基于多源传感器与导航地图的端到端自动驾驶方法
2022-02-01张纪伟谈东奎胡旭东
朱 波,张纪伟,谈东奎*,胡旭东
(1.合肥工业大学 汽车工程技术研究院,合肥市 230009,中国;2.合肥工业大学 智能制造技术研究院,合肥市 230051,中国)
自动驾驶技术能够有效缓解交通拥堵现状,减少交通事故的发生,是未来汽车工业发展的必然趋势[1]。传统的基于规则的自动驾驶技术通常将自动驾驶解决方案划分为感知、决策、控制3 个部分[2]。这种方法的特点在于各模块之间分工明确,系统有明确的规则设定,可解释性较强。然而,该方法也存在着系统结构复杂、设计开发难度高、过渡依赖人工规则等缺点,同时在遇到设定之外的情形时,系统难以有效建模并快速做出决策[3]。而基于深度神经网络的端到端自动驾驶系统,通过采用监督学习或无监督学习的方法模仿人类驾驶员的驾驶行为,建立感知输入与车辆控制之间的直接映射关系[4]。
“端到端(end-to-end)”指“传感器数据输入端”到“车辆控制命令端”。经过特定的数据训练后,端到端自动驾驶系统能够直接根据获得的摄像头、激光雷达(激光探测及测距系统,light-laser detection and ranging,LiDAR)等传感器信息,映射输出自动驾驶车辆控制所需要的方向盘转向角、速度等控制命令。
D.A.Pomerleau 提出了Alvinn 模型[5],证明了经过专门训练后的端到端神经网络能够在公共道路上自主驾驶车辆。Y.LeCun 等人[6]将端到端神经网络用于自动导向车辆(automated guided vehicle,AGV),使其能够在野外自由避障。NVIDIA 公司(英伟达公司)提出了基于深度卷积神经网络(convolutional neural network,CNN)的PilotNet 模型[7],该模型通过已训练的神经网络模型将左、中、右3 个摄像头输入的图像直接映射为控制车辆的转向角,在多种道路上取得了较为满意的结果,证明了CNN 强大的图像特征提取能力,但该模型在遇到交叉路口时就会失去前进方向,无法继续行驶。XU Huazhe 等人则提出长短期记忆全卷积网络(long short term memory fully convolutional network,LSTM-FCN)模型[8],通过大规模的驾驶视频数据完成神经网络训练,提高了模型的理解能力,实现了对离散或连续驾驶动作的预测。文献[9]则在端到端模型中引入了视觉注意力机制,以关注图像重要信息和减少冗余信息,进一步提高了模型的预测精度。文献[10]针对交叉路口问题提出了使用导航指令的方式,即在路口处通过向前、向左、向右的导航指令引导车辆通过交叉路口,间接解决了交叉路口通行的问题。A.Sallab 等人提出将深度强化学习方法应用于端到端自动驾驶模型[11],并在开源赛车模拟器(the open racing car simulator,TORCS)上完成了网络模型智能体的训练,并取得满意结果。此外,其他研究也表明[12-13],将强化学习应用于端到端驾驶动作预测能够取得较好的结果。
现有的端到端自动驾驶方法多以摄像头为主[14],受光照、雨水等天气影响较大,且由于摄像头视角有限,使得多个摄像头融合后图像信息量较大,导致神经网络结构规模倍增,模型训练速度变慢,且占用大量的计算资源。更重要的是,现有研究方法主要体现在车道保持方面,而关于主动避障行驶和交叉路口通行等任务的端到端自动驾驶研究相对较少。
为此,本文提出了一种基于多源传感器与导航地图的端到端自动驾驶决策模型。该模型的输入由单目前视摄像头、360°多线激光雷达投影处理后的二维俯视图、精准定位后截取的局部导航地图3 部分组成,输出为汽车方向盘转向角。经过数据集迭代训练后,该模型不仅能够实现跟随车道线行驶的车道保持功能,而且能够在遇到障碍物时控制车辆完成局部避障任务,并在遇到Y 字型交叉路口时根据导航信息驶入指定车道。为验证所提出的端到端自动驾驶模型的有效性,在常规的仅有视觉图像输入的端到端模型的基础上,通过逐步添加不同的网络分支进行对比分析,验证了LiDAR 俯视图与局部导航地图网络分支的加入对基础端到端决策模型功能扩展的有效性。
1 端到端决策模型设计
1.1 端到端决策模型架构
所提出的基于多源传感器与导航地图的端到端决策模型为多输入单输出模型,其输入分别由单目前视摄像头、LiDAR 俯视图以及局部导航地图3 部分组成,经过特征提取网络处理并融合特征后输出下一时刻期望的方向盘转向角。采用递进式方法逐步验证所提出模型的可行性,分别建立了Model-A、Model-B、Model-C 3 种端到端决策模型如图1 所示。其中,Model-A 为最基本的端到端决策模型,能够实现基础的车道保持功能;Model-B 则是在Model-A 的基础上增加了LiDAR 俯视图网络分支,主要用于实现车道保持与局部避障行驶功能;而Model-C 则是进一步的增加了局部导航地图分支,通过引入导航信息使得车辆经过路口时能够根据指示信息驶入正确车道,其是本文所提出的核心模型。
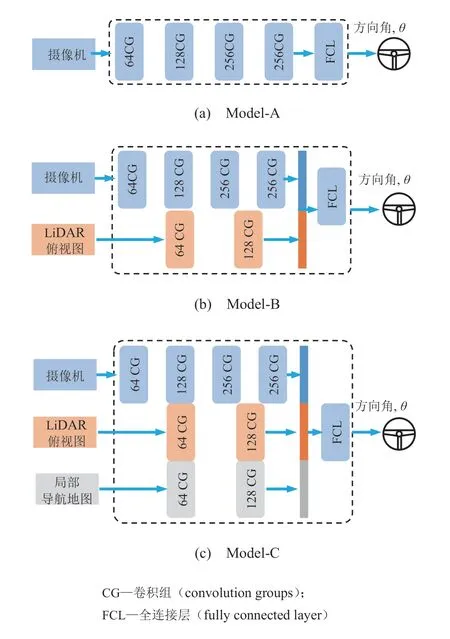
图1 3 种端到端决策模型架构
可见,Model-C 为三输入模型,每个输入分别在模型中承担着不同的角色:前视摄像头主要用于车道线和障碍物识别,使车辆能够具有车道保持和基本避障能力;由于单摄像头的视野有限,故LiDAR 俯视图可用于弥补摄像头的视角不足问题,使得车辆在避障过程中不会因视野丢失导致避障功能失效,辅助实现车道保持与局部避障功能;局部导航地图则主要用于引导车辆通过交叉路口时按照导航信息选择指定的路口,并顺利驶入该路口。Model-C 模型通过融合不同传感器输入的关键图像特征信息,最终输出方向盘转向角的预测值,实现对车辆横向运动的端到端控制。
卷积神经网络中,利用权值共享与局部相关性,减少了网络的参数数量,提高了训练效率,常用于对图像关键特征的提取[15]。若令b表示输入图像数量,h为图像高度,w为图像宽度,c为图像通道数,则CNN的输出尺寸[b,hout,wout,cout]由卷积核的数量cout、卷积核的大小k、步长s、上下填充数量ph、左右填充数量pw以及输入图像X的高宽所共同决定,它们之间的数学关系为:

