基于轨迹式的Q 学习算法对探索环境预处理的研究*
2022-01-25胡常礼邵剑飞
胡常礼,邵剑飞
(昆明理工大学,云南 昆明 650500)
0 引言
Q 学 习(Q-learning)算法[1]是 由Watkins 和Dayan 提出的,用于估计马尔科夫决策过程的Q 函数,也是强化学习[2]中的经典算法之一。强化学习是基于奖惩机制[3]来鼓励智能体对环境进行探索,在智能体探索环境的每个状态空间会形成的长的轨迹,而长轨迹探索使得智能体要经过较长时间的学习才能获得奖励,形成延迟奖励的现象。本文提出的基于轨迹式的Q 学习(TracesQ-learning,TQlearning),在智能体在每次探索新环境的状态空间形成的轨迹以增量式轨迹T更新,从而减少延迟奖励的形成。
Q-learning 是传统的强化学习算法在稳定的环境中的研究[4-7],是智能体获得探索能力和最优策略的基础。强化学习最初是运用在最优控制[8]中,现在强化学习也运用在自动控制[9]、自动预测[10]等方面。由于现实世界的环境不断变化,智能体要探索的环境会更复杂,因此需要新的知识加入到智能体学习系统中来预处理探索环境的变化。本文提出的基于TQ-learning 对探索环境先进行预处理然后再探索的算法,在原来形成的学习策略上加入环境预处理的知识来处理探索环境的变化。
1 TQ-learning 与探索环境预处理
1.1 Q-learning的表示方式
Q-learning的原理是:先建立Q表格,然后根据Q表格选择动作再与环境交互得到奖励值R,最后再更新Q表格。Q更新的表达式为:
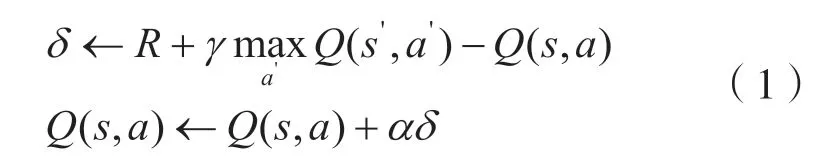
式中:Q(s,a)为动作值函数也称Q函数;R为在s状态下的奖励值;为下个状态执行下个动作a'选择最大值;α为学习率;γ和λ为折扣因子;θ为阈值。
Q函数的更新为:实际更新值=当前现实值+学习率×(现实值-估计值)。
1.2 TQ-learning
智能体在Q-learning的训练下在领域探索时可能会出现问题,例如在导航任务上可能在当前状态撞到返回到上个状态的相同动作,导致智能体不采取动作或循环这一动作。为了阻止重复这样的动作,采用增量轨迹的方式标记,如图1 所示。
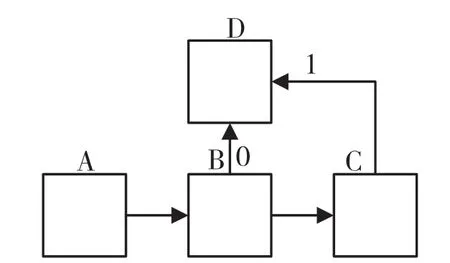
图1 轨迹标记
A 为起始地点,D 为目标地点,C 到D的轨迹标记为1,B 到D 标记为0。这样标记后,使智能体选择最短步数时会优先选择B 到D的动作。增量轨迹记为T,其更新方式为:
