面向应急管理的事故和灾害网络舆情监管系统
2022-01-28周天墨陈佳林诸云强
周天墨 陈佳林 诸云强
1(中国科学院地理科学与资源研究所 北京 100101) 2(中国科学院大学 北京 100049) 3(应急管理部信息研究院 北京 100029)
0 引 言
信息技术的快速提升在为人们带来便利的同时,也带来了事故和灾害负面舆情来源广且不确定性强[1-2]、蔓延广且传播快[3-4]、数据量大且表述随意性强不易甄别[5]等问题,为舆情管理工作带来前所未有的挑战。因此,如何从海量信息中快速获取与处理事件信息是亟需优化与解决的问题。
基于前人的研究可知:从系统角度[4,6-7],传统舆情监控系统主要依赖于工作站或服务器集群,受可扩展性差、单点通信故障等问题的约束,已不能很好地满足信息快速捕获与甄别的要求。从数据量角度[8-9]来看,随着人们对于互联网与移动终端依赖性的增加,网络信息量每日均呈几何级增长,不仅增加了舆情信息的检索范围与挖掘难度,也对海量数据的高效分类与处理能力提出了新的要求。从使用习惯角度[10-11]来看,企业微信因其针对工作场景的平台架构与模块设置,已成为协同办公的主要方式之一,因此实现与企业微信的信息互通,也是当前舆情系统在研发过程中需要重点关注的内容。
本文采用Hadoop分布式框架设计研发事故和灾害网络舆情监控系统,实现自然灾害、事故灾难、社会公共安全等领域网络舆情信息的实时监控、及时搜集、有效甄别、快速预警、果断处理与动态分析。通过试运行,系统可准确快速地采集与甄别舆情信息,并自动生成热点事件分析报告,对第一时间获取突发事件信息、掌握事态进展、了解网友情绪动态、引导正确舆论导向等具有重要意义,可为实际工作提供有力支持。
1 总体框架
1.1 建设思路