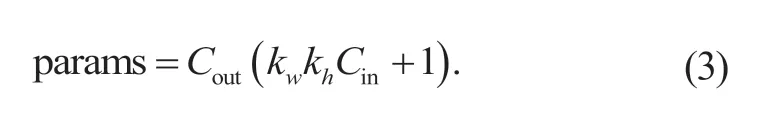
式中:Cout为输出通道数量,Cin为输入通道数量,kw为卷积核宽,kh为卷积核高。
模型的最大池化层(Max pool 层),它能够有效降低输入矩阵尺寸,减少特征维数,降低数据量,提高模型的尺度不变性以及防止过拟合现象,其数学表达为:

式中:xi为感受野区域内Rm,n个神经元的激活值。
模型的压平层 (Flatten 层)主要用于将CNN 层的数据变为一维矩阵,以转化为全连接层,其数学表达为:

模型的连接层(Concatenate 层)则用于将来自多个特征提取网络的特征信息进行融合,其数学表达为:
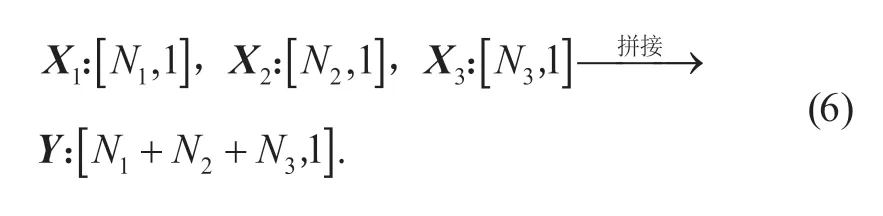
鉴于Max Pool 层、Flatten 层以及Concatenate 层均不会额外增加参数量,根据式(1)—(3)的规则,Model-A/B/C 的总参数量分别为45 645 633、146 831 233 和158 166 977。
对于网络模型不同的输入,应当采取不同结构的特征提取网络来实现对各种特征信息的提取。对于摄像头图像输入,借鉴经典的VGG 系列网络模型的图像特征提取结构[16],来确定相机图像特征提取网络的结构参数,即8 层CNN 结构。而端到端模型所使用的LiDAR 俯视图和局部导航地图在输入网络前将经过一定的预处理,这使得最终输入到神经网络的图片层次较为分明,特征较为显著,并不需要过多层数的卷积神经网络,故此处选择使用4 层CNN 作为其特征提取网络。这将有助于降低端到端决策模型对计算资源的占用,提高模型的训练和执行速度。
根据卷积神经网络图像特征提取经验,卷积层激活函数采用ReLU[17]函数:

全连接层激活函数采用Sigmoid 函数:
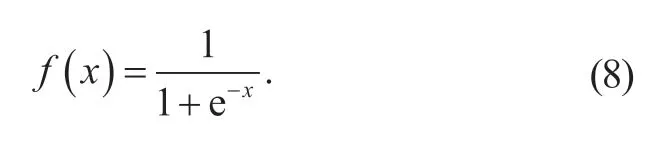
1.2 模型损失函数选择
本文所设计的端到端自动驾驶模型暂不考虑对期望车速的决策,并假定车辆车速保持不变。由于Model-A/B/C 输出的预测结果只有转向角,而车辆方向盘转角本身是一个连续的区间变量,故方向盘转角的预测问题可视为一个回归问题。为此,模型选择使用真实值与预测值之间的Euclid 距离作为Loss 损失函数[9],损失函数为

式中:yb为转向角真实值,M为端到端决策模型,I为模型输入,W为目标网络权值,M(I,W)为模型预测输出结果,即转向角预测值。
为了求解模型损失函数的最小值,训练优化器选择Adam 优化器,故模型损失函数更新后,训练优化后的目标网络权值为
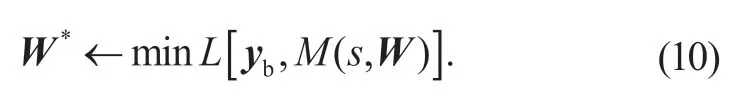
2 数据采集与处理
将Model-A/B/C 所对应的数据集分别命名为Dataset-A、Dataset-B、Dataset-C,并利用Prescan 仿真软件自行构建场景并采集数据集Dataset-A/B/C。数据采集所用车辆为Prescan 内置的某款紧凑型轿车,车辆模型的主要参数如表1 所示。

