基于深度学习的远程监督关系抽取方法研究
2022-01-25苏江文
苏江文
(福建亿榕信息技术有限公司,福建福州 350003)
深度学习描述了待学习数据样本的表示层次规律及内在表现形式,在实际学习过程中,已获取的声音、图像、文字等数据信息,能够为应用指令提供更加可行的执行方向。其最终处理目标是让机器具备像人一样的学习分析能力,从而使数据信息的识别流程逐渐趋于完善[1-2]。总的来说,深度学习是一个相对较为复杂的机器学习算法,在图像、语音等信息识别方面具备较强的实际应用价值。
远程监督关系抽取是一种极为有效的语句提取方法,可在数据应用框架的基础上,对所有信息参量的具体释义行为进行详细描述[3]。然而随着实体化远程监督语句数值量水平的提升,个别语言信息的实际分辨能力开始不断下降,易导致识别等待时间的无限延长。为解决此问题,词义型抽取手段在非编码条件的作用下,对所有远程监督语句进行逐一定义,再联合既定的解码模板,分析其中所隐藏的词义条件,然而该方法的执行速率过慢,易造成语句信息的大量堆积。为避免上述情况的发生,引入深度学习理论,设计一种新型的远程监督关系抽取方法,在关系三元组、数据标注信息等多项应用条件的作用下,确定与待抽取标签匹配的语句学习行为,实现对句子级别特征的准确定义。
1 远程监督关系抽取数据集构建
1.1 远程监督方法
在远程监督方法中,必须假设两个关系实体在学习知识库中存在某种联系,且包含这两个实体的描述语句都能描述这种原始的信息关系。远程监督方法与词义型抽取手段一样,不需要大量人工标注数据集,就能实现对种子模板质量问题的研究,但在既定解析时间内,后者的抽取速度明显低于前者[4-5]。通过上述分析可知,基于深度学习远程监督关系的构建主要分为如下两个步骤:第一步,获取与词义语句相关的关系三元组;第二步,对所有语义文本中的数据信息进行标注处理。图1 为远程监督方法实践流程。
