基于EMD和时空图神经网络的污染物浓度预测研究
2022-01-26王彤彤严华
王彤彤,严华
(四川大学电子信息学院,成都 610065)
0 引言
近年来,伴随着社会对空气质量的讨论度持续升温,政府对空气治理问题高度重视,出台了一系列针对大气污染防治工作的防治政策、措施和机制体系,我国大气污染防治工作已经取得了阶段性胜利,进入到从单一污染物防控向多污染物协同控制的转折点[1]。根据《2019中国生态环境状态公报》[2],2019年全国空气质量指数超标天数比例为18%,其中首要污染物细颗粒污染物(PM2.5)和臭氧(O3)的天数分别占2019年总污染物天数的45%和41.7%。显然,PM2.5和O3已经成为我国最严重的空气污染物。PM2.5成因复杂且含有大量有害污染物,地面臭氧则是一种光化学污染物,二者对人体的呼吸系统都有强烈的危害性,严重影响人体健康[3-6]。根据研究表明,二者不仅拥有共同来源,并且在大气中相互影响,存在着复杂的关联性[7]。PM2.5与O3的协同防护已经成为改善我国空气质量和打赢蓝天保卫战的关键[8-9]。因此,一个可以同时准确预测细颗粒污染物和臭氧的空气质量预测模型,是当前大气污染治理工作的急迫需求。
随着深度学习技术在各个领域的深入应用,基于深度学习的数据预测模型可以模拟大气污染物扩散的非线性机制。作为循环神经网络的改进模型,长短期记忆网络[10-11]等在空气质量预测上得到了广泛的应用。但大气污染物数据是典型的非线性非平稳的气候时空序列数据,预测其浓度也受到气象和地理信息的影响[12-13]。单一模型无法同时兼顾空间依赖性、时间依赖性及邻域知识三者对污染物浓度的影响。针对其空间和时间特征,Yanlin Qi等[14]提出了将挖掘空间依赖关系的图神经网络与挖掘时间依赖关系的LSTM相结合的混合模型GCN-LSTM,并取得了较好的预测结果。但依然没有考虑到先验知识的影响,且只针对单任务预测进行建模,模型泛化能力不足,预测精度存在较大的提升空间。
针对上述问题,本文提出了一种基于EMD的自增强多任务大气污染物浓度预测模型。首先,利用encode-decode结构实现多步预测效果。增强对前向和后向序列信息的利用。其次,通过经验模态分解(EMD)可以将非平稳非线性的数据转化为多个相对平稳线性的数据,起到了附加特征的作用,对挖掘时空数据隐藏的序列关系有极大的辅助作用。再次,通过综合考虑气象信息和地理信息等邻域知识和空间依赖性,构建一个有向图,通过知识增强型的图神经网络学习城市间的污染物的迁移核扩散机制,通过门控神经单元学习污染物间的时间传输机制。实验验证了所提方法的有效性和优越性。
1 数据与研究方法
1.1 研究区域
