基于多特征融合和卷积神经网络的无参考图像质量评价
2022-01-27刘楷贇邹国良王振华郑宗生
卢 鹏, 刘楷贇, 邹国良,王振华,郑宗生
(上海海洋大学 信息学院,上海 201306)
1 引 言
数字信息化和显示技术持续进步,图像数据也持续飞速性地增长,广泛出现在人们的生产生活中。图像的视觉质量与用户的体验密切相关,是决定计算机视觉应用的重要因素之一[1]。图像质量客观评价的应用非常广泛,例如用于评价图像去雾[2]、图像去噪[3]等图像处理算法等。图像质量评价(Image Quality Assessment,IQA)方法在图像显示技术等领域发挥了重要作用。
图像质量评价有主观评价和客观评价两种基本方法。主观质量评价是观查者本人对图像的视觉质量来打分,主观质量评价符合人眼的视觉系统(Human Visual System, HVS), 但不适用于实际系统[4]。依据对参考图像的依赖程度,客观图像质量评价可以分为3种基本类型:全参考(Full-Reference)、半参考(Reduce-Reference)、无参考(No-Reference)。全参考和半参考IQA需要有参考图像来辅助进行质量评价。常见的全参考方法有均方误差(Mean squared error,MSE)、峰值信噪比(Peak signal-to-noise ratio,PSNR)[1]。比较典型的有结构相似度评估方法(Structural similarity,SSIM)[5],根据图像的结构信息,通过分析和比较参考图像和失真图像之间结构信息的相似度,对失真图像质量的评估和预测。Zhang等人基于此改进提出了基于特征的结构相似度方法(Feature similarity index,FSSIM)[6]。Heikh等人从信息论的角度出发,结合信息提取的过程来进行图像质量评价,提出了视觉信息保真度评价方法(Visual information fidelity,VIF)[7]。
无参考图像质量评价模型通常应用于缺少原始图像的场景,具有实际的应用前景和价值[8]。通用类型的无参考算法一般遵循两种方法,即基于自然场景统计(NSS)或机器学习的方式[9]。基于NSS的方法包括:Mittal 及其团队通过对图像提取形状和方差等统计特征来进行图像质量评价[10];Yu等人基于NSS通过色域映射的方式来评估图像质量[11]。基于机器学习的方法包括:Bianco 等人通过使用 CNN 提取图像特征,接着使用SVR回归质量分数的方法来获得预测评分[12];Ye及其团队将多特征予以融合,采用深度学习的方法对彩色唐卡的修复图像质量进行了评估[13];Fan等人通过自相似性显著性检测(SDSR)算法提取HDR图像的显著区域用于模拟人类的视觉注意力机制,然后根据亮度和对比度敏感度的视觉特征,设计了用于训练质量预测模型的视觉质量感知网络[14]。卷积神经网络(CNN)作为深度学习中的网络模型之一,被应用到IQA任务当中。Kang等人首次将卷积神经网络应用到无参考图像质量评价之中并提出了IQA-CNN模型[15]。他们提出的IQA-CNN由于首次将卷积神经网络应用于IQA,因此蕴含重要意义。该算法首先将预处理后的图像分成32×32的图像块,用整幅图像主观质量评分标注各分块,再投入卷积神经网络训练;接着对得到的各分块的图像质量评分取平均值以获得最终整幅图像的质量评分。IQA-CNN方法的优势在于将图像分块以满足卷积神经网络对于大数据量的要求,却忽略了不同图像块的质量由于人眼视觉关注度不同而存在的差异性,也就是说用大图像的主观质量评分来标注分块图像的标签并不准确。
通常情况下,图像纹理特征丰富的区域会表示更多的图像细节,人眼对于该区域的图像质量更加敏感。信息熵是反应图像信息丰富程度的度量方法,人眼倾向于从信息熵丰富区域来评估图像质量。充分考虑以上两个指标对人眼视觉关注区域的影响后,本文提出了一种基于多特征融合和深度学习的无参考图像质量评价模型。在原始的IQA-CNN算法基础上,计算每块图像的信息熵和图像纹理特征,在训练过程中用两个指标计算视觉权重用以修改损失函数,最后在两个通用数据集上进行检验,结果表明本文的算法性能要强于IQA-CNN等算法。
2 相关工作
2.1 分块图像质量的差异性
在进行训练之前,通常会对图像进行不重叠分块操作,然后对每个分块赋予整块图像的质量分数作为分数标签[15]。文献[15]中通过对比实验发现,将整幅图像分割成32×32的图像块,然后投入卷积网络进行训练能够得到较高的算法性能。但是用整幅图像的主观质量分数赋标签值的方法并不能准确代表各图像分块的质量评分,极易在训练中产生了较大的偏差。图1为LIVE数据集中所抽取的参考图像。

