基于Word2vec 的图书馆图书推荐系统的实现研究
2022-01-25柴源
柴源
(西安航空学院 图书馆,陕西西安 710077)
高校图书馆图书推荐是利用现代信息技术,分析读者阅读行为,挖掘读者阅读需求,通过多元化渠道将馆藏图书推荐给师生的一种服务[1]。目前,图书推荐系统主要包括基于内容的推荐系统,它侧重于图书的属性,例如文献内容[2]、学科分类[3]等;以及基于用户的协同过滤系统,它侧重于依据读者借阅数据来推荐其他相似读者曾经借阅过的图书,例如用户画像[4]、读者兴趣[5]等,但是这些系统都存在一定的局限性。
1 图书馆图书推荐系统面临的问题
1.1 数据稀疏性问题
目前,高校图书馆的藏书数量普遍在百万册以上,例如清华大学图书馆,书刊资料已达510 多万册。读者数量却相对较少,并且大多数读者只对极少量的图书有过借阅行为,使得形成的“读者-图书”借阅矩阵不仅非常大,而且绝大多数数值为空缺值,整个矩阵非常稀疏[6],稀疏性问题直接造成训练过程中的计算浪费。
1.2 数据语义化问题
传统的推荐系统是基于词袋模型构造向量空间的,定义一个窗口作为某个词的语境,统计整个语料中这个词在窗口内出现的特征,例如词的频度、tf-idf等,再把这些特征用词袋模型表示成一个向量,然后计算向量的余弦距离[7]。这种做法忽略了词的位置信息,而一个词的含义是可以从它的上下文语境中推断出来的。
1.3 图书在时间上的局部共存问题
传统的图书推荐算法分析所有读者的借阅偏好,对“读者-图书”矩阵应用协同过滤方法,得到不同图书组别的关联信息。如果一个读者群体拥有很多共同喜欢的图书,就可以推断这些读者借阅兴趣很相似,并且他们所借阅的图书之间也很相似。但是,这种多读者共现现象只能反映出图书之间是如何联系的,并不能反映出图书在时间上是如何局部共存的,即他们在同一时间段前后还借阅了什么图书[8]。
2 基于Word2vec 的高校图书馆图书推荐系统设计
2.1 Word2vec
Word2vec 是一种词嵌入(Word Embedding)方法,它根据语料中词汇共现信息,将词汇编码成一个向量,可以计算每个词语在给定语料库环境下的分布式词向量[9],它包含两种训练模型:跳字模型(Skip-Gram)和连续词袋模型(Continuous Bag of Words,CBOW),如图1 所示。