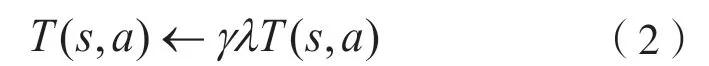
当训练过程中采取不是最优动作时,为了避免所有状态动作对的轨迹为零,采用了三角不等式去更新Q函数。三角不等式更新方式为:
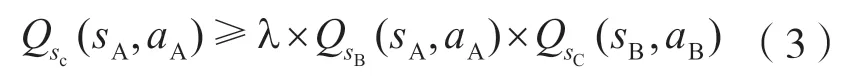
根据三角不等式更新方式,则Q函数更新情况有:
当T(s,a)=0,即采取了最优动作,
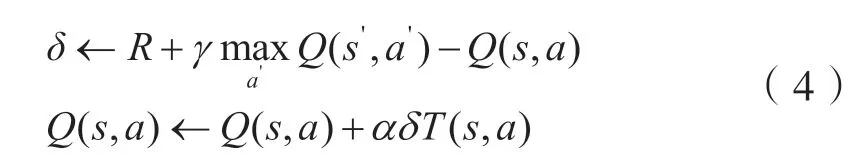
当T(s,a)≠0,即未采取最优动作,
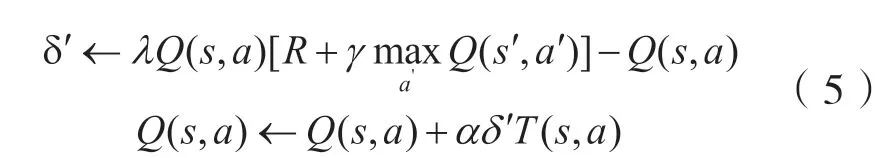
将标记轨迹融入到Q-learning 算法中,利用轨迹更新特性标记已走过的路线,使智能体积极探索,即遇到相同的状态再重新探索时不再重复采用同一动作导致学习速度慢。
1.3 探索环境预处理
探索环境的预处理主要是通过先检测探索的环境与之前环境是否相同,再判断在相同状态下采取相同动作的所获得奖励值是否和上次所获得奖励值相同。在原始环境下E,构造具有已知状态转移函数和报酬函数的环境模型En,原始环境定义为E(S,A,R,P),新的环境定义为En(Sn,An,Rn,Pn)。定义一个状态二元组(st,at),其中s∈S∩Sn,a∈A∩An,r∈R,rn∈Rn。如果r(s,a)≠rn(s,a),则该二元组(s,a)是变化的。在开始时已知原始环境中状态和动作对的总数记为Nsum。

对比本次训练和上次训练在下个状态采用的相同动作所获得的奖励是否相同,即式(6),若不同则标记此时的(st,at)为变化中状态空间对,将收集的标记构建Ed。通过检测这次探索的环境与上次探索环境所获得的奖励值是否相同,来标记变化的环境。检测和标记完探索环境后对探索环境进行预处理,将检测变化后的探索进行处理,处理方式为:

式中:Qtemp为现实值;为变化探索环境的下个状态;rnd为变化探索环境的奖励值;Qnd为变化探索环境的函数值;p(|snd,and)为在二元组(snd,and)到下个状态s'nd的转移概率;|Qtemp-Qnd(and,and)|为现实值减预测值的绝对值。
通过更新减小现实值和预测值的绝对值大小,使得智能体对变化的探索环境完成学习,即在原来的学习上可以对变化的部分进行补充学习。
探索环境预处理主要有两个关键部分组成:一是将通过扫描判断上一次探索所获得的奖励与这次探索原来的动态环境,标记出来构成Ed环境;二是通过对附近领域的环境扫描处理,使变化的状态空间奖励信息融合到原来的环境中组成新的探索环境。