图1 Carnivaldolls图像中不同区域图像的质量差异明显
2.2 图像纹理对分块图像质量差异性的影响
纹理是一种反映图像中同质现象的视觉特征,包含了图像中事物表面结构组织排列的重要信息[16],反映了图像中局部区域的像素灰度级的空间分布[17]。获得图像纹理特征通常基于统计的方法,比如计算灰度直方图、灰度共生矩阵方法[18]、Tammre方法等。
图像纹理包含了许多图像中的细节信息。人眼倾向于从纹理特征更明显的区域来评价图像质量,而整幅图像不同区域纹理特征的复杂程度是不同的。因此分块后,不同分块图像质量应当存在差异性。为了验证整幅图像不同区域纹理特征程度的不同,选取了LIVE数据库中bikes图片,提取其中不同区域相同大小的图像分块后,计算其对应的灰度直方图,如图2所示。从图2中可以看出,图像的纹理特征通过像素以及周围邻域的灰度分布来表现[19],且不同区域的纹理特征存在差异性。

(a)参考图像bikes以及同一图像下不同区域的两分块
2.3 信息熵对分块图像质量差异性的影响
图像的信息熵蕴含了图像的结构信息,表达了信息的丰富程度[20]。信息熵可以用其来衡量局部图像的敏锐度[21],图像敏锐度越高,人眼越倾向于从该区域评价图像质量[22]。而图像分块后,由于各分块图像的信息熵不相同,所以不同分块图像的质量评分会存在差异。假设图像P(x,y)具有K个等级,图像的熵可表示为
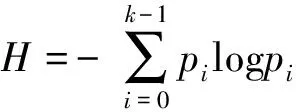
(1)
假定当pi=0时,pilogpi=0[21]。其中的pi表示灰度值为i的像素占比。
选取TID2008数据集中同一参考图像的不同失真类型并提取其信息熵图。如图3所示。从图3可以看出,对于同一参考图像的不同失真类型来说,其信息熵分布与人类视觉感知区域比较符合。

图3 相同程度的不同失真类型的图像及其信息熵图
3 多特征融合的卷积神经网络算法
3.1 算法的基础网络架构
本文采用类似于文献[14]的网络模型结构。在32×32的输入图像块上使用50个7×7大小的卷积核,卷积滑动的步长为1,以此得到了50个大小为26×26的特征图。为了更好地保留关联性更强的图像质量的局部特征,这里采用了最大池化的方式,池化窗口为26×26,使得每幅特征图作为一个激活单元。接着采用两个800个节点的全连接层方法,并使用ReLU作为其激活函数以加快训练时误差下降的速度,通过提出的多特征融合机制计算出的权重所修改的损失函数网络得到各分块图像的质量分数,最后,取各分块质量分数的平均值生成大图像的质量分数。其模型如图4所示。

图4 本文使用的卷积神经网络模型
在投入卷积神经网络之前,为了减少与图像质量无关或者关联性较弱的图像冗余特征,对图像分块进行局部归一化的预处理[23];反之,如果对其进行全局归一化处理,可能会降低CNN在训练期间的性能[15]。采用的局部归一化方法如下:

(2)