图1 Word2vec模型
CBOW 模型是一个三层神经网络,它利用上下文或周围的词语来预测当前位置词语w(t)的概率,即P(w(t)|w(t-k),…,w(t-1),w(t+1),w(t+2),…,w(t+k))[10];Skip-Gram 模型的计算方法逆转了CBOW 的因果关系,它利用当前位置词语w(t)来预测上下文中词的概率,即P(w(i)|w(t)),其中t-k≤i≤t+k且i≠k[11]。
2.2 Word2vec在图书推荐应用中的可行性
Word2vec 模型本质上是基于上下文语境构建词共现矩阵而建立起来的,因此,可以采用Word2vec算法改进基于共现矩阵的算法模型。
在推荐系统中,常用算法首先是建立“用户-商品”矩阵,然后计算行和列的相似性,并根据相似性进行推荐[12]。如果将某一个用户选择的所有商品看作一条商品序列,商品与商品之间就出现类似文档中的上下文关系,通过构建“商品-语境”矩阵,利用Word2vec 获得每个商品的向量表示,然后将各个商品向量求和,计算商品之间的相似度,将与求和的值最接近的一个或多个商品作为推荐商品[13]。
在图书推荐系统中,可以将每本图书看作一个商品,将读者借阅的所有图书看作一条具有上下文关系的图书序列,建立“图书-语境”矩阵,并利用Word2vec 进行训练。首先,得到每本图书的向量表示;其次,将这些图书的向量进行求和;最后,通过余弦距离计算图书向量空间上的相似度,并与求和的值进行比较,选择比较接近的值的图书,形成推荐列表。
例如,甲的借阅图书序列为A1、A2、A3、A4、A5、A6,利用Word2vec 进行深度学习,选择Skip-Gram 模型,预测上下文的词的个数、输出结果的个数都为2,预测结果如表1 所示。
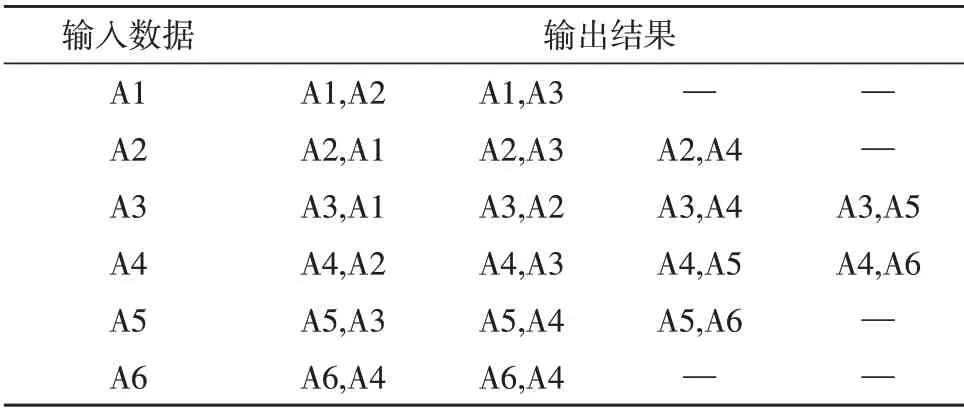
表1 Skip-Gram模型结果
表1 中,A4 的向量受A2、A3、A4、A5、A6 向量影响,A5 受A3、A4、A5、A6 向量的影响。Word2vec 通过上下文语境识别出A4 和A5 之间存在相似性。
Word2vec 将稠密向量作为输入层,解决了图书推荐中数据的稀疏性问题;构建基于时间和上下文关系的图书序列,建立“图书-语境”矩阵,解决了图书在时间上的局部共存和语义化缺失问题。所以,Word2vec 在图书推荐中具有极强的优势。
2.3 基于Word2vec的图书推荐系统设计
2.3.1 系统设计
系统设计主要包括借阅日志数据预处理,构建具有上下文语境的共现矩阵;利用Word2vec 工具对共现矩阵进行深度学习,提取每本图书的向量,并求和;通过Word2vec 计算相似度,推荐相似度较高的图书。系统流程如图2 所示。

图2 系统流程
2.3.2 详细设计
1)建立读者借阅图书的共现矩阵。从借阅日志中获取读者的借阅数据,经过数据预处理,建立基于时间序列的读者借阅图书的共现矩阵。
2)Word2vec深度学习。设定数据窗口大小,运用Word2vec工具,对借阅图书的共现矩阵进行深度学习,获得每本书的向量表示,然后将各个向量进行求和。
3)相似性结果推荐。计算图书之间的相似度,将其与2)中的值进行比较,选择比较接近的值的图书,同时过滤掉读者重复借阅的图书,形成推荐列表。
3 基于Word2vec 的高校图书馆图书推荐系统实验
3.1 数据来源及预处理
3.1.1 数据来源
该文抽取西安航空学院图书馆2019 年的借阅记录,共9 万余条,借阅记录包含图书条码、索书号、读者姓名、读者条码、题名、典藏部门等条目,如图3所示。数据分析汇总,如表2 所示。

图3 借阅记录数据(部分)
表2 中,11 229 个读者有借阅记录,表示可以构成11 229 个借阅图书序列。

表2 2019年的借阅记录汇总
3.1.2 数据预处理
数据预处理中,剔除掉没有研究意义的字段,例如馆藏地点、索书号等,选择题名、图书条码、读者条码、借阅日期等条目。题名是每册图书的书名,描述了图书的主要内容。图书条码是每册图书的唯一识别码,读者条码表示每位读者的身份ID,借阅日期表示图书的借阅时间。具体的预处理流程如下:
1)通过读者条码、借阅日期、图书条码确定读者的每一次借阅记录。
2)按照借阅日期将每位读者全年的借阅记录归并为一条借阅序列,形成读者借阅图书的共现矩阵,为了减少计算量,选择图书条码作为其值,如图4所示。