现有的研究区域通常局限于一个城市或一个地区[14-17],其预测模型也未充分揭示其在大空间尺度中的空间关联学习能力。为了解决这样的问题,我们构建了覆盖中国污染严重地区的大范围区域(103°E—122°E和28°N—42°N),该区域覆盖面积大,其中包含了长三角、珠三角、成渝、长中游等五大地区共184个城市。图1为区域地理空间范围及节点之间的潜在空间关系,城市之间若存在蓝色连接线即表示两城市间有可学习的空间依赖关系。从图中可以看出污染物甚至可以使实现跨区域的远距离传输。

图1 研究区域及空间相关性
1.2 研究方法
1.2.1 问题定义
为了准确的预测大气污染浓度问题,我们需要定义一个有向图。其中V为节点合集,本文中节点为城市,节点集合代表城市气象属性;E为边的合集,代表城市间的潜在交互关系。t时刻下污染物浓度表示为,其中N为点数。为了提高模型的预测能力,将领域信息编码进有向图中是必要的,不同的领域信息分别表示为图中的节点属性及边属性。设分别为t时刻下节点和边的属性矩阵,其中P,Q是对应的属性项。M= ||E是链接边的数量。值得一提,在预测阶段,我们将输入已知未来气象信息和作为邻域信息同时输入模型中。综上,对于任意时间t,预测m步长的污染物浓度可以表示为:
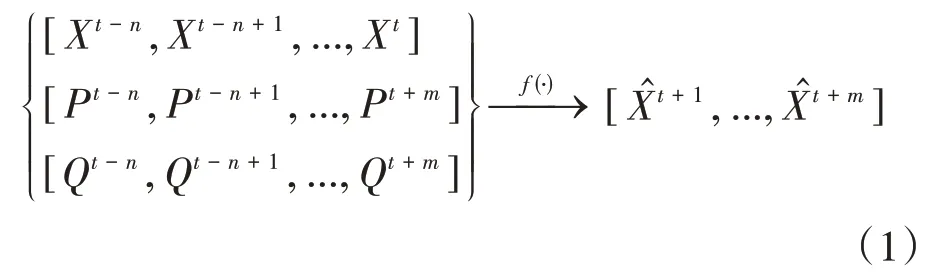
1.2.2 经验模态分解
经验模态分解(empirical mode decomposition,EMD)为一种经典的处理信号方法[18],无需任何事先设定的基函数就能够将非平稳非线性的数据分解成若干个固有模态函数(intrinsic mode func⁃tion,IMF)和一个残余分量,各个imf相互独立且有较强的规律性,视为我们的自增强数据。本文中EMD模块步骤如下:
(1)对污染物浓度数据的极大值与极小值绘制出上下包络线。
(2)求出上下包络线的均值,用x(t)减去它,即得到第一个imf序列分量imf1。
重复上述步骤,将剩余分量作为新的时间序列,直至当最后剩余部分为单调序列或常序列时,终止循环,得到最终的固有模式函数和一个残余分量F T={imf1,imf2,…,i mf l,rest}。EMD处理过程其表达式如下:
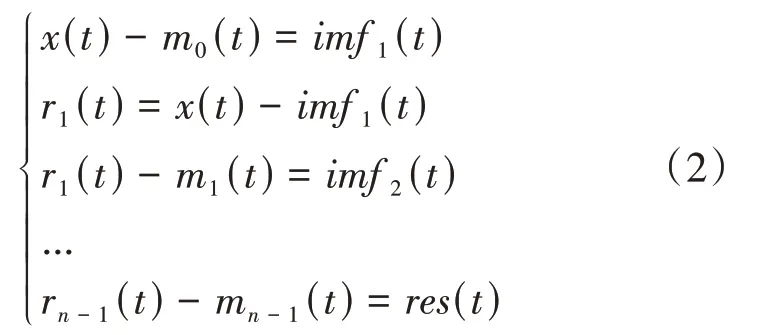
得到的固有模式函数,我们称为附加特征序列,l为序列个数,由数据自身特性决定。
1.2.3 图神经网络GNN
图神经网络(graph neural network)是指对图数据搭建神经网络模型并进行分析的方法[19]。图神经网络可以捕获图的拓扑信息,通过利用有向图中的节点信息和边信息捕捉污染物的水平传输规律,对提取有向图数据中的大范围空间依赖信息有很强的优势[20]。
