器层由一个多头注意力运算模块、点式前馈网络(Point-wise Feed-Forward Networks)和层归一化组成,且每层在其周围有一个残差连接。点式前馈网络是全连接神经网络结构,目的是提高模型非线性能力。残差连接用于避免深度网络中梯度消失问题。
每个多头注意力运算模块有三个输入,分别是:Q(查询,Query)、K(主键,Key)、V(数值,Value),其计算过程分成四个步骤:QKV线性层分拆成多头,按照比例缩放的点积注意力多头级联(Concat),最后一层线性层。以上过程用公式表示为

其中Mask是上三角掩膜,FFN是点式前馈网络。
解码器由一个答案嵌入层(Result Embed⁃ding Layer)和多个解码器层组成,答案和位置信息经过嵌入表示后生成d_model维度向量,这些向量相加并输入答案嵌入层。每个解码器层由两个多头注意力运算模块、点式前馈网络和层归一化组成,第二层多头注意力模块的V和K接收编码器输出作为输入,Q接收第一层多头注意力模块的输出,每层在其周围同样有一个残差连接。解码器关注编码器的输出及其自身输入(自注意力),来预测下一个时刻做题的正确概率。
嵌入表示后的习题矩阵分别作为Q、K、V输入编码器(各自权重不同),输出O分别作为V、K(各自权重不同)输入解码器的第二层多头自注意力模块。嵌入表示后的答案矩阵分别作为另一套Q、K、V(各自权重不同)输入解码器。Q是解码器第一层多头自注意力模块的输出。编码器过程用公式表示为

X在第一个编码器层是习题嵌入层输出,其余编码器层是上一个编码器层的输出,Oenc是编码器输出,LayerNorm 是层归一化。解码器过程用公式表示为

X在第一个解码器层是答案嵌入层输出,其余解码器层是上一个解码器层的输出,Odec是解码器输出。解码器的最后输出经过一个全连接层,采用Sigmod 激活函数,输出每个知识点掌握情况,并映射回所有习题正确概率。
2.3 学生知识水平向量/矩阵
令共有I个学生,习题库共M个习题,N个知识点,习题同知识点是多对多关系,Km表示第m个习题对应的N位一维知识点向量,每位取0 或1,K为所有习题对应知识点的M×N矩阵。SAINT-Lite 输入时只使用主要知识点ID,输出N维向量SKi,表示第i个学生所有知识点掌握情况,以主要知识点ID 预测结果表示习题ID 预测结果,将N维向量映射回M维,令其为SEi,所有学生向量组成I×M的答题正确概率矩阵SE。用答题正确概率矩阵点乘所有习题对应知识点矩阵,即SE×K,归一化后得到所有学生知识水平矩阵Y。令Yi表示第i个学生的知识水平向量,Yij表示第i个学生对第j个知识点的掌握情况,则KPj为第j个知识点均值:
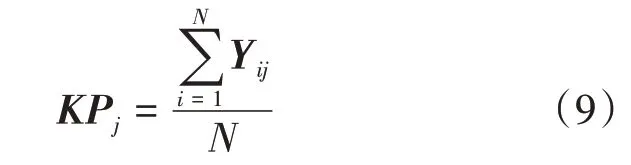
所有KPj组成N维知识水平均值向量(KP1,KP2,KP3,…,KPN),对KPj小于阈值(本文取0.5)的知识点向教师进行教学预警,表明此知识点是共性的薄弱环节,教师应进行集中复习讲解,对特定学生KPj过低的知识点向该学生提示重新学习课程。
2.4 个性化习题推荐
获得学生答题正确概率矩阵后,使用协同过滤来进行个性化习题推荐。协同过滤目前广泛应用于电子商务网站的商品推荐,其本质思想是找到与当前目标类似的目标群体,即找到水平接近的学生近邻集合,预测学生对没有做过习题的得分水平。令全体学生答题正确概率矩阵为U,Ui表示第i行,为第i个学生的答题正确概率向量,则Uj为第j个学生的答题正确概率向量,遍历所有行,以余弦相似度判断Ui和Uj相似度:
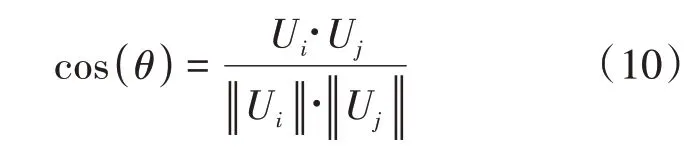
得分大于一定阈值(本文取0.9)的作为相似学生。根据马骁睿等[8]提出的方法计算第i个学生的习题得分向量为