本文系统基于Hadoop框架展开研发,旨在解决多渠道网络舆情信息获取、快速筛选甄别、按权限分时自动推送、各层级用户之间上传下达、舆情动态分析等问题的基础上,构建面向应急管理的事故和灾害网络舆情监测与管理系统。着重解决自然灾害、事故灾难、社会公共安全等多领域事故与灾害信息在网络媒介中传播时的实时挖掘与跟踪。系统与实际业务关联,不同层级用户可按照要求上报本地事故和灾害信息或反馈由上级主管部门下发的舆情信息。通过系统的使用与推广,依据指定关键词、高发时段、高频信息发布者管理、舆情传播途径与周期等特征,逐步优化系统检索与甄别模式,实现指定领域事故和灾害网络舆情信息的快速发现与推送。为进一步提升用户信息接收与浏览的便捷性与使用感,系统与企业微信关联,并依据用户权限进行操作,实现省、市、区三级用户一体化应急管理。
1.2 数据源及分类
通过前人的研究可知[7,12],新浪微博因其具有公开化转发、评论、点赞,曝光量大,易引发热议的特点,是很多热点评论人与爆料爱好者的首选。但随着微信的普及与深化,微信平台逐步成为各类事故和灾害零延迟展现与移动评论的新场所[11]。此外,百度贴吧、抖音、今日头条等社交平台也是当前舆情信息集中出现的媒介。因此,为提升系统检索效率与信息提取精度,本文系统的研发采用“指定网站、逐步完善”的模式,以上述媒介为核心数据源,并依据实际使用情况逐步添加舆情信息高发的网站及论坛,共同组成系统数据源。
依据应急管理工作范围,结合日常接警数据,确定系统检索范围为火灾(城市火灾和森林火灾)、交通事故、洪涝、地震、地质灾害(山体滑坡和泥石流)等领域,子类别按照高发以及社会影响大、损失伤亡重的类别进一步细化。由于多类事故会伴随爆炸、浓烟等现象,故系统针对爆炸类网络信息进行专题抓取。此外,添加政务类检索主题,包含违规曝照、消防通道占用、作风规范等方面。
1.3 技术路线
