Apache ZooKeeper设计理念和数据结构的研究
2022-02-03索海燕
陈 涛,索海燕
(1.毕马威信息技术服务(南京)有限公司,南京 210003;2.南京医科大学第一附属医院(江苏省人民医院)信息处,南京 210096)
0 引言
在传统的计算机行业中,开发人员通常擅长开发单机程序,却很难高效地开发出多个独立程序协同工作功能。这是因为开发这种协同技术是非常困难的,很容易导致开发者投入大量的时间考虑协同工作的业务逻辑,而没有时间更好地处理并实现应用程序的业务逻辑。
Apache ZooKeeper 是基于分布式计算的核心概念设计的,中心化的管理方式,提供了注册中心和配置中心,旨在解决分布式框架数据一致性的难题。分布式系统的核心要素就是构建中心化平台,集群中每个子节点都需要通过中心化平台保障数据的最终一致性。ZooKeeper 一词的本意是“动物园管理者”,原因是Apache基金会有多个以动物名称命名的框架,这些框架都需要中心化服务。ZooKeeper 最初由知名互联网公司雅虎创建,该项目最早起源于雅虎研究院的一个研究小组。当时雅虎研究人员发现,雅虎内部很多大型系统都需要依赖一个分布式协调系统,但是这些系统存在分布式单点问题。开发人员尝试开发了一个无单点问题的通用分布式协调框架,利用该框架后业务开发人员可以将精力全部集中在处理业务逻辑上。本文深入研究ZooKeeper内核数据结构的原理。
1 ZooKeeper设计理念
分布式领域有一个著名的“拜占庭将军问题”[1],它是由Lamport 等人在1982 年提出的。“拜占庭将军问题”描述了这样一个场景:拜占庭帝国有许多支军队,不同军队的将军需要共同制定一个统一的军事计划,用于做出进攻或者撤退的决定。这些将军因为地理隔离原因,需要依赖通信员进行通信。但是,通信员之中可能会存在叛徒,这些通信员叛徒可以任意篡改军事信息,从而欺骗将军。
“拜占庭将军问题”在分布式计算领域引发了探讨[2]。从理论上来说,在分布式计算领域,试图在异步系统不可靠通道上达到一致性状态是不可能的。通常在对一致性的研究过程中,都需要一个前提假设:通信通道是可靠的。但在实际应用中,网络波动和硬件故障很容易造成消息不完整,或被恶意程序篡改。为了保障消息的最终一致性,学者们提出了多个定律或理论。
分布式领域有一个很著名的CAP 定律[3]:一致性(consistency)、可用性(availability)和分区容忍性(partition-tolerance)。任何一个系统都不能同时满足这三个要求。对于网络分区(network-partition),为了避免脑裂(split-brain)问题,即从节点无法与群首节点通信时,与第二个群首节点建立主从关系。ZooKeeper 在脑裂场景下,从节点为只读状态,从而保证不会产生多个主从关系集群。ZooKeeper 的设计理念可以保证一致性和可用性。
此外分布式领域还有一个BASE 理论[4],它是基本可用(basically available)、软状态(soft state)和最终一致性(eventually consistent)的简写。核心思想是即使无法做到实时一致性(强一致性),也能够采用一定的同步机制来保证系统最终达到一致性的效果。这也是对CAP 定律一致性和可用性进行权衡的结果[5]。ZooKeeper 巧妙地使用了一种称为Zookeeper 原子广播(Zoo⁃keeper atomic broadcast,ZAB)的协议保障数据的最终一致性,使得其成为分布式系统的奠基石。
ZooKeeper 集群采用了中心化设计理念和最终一致性算法,本质上和分布式数据存储系统原理相似。其数据结构是模仿文件系统设计的,数据结构是一个带有根节点的目录树。其中每个节点被称为Znode,每个Znode 都对应着唯一的路径,并默认能够存储大小为1MB 的二进制数据。下面以Apache Dubbo 对接ZooKeeper 生成的服务提供目录为例展示中心化设计理念,如图1所示。
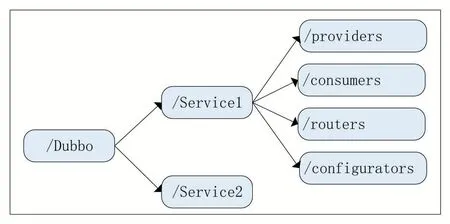
图1 Apache Dubbo生成的服务提供目录
如图1所示,Apache Dubbo在启动时会根据用户配置在ZooKeeper注册中心创建四个Znode:/providers、/consumers、/routers 和/configurators。每个节点的路径由父节点和服务名组成,例如,第一行的/providers 节点对应的路径是/dubbo/ser⁃vice1/providers。
采用中心化设计理念的分布式系统,可以利用ZooKeeper实现如下五种需求。
(1)为分布式集群提供中心化配置功能,例如负载均衡配置、异常场景策略配置。此外还支持热更新,监听某个路径的状态,在不重启程序的前提下,修改配置参数并立即生效。