(3)
σ(i,j)=

(4)
其中:w是高斯函数窗口的权重值,本文采用的是3×3大小的窗口,I(x,y)是失真图像;M、N分别表示图像的高和宽;K、L是归一化窗口的大小且不可超过图像大小。
3.2 算法流程
(1)将数据集中的图像按照式(2)~(4)进行局部归一化处理后,将图像进行分割为不重叠的32×32大小的图像块。每个图像块对应的标签为整幅图像的图像质量分数。
(2)提取各图像分块的信息熵和纹理特征并计算重要性权重。
(3)将所有图像块投入到IQA-CNN网络模型进行训练并根据重要性权重改进L2损失函数以增强代表性强的图像分块在训练中的权重。
(4)在得到最优参数的模型后,任意选取图像进行测试,在得到分块图像的质量分数后取均值求得整幅图像的质量评分。
3.3 多特征融合
3.3.1 基于纹理特征和信息熵的归一化
首先,提取整幅图像所对应的分块的灰度直方图,通过公式(5)计算其均值T用以表示纹理特征。

(5)
其中,pi是指第i个像素的灰度值。
接着通过公式(1)直接计算分块图像的信息熵H。最后通过公式(6)对计算的两个特征进行归一化操作得到纹理特征权重W1(i)与信息熵权重W2(i)。

(6)
其中:N表示每幅大图像被分割成不重叠的分块的个数。I表示第i个图像块灰度直方图的均值T或者信息熵H。i的取值范围为1~N。
3.3.2 对于重要性权重的计算
由于纹理特征和图像信息熵都能对分块图像产生质量影响,从而导致对整幅图像质量评价的结果产生偏差。基于此,本文将纹理特征权重和信息熵特征权重相结合,提出了一个重要性权重W(i),用以减弱分块图像的质量偏差对整幅图像产生的质量影响。重要性权重计算如下:
W(i)=w1(i)×w2(i).
(7)
根据上述公式,从TID2008数据集中选取出同一程度不同失真类型的图片来分块和计算结合后重要性权重W并将其进行可视化操作,具体效果如图5所示。
图5中,颜色深浅的程度不同代表重要性权重不同,颜色越深,代表权重越大。由图5中失真图像与两特征结合后的权重图对比来看,失真图像的权重分布基本都与原图像的特征分布相对应,且比单信息熵归一化权重图更贴近人类视觉感知区域。因此说明,图像分块具有越高的权重,其代表性越强。

(a)Refimg
3.4 带权重的损失函数
若分块图像的重要性权重越高,则其对于整幅图像来说越具有代表性。因此,本文提出给原网络中的L2损失函数添加权重值:

(8)
其中:ypred是每个分块的预测值,yi是每个分块的标签值。
权重值越高,代表性强的分块实际质量分数与原始标签值的偏差越大,网络就会通过产生更高的损失来弥补这样的偏差。通过这样的修改,可以使代表性更强的分块在训练中发挥更强的作用,让训练变得更加准确有效。
4 实验过程及结果分析
本文的所有实验结果及部分对比实验基于Windows 10 Intel Core i5-10210U CPU1.60 GHz,内存为16 GB,使用了Python中的机器学习库Pytorch。
4.1 评价数据库
在本文的实验过程中,使用到了LIVE(http://live.ece.utexas.edu/index.php)和TID2008(http://www.ponomarenko.info/tid2008.html)两个公开数据集。LIVE标准数据库中有29幅参考图像,并在此基础上加入5种不同类型和等级的失真,生成了包括高斯白噪声(WN)、高斯模糊(GBlur)、JPEG失真、JPEG2000失真以及快速衰落(FF)等失真类型的779幅失真图像。TID2008数据库有25幅参考图像,并且以此添加17种失真类型生成1 700张失真图片。为对比LIVE数据库,从TID数据库抽取了400幅图像来进行测试以验证本文算法的泛化性能,两个数据库详细信息如表1所示。

表1 LIVE和TID2008数据库信息对比
LIVE数据库还提供了每幅图像对应的平均主观得分差值(Differential Mean Opinion Score,DMOS)作为其主观质量评分,分值在[0,100]。图像DMOS值越大,表示其质量越差,如图6所示。