表1 车辆主要参数
车载传感器包括16 线激光雷达、水平视角为48°的单目前视摄像头,其他车辆信息由Prescan 内置模块提供。
2.1 激光雷达点云预处理
模型所用的激光雷达为16 线360°环视激光雷达,垂直视角范围为[-15°,15°],方位角分辨率为0.2°。如图2 所示。LiDAR 坐标系以安装位置为原点、车辆行驶方向为y轴正方向、与车辆轴线垂直指向车辆右侧为x轴正方向,投影俯视图像素w=220,h=440。
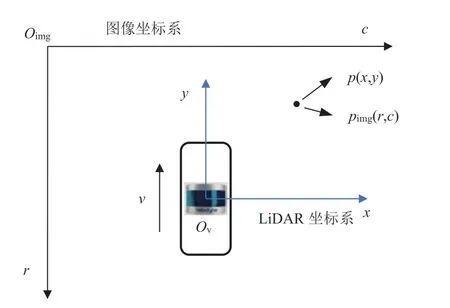
图2 LiDAR 坐标系和图像坐标系
由于Prescan 提供的点云坐标值并不是以激光雷达本身作为坐标原点,而是在Prescan 全局坐标系下的坐标值,因此需要进行相应的平面坐标旋转变换,将点云坐标转换至LiDAR 坐标系下,转换公式如下:
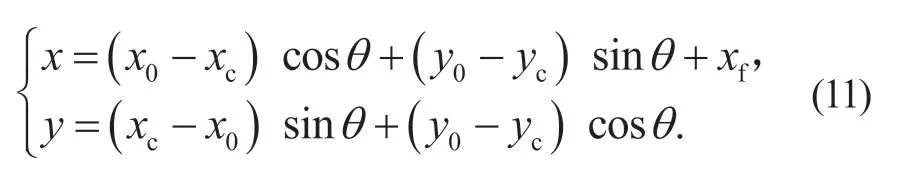
式中:(x0,y0)为点云在Prescan 坐标系下的坐标,(x,y)为点云在LiDAR 坐标系下的坐标,(xc,yc)为质心坐标,xf为质心坐标系与LiDAR坐标系在X轴方向上的差值,θ为车辆绕着Prescan 坐标系Z轴旋转的角度。
显然,激光雷达的点云数据需要经过由LiDAR 坐标系向图像坐标系的转换。如图2 所示,假设激光雷达的某一个反射点为p,其在LiDAR 坐标系下的坐标为p(x,y),图像坐标系下的坐标为pimg(r,c),考虑到模型更需要前方视野,故雷达中心投影相对图像中心向下平移一定距离,实际坐标转换关系如下:
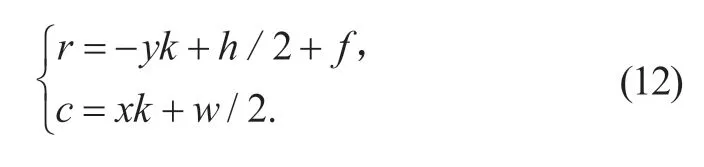
式中:k为LiDAR 坐标系与图像坐标系的比例尺,单位为:像素/m;f为雷达相对图像中心向下平移了多少个像素,取f=25。
在对点云数据投影时将进行数据预处理,即对点云数据进行地面分割:先实时使用点云数据动态拟合近似地平面的平面方程(ax+by+cz=1),再利用反射点到平面的距离d(见式(13))实现点云的筛选。

式中:(x1,y1,z1)为某反射点在LiDAR 坐标系下的坐标,LiDAR 相对地面安装高度为1.9 m。
地平面的平面方程拟合步骤如下:
步骤1:原始点云数据筛选。根据点云Z轴坐标值,筛选z∈ [-2.6,-1.8] 的点云集合A1。
步骤2:提取坐标信息。创建集合A2,提取点云集合A1中的X、Y、Z坐标信息,形成A2,大小为3n,其中n为点云的数量。
步骤3:根据线性代数理论,计算A2X=1,初步拟合平面系数矩阵X=[a,b,c]T。
步骤4:迭代优化。根据公式(13)计算集合A1中点云到拟合平面的距离,可得d∈ [0,0.03+0.01n] 的点云集合C,其中n依次取8、7、6、5、4、3、2、1,重复步骤3,不断优化拟合平面系数矩阵X。
仿真环境中的地平面较为理想,因此根据上述方法和距离公式,即可完成地平面分割。但现实世界的地面状况更为复杂,通常存在一定的坡度变化,并且激光雷达包含测量噪声,这时更好的地面分割方法是沿着y方向将空间分割成若干个子平面,然后对每个子平面使用上述地面平面拟合算法。
在去除地平面点云后,根据点云y/x坐标距离与图像的行像素与列像素之间的比例关系,将剩余点云在俯视图上进行映射。俯视图像默认为黑色,若图像中某个像素位置被点云投影占据则将该点赋为红色,最终得到的俯视图示例如图3 所示。

图3 16 线激光雷达俯视图
显然,激光雷达点云俯视图中包含了驾驶场景的障碍物信息,将该图像输入自动驾驶决策模型能够使其清晰地了解到车辆与周围障碍物之间的位置关系,为模型的避障行驶功能提供了信息支撑。
2.2 局部导航地图获取
现有模型大多以研究车辆在行驶过程中的车道保持任务为主,并没有考虑如何通过交叉路口的问题,故本模型针对交叉路口中的Y 字型路口提出了一种解决方法,即:给定一张全局导航地图,根据定位信息,以车辆为中心截取指定大小的局部导航地图作为决策模型的分支输入,以引导车辆在遭遇交叉路口时应当选择哪条路线继续行驶。
由于预先给定的全局导航地图是固定而不发生旋转的,而车辆是处于实时运动的,故为了模拟人类驾驶时局部导航地图信息会随着车辆的运动而进行旋转的情况,从全局导航地图中定位截取的局部导航地图也应当进行旋转,具体的截取步骤如图4 所示。