在明确检索范围后,基于Hadoop框架展开研发,技术路线如图1所示。采用API调用与网页解析的方式,从新浪微博、今日头条、微信公众号、百度贴吧、主流媒体网站及重点关注站点等网络媒介获取原始数据。对于提供API接口的平台服务商,通过API调用获取JSON数据并存入HBase库,未提供的则通过基于HTML的爬虫技术抓取数据。
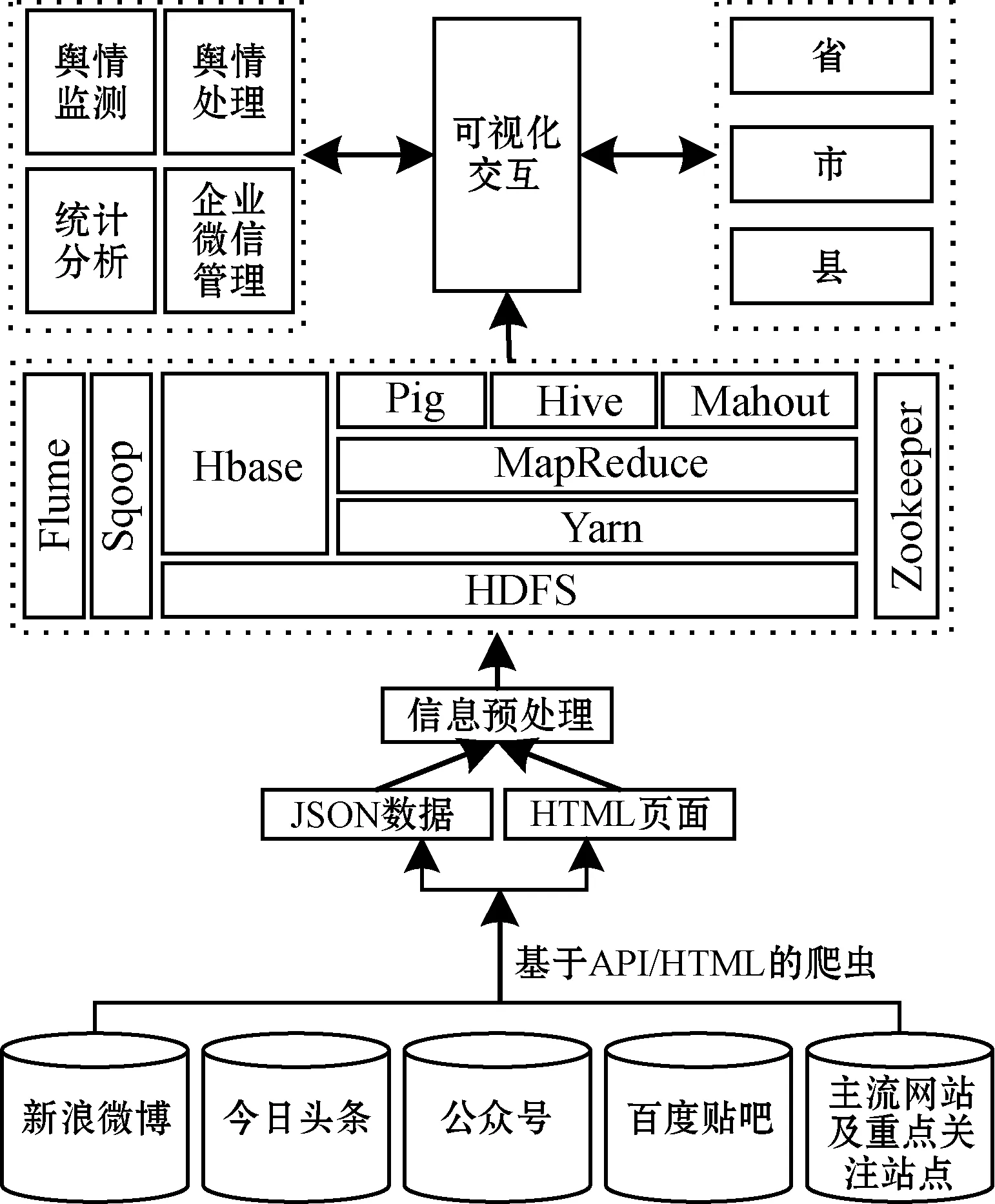
图1 技术路线
获取的数据经清洗过滤等预处理,去除错误、重复或不一致的数据后存储于分布式文件系统HDFS。然后利用MapReduce作为编程模型,使用K-means算法等实现舆情信息的快速分类,既满足网络数据实时检索甄别、分布式管理与高效传输的需求,又实现了对海量舆情信息高效存储与挖掘分析的要求。
最后,按照用户权限通过命令行交互实现系统可视化管理与操作,并通过API接口与模块相关联。包括舆情监测、舆情处理、统计分析、企业微信管理等功能。
2 关键词K-means算法
由于K-means方法具有相似簇间距离小、不同簇间距离大的特点,常被用于文本聚类,但同时具有聚类准确性受初始聚类数K值影响的缺点[13],故本文采用基于高频词的K-means方法[14-15],既优化了初始聚类数的选择,也避免了高维空间向量的处理问题。
2.1 算法原理
基于获取的文本集T={T1,T2,…,Tn},计算文本T1中各分词的TF-IFD值,选取排名前5的分词作为T1的关键词。以此类推获得每个文本的关键词,排序后选取前k个形成文本集T的关键词集W={W1,W2,…,Wk}。将词集中的关键词分别作为初始簇的聚类中心,逐个计算剩余样本到聚类中心的距离,并将样本赋给最近的簇。然后重新计算每个簇的平均值,不断重复直到相邻两次调整没有明显变化,说明算法已收敛。其中,k值为每日动态变化的。通过前期工作积累可知,一般情况下每日事故和灾害起数的波动范围较为稳定,因此采用从系统运行第一日起至运行当日0时前,所有经确认的事件总量的平均值为当日舆情系统文本聚类的初始簇数量k。