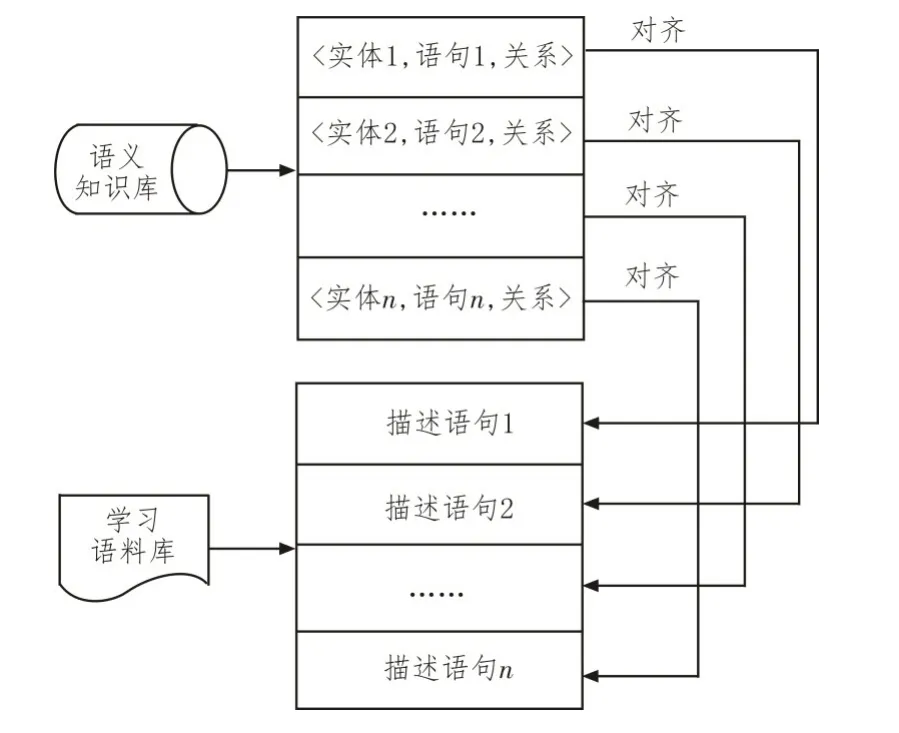
图1 远程监督方法实践流程
1.2 关系三元组获取
关系三元组描述了远程监督关系语句的实际连接形式,可在已知监督方法实践流程的基础上,确定特殊学习节点所具备的数据承载能力,从而确定最终抽取指令的实际操作步长值。在不考虑其他干扰条件的情况下,关系三元组获取结果受到远程监督关系语句输出量、语句调度步长值两项物理量的直接影响[6-7]。远程监督关系语句输出量常表示为χn,在深度学习权限值等于n的情况下,待抽取的语义数据越多,最终计算所得的关系三元组定义量也就越精准。语句调度步长值常表示为β,一般情况下,该项物理量的数值水平越高最终抽取处理所得的关系三元组信息总量也就越大。联立上述物理量,可将关系三元组获取结果表示为:
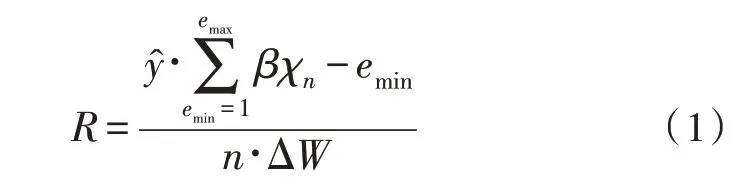
其中,emin代表最小的远程监督语句抽取系数;emax代表最大的远程监督语句抽取系数;代表语句定义权限量;ΔW代表单位时间内的监督语句传输变化数值。
1.3 待学习数据标注
待学习数据标注操作需要同时进行句子级别特征定义、多示例条件选择、分类查询3 个处理流程。其中,句子级别特征定义可为不同远程监督关系数据匹配不同的实体输入模型,并可借助字符级别权限,将所有加权输入信息整合到一起,最后形成独立的句子级特征向量条件。多示例条件选择可将同一个句子级别注意力转移给多个不同的语句权重量,再通过间接性屏蔽的方式,调取远程监督关系语句中的待学习词汇信息[8-9]。分类查询分别对应多个不同的深度学习型函数,可在句子级别特征条件的支持下,实现对待抽取语句标签的实时定义。设w1、w2、w3分别代表3 个不同的待学习数据信息参量,T代表单位抽取时长,联立式(1),可将待学习数据的标注结果表示为:
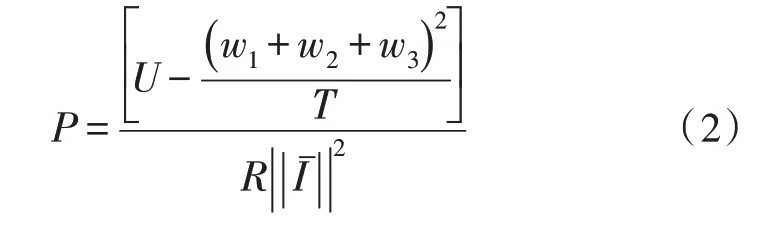