(2)为分布式集群提供节点动态发现与异常监控机制,例如RPC 提供者向注册中心同步自己的服务状态,注册中心实时监控提供者的异常情况,并及时通知服务消费者。节点的动态拓展功能指的是新节点能够获取集群其他节点信息。某节点故障宕机后,集群中其他节点可以获取通知并实现故障恢复。
(3)为分布式集群提供主从集的集群管理,支持Raft 协议群首节点投票选举功能,是绝大多数分布式系统主从集的核心功能。
(4)提供分布式锁,支持公平锁和非公平锁,提供分布式队列。提供分布式计数器、分布式多线程同步器。支撑客户端实现群首选举设计模式。
(5)提供发布/订阅设计模式的实现方案。
2 ZooKeeper数据结构
ZooKeeper 命名空间内部拥有一个树状的内存模型,其中各节点被称为Znode。每个Znode包含一个路径和与之相关的元数据[6],以及该Znode 下关联的子节点列表。ZooKeeper 内核设计原理都是围绕着Znode 展开的,Znode 在Zoo⁃Keeper中所起的作用如图2所示。
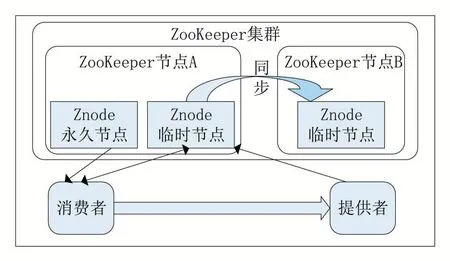
图2 Znode实例
如图2 所示,提供者向ZooKeeper 节点A 创建了Znode临时节点,用来保存其地址和接口等信息。服务消费者从Znode临时节点获取对应的地址等信息,从Znode永久节点获取负载均衡路由策略等信息,最后直连提供者发起请求。同时服务消费者监控Znode 临时节点,及时获取提供者在线状态信息。ZooKeeper 节点A 通过ZAB 协议同步Znode 临时节点数据到ZooKeeper节点B。
每个Znode都对应着一个唯一路径,并存储默认1 MB 的二进制数据,格式为字节数组(byte array)。ZooKeeper 不直接提供序列化和反序列化的功能,通常使用客户端序列化工具进行解析操作。Znode 可以通过配置增大存储数据容量,但通常不建议这么做,如果存储的数据容量比较大,客户端拉取时会面临着网络带宽的压力,ZooKeeper 主从集同步数据也会有带宽压力。如果真有这方面的需求,可以考虑把数据保存在支持事务的数据库里,例如MySQL 把数据的主键更新在Znode上,实现大容量数据的实时同步。此外,因为临时节点在创建者会话失效时会被删除,所以ZooKeeper 不允许临时节点拥有子节点,临时时序节点同理。如果需要创建子节点,可以考虑父节点采用持久节点或者持久时序节点来实现。ZooKeeper 将全量Znode数据保存在内存中,用此来增加服务器的吞吐量。这种机制导致了ZooKeeper 特别适合以读操作为主,不涉及事务的请求处理。
原语操作列表API 在扩展操作列表时需要新增API,频繁更新API 将会降低服务的灵活性。为了保障服务的灵活性,ZooKeeper 提供给客户端可调用的API,用于文件系统的操作,既实现了对Znode 的操作,又保障了API 的长期稳定运行。
每个Znode 都有一个版本号,当对Znode 执行修改或删除操作时,都会导致版本号增加。所以对Znode 的并发修改可以保证有顺序地执行,因为每次调用API 传入的参数包含版本号,只有当参数版本号与ZooKeeper 服务器上的版本号一致时,修改或删除操作才会执行成功。当多个线程同时对一个Znode进行操作时,版本号就能保证操作的原子性和可见性。ZooKeeper API支持用户设置成禁用版本号检查。版本号的设计和JDK 的AtomicStampedReference 采用long类型时间戳控制版本号,保障比较并交换(CAS)原子操作的原理相似。图3 为Znode 使用版本号来控制并发操作的示意图。
如图3 所示,客户端1 发起修改请求,把版本号1 当作参数,如果版本号等于1,就设置/path 路径Znode 的值为A。服务端接收到请求后,设置Znode 的值为A,并把版本号加1,此时服务端版本号为2。客户端2 获取版本号为2的Znode值,然后向ZooKeeper服务端发起请求,把版本号等于2当作参数。服务端通过版本号校验,把Znode 值设置成了B,并把版本号加1,此时服务端版本号为3。客户端1 发起修改请求,把版本号2 当作参数,但是此时ZooKeeper服务端的Znode 版本号为3,所以版本校验不通过。ZooKeeper 服务端直接返回操作失败异常。通过图3的示例可以看出版本号机制可以有效地控制并发修改问题,保证操作的原子性。

图3 Znode版本号机制
Znode 上保存的版本号本质上是Stat 类型的对象属性,该对象保存了节点的属性信息。Stat对象主要包含了上次更新的时间戳(ZooKeeper transaction ID,zxid)以及拥有的子节点数量。实际业务中,ZooKeeper 管理版本号时,并不是使用单纯加1的操作,还要利用事务的机制,将事务中的版本号zxid 更新Znode 的版本号。Zxid 是ZooKeeper 服务端处理事务最重要的组成元素,zxid 是64 位long 类型整数,前32 位表示时代标识Epoch,后32位表示操作序号counter。
