融合字词特征的中文嵌套命名实体识别
2022-01-26黄铭刘捷戴齐
黄铭,刘捷,戴齐
(西南交通大学计算机与人工智能学院,成都 611756)
0 引言
随着数据挖掘与人工智能的发展,人们对数据潜在价值的重视程度日益提升。作为知识抽取的重要组成部分,命名实体识别成为当下研究热点之一。命名实体识别常作为序列标注任务处理,需要同时预测实体的边界及实体的类别。目前,命名实体识别常采用Bi-LSTM作为文本特征提取器,并使用CRF(conditional random fields)对标签的相对关系进行约束,组合形成Bi-LSTMCRF[1]作为模型进行训练。此外,针对训练文本的词嵌入,采用单词的字符特征与预训练的词向量结合的形式,常用的字符特征提取方法包括CNN[2-3](convolutional neural networks)、LSTM[4](long short-term memory)等。不同于英文命名实体识别,中文命名实体识别的训练文本没有明确的词边界,需要进行分词处理。因此,中文命名实体识别常伴随错误传播问题,分词错误将直接导致命名实体识别错误,且不同的分词方法分词结果不同可能导致词嵌入时OOV(out of vocabu⁃lary)。
研究表明,针对命名实体识别任务,基于字粒度的词嵌入方法性能要优于基于词粒度的词嵌入方法[5-6]。然而,基于字粒度的词嵌入方法同样存在问题。首先,基于字粒度的词嵌入方法能够传递的信息有限,会忽略文本中许多隐含信息。此外,相同字在不同词语中表达的含义也可能不同。例如,在铁路领域,“正线”和“到发线”中的“线”指铁路中的轨道线路,而“接地线”中的线表示电路中的电缆。这使得基于字粒度的词嵌入方法的文本特征提取难度变大,而LSTM虽然能够学习上下文信息,但对局部特征的提取能力不足,仅使用Bi-LSTM存在对潜在特征的提取能力不足的问题。此外,命名实体中常伴有实体嵌套,CRF结合常规的BIOES或BIO编码方式无法完成对嵌套实体的标注。
针对上述两个问题,本文采取基于字的词向量嵌入方法,使用ANN对词向量进行学习,并使用CNN提取局部的词汇特征,通过结合字词特征并使用Bi-LSTM学习文本上下文信息,并采用合并标签标注方法解决实体嵌套问题。最后,本文在多个数据集上进行对比实验,验证了模型的有效性。
1 相关工作
命名实体识别指从文本中识别出特定类型实体的过程,常作为序列标注问题。根据使用方法不同可将其分为两类:统计学习方法和深度学习方法。统计学习方法的常用模型包括HMM(hid⁃den markov models)和CRF。Ratinov等人[7]使用BIOES标注结合词典与词性标注特征在CoNLL03等数据集上取得当时最优效果。Zhou等人[8]利用手工提取特征结合HMM在多个数据集上取得改进。王蓬辉等人[9]使用生成对抗网络自动生成大量数据标注,并将其应用于医疗实体识别并展现出良好的效果。虽然统计学习方法在过去的工作中展现出良好的效果,但此类方法需要结合领域知识和大量特征工程,需要消耗大量的人力资源,且普适性较差。随着深度学习的发展,神经网络模型在序列标注任务中展现出良好的效果,基于深度学习的命名实体识别方法应运而生,许多学者提出基于神经网络的自动学习方法。Huang等人[1]提出使用LSTM-CRF模型进行命名实体识别,并取得当时最优效果。张应成等人[10]使用LSTM-CRF进行商情实体识别。Chiu等人[2]和Ma等人[3]使用CNN提取字符特征,结合LSTM-CRF模型提出LSTM-CNNs-CRF模型。买买提阿依甫等人[11]将LSTM-CNNs-CRF模型应用于维吾尔文命名实体识别。罗熹等人[12]使用结合多头自注意力机制与Bi-LSTM-CRF模型,对中文临床文本进行命名实体识别。Yang等人[13]提出使用nbest策略改进CRF,并整合各类表征学习方法提出NCRFpp开源框架。随着BERT等的预训练模型出现,许多学者基于BERT模型提出了许多高性能模型。Emelyanov等人[14]整合Bert、Bi-LSTM、多头注意力机制及NCRF,在命名实体识别任务及文本分类任务中取得良好效果。此外,由于中文文本的特殊性,针对中文命名实体识别的研究亦层出不穷。例如,Liu等人[5]和Li等人[6]针对中文命名实体识别的词嵌入粒度进行研究,证明了基于字的词嵌入方法具有更好的性能。Zhang等人[15]通过使用Lattice LSTM进行表征学习,同时使用了基于字的词向量嵌入和基于词的词向量嵌入方法,并多个数据集上证明有效。
命名实体识别常伴有实体嵌套问题,如图1所示。