图4 局部导航地图截取流程
车辆质心在全局导航地图中的定位公式如下:
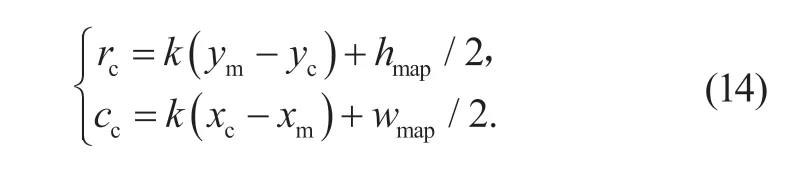
式中:k为全局导航地图比例尺,(xm,ym)为全局导航地图中心在Prescan 全局坐标系下的坐标,hmap与wmap分别表示全局导航地图的高与宽。
旋转后的局部导航地图如图5 右侧部分所示,其中蓝色矩形代表车辆所处的位置,红色线路代表预先指定的路线,程序所截取的图像像素尺寸为50×50。根据车辆在全局坐标系的位置信息,旋转前后的局部导航地图对比,如图5 所示。
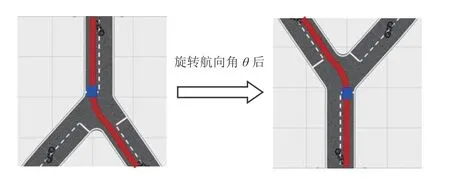
图5 局部导航地图旋转前后的对比
实际上,直接将导航指令数据作为模型的输入也能够实现路口通行功能[10],但是此时模型的特征提取网络就需要重新设计,而且随着后续功能扩展和输入数据增加,模型结构还需要不断调整。本文将图像化后的局部导航地图作为端到端自动驾驶决策模型的输入,主要是考虑到模型输入信息的一致性以及模型的可扩展性。下一步还可以在图像中增加限速和红绿灯等信息,由于局部导航地图的尺度是固定的,因此不需要修改原先网络的结构。
2.3 数据采集规则
结合自身实际需求以及现实世界的交通规则,本文在采集数据集时将依据如下原则:
1)车辆以平稳的速度在仿真环境中采集数据,车速保持在40 km/h 及以下,不存在急加速或急减速的情况;
2)鉴于障碍物和交叉路口的类型多样化,为了证明所提出的端到端决策模型的有效性,仿真环境下设置的障碍物主要是静止停放的车辆及行人,交叉路口主要为Y 字型交叉路口;
3)为避免训练数据的不平衡,即避障与转弯数据过少,导致车辆趋向于直线行驶[10],实际搭建驾驶场景时将在行驶路段适当增加弯道、障碍物以及交叉路口等场景的频率,提高数据集的平衡性,避免过拟合现象;
4)由于较高的采样率将导致数据集包含高度相似的图像,并不能提供较为有效的监督信息,因此数据集的采样频率设置为10 Hz[19]。
此外,Y 字型交叉路口的向左侧和右侧转向的两个分岔口分别命名为分岔口M 和分岔口N。在Dataset-C采集时,数据采集车辆所途径的M 和 N 类型的分岔口数量分别为16 和11,以避免训练后的网络模型出现过拟合现象。
值得注意的是,真实汽车的驾驶场景丰富多样,难以穷尽,为了验证所提出的端到端自动驾驶模型的有效性,本文只针对每个功能设计了具有代表性的测试场景。若要进一步提高模型的适应能力和泛化性能,还需要获取更多驾驶场景下的训练数据。
2.4 数据集增强
在驾驶员认知中,车辆在行驶时是不应该偏离车道的[20],因此在采集常规数据集时,车辆尽量维持在车道中心,不会出现无故偏离车道的情形。然而,这样的数据集缺乏错误样本,进而导致使用该数据集训练后的模型可能缺乏纠错能力,即当车辆由于累积误差出现偏离车道时无法自我调节,回到车道中心附近位置。
为了解决该问题,需要向数据集中增加纠错样本集。所采用的方法是:将车辆随机初始化在偏离车道中心的某处位置,并调整其朝向(如图6 所示,左侧示例车辆航向角θ为10°,右侧为-10°,航向角取值范围为[-30°,30°]),然后使用Pure Pursuit 算法使车辆回到车道中心附近,从而获得纠错样本集。

图6 车辆初始化偏离车道中心
Pure Pursuit 算法是根据车辆的几何位置关系来推算车辆的控制参数,在中低速情形时具有较好的路径跟踪控制性能,图7 展示了Pure Pursuit 算法的跟踪模型。
由图7,可得
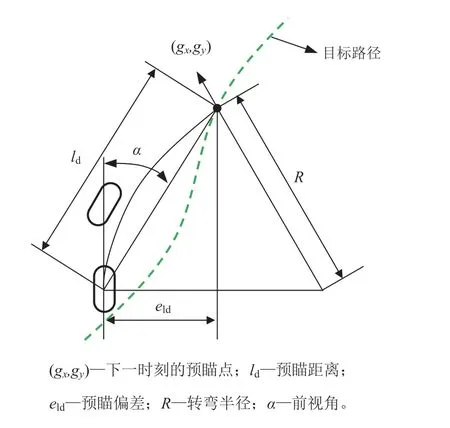
图7 Pure Pursuit 算法跟踪模型