其中,U代表远程监督关系语句在单位时间内的最大定义量;代表语句传输均值。
2 远程监督关系抽取方法
在远程监督关系抽取数据集的支持下,按照监督框架搭建、句子级别特征定义、待抽取标签学习的处理流程,实现基于深度学习远程监督关系抽取方法的顺利应用。
2.1 监督框架
基于深度学习的远程监督关系语句抽取框架由语句级特征、深度学习注意、多标签分类三部分共同组成。其中,语句级特征包含S、H 两类应用型抽取关系节点,前者能够直接调取与远程监督方法相关的关系三元组参量,并可在不违背深度学习法则的基础上,确定语义数据的实际应用能力;后者可在接收语义数据信息的同时,建立与深度学习节点的物理连接,从而实现对远程监督关系语句的传输与调度[10-11]。深度学习注意单元中只包含一种N 型抽取关系节点,可在已知头标签、过渡标签、尾标签划分需求的同时,完成对远程监督关系语句调取规则的构建。图2 为监督框架结构。
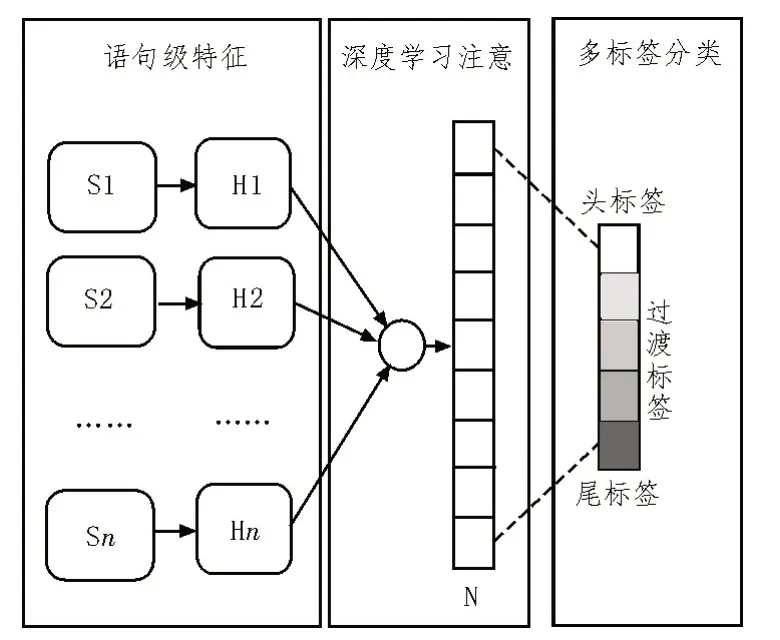
图2 监督框架结构
2.2 句子级别特征
句子级别特征是指应用分布式行为,构造远程监督关系语句的深度学习法则。可借助监督框架提取语句信息中的高级特征,并将其整合成既定的数据连接形式[12-13]。一般情况下,语句字符级别注意力能够与监督条件加权值保持实时对应关系,且每个时间步长量的词级特征都可在既定抽取时间内始终保持一致。在语句文本中,除了特定符号信息之外,所有字符之间均保持紧密相连状态,且始终没有明显的词性边界,因此很难将语句数据直接提取出来[14]。大多数远程监督关系语句均由字符组信息组合而成,且其组合的复杂程度越高,最终定义所得的句子级别特征量也就越清晰。设l0代表与远程监督关系语句相关的最小分布式行为常数项,f代表深度学习算法的实际作用权限量,联立式(2),可将远程监督关系的句子级别特征定义为:
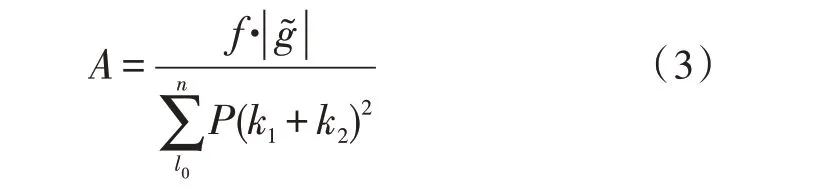