图1 嵌套实体示意图
实体嵌套问题在各个领域普遍存在,如生物[16-17]、医疗[18]等。针对命名实体识别中的实体嵌套问题,国内外许多学者提出了解决方案。目前,现有的嵌套实体识别的处理方法可分为四种。第一种方法将命名实体识别任务作为序列标注任务,使用多层的扁平实体识别模型识别嵌套实体。Alex等人[16]提出使用多层CRF进行嵌套命名实体识别,每层CRF负责标注特定类型的实体。Ju等人[17]通过动态堆叠扁平实体识别网络,动态识别大实体中的小实体,直至没有实体被识别出为止,有效解决实体嵌套识别问题。第二种为基于超图的命名实体识别方法。Lu等人[19]及Muis等人[20]先后提出基于超图的嵌套实体识别模型。第三种为Wang等人[21]采用的Shift-Reduce系统,Shift-Reduce系统将嵌套实体识别任务转换为Action序列预测任务,结合Stack-LSTM取得了良好的识别效果。最后一种为基于MRC(machine reading comprehension)的方法,Li等人[22]提出将命名实体识别任务转换为MRC问题,针对每种类型实体,通过问答的方式分别提取文本中的句子类型。文中提出的实体头尾指针标注方法目前在多个领域得到了广泛应用。
虽然许多学者提出了针对命名实体识别的解决方案,但针对中文命名实体识别基于字进行词嵌入潜在问题的研究较少,结合字词向量进行文本表征的Latice LSTM在训练时需要查找词表,导致训练效果较慢。本文针对中文命名实体识别的字嵌入特征提取困难问题,提出使用ANN、CNN及Bi-LSTM的组合网络CACL(Combination of ANN CNN and LSTM)作为文本表征学习的方法,增强了神经网络特征提取能力。此外,针对命名实体识别的嵌套实体问题,本文采用经典的序列标注方法,通过使用合并序列标签结合CRF的形式进行嵌套实体的标注。
2 模型
本文模型由表征学习方法及实体识别方法组成,模型示意图如图2所示。

图2 模型示意图
如图2所示,模型共包括5个部分:词嵌入层、ANN、CNN、Bi-LSTM与CRF。其中,词嵌入层、ANN、CNN及Bi-LSTM为模型的表征学习方法。其中,Bi-LSTM层数可根据实际情况增减。为实现嵌套实体识别,模型最后一部分使用合并标签标注方法结合CRF进行实体标注。
2.1 表征学习方法
2.1.1 词嵌入层
词嵌入层旨在将原始文本转换为分布式的向量表示。给定长度为n的句子S={w1,w2,w3,…,wn},其中wi表示原始文本中的第i个字。通过查找预训练的词向量,词嵌入层将原始文本S转换为分布式的向量表示S={w1,w2,w3,…,wn},其中未找到对应词向量的字通过随机初始化的词向量进行嵌入。
2.1.2 ANN
ANN是一种浅层的全连接神经网络,通过连接大量神经元的加权运算与激活函数构成。本文利用ANN对文本的词向量进行进一步学习,使其能够更准确表示原始文本特征,其运算公式如式(1)所示。

其中anni为ANN的输出向量,wi为词嵌入后获取的文本的向量表示;Wa和b a为神经网络的自学习参数,Wa为权重矩阵,ba为偏移量矩阵;tanh为激活函数。
2.1.3 CNN
CNN是一类包含卷积运算的神经网络,通过使用卷积核平移进行输入向量的局部加权求和进行表征学习,对局部特征提取能力较强。由于本文是针对文本进行卷积操作,因此此处使用一维卷积进行特征提取,计算公式如式(2)所示。

其中l为卷积核长度ωm为卷积核中第m个待学习参数。此外,为保证卷积后文本长度不变,卷积核长度应设置为单数,并使用长度为(l-1)/2的空值对文本前后进行填充。
2.1.4 Bi-LSTM
Bi-LSTM是LSTM的变体,由一层前向LSTM和一层后向LSTM组成,通过连接两层LSTM的输出,可以有效学习序列前后的关联关系,其计算公式如式(3)所示。

2.2 解码层
如上文所述,本文采用合并标签标注方法结合CRF进行嵌套实体标注,以下将对方法进行详细介绍。
2.2.1 合并标签方法
合并标签方法通过将嵌套实体单个字符的多个标签合并形成新的标签,解决了单层标签无法标注嵌套实体的问题,如图3所示。