average(NUi)表示同第i个学生相似学生答题正确概率向量的平均值,p取值0 到1,用于调节相似学生对于习题得分向量的影响力,p为1时,习题得分向量完全退化为答题正确概率向量。向学生推荐预测得分在某个区间的习题,对于预测得分过低甚至为0 的习题和学习内容,本文认为这样的内容学生完全没有掌握,应重新学习而不是直接做题。
3 实验
3.1 数据集
使用两个公开数据集ASSISTments 2009(以下简称ASSIST)、STATICS 2011(以下简称STATICS)和一个本文数据集来验证习题。ASSIST 收集自ASSISTments 教育平台2009 年数据,为高中数学题,对应124个知识点,包含了4217 名学生共525535 次答题记录。STATICS 收集自大学工程力学课程,对应1223 个知识点,包含了333 个学生共189927 条答题记录。本文数据集来自本校已使用多年的C++网络习题平台,共1374 道习题,对应173 个C++知识点,采集自2018 年和2019 年不同专业532 人共32843条答题记录。为使ASSIST、STATICS 数据规模同本文数据集接近,从ASSIST、STATICS中分别抽取一段时间内数据,处理后所有数据集具体信息见表1。数据分布上,ASSIST 更接近本文数据集,将其称为稀疏数据集,将STATICS称为稠密数据集。
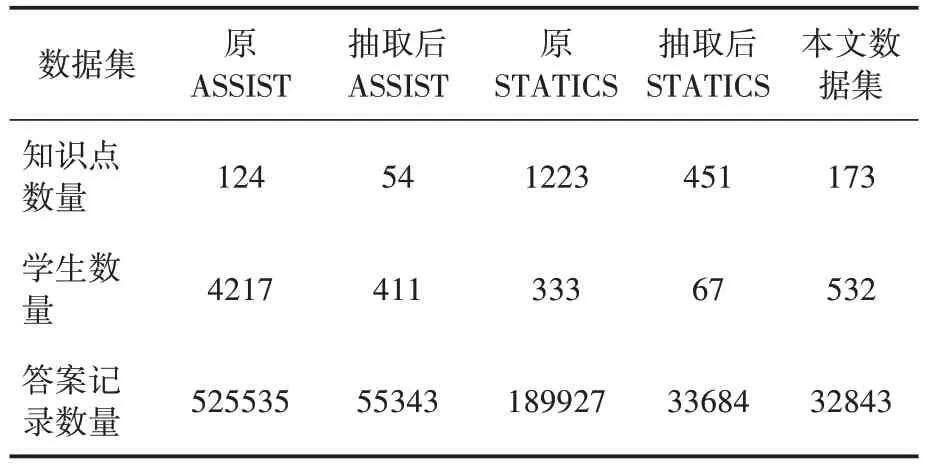
表1 所有数据集信息
3.2 系统实现细节
训练在i7 CPU、16 G 内存、GTX 2060 显卡的机器上进行,使用PyTorch 框架实现,使用Adam 优化器,学习率0.001,迭代次数100 次。数据集根据学生按照8∶2 的比例分为训练集和测试集。
本文数据集中包括以下几项特征:练习题ID,对应的一个主要知识点ID,对应的多个附属知识点ID,学生答题结果。习题的特征包括习题对应的主要知识点ID、位置信息。答案的特征包括回答正确与否(取值0 或1)、位置信息。先预处理数据集,得到每个学生对应答题序列,此时只使用主要知识点ID,将此序列转换为知识点独热(one-hot)编码和答案独热编码。模型一次并行处理windows_size 个时刻数据,舍弃所有做题数目不超过windows_size 的学生数据,超过windows_size 的分拆后分批处理,分拆后不足window_size部分舍弃。
所有特征各自嵌入表示降为d_model维,再求和。由于习题和答案位置一一对应,两者共享同样的位置编码。位置编码用于保留因并行处理丢失的序列信息,即学生做题先后顺序,反映学生知识技能动态掌握程度。
答案的输入比习题的输入推迟一个时刻,即在一次训练迭代中,编码器输入window_size个时刻的习题信息,解码器输入只有win⁃dow_size-1 个时刻的答案信息,最后输出win⁃dow_size个r_,使用上三角掩膜避免模型在使用习题信息预测t时刻答题正确概率时参考t时刻之后的答案信息。训练时候使用最小化二分类交叉熵损(Binary Cross Entropy Loss)作为损失函数,计算输出和标签的误差并执行反向传播,优化模型参数。推理时只关注最后时刻输出的r_。
3.3 超参数选择实验
超参数n是解码器/编码器层堆叠数(多头自注意力模块重复次数),SAINT 取4,分别设置n为2 和4 进行消融测试。深度知识追踪一般使用准确率(Accuracy,ACC)和受试者工作特性(ROC)曲线下面积(Area Under the Curve,AUC),ACC为正确预测结果占全部结果的百分比,AUC被定义为ROC 曲线与下坐标轴围成的面积,两个指标均是越高,说明模型性能越好,具体计算方法见SAINT/SAINT+论文。结果见表2及图2。