2.2 算法实现
本文基于MapReduce实现K-means聚类算法,即首先利用map函数计算每个样本点与簇中心的距离,将其对应到最近的簇,并以
(1)Map部分如下:
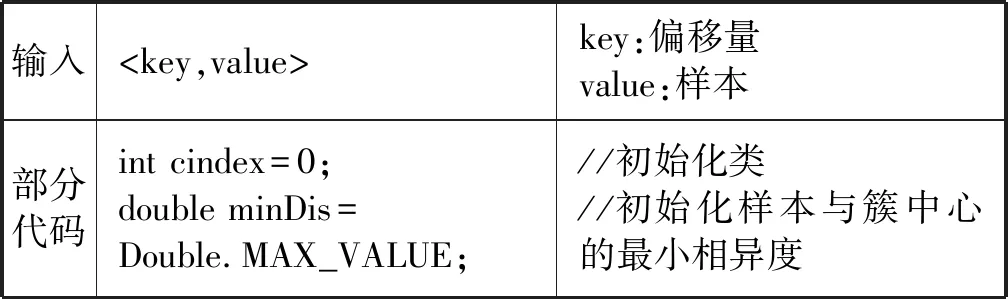
输入

部分代码for(int i=1;i
(2)Reduce部分如下:
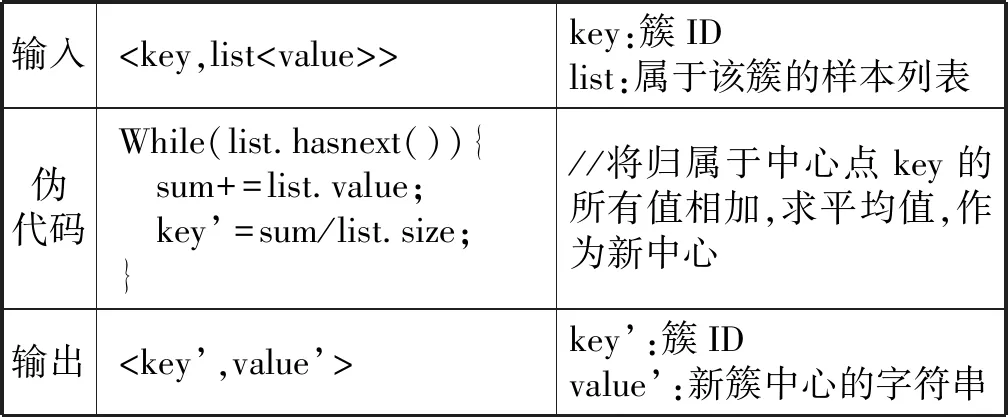
输入
3 系统功能
事件与灾害网络舆情监管系统包括舆情监测、舆情处理、统计分析、企业微信管理等四个模块(如图2所示),可实现舆情信息的自动监测、热点获取、自主上报、反馈处置、综合分析等功能性服务,以及信息检索、列表导出、系统管理等辅助性服务。为简化操作流程,以用户易理解性与易用性为导向,对舆情监测与舆情处置模块的展示页面进行合并,将系统入库的全部网络舆情信息按照时间顺序统一展示在舆情列表中,通过加注标签、按钮及已读信息颜色变化、弹框提示等方式明确表示舆情处置状态与可进行的操作。
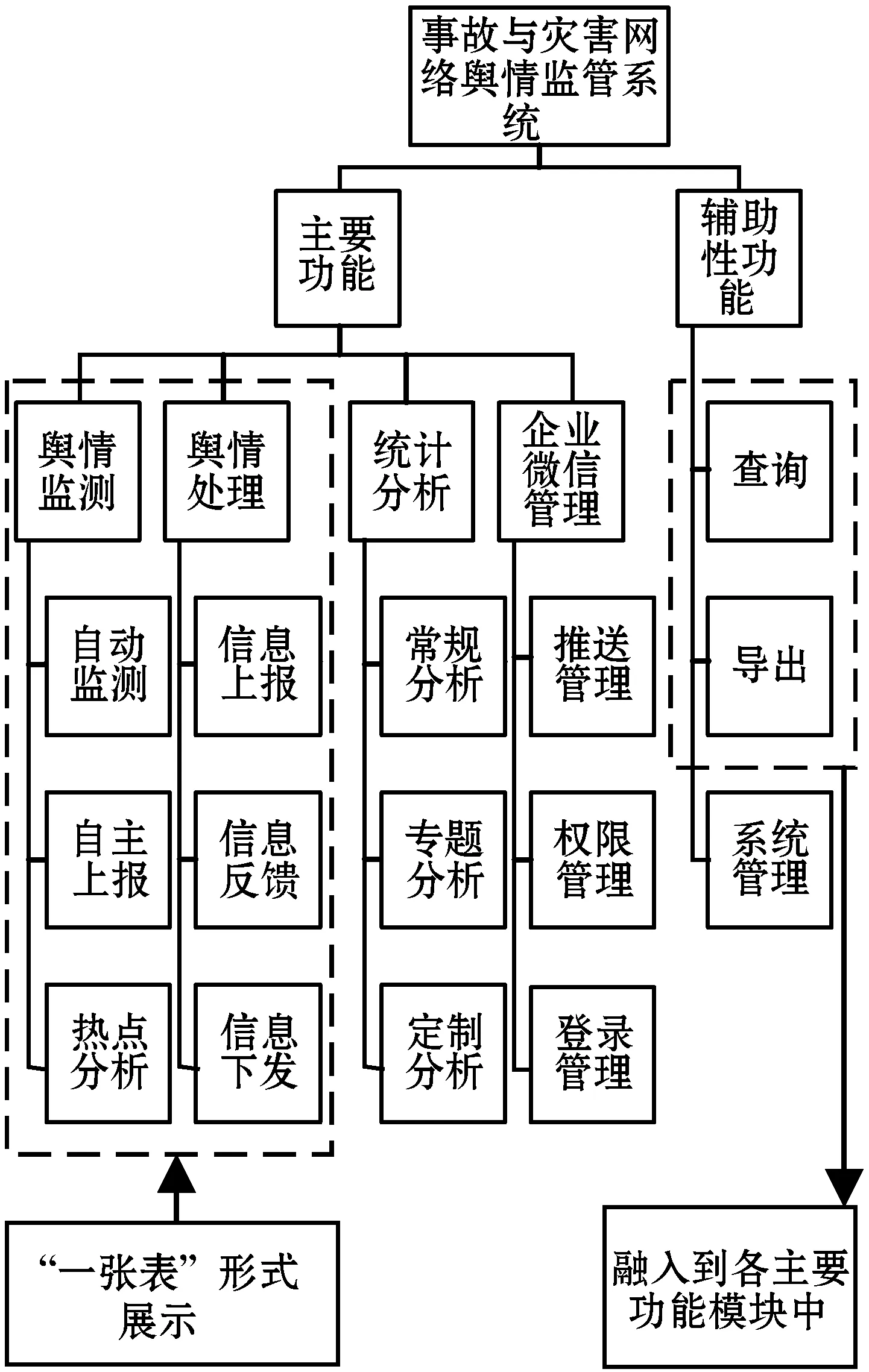
图2 功能体系
3.1 舆情监测
(1)日常监测。基于预设的关键词对指定网站开展爬虫,并将规范化的数据按照类别、地域、标题、摘要、敏感度、倾向性、处置状态、来源的形式进行展示。系统自动判断与其匹配的地址标签,并按照权限自动推送至相应省、市、区等不同层级的用户界面中,实现舆情信息的实时推送与预警。
