结合拓扑势与TextRank算法的关键词提取方法
2022-01-28罗婉丽
罗婉丽 张 磊
1(四川旅游学院信息与工程学院 四川 成都 610199) 2(四川省农村信用联合社 四川 成都 610041)
0 引 言
网络文本数据呈爆炸式增长,且呈现出随机性、模糊性及网络化的特点。关键词作为表达文本核心意义的最小单位,以凝练简洁的形式对文本主题进行有效概括,能帮助人们快速地把握文档主题及内容[1],对关键词进行提取在信息检索、情感分析及舆情分析等领域发挥着重要作用。现在主要的关键词提取算法有TF-IDF、TextRank、LDA等,其中TextRank算法以思想简单、语言弱相关、适用于单文本及多文本等优点得到广泛应用,但也存在忽略词语间影响力、句子位置、文档整体结构等诸多不足[2]。针对TextRank算法的不足改进,大量学者做了相关研究。
国内文献对TextRank算法的研究多集中在特征整合、转移概率矩阵改进等方面。李航等[3]考虑词语平均信息熵、词性及词语位置三大特征,通过神经网络训练优化三个特征的权重分配以完成特征融合,使用融合的特征改进TextRank算法的词语初始权重及概率转移矩阵,提高了提取准确率;周锦章等[4]针对词汇语义差异对TextRank算法的影响,利用FastText将文档集进行词向量表示,以词语间的角余弦位距为基础构建转移概率矩阵后进行迭代计算和关键词抽取,取得较好的实验结果;刘竹辰等[5]使用词语覆盖范围、词语位置、词频综合加权作为词语位置分布权值,计算概率转移矩阵并迭代得到候选关键词评分,改进的方法取得了不错的效果;余珊珊等[6]将句子与标题相似度、特殊段落中句子位置、关键句子、特殊句子权重、句子长度等因素加入TextRank网络图构造中,提出了iTextRank方法且实验证明该方法较经典的TextRank算法有更高准确率及更低召回率。
国外文献关于TextRank算法的研究则以与其他方法结合提高准确率和应用创新为主线。Mallick[7]以句子为节点,句子间相似度作为句子间边权值来构造图,使用修改后的逆句子频率对句子中的词赋权值,并基于一个簇内的句子彼此相似、不同簇内的句子各不相同的假设,对图进行稀疏处理并划分为不同的簇以生成文本摘要;Ashari等[8]利用TextRank算法、语义网络及语料库统计构建文档汇总系统,其中使用TextRank提取文档的主要短语并形成句子作为摘要的输出,这一过程由标记化语句、图的建立、使用语义网络和语料库统计的连接边值计算、顶点值计算、排序顶点值以及摘要的创建等子过程组成,使用ROUGE-N方法计算总结的召回率、准确度和F-Score来测量系统输出的质量;Zhang等[9]从语料中选取与某种子词集语义相关的词语或与主题相关但在目标语料中未明确表述出来的词组成子集,使用改进的TextRank构建词图模型并计算语料分数给每个词,用这些分数修改ATE计算出的分数;Petasis等[10]以检查摘要提取和观点挖掘间是否有重叠以及摘要提取方法是否对观点挖掘任务有积极影响为动机,将无监督摘要提取方法TextRank应用于观点组成识别任务,在两个数据集上进行验证得出基于图的方法对观点挖掘会产生积极的影响;Barrios等[11]针对自动摘要提取时TextRank算法仅根据两个句子共享的内容来确定相似关系,提出一种新的相似度函数来计算边的权值,再使用PageRank计算各顶点的重要性挑选出最重要的句子,按句子在文中出现的顺序形成摘要。