根据Ackerman 转向原理,车辆轴距L、转向半径R与前轮转角δf有以下关系:
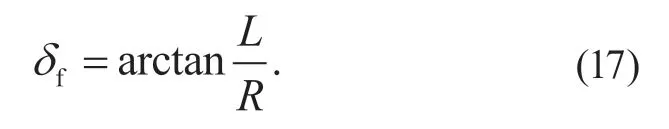
Pure Pursuit 算法的前轮转向角为
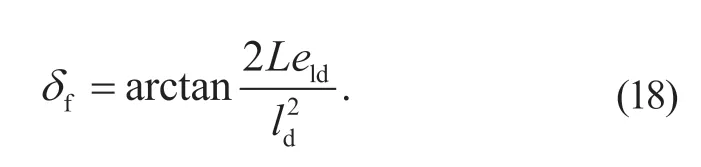
综上所述,基于Prescan 在仿真环境下搭建数据采集场景,采集程序在收集相机图像、激光雷达俯视图和局部导航图等数据的同时,还同步保存方向盘转角作为标签数据。
最终,Dataset-C 共获得3 万余个样本,其转向角频数(Nδ)分布情况如图8 所示,其中 [-50°,50°] 的转向角占比约为25.67%,处于较为合理的比例,避免车辆趋向于直线行驶。Dataset-A/B 的转角分布情况与Dataset-C 类似,此处不再赘述。
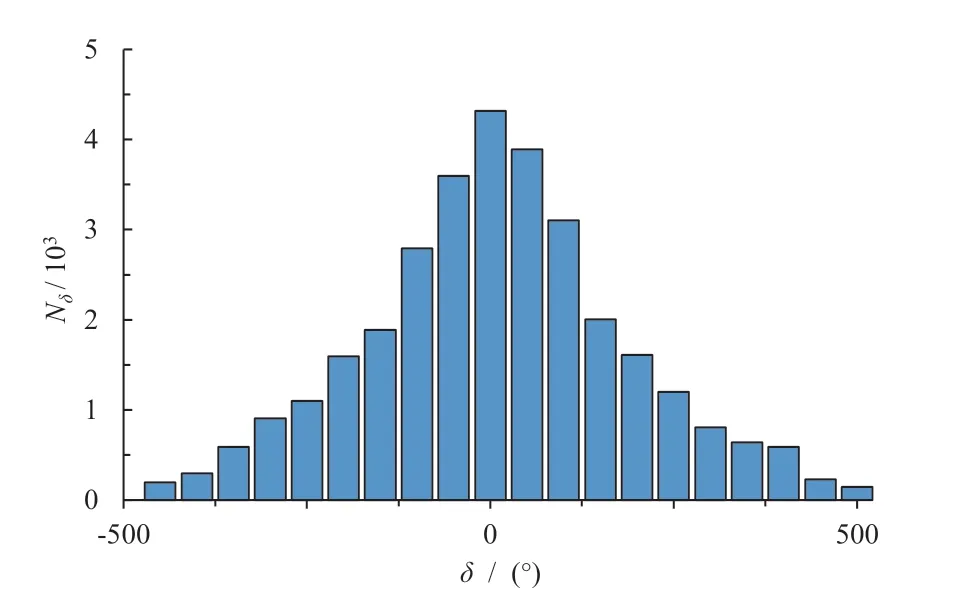
图8 Dataset-C 转向角统计
3 模型训练与验证结果分析
3.1 网络模型的训练
模型训练的深度学习框架为TensorFlow 2.1 版本,编程环境为Python 3.7.0,CUDA 版本为10.1;GPU 为NVIDIA GTX 2060Ti、内 存 为32 GB;CPU 为Intel Core i7-8700 (六核十二线程)。
显然,从图像中预测方向盘转向角属于一种回归问题[21],为此选用均方根误差RMSE 作为评价指标,其表达式为
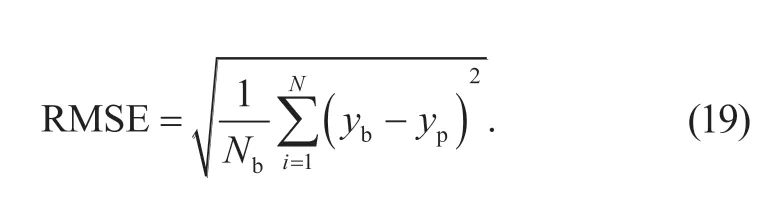
式中:yp为方向盘转向角的预测值,Nb为图像批量大小,取Nb=64。
使用TensorFlow 加载数据集Dataset-A/B/C,并将LiDAR 俯视图尺寸放缩至110×220,其他输入尺寸保持不变,并按照80%和20%的比例分别将数据集划分为训练集和测试集,测试集将通过RMSE 来实时评价网络的优化过程。以Model-C 为例,其训练过程示意图如图9 所示。
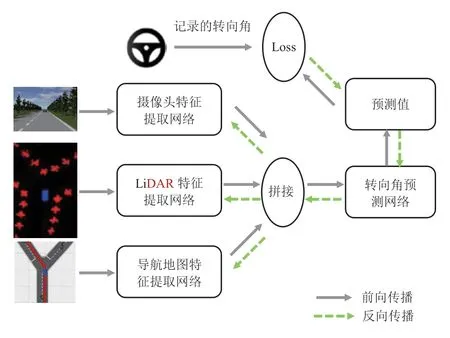
图9 Model-C 模型训练过程示意图
作为对比,NVIDIA 提出的含有5 层特征提取网络的PilotNet 网络将一同参与模型训练,其训练所用的数据集为Dataset-A。经过50 个迭代次数(N)的epoch训练,Model-C 的Loss 变化曲线如图10 所示。

图10 Model-C 模型训练Loss 变化曲线
各个模型在不同数据集训练下均呈现收敛,并没有出现明显的波动现象。为了定量分析不同模型之间性能的差异,以各模型在测试集上最后5 个Epoch 的平均值来对比分析,如表2 所示。从RMSE 值对比可以看出,Model-A/B/C 的表现要明显优于PilotNet 模型。此外,相比Model-A 的RMSE 值,Model-B/C 出现逐渐增大趋势,可以认为这是由于局部避障和交叉路口通行数据相比车道保持数据有着更大的转向角差异性,即RMSE 值的增加是由于网络分支增加所带来的合理现象,属于可接受范围。