图3 合并标签示意图
如图3所示,“隧道”中心脏为“build”类型实体,“隧道衬砌”为“struct”类型实体。若通过常规的BIOES标注,“隧”和“道”都需要两个标签才能完成标注,CRF无法进行解码。因此,本文通过合并标签形成新的标签,再使用CRF对其进行解码。
2.2.2 CRF
CRF是一个概率模型,通过给定输入x与前一时刻的状态yt-1预测当前状态yt。其概率计算公式如式(4)所示。
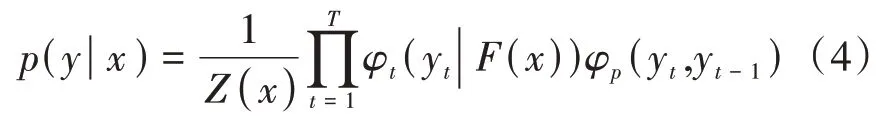
其中φt和φp为特征函数,用于预测输入x与y之间的关联概率,用于表示当前状态与前一个状态的转换概率。x为模型输入,yt为当前状态,yt-1表示前一时刻状态。最终,我们选用概率最大的状态作为当前状态预测值。此外,为了使CRF的输入维度与标签类别数保持一致,本文通过一个全连接层对Bi-LSTM的输出进行降维,计算公式如式(5)所示。

其中Wl与b l为神经网络待学习矩阵,oi为i时刻Bi-LSTM的输出向量。
3 实验
3.1 实验概述
3.1.1 实验方案及评价指标
本文实验主要涉及5种文本表征方法,包括Bi-LSTM、IDs-CNN、Bi-GRU、CACL及Lattice LSTM[15]。其中,Bi-LSTM、IDs-CNN、Bi-GRU为序列数据表征常用的表征方法,CNN-LSTM为本文模型,而Lattice LSTM为Zhang等人提出的另一种融合字词特征的表征网络。此外,为验证模型参数对模型性能影响,本文对模型中涉及的超参数进行实验,并分析其对模型性能的影响,模型各参数如表1所示。

表1 实验模型参数
其中,学习率及词嵌入维度选用中文自然语言处理中常用的学习率0.001及词嵌入维度300。词向量采用Python gensim库中的word2vec模型针对WIKI百科中文语料库训练获取。神经网络神经元数量取100-500,变化梯度为100。Dropou取[0.1-0.9],变化梯度为0.2。CNN的卷积核大小kernel size设为[3,5],并将填充长度padding分别设为[1,2]以保证卷积后句子长度不变,IDs-CNN的层数设置为4层。
实验评价指标采用精确率(Precision)、召回率(Recall)及F1值,计算公式如式(6)、式(7)及式(8)所示。

其中TP表示将正类预测为正类数,即识别出的正确的实体数量;FP表示将负类预测为正类数,即识别出的错误的实体数量;F N表示将正类预测为负类数,即未识别出的实体的数量。
3.1.2 实验环境设置
本文实验主要针对铁路领域文本,使用《城际铁路设计规范》TB10623-2014(以下简称TB10623)进行标注获取训练数据。此外,为进一步验证模型有效性,本文选用第六届中国健康信息处理会议(CHIP2020)命名实体识别子任务的公开数据集进行实验,以下简称CHIP2020。数据集的简介如表2所示。

表2 数据集简介
如表2所示,CHIP训练集中包含15000条训练数据及5000条验证数据,包含疾病、临床表现等9类实体;TB10623数据集包含895条训练数据和228条验证数据,包含电气设备、设计参数等6类实体。此外,由于CHIP2020数据集的测试集不包含标注,本文将训练集按照8∶2的比例进行切分,分为训练集和测试集。
此外,本文采用的实验环境如表3所示。