3 监视点与通知
客户端可以对Znode 设置监视点(watcher),当Znode 状态发生变化时,ZooKeeper 对客户端发出对应的事件通知,又称基于通知(notifica⁃tion)的事件消息机制[7]。简而言之,就是对Znode 绑定了一个状态监视机制。监视点是单次触发的操作,一个监视点只能触发一个通知。
对一个Znode 的操作,ZooKeeper 先向客户端传送事件通知,然后对该节点进行变更操作。这里的Znode操作是一个事务,客户端不需要担心收到通知后,再获取的数据有问题。Zoo⁃Keeper 管理的API 均可在Znode 上设置监听点,监听其读写操作,如Exists()、GetData()、GetChildren()。
ZooKeeper 移除监视点的方法有两个,一是触发这个监视点事件通知;二是客户端会话关闭或超时,监视点通知无法发送,导致监视点移除。监视点触发的事件通知不包含变更的Znode 数据。客户端在获取事件通知以后,仍然需要主动调用GetData API 获取变更的数据。当然这个操作并不是原子性的,获得通知和拉取数据的过程中Znode数据可能会被再次修改。监视点事件通知的详细过程如图4所示。
在图4 中,客户端1 创建Znode 数据为A,并设置监听点。客户端2 更新Znode 数据为B,并触发监听点NodeDataChanged。此时,Zoo⁃Keeper 先通知客户端1 数据变更,再通过ZAB协议通知集群数据为B,并修改群首持久化数据。客户端1 接收到只是变更通知,仍需发起GetData 请求获取Znode 数据,客户端1 获取数据的过程中,客户端2 又更新Znode 数据为A。结果客户端1 获取Znode 数据仍然为A。客户端1 再次对Znode 设置监听点。虽然客户端1 使用监听点,没有获取数据B,出现了ABA 的问题,但是监听点机制能够保证数据的最终一致性。这里获取Znode 数据和设置监听点是同一个API请求(GetData API)。

图4 监视点事件通知
服务端监听点的信息全部保存在内存中,每个监听点大约占用0.3 KB 内存,监听点不会存到硬盘上。因为当服务端发现客户端连接断开时,判断出无法给客户端发送监视点通知,就会把内存中失效的监视点删除。之所以客户端重连后监视点仍旧生效,是因为客户端本地保存了监视点数据,重连后同步服务端启用对应的监视点。
客户端重连成功后,会将全部未触发的监视点列表发送给服务端。服务端接收并检查该列表,如果部分Znode在客户端上一个会话注册监视点之后就已经更新了,那么服务端将直接把对应的监视点通知事件发送给客户端,其余监视点重新在服务端上注册。服务端通过对比Znode 修改zxid 包含的时间戳,就能判断未触发监视点列表Znode是否已经更新。
除此之外,还有一种可能导致ABA 的问题场景,假设Path 路径的Znode 不存在,客户端A调用Exists API 监听该路径是否存在,如果此时客户端A 突然断线,在客户端A 断线期间,客户端B 创建了Path 路径的Znode,很快Path 路径的Znode 又被删除了。Path 删除后,客户端A 重新连上了,但是此时客户端A 无法感知Znode是否存在过。客户端A 没有收到对应监视点通知,仍然会将全部未触发的监视点列表发送给服务端。这种ABA 问题无法避免,所以业务上应尽量规避这种场景。
4 ACL权限控制
ZooKeeper 提供的安全机制,是通过访问控制表(access control list,ACL)来实现访问权限控制的。权限控制表ACL 绑定在每个Znode 上,且子节点不会继承父节点的权限,父、子节点的权限相对独立。如果客户端没有父节点的权限,在子节点没有设置权限的情况下,客户端可以直接访问子节点,所以需要分别设置父、子节点权限。ACL 权限控制方式也被应用在Linux和Unix文件系统中。
ACL 定义了Read、Write、Create、Delete、Admin共五种Znode操作的权限。Read权限用于获取当前节点数据权限,获取子节点列表权限。Write 权限用于更新当前节点权限。Create 权限用于创建子节点权限。Delete权限用于删除子节点权限。Admin 权限用于设置节点ACL 列表的权限。
访问权限的检查是基于每一个Znode 的,ACL 权限控制包含两个方面,一是ZooKeeper 服务端内置的ACL 鉴权模式;二是客户端请求服务器提交的鉴权信息。客户端请求携带的鉴权信息数据结构是根据ZooKeeper 服务端采用的鉴权模式来匹配的,格式是scheme:auth-info,即“鉴权模式:鉴权信息”的格式。通常客户端进程可以在任何时候调用addAuthInfo 来提交鉴权,只有IP 鉴权模式不需要该操作。常用的鉴权模式包括world 鉴权模式、digest 鉴权模式、IP 鉴权模式、自定义鉴权模式、SAS鉴权模式、super鉴权模式共六种。