2.3 待抽取标签学习
在传统的远程监督关系学习方法中,可用一个语句示例表示一个真实的数据对象,且该示例与表示该示例对象相关类别权限的学习标签始终保持对应关系。一般情况下,一个训练集只能由一类带有已知标签的示例信息数据共同组成,通过对已有标签的训练集样本进行学习处理,可以得到一个目标应用函数,在语句信息实际抽取过程中,以此函数来正确分类未知的信息示例标签,能够实现对单示例标签语句结构体的准确学习[15-16]。在一个数据参量组别中,待抽取的远程监督关系语句信息越多,学习标签所具备的实际应用能力也就越强,反之则越弱。设υ0代表与语句特征参量相关的最小标签学习系数,υn代表与语句特征参量相关的最大标签学习系数,联立式(3),可将远程监督关系语句的待抽取标签学习行为定义为:
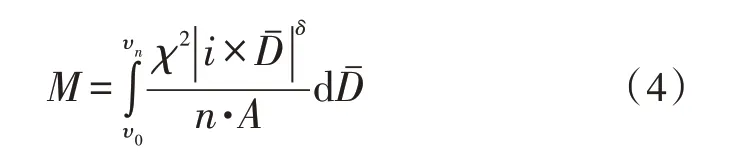
其中,χ代表监督关系语句的远程监督系数;i代表语句数据的实际抽取步长值;Dˉ代表语句数据在单位时间内的传输均值。至此,实现各项系数应用指标的计算与处理,在深度学习理论的支持下,完成远程监督关系抽取方法的搭建。
3 对比实验
为验证基于深度学习远程监督关系抽取方法的实际应用能力,设计如下对比实验。在相同语句传输环境中,截取两组数量级水平相等的待识别数据信息作为实验组、对照组实验对象,其中实验组控制主机搭载基于深度学习的远程监督关系抽取方法,对照组控制主机搭载词义型抽取手段。
3.1 实验参数设置
表1 反映了实验参数设置情况,出于应用公平性考虑,除所使用抽取控制行为不同外,实验组、对照组实验参数始终保持一致。

表1 实验参数设置表
3.2 实验结果分析
已知远程监督语句的可同时调度量能够反映学习主机对语言处理信息的准确提取能力,一般情况下,可同时调度量越大,学习主机对于语言处理信息的准确提取能力也就越强,反之则越弱。
表2 记录了实验组、对照组远程监督语句可同时调度量的实际变化情况。