表3 实验环境设置
3.2 参数验证实验
为验证模型参数对模型性能影响,并选取最优实验参数,本部分实验使用CHIP2020数据集,针对模型的隐藏神经元数量、Dropout参数及卷积神经网络卷积核大小进行分别进行梯度取值对比。
3.2.1 隐藏神经元数量参数验证
模型的隐藏神经元数量表示神经网络中每一层中包含的神经元数量,增加模型的隐藏神经元数量可以有效增强模型的学习能力,但神经元数量过多会导致计算量增加和过拟合现象。本文对模型中的隐藏神经元数量分别取100-500,变化梯度为100进行对比实验,实验结果如图4所示。
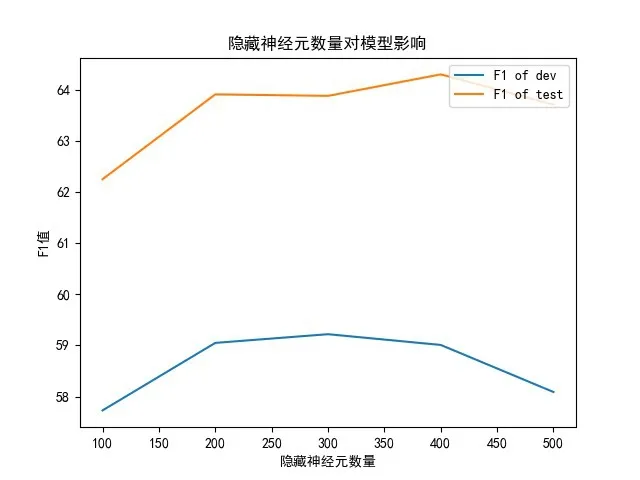
图4 隐藏神经元数量对模型性能影响
当隐藏神经元数量为200—400时,模型性能趋于较好,且趋于稳定。因此,出于对模型性能考虑,本文取200为隐藏神经元数量。
3.2.2 Dropout参数验证
Dropout表示模型训练时的丢失率,是Hinton等人[23]于2012年提出的防止过拟合的方法,过高的Dropout参数会导致模型学习能力下降,且收敛速度下降,而过低的Dropout参数将导致其效果不明显。因此,本文选用0.1—0.9区间对其进行实验,变化梯度为0.2。其实验结果如图5所示。
如图5所示,当Dropout取0.5时模型取得最优性能。因此,本文选用0.5为最终的Dropout参数。

图5 Dropout对模型性能影响
3.2.3 卷积核大小验证
CNN卷积核大小设置直接决定卷积计算范围,由于本文使用CNN对局部的词汇特征进行学习。因此,仅选用大小为3和5的卷积核进行实验,实验结果如表4所示。

表4 卷积核大小对模型影响
当卷积核大小为3时,模型效果最佳。因此,本文选用3为卷积核大小。
3.3 有效性验证实验
本部分实验采用合并标签方法作为嵌套实体识别方法,并使用Bi-LSTM、Bi-GRU、IDs-CNN及Lattice LSTM作为基线模型验证CACL作为表征学习方法有效性。其中,模型参数取各模型多次实验结果平均后最佳参数,实验结果如表5所示。
由表5可知,CACL作为表征学习方法的模型在两个数据集上展现出最优效果。

表5 有效性验证实验结果
在CHIP2020数据集实验中,CACL的F1值比次优模型的F1值分别高出1.21%和1.82%,同时模型的Precis i on和Recall均高于其他基线模型。而Lattice LSTM作为融合字词特征的另一模型,其F1值略高于除CACL外其他模型,且除验证集Recall指标略低于Bi-LSTM外,其他指标皆高于其他模型。此外,Bi-LSTM的训练效果略高于IDs-CNN及Bi-GRU。
在TB10632数据集的实验中,CACL的F1值在Dev及Test数据集中比次优模型分别高出1.82%和1.59%,且除Test数据集中的Recall指标外,模型Precis i on及Recall指标均高于其他基线模型。而Lattice LSTM的各项指标均同样高于除CACL外的其他模型。此外,与CHIP2020数据集不同,优于TB10632数据集中文本较短,因此IDs-CNN的训练效果略优于Bi-LSTM及Bi-GRU。
以上结果表明,融合字词特征可以有效提高命名实体识别能力,且CACL具有更好的文本表征效果。
4 结语
本文针对中文命名实体识别字向量嵌入方法文本表征学习困难问题,提出使用CACL作为文本表征学习方法,并对比现有嵌套实体识别方法,提出一种新颖的中文嵌套命名实体识别模型。实验结果表明,ANN-Bi-LSTM作为中文命名实体识别表征学习方法是有效的。此外,嵌套实体识别方法对比实验,本文选用Shift-Reduce系统作为嵌套实体识别方法,并与基线模型进行对比,证明本文模型的有效性。
当然,本文工作也具有一定的局限性。一方面,除了本文使用的本团队标注的铁路相关实验数据外,本文模型仅在CHIP2020数据集进行验证,针对其他领域数据集的有效性仍需进一步验证。此外,针对TB10632数据集的实验效果较差,需要进一步调整才能应用于实际应用场景。在未来工作中,我们将对模型做进一步改进并使用更多其他领域数据来验证模型。