(2)热点分析。因日常监测范围为特定领域事故和灾害信息的实时监测,故通过热点分析模块对话题进行识别与展示。采用K-means算法[2,11,16]将同一事件网络信息汇总合并,热点话题形成后,进入话题集的舆情信息不再重复推送,按时间顺序依次排列在该话题的舆情列表中。
(3)自主上报。因自动监测和热点分析均为面向指定媒介事故和灾害网络舆情识别与监测,为保证分散信息或非主流传播途径发布的舆情信息不被遗漏,平台提供自主上报功能。各层级用户均可通过该模块录入系统尚未发现的事故和灾害信息,经本级管理员审核后发布并按照报送流程推送至上级用户界面。发布成功后,若系统后续再次监测到该事件则自动归类,不再单独提醒与推送。
3.2 舆情处理
基于本功能可实现舆情信息的上传下达、多级联动与协同处置的目的。系统提供信息报送接口,上级单位可针对某一事件下达指导要求,下级部门逐一填报相应舆情信息现场或网络核实与处置情况。若在规定时间内,事件当前主管层级未做出实质性响应或反馈,系统可通过高亮闪烁、语音提醒、弹窗等方式进行提示,同时按照报送流程上报至上级单位,以提高协同应对效率。
3.3 统计分析
(1)常规分析为系统自带模板,依据用户权限按照时间维度(周、月、季度、年)对指定区域在规定时间内,系统舆情监测与管理的整体情况自动生成图表形式的统计报告。基于报告,用户可直观获取目标区域在指定时间区间内,各类事故和灾害舆情基本情况、时间特征、传播媒介、反馈处理情况、本期重点舆情等,并按照权限推送至相应用户系统界面中。
(2)专题分析只针对某一热点或专题事件,基于系统入库数据及热点词出现频率,通过模型计算后获取该事件概况信息、随时间变化的走势特征、热度指数、地域分布、传播脉络、用户与话题活跃度、话题敏感度与倾向性、情绪分析、事件延伸跟踪等舆情要素的综合分析结果,形成专题分析报告并按权限推送展示。