针对上述问题,本文考虑词语词频及分布情况作为词语“全局”重要性,在句子范围内结合拓扑势理论改进转移概率矩阵,提出结合拓扑势与TextRank的关键词提取方法(Topology Potential Combined TextRank,TPC-TextRank)。实验表明该方法能有效提高关键词提取准确率和召回率。
1 TextRank算法
Mihalcea等[12]提出的TextRank算法主要应用于提取关键词和自动摘要生成,其提取关键词的基本思想为:利用词在窗口范围内的共现关系构造词项连接图,用邻居词向当前词的连接表达投票关系,连接条数反映边的权重,再通过公式迭代计算词语重要性直至收敛,最后将词语按重要性逆序并选择排名高的若干词作为关键词。假设有一篇文档D,需经过以下步骤来实现TextRank算法:
(1)句子划分。将文档按句子划分并对句子编号,即:D={s1,s2,…,sm}。
(2)预处理。该过程包括两个步骤:① 用分词工具进行分词,即si={wi1,wi2,…,win};② 词性标注并保留特定词性的词,如名词、动词、形容词。
(3)词项图构建。选定窗口大小为N,设词win在句子si中的位置表示为index(win),若|index(wia)-index(wib)|≤N,则认为词wia和词wib存在连接边。Mihalcea指出:句子是按一定结构组成的,没有十分“自然”的指向关系来描述词之间的连接关系。实验也表明无论词之间的指向如何,有向图的提取效果均低于无向图的提取结果。因此TextRank算法提取关键词时构造的是无向图。
(4)词语重要性计算。Mihalcea提出的原始Text-Rank算法迭代公式为:
(1)
式中:WS(Vi)表示词语Vi的权重值;d为阻尼系数,表示保证某一词跳到相邻词的概率,(1-d)则表示跳到一个新词的概率,常取d=0.85;In(Vi)表示指向Vi的词语集合;Out(Vj)表示Vj所指向的词语集合;wji表示两个词连接边间的权重。但算法应用于关键词提取时构造的是无权边模型,公式变为:
(2)
根据式(2)迭代计算词语的重要性直至收敛,一般当两次迭代结果差别非常小时(如:两次结果差值小于0.000 1)则认为算法结束。
(5)将词语按重要性逆序排列并选择Top-K个词作为文档关键词。
2 结合拓扑势与TextRank算法的关键词提取方法
2.1 拓扑势
网络结构中各节点都不是相互独立而是存在某种联系的。法拉第为描述粒子间非接触相互作用而提出场的概念:处于场中的任意粒子都将受到其他粒子的联合作用[13]。文献[14]从数据场的思想出发提出拓扑势:节点在网络结构中的拓扑位置相当于节点所处的位势,反映影响相邻节点的能力,称为拓扑势。
真实网络的模块化特征表明节点间的相互作用具有范围特征且节点的影响力与距离呈反比例关系,这十分符合短程场的概念。因此采用具有短程场特性且数学性质良好的高斯函数来描述节点间的相互作用,作用大小通过拓扑势值来表示。给定网络G=(V,E)和势场,其中V={vi|i=1,2,…,n}表示节点集合,E={(vi,vj)|vi,vj∈V}表示边的集合。对于任意节点的拓扑势值计算如式(3)所示。
(3)
式中:φ(Vi)表示节点Vi的拓扑势值;n为在节点Vi影响范围内邻居节点的个数;mj表示节点Vj的固有属性,在现实网络中常设为1;dij表示两互相连接节点的最短距离,常用跳数进行度量;σ为影响因子,主要用于控制节点的影响范围。
(4)

2.2 结合拓扑势的TextRank算法