根据1.2.1的定义,我们将邻域信知识作为节点和边的属性来建立有向图,其中节点属性代表该节点的气象特征,详情见表1。研究表明,风向及风速对污染物水平传播有决定性影响[21-22],因此总结了相关风场信息作为边属性,详见表2。

表1 节点属性

表2 边属性
1.3 模型构建
EMD-GNN-GRU模型流程如图2所示:在编码阶段,将已知污染物浓度数据进行EMD数据自增强处理,同时将污染物浓度数据及对应的邻域信息输入到GNN网络中学习邻域信息对污染物的影响及污染物的空间传输机制。从图神经网络传输出来的数据与EMD处理后的附加序列压缩成固定维度的向量,一同穿入GRU网络中学习底层空间依赖关系及时间依赖关系,其编码长度即为设定的时间窗长度。编码器后输出为中间向量状态Cr、Hr,并输入到解码器中,解码器由GNN+GRU混合模型共同组成,经过一个多层感知器后输出,解码过程即为多步预测过程。

图2 EMD-GNN-GRU模型结构
2 实验结果与分析
2.1 评价指标
为了能够准确评价预测模型的精度,本文实验选取三组度量评估模型的性能:①训练和测试损失显示模型的泛化能力。②平均绝对误差(MAE)和均方根误差(RMSE)检验预测的绝对和相对精度。③常用的气象度量来衡量污染阈值附近的性能,包括临界成功指数(CSI)、检测概率(POD)和空报率(FAR)。
RMSE和MAE指标的表达式如下:
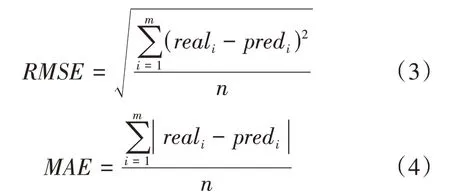
其中real i为地面实况值,pred i为模型预测值,m为设定预测序列长度。RMSE和MAE数值越小说明预测值与实况值差别程度越小,表明预测效果越好。
CSI、POD和FAR指标的表达式如下:

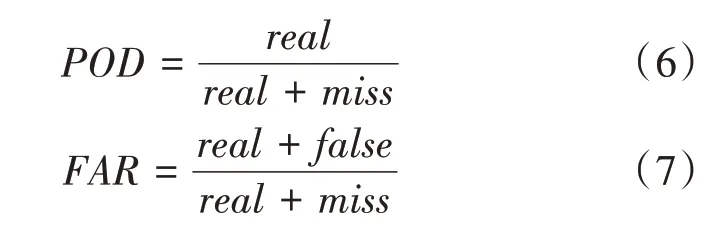
其中r eal示为地表实况值,false为误报的污染值,miss为漏报的污染值。我们使用污染物的阈值将预测值和地面实况值二值化后生成0-1矩阵来判断其是否已构成污染。基于我国环境空气质量标准,PM2.5的阈值选择为75µg/m3,臭氧O3的阈值选择为160µg/m3。CSI、POD的数值越高,C S I的数值越低,表示预测数据在阈值附近的准确度越高,模型性能越好。
为了确保检测指标的公平性和有效性,其评价指标是每个模型重复3次实验,在全部184个城市中提取所有预测步长的平均值得到的。
2.2 实验设置
实验部署在NVIDIA 2080 Ti上,模型使用Py⁃thon 3.6和Pytorch框架实现。实验开始前的预设值阶段,将有向图中的节点和边缘的特征重定义为均值为0,标准差为1。固定输入时间窗N设置为8、16、24,预测步长m也相应设置为8、16、24,分别代表用已知前24 h、48 h和72 h的大气污染浓度预测。