在扫描过程中利用检测智能体观察到的新奖励和原始环境的最优值函数,并通过迭代更新这个变化的环境模型的值函数,将新信息融合到原来的环境中形成新的探索环境,然后再对新的环境进行探索学习,形成最优函数和新的策略。
本文算法利用增量式轨迹标记方式,使智能体在原始的环境再遇到相同状态时,不会重复上一个动作或停止不动,而是返回上一个状态空间,最后学习得到了原始的最优策略。为应对变化的环境的情况本文算法通过对探索环境进行扫描,对扫描出来变化的环境进行预处理形成新的探索环境,并通过轨迹标记方式使智能体积极对新形成环境进行探索。本文算法使智能体不必从头学习,并以更快的速度收敛到新的最优策略。算法具体实现流程见第2 节。
2 算法实现
2.1 算法流程
本算法首先初始化Q值和轨迹T,根据轨迹获取原始的最优策略π*和Q*值;其次在新的变化的环境中,算法通过检测变化动态的环境算法标记变化的环境Ed;最后根据扫描处理End,初始化环境π*,开始新的学习。该算法流程中,增量式Q 学习更新最优策略π*和Q*值,检测学习环境是否变化和扫描处理变化的环境,并将处理的状态环境更新到环境End中,形成带有原来知识的环境,使智能体在可以在原有知识的前提下学习新的知识,而不必从头学起,在将新的知识学习完后,通过迭代形成新的最优策略。算法框架具体如图2 所示。
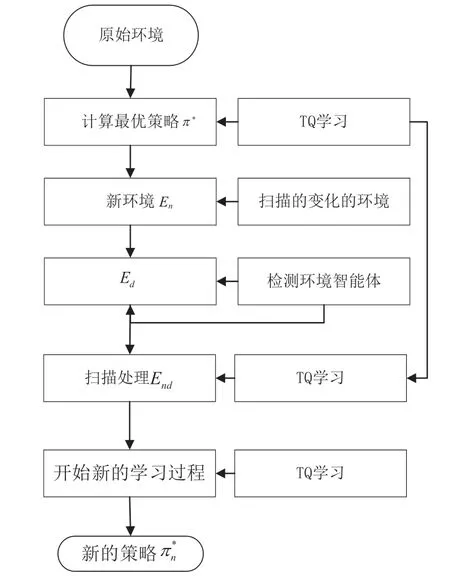
图2 算法框架
2.2 算法实现
TQ-learning 探索环境预处理算法的具体实现流程为:


本算法使智能体在探索过程中无需从头学习探索中部分变化的环境,只需要返回到上一个状态空间后继续探索,然后再对探索环境变化的部分进行预处理,即先检测动态环境后处理动态环境,更新状态价值函数的分布。本算法利用了轨迹的标记,使智能体可以在一段完整的训练学习期间达到目标,而且通过对变化环境的检测和预处理后,智能体可以在原来知识的基础下继续探索变化环境附近的领域,在遇到这部分变化的环境时会积极地采取动作去探索,最后探索形成新的策略。
3 实验仿真与分析
为了查看本论文改进的算法效果,将文本算法与使用原始策略、不使用原始策略以及策略重用算法进行对比。实验在60×60的二维变化迷宫中进行,如图3 所示。
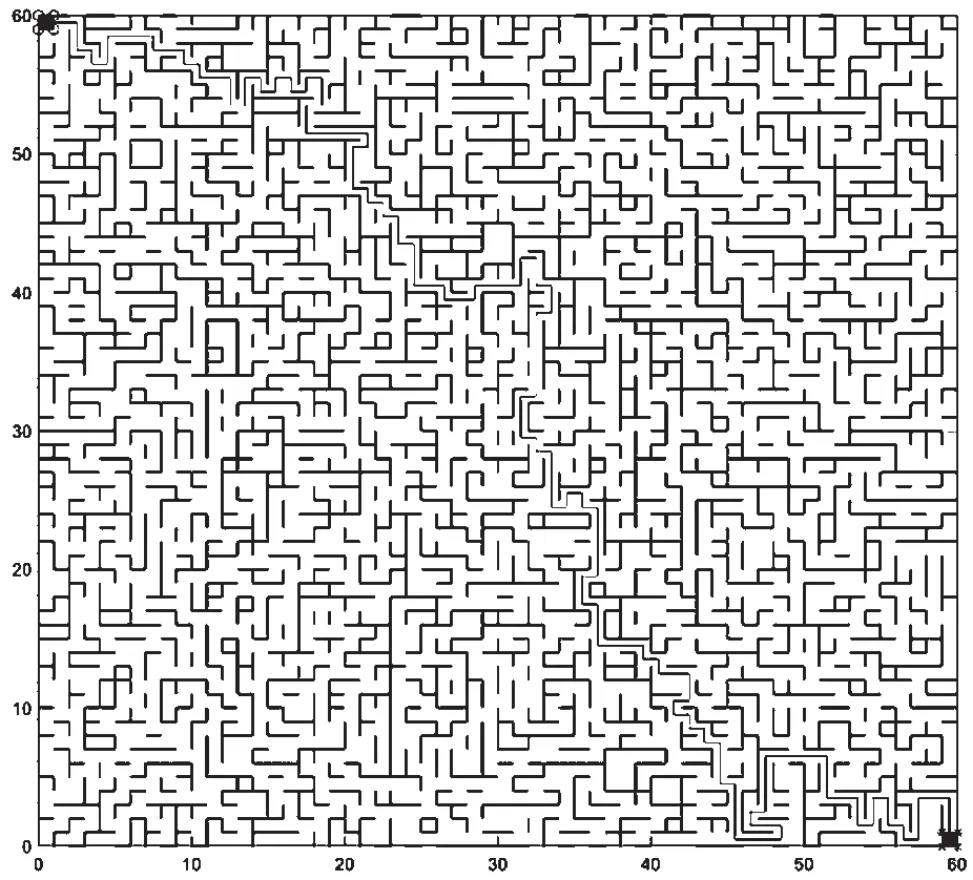
图3 迷宫仿真实验
迷宫的环境是可变的,迷宫中的右下角黑色格子是开始位置,左上角黑色代表目的地。连起来的细实线代表最优的路线且成功到达目的地。