表2 超参数n的不同取值对ACC和AUC的影响

图2 超参数n的不同取值对ACC和AUC的影响
n为4 时,在STATICS 上AUC和ACC均升高,表现变好,ASSIST 和本文数据集上AUC和ACC均降低,表现变差。n为2 时,在STATICS上表现变差,ASSIST和本文数据集上表现变好。本文认为n为4 更适合STATICS 类的稠密数据集,n为2更适合ASSIST和本文数据集类的稀疏数据集。本文系统实际应用中n取2。
超参数d_model是每个编码器层或解码器层输入或输出的维数,SAINT 取256 和512,分别设置d_model 为64、128 和256 进行消融测试。结果见表3及图3。
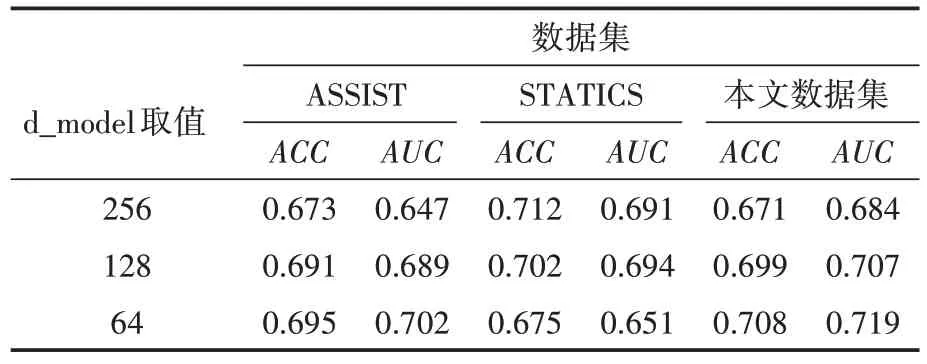
表3 超参数d_model的不同取值对ACC和AUC的影响

图3 超参数d_model的不同取值对ACC和AUC的影响
纵向比较,随着d_model 取值增大,在STATICS 上ACC和AUC均升高。在ASSIST和本文数据集上,当d_model 是64 或128 时,ACC和AUC 差别不大,甚至在d_model 为256 时,ACC和AUC 均出现下降。横向比较,d_model 为256或128 时,在STATICS 上ACC和AUC均升高,表现变好;ASSIST 和本文数据集上ACC和AUC均降低,表现变差。d_model为64在STATICS上表现变差,ASSIST 和本文数据集上表现变好。我们认为d_model 为64 即可处理ASSIST 和本文数据集类的稀疏数据集,更高的取值适合STATICS 类的稠密数据集。本文系统实际应用中d_model取64。
超参数window_size 表示模型一次处理几个时刻的数据,本文取100。超参数h表示多头注意力机制头(head)数,SAINT 中取8,本文取2,即64 维(d_model 维)的QKV 被拆分成32 维进行注意力计算。训练时的超参数batch_size,表示模型在一个时刻处理几批数据,本文取16。所有超参数最终取值见表4。