表2 不同模型的性能对比
3.2 车道保持验证分析
针对各模型的车道保持性能验证,设计了图11 所示的测试场景,包含直行车道、S 形弯道以及大曲率弯道。
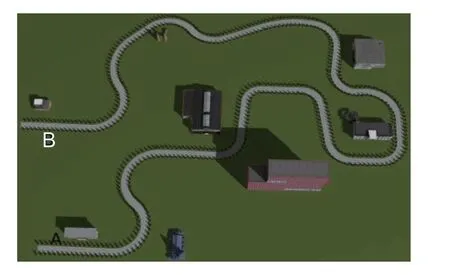
图11 车道保持验证场景
通过Prescan 与MATLAB 联合仿真来验证Model-A 与PilotNet 在车道保持方面的表现,而参照的基础模型则为Prescan 自带的预瞄控制器的转向角预测曲线,对比结果如图12 所示。显然,Model-A 与基础模型的重合度较高,且较为稳定;而PilotNet 网络在部分弯道存在明显的波动现象,这进一步表明了所建立的Model-A 模型具有较好的学习与表达能力。
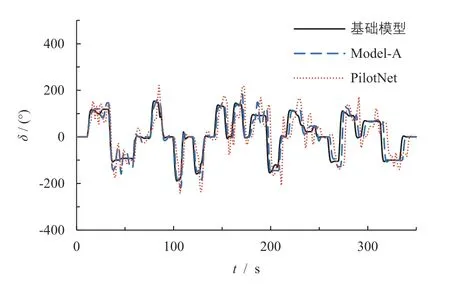
图12 基础模型/Model-A/PilotNet 转向角预测
为了验证Model-B/C 额外网络分支加入对车道保持的影响,在同样的测试场景上测试Model-B/C 模型,并结合Model-A 预测结果,构成了图13 所示的对比图。显然,Model-B/C 模型的预测曲线与Model-A 模型的预测曲线有着高度重合,且均较为平滑,抖动幅度较小,Model-B/C 模型仅在部分弯道处存在些许的明显波动。可见,额外网络分支的加入,并没有明显改变原有模型对相机图像输入的特征提取能力。
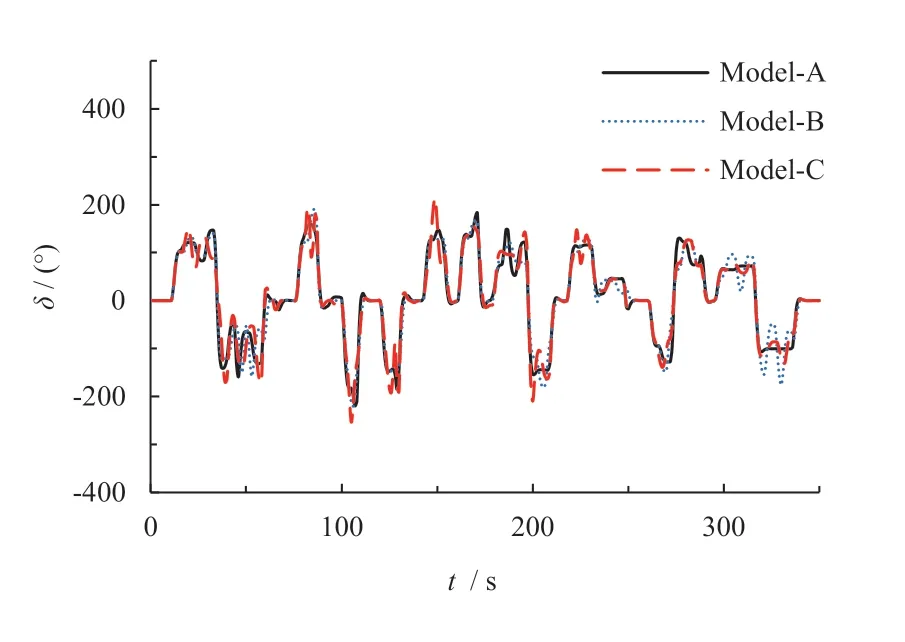
图13 Model-A/B/C 转向角预测
由于本文所设计的端到端自动驾驶模型主要目的是为了扩展传统端到端模型自动驾驶功能,因此模型输入没有考虑车速等汽车状态数据。为了提高模型在不同车速下的车道保持性能,一个可行的改进方法是将汽车车速、侧向加速度、纵向加速度等状态量输入给端到端自动驾驶模型。
3.3 避障行驶验证分析
针对车辆自主换道避障功能的验证,本文目前仅考虑较为简单的情况,即双向两车道,障碍物为静止的车辆和行人障碍物,且当主车避障到左侧车道时,左侧车道无干扰车辆。具体设置的验证场景如图14 所示。
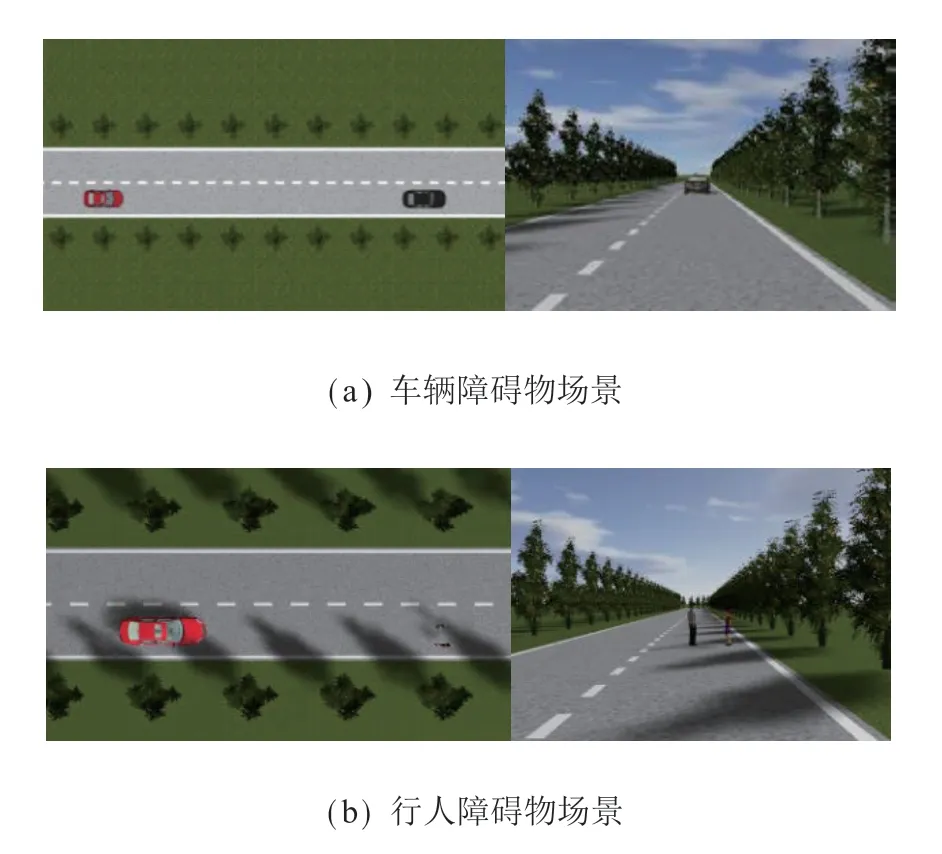
图14 避障验证场景图