图6 LIVE数据库中不同程度的同一失真类型图像及其DMOS值
TID2008数据集也提供了平均主观得分(Mean Opinion Score,MOS)作为其主观质量评分,分值在[0,9]。MOS值越高,代表图像质量越好,如图7所示。

图7 TID2008数据库中不同程度的同一失真类型图像及其MOS值
4.2 算法评价指标
为了能够客观地衡量算法的性能,本文选用了两个通用性能指标来对提出的算法进行评估,分别是Spearman 秩相关系数(Spearman’s rank-order correlation coefficient,SROCC)和 线 性 相 关 系 数(Linear correlation coefficient,LCC)。这两个指标都是用来衡量算法和人类视觉系统(Human visual system,HVS)的主观评价的一致性,SROCC评价算法输出和主观评价的单调性;LCC评价算法输出和主观评价的线性相关性[24]。
秩相关系数(SROCC)计算公式如下:

(9)
其中,di是第i个图像的主观质量评分和预测评分的差值。
线性相关系数(LCC)计算公式如下:

(10)
其中:si是第i个图像的主观质量评分,xi则是其预测评分。
一般来说,两个指标的值越高,代表方法性能越高;反之,则较差。
4.3 实验结果
训练过程中,将LIVE数据集按照0.6∶0.2∶0.2比例划为训练集、验证集和测试集,训练的学习率设置为0.01,批样本数量为64。在此基础上,每次训练的epoch为1 500轮。进行1 000次训练操作,并测试得到每次的算法性能指标值,最后取均值作为其最终的性能评价,该操作显著降低了训练过程对测试过程的影响。实验过程中,为了验证本文算法的准确性和有效性,选择了一些有代表性的全参考和无参考算法来进行对比。全参考方法包括SSIM、PSNR等方法;无参考评价方法包括CORNIA[25]、BRISQUE[26]、DIIVINE[27]、VI-IQA[28]、MS-C[29]等方法。
从表2、表3中可以看出,本文提出的方法对于不同失真类型基本都能获得良好的主客观一致性,对于SROCC和LCC性能指标基本提升0.5%以上。在对数据集综合评价的情况下,本文提出的多特征融合的卷积神经网络的方法相比其他全参考、无参考方法都有了明显的提升,SROCC和LCC提升至少0.9%以上。并且进行消融实验后发现,融合两特征权重的算法性能强于单特征权重的性能。为了验证算法的泛化性能,对TID2008数据集进行上述实验。

表2 LIVE数据库上SROCC对比

表3 LIVE数据库上LCC对比
从表4、表5中可以看出,在TID2008数据集上,无论是对单独失真类型的评价还是对于数据集综合评价来说,本文提出的修改权重的损失函数的方法相对于其他算法得到了很大的提升,SROCC与LCC至少提升0.6%,且基本优于使用单特征权重的算法性能。对于提取的失真图像可以根据更加贴近人眼视觉区域的特征权重,得到更为贴切有效的质量分数。在TID2008数据集的基础上对本文算法得到的主观质量分数和客观质量分数绘制散点图,如图8所示,发现本方法的散点对于y=x曲线的拟合效果较好。基于以上两种数据集的实验结果,可以充分说明本文算法的泛化性及有效性。
5 结 论
本文基于IQA-CNN方法提出了改进:通过对图像纹理特征和信息熵计算重要性权重,并修改损失函数为带权重的损失函数,使得更能够代表整幅图像的图像分块能够在训练过程中发挥更大的作用。通过改进的算法模型与几种典型的图像质量评价方法比较,在LIVE数据集上综合验证,SROCC与LCC指标为0.962和0.960,算法性能提升至少0.9%;在TID2008数据集上综合验证,SROCC与LCC指标为0.922和0.926,算法性能提升至少0.6%。消融实验也证明,结合两特征权重的算法性能高于单特征的算法性能。本文算法改进了原有算法的不足,基本能够准确地评估各种类型及程度的失真图像,预测结果与人类视觉感知有很好的一致性。