TextRank算法在迭代过程中通过词语在窗口内的共现关系构建词项图且连边间权重均匀转移,未考虑词语的语义信息及句法结构。本文综合考虑词语局部和全局重要性,提出了结合拓扑势与TextRank算法的关键词提取方法TPC-TextRank。
1)局部重要性。句子常由词语通过语法规则组合而成,若将句子抽象为以词为顶点的网络,顶点间由于句法结构的原因存在相互影响。拓扑势值表示网络中节点在影响范围内受其他节点联合作用的大小,将其计算方式进行修改后可得到两个单独节点间的影响作用,以此作为词语间的转移概率,计算如下:
(5)
式中:σ表示影响范围,其最优值常根据势熵来确定,但TextRank算法根据窗口大小N来确定共现关系,则可以通过下式确定σ:
(6)
dij为两个词语间距离。设dij=|Index(vi)-Index(vj)|,当dij>N时,dij=0;当dij≤N时,dij=|Index(vi)-Index(vj)|。计算词语间的拓扑势做为连接边的权重以改进TextRank算法的转移概率矩阵。
2)全局重要性。TextRank算法加入词频、词语分布等语义信息可以消除高频词的影响,实现对节点固有属性mj的表示,主要包括两个部分:TF(vj)表示词语在整个文档中出现的次数;DF(vj)表示词语在句子中的分布情况。要注意的是,文章都是高度聚合的,若词语在文中分布越广则更有可能成为关键词。TF(vj)和DF(vj)的计算如式(7)-式(8)所示:
(7)
(8)
词语固有属性mj表示为:
mj=TF(vj)×DF(vj)
(9)
将式(9)代入式(5),则转移概率计算公式为:
(10)
TPC-TextRank算法的基本流程如图1所示。
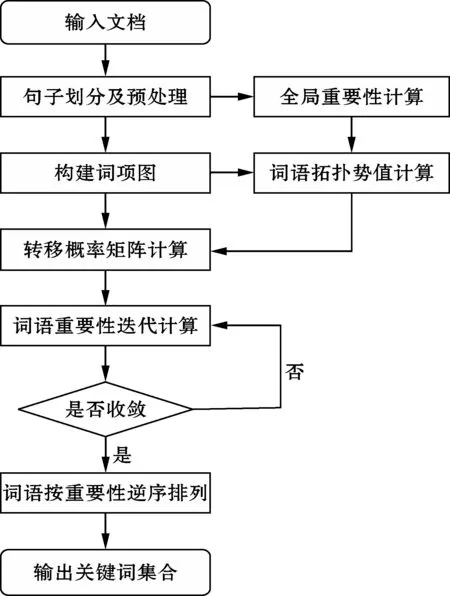
图1 TPC-TextRank算法流程
对TPC-TextRank算法流程进行如下说明:
(1)输入文档D。
(2)按句子对文档进行划分后按句子进行分词、停用词去除、词性标注等预处理。
(3)根据式(9)计算词语全局重要性。
(4)设定滑动窗口大小为N,在窗口范围内通过词在句子范围内的共现关系构建词项图。
(5)结合词语全局重要性及词项图使用式(10)计算词语的拓扑势值,作为词语的转移概率。
(6)结合词项图及转移概率构造转移概率矩阵。
(7)根据式(2)迭代计算词语重要性直至收敛。
(8)词语按重要性逆序排列并输出关键词集合。
3 实验仿真
3.1 实验数据及环境
实验数据选取清华大学刘知远团队提供的2010年6月12日至2010年12月29日网易新闻信息,共计13 702条。每一条新闻包括“content”“title”“tags”等14个字段。其中主要用到了表示新闻正文的“content”字段,人工标注标签的“tags”字段。实验环境为Windows 10,开发语言为Python 3.7,选用自然语言处理包TextRank4ZH和Jieba辅助实验仿真。
3.2 评价指标
实验效果通过准确率(P)、召回率(R)及F值(F)进行验证。设经TPC-TextRank算法提取的关键词集合为TPC,原始标注的关键词集合为TAG,则:
(11)
(12)
(13)
3.3 实验与分析