车辆和行人障碍物场景下,模型Model-A/B/C 控制的主车行驶轨迹如图15 所示。从图15a 可知:Model-A 未能控制车辆完成局部避障,这是由于数据集Dataset-A 中并没有相关避障数据,因此Model-A仅关注车道线信息;而Model-B/C 均能顺利完成局部避障,这充分表明模型已从数据集中学习到对障碍物的识别能力。与Model-A 相比,Model-B 的表现也从侧面说明了LiDAR俯视图的加入能够实现避障的作用。从图15b 可知:在行人障碍物场景下Model-B/C 依然能够有效完成避障行驶,相比车辆障碍物场景,此时主车的换道行驶距离要短一些。
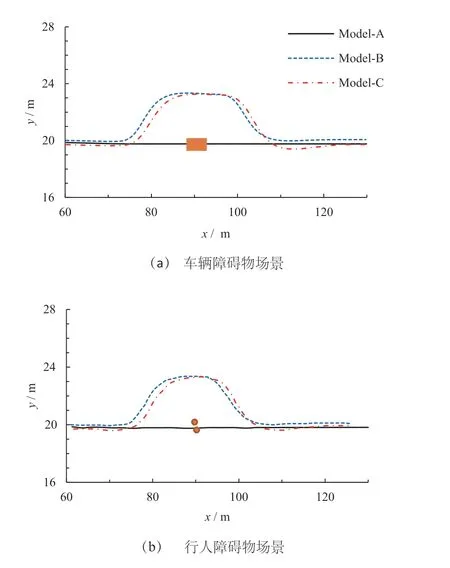
图15 避障场景下Model-A/B/C 的车辆轨迹
考虑到Model-A 和Model-B 训练所用的数据集并不是同一个数据集,其避障表现结果并不能直接验证LiDAR 俯视图对于扩大感知视野的作用。为此,这里使用数据集Dataset-B 再次训练Model-A,并将其测试结果与Model-B 对比,可得图16 所示的轨迹。
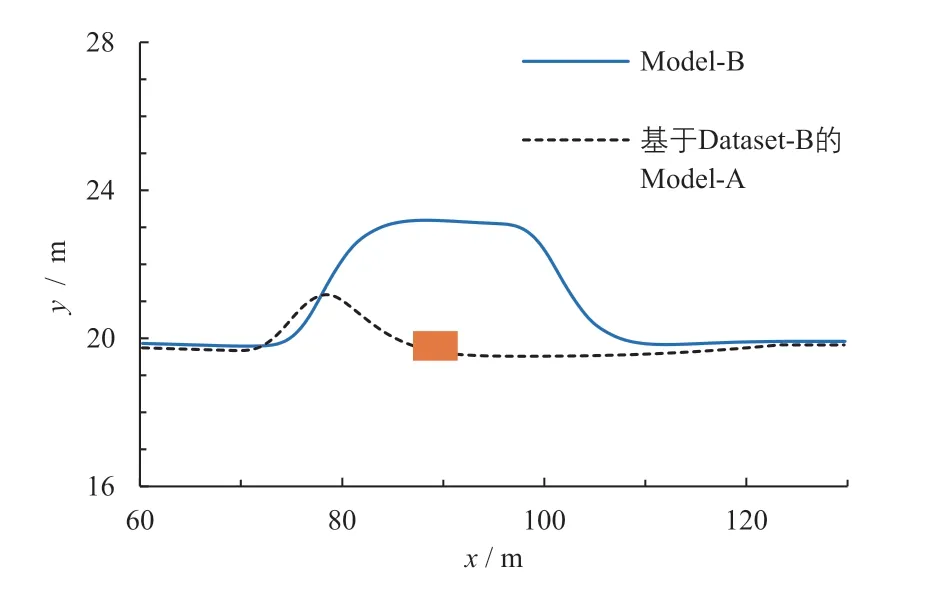
图16 车辆障碍物场景下基于Dataset-B 的Model-A/B 的车辆轨迹
从图16 可知:基于Dataset-B 训练的Model-A 依旧未能完成预期的避障转向行为,但相比基于Dataset-A的Model-A 却有着明显变化。对于Model-A 控制下的车辆自动转向一段距离后折返的现象,通过观察摄像头的实时输入状况发现:车辆的异常行为发生在摄像头视野中丢失障碍物车辆信息后。然而,作为对比分析的Model-B 模型所控制的主车并没有发生此异常行为,而是成功完成了避障转向行为。
结合2.4 小节提到的基于路径跟踪模型的数据增强以及Model-B 的LiDAR 俯视图输入,可以分析出:Model-A 的这一现象是由于视野丢失障碍物信息后,Model-A 认为车辆存在偏离预期车道行驶的迹象,因此开始控制车辆返回原车道;而Model-B 在LiDAR 俯视图的影响下始终没有丢失障碍物信息,因而能够顺利完成局部避障行为。可见,图16 的轨迹对比不仅直接验证了加入LiDAR 俯视图分支的有效性,而且侧面验证了增强数据集能够帮助可能偏离车道的车辆维持车道保持的稳定。
3.4 交叉路口验证分析
对于交叉路口验证场景,这里主要探索Y 字型交叉路口,以尽快验证所提方法的有效性。验证场景设计如图17 所示。以左侧的S 点作为主车的起点,在随后的路段分别设置了A、B、C、D共4 个Y字型交叉路口,E、F、G分别为3 条道路的终点位置。图18 展示了2 条用于测试模型的全局导航地图行驶路径(命名为nav-1 和nav-2),分别经过S-A-B-E和S-A-C-D-F。