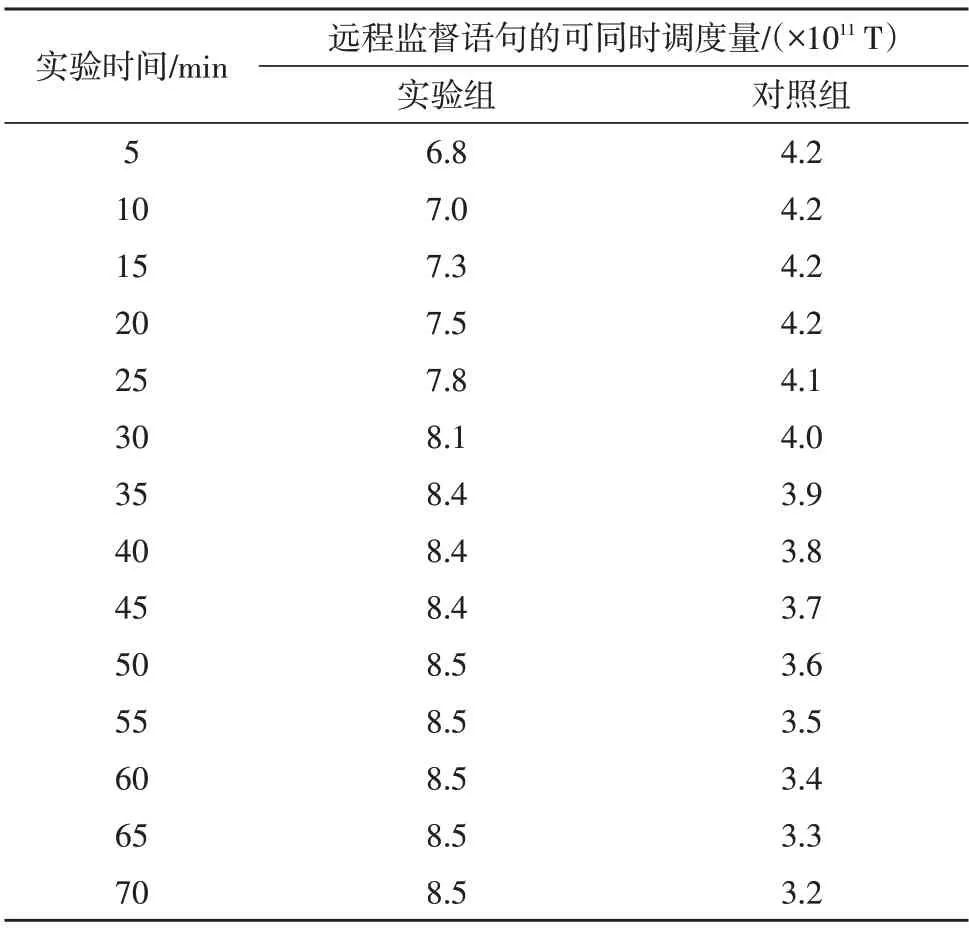
表2 远程监督语句可同时调度量对比
分析表2 可知,随着实验时间的延长,实验组远程监督语句可同时调度量保持先上升再稳定的变化趋势,且实验前期的上升幅度明显大于实验中后期,全局最大值达到了8.5×1011T。对照组远程监督语句可同时调度量则在一段时间的稳定状态后,开始出现持续性下降的变化状态,全局最大值仅能达到4.2×1011T,与实验组极大值相比,下降了4.3×1011T。综上可知,应用基于深度学习的抽取方法后,远程监督语句可同时调度量出现了明显增大的变化趋势,能够有效提高学习主机对语言处理信息的准确提取能力。
语句分辨等待时间反映了学习主机对于远程监督语句中实体语义关系的实际判定能力,一般情况下,分辨等待时间越短,学习主机对于远程监督语句中实体语义关系的判定能力越强,反之则越弱。图3反映了实验组、对照组语句分辨等待时间的实际变化情况。
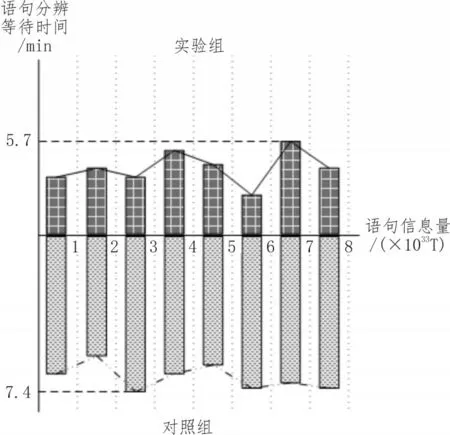
图3 语句分辨等待时间对比
分析图3 可知,在语句信息量水平相同的情况下,实验组分辨等待时间的数值水平明显低于对照组。从极值角度来看,实验组最大值为5.7 min,与对照组最大值7.4 min 相比,下降了1.7 min。综上可知,应用基于深度学习的抽取方法后,语句分辨等待时间得到了有效控制,能够增强学习主机对于远程监督语句中实体语义关系的实际判定能力。
4 结束语
为了解决传统方法存在的执行速率过慢,易造成语句信息大量堆积的问题,提出基于深度学习的远程监督关系抽取方法。与词义型抽取手段相比,基于深度学习的远程监督关系抽取方法可在关系三元组条件的作用下,实现对待抽取标签的学习与处理。从实用性角度来看,语句分辨等待时间的缩短能够促进远程监督语句可同时调度量的增大,可在准确提取语言处理信息的同时,实现对实体语义关系的有效判定。