为验证TPC-TextRank算法的效果,共设计了两组实验。第一组实验:因TextRank和TPC-TextRank都将受滑动窗口大小及Top-K大小的影响,为验证TPC-TextRank算法引入词语局部重要性对最终效果的影响,设计实验取不同Top-K时准确率、召回率及F值随滑动窗口大小变化的情况,实验结果如图2所示。其中T-precision、T-recall、T-Fvalue分别表示TextRank算法的准确率、召回率、F值,TPC-precision、TPC-recall、TPC-Fvalue表示TPC-TextRank算法的准确率、召回率、F值。第二组实验:TF-IDF算法、TextRank算法、TPC-TextRank算法三者在Top-K值不同的情况下所得到的结果是不同的,而TextRank和TPC-TextRank又受到滑动窗口大小的影响,故设计实验考查三种算法在滑动窗口一定的情况下准确率、召回率及F值随Top-K取值变化的情况,实验结果如图3所示。
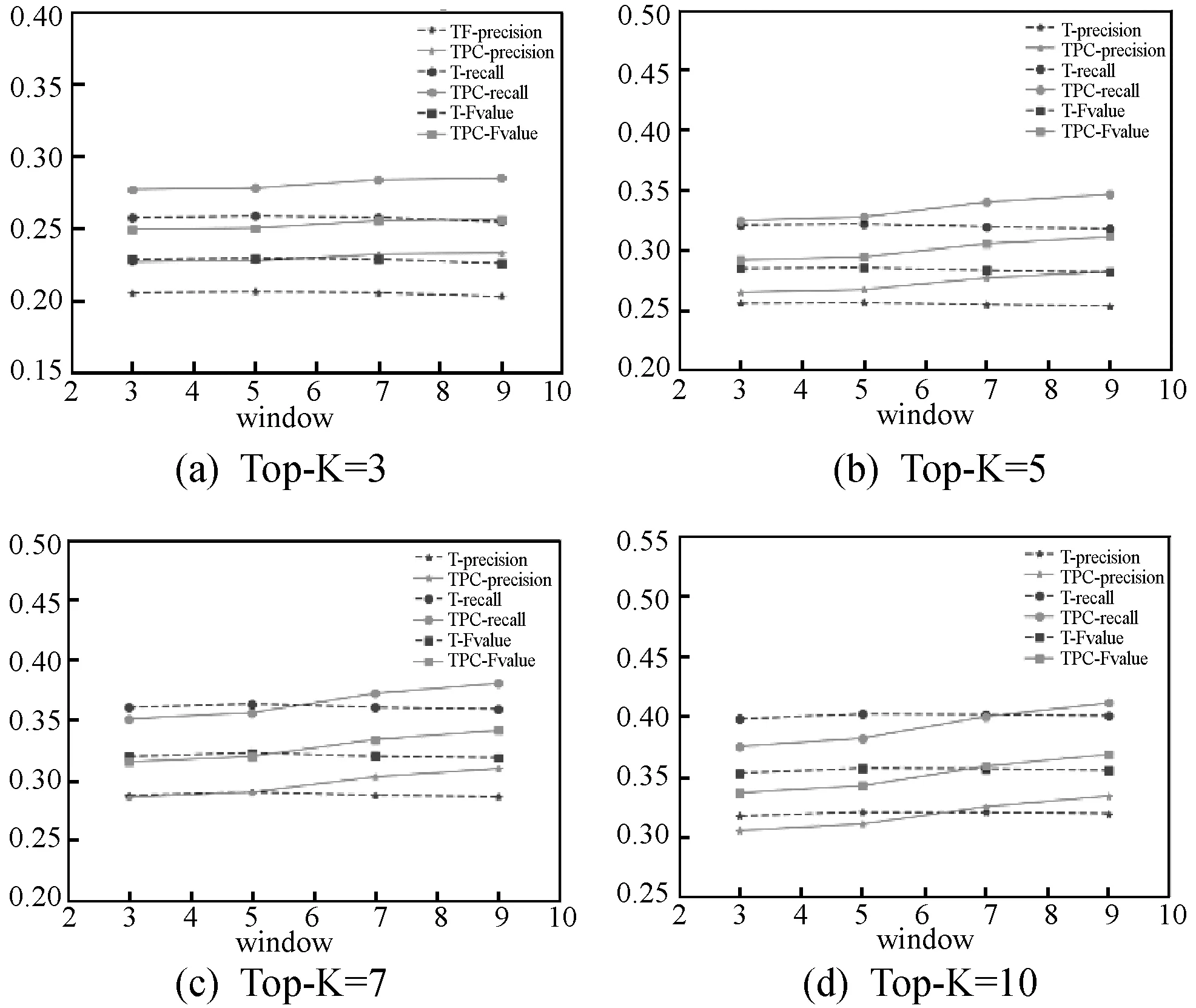
图2 TextRank与TPC-TextRank算法不同Top-K值时对比图

图3 三种算法对比图
从图2(a)、(b)可以看出,在Top-K值较小时TPC-TextRank算法三项指标均高于TextRank算法,且TextRank算法各项指标随着滑动窗口的增大而呈平衡趋势,而TPC-TextRank算法效果随滑动窗口的增大而呈上升趋势,说明考虑词语全局及局部重要性时窗口越大越利于挖掘词语间的关联关系。从图2(c)、(d)可以看出,在Top-K值增大后,TPC-TextRank算法三项指标的起点低于TextRank算法,说明TPC-TextRank算法在窗口较小时对词语间的关联关系挖掘能力较弱,但随着滑动窗口的增大其效果呈现上升趋势,验证了考虑词语局部及全局影响对关键词提取效果的提升。
由图3可以看出,TF-IDF算法随着Top-K取值的增加,准确率呈降低趋势而召回率呈升高趋势,说明候选项中提取准确的项数增速与候选项的增速不匹配,即未能有效地准确提取出关键字;但其余两种算法随着滑动窗口的增大以及Top-K取值的增加,准确率均呈现上升趋势,说明滑动窗口的变化在构建词项图时更加利于发现词语之间的关联关系。再结合图2的分析结果,TPC-TextRank算法可更深层次地挖掘词语间的语义信息并应用于TextRank算法,提取效果优于传统的TextRank算法。
由上述实验结果可见,TF-IDF思想简单且未考虑词语语义信息,在实际中无法展现出良好的提取准确率。传统的TextRank算法虽然不依赖于语料库且是基于图的提取方法,但其迭代过程中连接边的权值均匀分配,同样忽略了词语的语义信息而使得算法效果不佳。本文提出的TPC-TextRank方法综合考虑词语的全局及局部重要性,使用拓扑势的思想对转移概率矩阵进行改进,再结合传统的TextRank算法实现了提取准确率及召回率的提升。
4 结 语
关键词是指能反映文本主题或主要内容的词语。作为自然语言处理领域的一个重要子任务,关键词提取在信息检索、情感分析、对话系统、文本分类等领域发挥着重要作用。本文针对传统的TextRank算法提取关键词时未考虑词语的语义信息、构建词项图时仅以词语统计信息作为连接边权值的考量、权值以均分的形式向相邻节点传统这些不足,使用词频和词语分布情况作为词语全局重要性指标,再结合拓扑势场理论相计算词语的拓扑势值作为局部重要性,将局部重要性引入传统TextRank算法实现转移概率矩阵的构建,实验结果表明该方法实现了关键词提取准确率和召回率的提升。
TPC-TextRank算法在考虑词语的全局重要性的基础上结合拓扑势思想形成了词语的局部重要性考虑,但与传统TextRank算法相结合后仍需要进行多次迭代计算,使得算法的时间复杂度较高。本研究的后续工作将探讨使用预先聚类、局部游走等方法降低TPC-TextRank算法的时间复杂度。