图4 读者借阅图书的共现矩阵(部分)
图4 中第一列数字表示读者的借阅证号,第二列以及后面的所有列表示读者按时间序列的借阅记录,每一行表示一位读者的图书借阅序列。
3.2 实验及结果分析
3.2.1 实验设置
Gensim 是一款开源的第三方Python 工具包,用于从原始的非结构化文本中,无监督地学习到文本隐层的主题向量表达[14]。主要用于主题建模和文档相似性处理,支持包括TF-IDF、LSA、LDA 和Word2vec在内的多种主题模型算法[15]。文中利用Gensim 中的Word2vec 类进行模型训练,参数设置如下:
size:词向量的维度,文中是指图书条码的向量维度,设置为300。
window:词向量上下文最大距离,window 越大,则和其他词产生上下文关系的可能性就越大。该文的实验数据中,读者的年均借阅量约为5 册,因此,window 值设置为5。
sg:模型选择,该文选择CBOW 算法,即sg=0。
min_count:需要计算词向量的最小词频,可以去掉一些很低频词。文中实验数据仅包含2019 年的图书借阅记录,数据的稀疏性较强,因此,min_count设置为2。
3.2.2 实验结果
该文通过Word2vec 对数据进行训练,利用tsne对Word2vec 模型进行降维可视化展示[16],如图5 所示。图中展示了部分数据,每个点表示一本图书,数字表示图书条码。图5 中,点之间距离的大小表示图书的相似程度,距离越小相似性越高。

图5 相似性图书可视化
实验中,假设读者借阅图书的条码为1824272(题名为《电气工程概论》),去掉重复借阅的图书,提取排名前5 的结果形成推荐列表,如表3 所示。
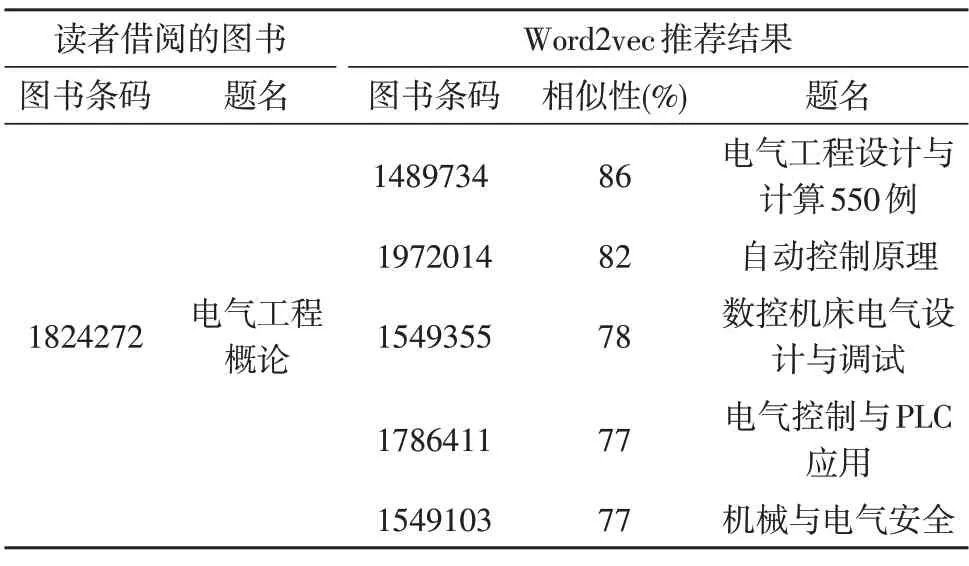
表3 Word2vec推荐结果
由表3 可知,推荐结果的相似性比较高,与输入图书匹配得较好,说明Word2vec 在图书推荐方面适用性较强。
4 结束语
Word2vec 是一个简单的三层神经网络,能够考虑上下文的关联关系。所以,该文将这一技术引入图书推荐系统,以提高图书推荐的精准性。从数据稀疏、语义缺乏等方面分析了传统图书推荐系统存在的问题。讨论并设计了基于Word2vec 的高校图书馆图书推荐系统。设计中,将读者借阅数据按照时间序列形成借阅行为共现矩阵,并将共现矩阵看作具有上下文关系的语境,利用Word2vec 技术发现读者的阅读偏好,形成图书推荐列表。选取西安航空学院图书馆11 229条借阅数据进行实验,结果表明推荐图书的相似性为77%,相似度较高,验证了Word2vec 在改进传统图书推荐系统方面具有较好的效果。