2.3 EMD自增强数据分析
选取四川省成都市作为代表,将O3与PM2.5以一周、一个季度及一年为时间长度,以EMD方法进行数据自增加,imf从小到大代表了不同频率下的数据特征。通过观察图3可以看出,无论是PM2.5还是O3数据都具有较大的波动性和非线性,提取特征难度较大。但是通过数据分解后,图3的第4列i mf2很清晰的反映出O3浓度以天数为周期的性质,而第2列i mf6则反映了PM2.5数据在一个季度内的波动趋势。通过对第2列和第6列的数据观察我们可以印证PM2.5与O3有相互抑制作用。值得一提的是,在O3一年数据中,两个峰值间的突变峰谷信息也被imf8分解出来,可见不管是数据的波动趋向、周期还是突变等性质,通过EMD都能很好的表达出来,由此,我们确认通过EMD方式对数据进行自增强处理能够更好提取数据的隐藏信息进而对模型预测起到辅助作用。

图3 基于EMD的数据自增强可视化结果
2.4 预测结果分析
为了测试复合模型的预测效果,本研究与常见的基于神经网络的气象预测模型相对比,包括MLP、GRU、GC-LSTM,其整体表现如表3所示。实验结果表明,EMD-GNN-GRU模型不仅能够同时获取时间与空间的依赖关系。还兼顾拟合了邻域信息,在所有评判维度上都获得了最好的结果。在预测PM2.5未来72 h的基准结果中,和GCN-LSTM模型相比,复合模型在测试集损失、均方根误差RMSE、平均绝对误差MAE和临界成功指数CSI中分别提高了41.29%、21.33%、22.54%和26.71%。提出模型不仅提升了模型的学习泛化能力,并且在预测精度和临界值取定的全方面有了显著的提升。这是由于在预测阶段,我们不仅对大气污染数据进行了EMD处理,增加了数据维度,分解污染物数据潜在信息并且充分利用了邻域信息对数据预测的影响作用。这一结果显示了复合模型在挖掘数据潜在信息,捕捉数据时空相关性及充分利用邻域知识三个角度的全面优势,表明了其可靠的预测能力。
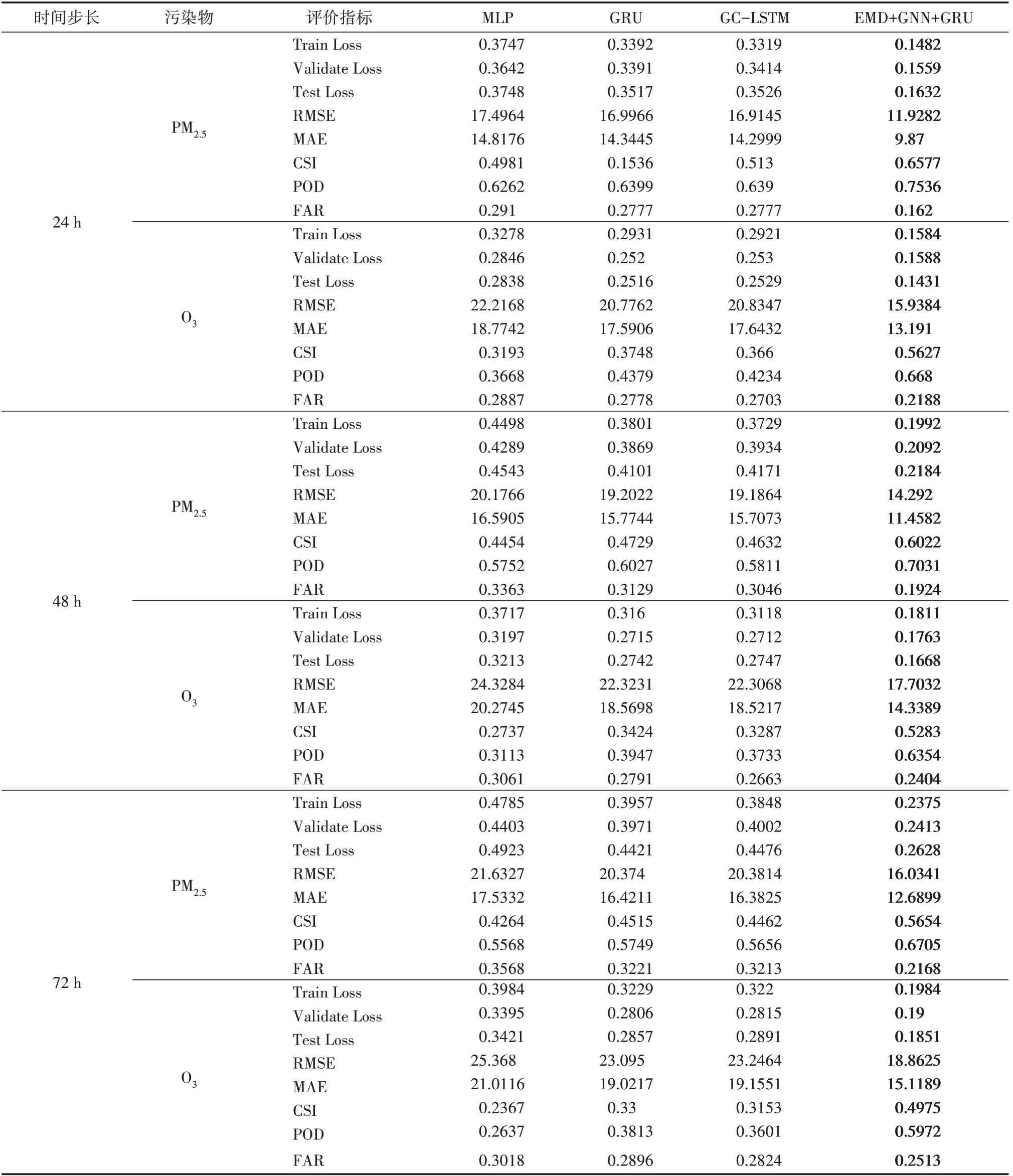
表3 实验结果
3 结语
本文利用经验模态分解和时空图卷积模型解决对非线性大气污染浓度预测问题。首先针对预测数据非线性的特性,借助EMD对数据进行自增强处理,有助于挖掘数据的隐藏逻辑。此外,为解决目前神经网络预测模型未考虑到的邻域信息对预测结果的影响,我们提出了GNN+GRU的时空图神经网络混合模型,做到了同时捕捉数据的时间依赖性、空间依赖性及邻域信息三个维度信息,有效提升了模型的预测能力。为了验证模型的有效性,我们选择PM2.5及O3作为预测对象,在真实数据集中进行实验,通过对比发现所提模型中获得最好效果。