表4 所有超参数及取值
3.4 同其他知识追踪模型比较实验
本实验使用Paper with code 网站上开源的DKT、SAKT 和SAINT 在PyTorch 下实 现,将三种数据集在四种模型上重新训练测试。评测指标为ACC、AUC和RMSE(Root Mean Squared Er⁃ror)。RMSE被定义为预测值与真实值的均方根误差,其值越低,说明模型性能越好。结果见表5及图4。

图4 DKT、SAKT、SAINT和SAINT-Lite在ACC、AUC、RMSE上的得分对比

表5 SAINT-Lite同DKT、SAKT和SAINT的对比
在ACC和AUC这两个评测指标上,SAINTLite 在ASSIST 和本文数据集下表现比DKT 和SAKT 要好,比SAINT 略差,但在STATICS 下表现较差,仅比DKT 稍好,比同样使用自注意力机制的SAKT 和SAINT 均差。在RMSE 这个指标上,SAINT-Lite 在ASSIST 和本文数据集下表现最好,在STATICS 下表现同样较差,仅比DKT稍好。我们认为这是由于STATICS 知识点较多,简化模型结构使得系统不能很好拟合这种复杂数据,但是对于小数据集,裁剪后的结构也可以获得较好的性能,其结果是可信的,可以用于教学预警和后续的习题推荐。
3.5 个性化习题推荐实验
一些论文或者系统使用答题正确率来衡量推荐习题质量,本文认为这不符合实际,极端情况下推荐最简单的习题必然都是正确的。本文通过判断答题正确率是否符合期望来验证习题推荐效果,将习题推荐难度平均分为五个区间,使用三个测试集中每个学生的200次答题记录推荐50 题,并计算推荐习题的实际答题正确率,结果见表6。

表6 不同难度区间推荐习题的实际答题正确率
表6数据表明,基于STATICS训练模型的习题推荐有部分实际正确率未落在对应区间内,再次说明本文使用的解码器/编码器堆叠层数2不能很好拟合STATICS 这种知识点较多的复杂数据,而基于ASSIST 和本文数据集训练模型的习题推荐所有实际正确率都落在对应区间内,表明实际应用中SAINT-Lite-CF 的推荐结果是可信的。
3.6 实际应用
本校C++一学期共16 周课程,从第2 周开始,除共同课后作业外,向每个学生进行个性化习题推荐,推荐区间为[0.6,0.8)。统计全体学生每周所有习题的平均正确率,结果见图5。

图5 全体学生16周内所有习题的平均正确率
横轴为周次,纵轴为平均正确率,图中出现两次较明显的平均正确率下降,分别是第2周和第8 周,原因是第1 周主要复习C 语言内容,第2 周开始教学C++新内容,第8 周和第9 周开始教学继承和多态。这两周均有大量重点难点内容,学生初期掌握不好,通过个性化习题推荐和教学预警后教师针对薄弱知识点的补强,提升了学生的平均正确率,其效果反映在预测和多次真实考试中,最后的期终考试也取得了师生满意的成绩。
4 结语
本文提出的SAINT-Lite-CF 方法在C++教学实践中起到了很好的辅助作用,帮助学生和教师快速定位薄弱知识点,进行教学预警和个性化习题推荐。受平台限制,SAINT-Lite 使用的特征没有考虑时间对知识遗忘的影响,后续可以改进本校C++网络习题平台,收集学生做题相关的时间信息用于训练,提高模型对学生知识水平的拟合和表达能力。本文方法应用协同过滤较简单,后续可以考虑更复杂的个性化习题推荐算法。本文使用2018 年和2019 年积累的数据来预测2020 年,后续会扩充数据集,继续辅助C++教学。