图17 交叉路口验证场景

图18 全局导航路径nav-1 和nav-2
交叉路口场景的测试重点在于验证局部导航地图的加入是否对Model-C 在Y 字型交叉路口的选择中起到了关键作用。因此,可直接将Model-C 与Model-B的验证结果进行对比分析,以便能够直观体现出局部导航地图加入的作用。模型Model-B/C 控制下主车的运动轨迹如图19 所示。

图19 Model-B/C 预测的车辆行驶轨迹对比
结合导航地图与验证场景可知:对于nav-1 的导航地图,Model-C 选择了S-A-B-E线路,与设定导航地图相符;对于nav-2 的导航地图,Model-C 则选择了S-AC-D-F线路,同样与其全局导航地图相符;而没有导航地图网络分支的Model-B 则选择了S-A-C-G线路,与设定的nav-1 和nav-2 导航路径均发生了分歧。显然,Model-C 与Model-B 选择的不同已充分表明了局部导航地图网络分支的加入对模型在交叉路口的选择起到了关键作用。对于Model-B 这一现象,通过观察其所途径的交叉路口可知:Model-B 由于缺乏导航地图,在交叉路口无法做出正确的判断,因此只能选择始终沿着车道线行驶,而右侧车道线始终没有发生中断,这就是为什么Model-B会在路口朝着右侧转向的缘故。可见,Model-B 模型对车道线的依赖进一步说明了局部导航地图在交叉路口处道路选择时的作用。
此外,根据Dataset-C 中车辆所通过的交叉路口统计可知:M 型分岔口即为通往车道线发生中断的那条道路;N 型分岔口即为通往右侧车道线未发生中断的那条道路。显然,统计信息表明了车辆既有通过M 型分岔口,也有N 型分岔口,且N 型占据了40.7%的比例,这充分排除了Model-C 存在对M 型分岔口过拟合的可能。可见,端到端自动驾驶模型引入局部导航地图的设想是可行的,即通过增加额外的局部导航地图网络分支的方法,能够使得决策模型具备在Y 字型交叉路口选择正确车道的能力。
综上所述,所涉及的端到端决策模型经历了从PilotNet、Model-A,再到Model-B,最后到Model-C的改进,其功能表现也随之逐渐提升,如表3 所示,清晰地展示了各模型间能力的不同。表3 中,模型处理时间“t”是指在本验证平台环境下,MATLAB 深度学习架构对不同模型单个输入数据的平均处理时间,以衡量各模型对平台算力的需求。

表3 不同模型间的功能表现对比
显然,网络层数的加深以及网络分支的增加必然会增加额外的模型处理时间,但考虑到控制程序20 Hz的更新频率要求和带来的模型能力提升,模型处理时间的牺牲是可接受的。
3.5 实车道路测试
为进一步验证所设计的端到端自动驾驶决策模型的有效性,以某款具备主动驱动、转向和制动功能的电动汽车搭建实车道路测试验证平台如图20 所示。车载设备包括Velodyne 16 线激光雷达、单目摄像头、全球定位系统(global positioning system,GPS) 组合定位导航、高性能工控机和控制器局域网总线(CANBUS)等,软件环境为Python 3.7.0。

图20 智能驾驶电动汽车试验平台
鉴于真实场景下Y 字型交叉路口较少,且验证平台行驶区域限定,不易采集真实数据。而T 字型交叉路口与Y 字型本质上是相同的,且在特征方面有较多的相似性。因此,根据迁移学习任务转移的理论,可通过采集一定的T 字型交叉路口数据构建数据集后迁移训练Model-C,并验证其在真实场景下的表现,从而验证LiDAR 俯视图与局部导航地图网络分支的可行性。
真实场景数据及验证在某一园区进行,如图21 所示为园区道路俯视图。由图21 可见:该园区内有多个T 字型交叉路口、直道和弯道可供数据采集。传感器经过组合调试后,由熟练驾驶员在园区内驾驶实车完成真实场景数据采集。摄像头采集的道路图像照片示例如图22 所示。

图21 园区道路俯视图及测试路线

图22 真实场景道路图像示例
为了安全着想,利用真实场景数据对Model-C 进行迁移训练后,在园区内以10 km/h 的车速进行实车验证。图23 展示了人类驾驶员与无人驾驶的Model-C 的转向角对比。
由图23 可知:尽管经过真实数据训练后的Model-C 在转向角预测方面存在较为明显的波动,但整体上车辆并没有偏离目标路线,仍完成了预期任务,即:完成了直道与弯道车道保持控制、主动避障行驶以及交叉路口通行。实车道路测试结果进一步验证了本文所提出的融合多源传感器与导航地图的端到端自动驾驶决策模型的可行性。

图23 人类驾驶员与Model-C 的转向角对比
4 结论
本文提出了一种融合多源传感器和导航地图信息的端到端自动驾驶决策模型,该模型以单目前视摄像头、多线激光雷达俯视图以及局部导航地图作为输入,通过特征融合后,能够实现对车辆转向角的预测,克服了单摄像头视野不足以及交叉路口无法通行的问题。此外,针对训练数据集缺乏纠偏能力的问题,提出了应用车辆不同初始化位置与纯跟踪算法结合的方式,构建了增强数据集。软件仿真和实车道路试验结果表明,经过训练后的端到端决策模型在车道保持、主动避障、交叉路口通行方面都表现出良好的性能。
然而,由于所提出的决策模型并没有考虑其他障碍物的运动状态以及自身的纵向速度控制等,因此无法应用于更为复杂的驾驶场景。考虑到速度与转向具有不同的属性,未来的工作将更多集中于通过增加额外网络分支来赋予模型车速控制能力以及多障碍物场景下的端到端决策等方面,使得模型能够适应更加复杂的路况并提高车辆的行驶安全性。