(3)定制分析则以大量舆情报告为基础,综合常规分析和专题分析框架,用户可依据实际需求自行添加要素生成舆情简报或专业化报告。
3.4 企业微信
移动办公已成为当前的主流办公方式之一,故基于企业微信提供的二次开发平台,研发实时舆情推送功能,以实现增强用户粘性与信息送达准确度、降低部署成本等目的。本次在企业微信自带的权限管理基础上,按照信息推送层级、浏览权限等要求,进一步细化系统用户权限层级。为更好地保障系统用户的群组性、减少信息泄露的可能性,新增用户只能通过定向邀请方式进入系统。用户加入后,依据权限收取以链接方式实时推送的监测信息。发送的信息包括标题、概要、正文、来源、发布时间、相关图片影像资料等,可实现网络舆情信息的及时浏览。
3.5 辅助性功能
辅助性功能包括查询、导出、系统管理等功能。为便于用户快速查找感兴趣的舆情信息,在舆情列表中提供多重检索功能。用户可设置一个或多个检索条件,按照时间、地点、关键词、敏感度、倾向性、处理状态等进行复合查询。针对用户筛选后的舆情信息、统计分析结果、系统日志情况等,提供列表导出功能。系统管理主要对用户权限、操作日志、个性化设置等提供需求提供支持。
4 平台实现
系统已完成开发,试运行期间共抓取火灾(城市火灾和森林火灾)、交通事故、洪涝、地震、地质灾害(山体滑坡和泥石流)、爆炸、政务类等事故与灾害信息95万余条。通过数据预处理后,符合既定类别、满足筛选条件且地址匹配正确的数据约83万余条,在此基础上经文本聚类分析,最终获取事故与灾害15 974起。
通过人工优化及系统自学习,每日事故和灾害网络舆情信息的抓取与分类准确度不断提升,基本符合实际事发数量。以2018年10月任意一天数据为例:初始簇个数k通过计算设定为89。参考前人研究[17],采用错误率MR评测文本聚类的效果,指标定义为:
当日系统自动获取并筛选有效舆情信息4 523条,经过系统聚类分析,形成舆情事故共89起。另有5起事件(共5条)为非设定检索范围获取的舆情信息,通过人工录入方式加入系统。
因此,当日系统内有效舆情信息合计4 528条,经核对分类错误501条,错误率11.06%。造成这一情况的主要原因为部分舆情信息事发地点相同且关键词相似度高。部分话题聚类评价结果如表1所示。
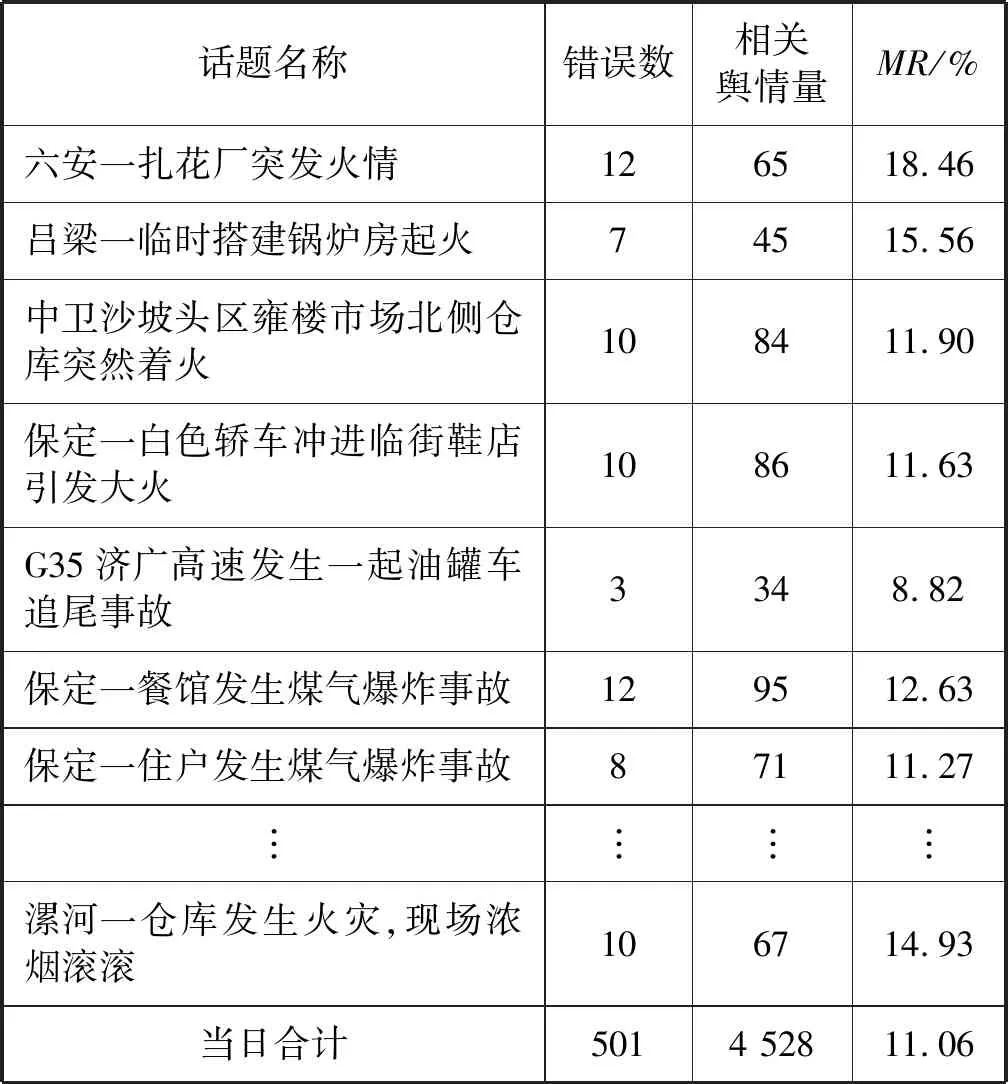
表1 部分舆情信息话题聚类结果
5 结 语
(1)系统基于Hadoop框架进行研发,在保证海量多源数据处理效率的同时,保障了数据检索的时效性与准确性,并通过对话题进行挖掘与分析,获取舆情信息的敏感性与倾向性,为掌握该事故和灾害网络舆情动态提供支持。
(2)依据应急工作范围,通过分析日常接警信息,确定系统检索范围,有针对性地对通过网络途径发布的事故和灾害数据、持续热点事件的动态进行辨析、归类。
(3)通过对网络媒介中舆情信息的自动检索与甄别,发现最新事故信息、抽取热点事件,值守人员可第一时间获取“原生态”网络舆情信息并跟踪进展,有助于对异常增长的话题或事件信息,提前预警并启动相应应对措施,减少因信息瞒报、误报、迟报而导致的被动应对状态。
(4)区别于以往的舆情监测系统,本文系统与实际业务相结合,构建省、市、区三级一体化的舆情监测与处置体系,实现以事件为触发点、快速联通各级应急管理人员、多级协同响应的目标。采用一张表的展示形式,将与同一事件相关的舆情信息、现场核查情况、处置意见与状态等情况综合展示,实现不同层级用户进入系统均可快速了解舆情状态与处置情况。
(5)因系统会依据关键词所属的事故和灾害类别,对检索入库的舆情信息进行自动标注与分类,故利用其统计分析功能,可获得指定周期内各地区高发事故与灾害的类型、数量变化等特征,为事故与灾害的防范与预警提供参考。