仿真结果如图4 所示。
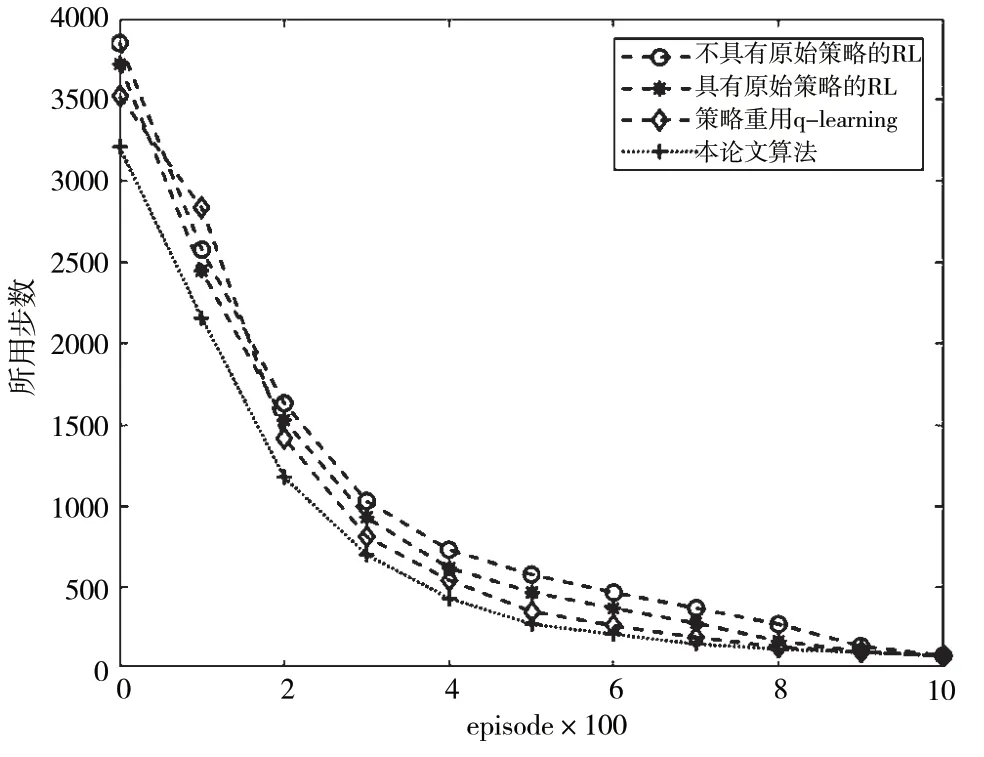
图4 仿真结果
在仿真结果中,Q-learning(不具有原始策略)首次达到目标后,经过后面迭代次数后,步数也减少了。Q-learning(不具有原始策略)在开始一定时间迭代内所用的步数是少于使用过原始策略和策略重用Q 学习的,但经过一段时间后,其迭代速度降低了。Q-learning(具有原始策略)首次达到目标,所探索的步数比较大,经过很长的迭代周期后,所用步数慢慢少了,最后趋于一个收敛值。Q-learning(具有原始策略)在经过一段episode 之后所用步数也增加了,但最后经过一段时间后所用步数慢慢减少。造成Q-learning(具有原始策略)这种现象是由于它在原始训练达到目标后形成一个策略,而这个在面对新的环境仍然按照之前的策略进行探索,然后在新的环境更新迭代原来的策略,最后根据这个策略使步数慢慢的减少,并到达一个阈值。没有使用原来策略的Q-learning 算法在一开始的步数和使用原来策略步数是一样;但使用原来策略经历迭代次数后,一段周期迭代后步数少于没使用策略后的,而最终收敛步数值趋于相同。本文算法在探索环境下首次达到目标所用的步数,明显少于策略重用学习。使用策略重用算法[11]造成该结果的原因有:策略重用在迭代首次达到目标的过程中由于不断的失败需要从头学习,使用原来策略在新的环境探索时策略更新的慢,导致步数在首次达到目标的步数远超于其它算法。
本文算法与其他算法相比,在整个迭代周期内,到达目的地的步数在一定程度上是最少的。因为探索迷宫对于本算法和其他算法在首次到达目的时需要一定探索时间,所以在第一次所需的步数也比较多;但在一段训练时期后,其所需的步数在快速减少。本算法的优点在于探索的过程中,遇到障碍物或者目的地的变化不必从头开始,通过对所处状态环境扫描预处理,返回上一个动作继续探索。本算法和对比算法都是基于Q-learning的更新方式更新Q表格,只是更新Q表格的方式和速度不同;所以通过迭代次数的增多,最后所需步数收敛于相同阈值。
4 结语
本论文研究的算法是在Q-learning的基础上对探索的途径进行轨迹标记,从而对探索的环境进行扫描,以及对变化环境进行预处理,然后对处理后的探索环境再学习,使智能体不必从头开始学习。为验证本文算法的有效性,本文利用二维变化迷宫环境模拟探索环境,通过与不具有原始策略和具有原始策略以及策略重用的Q-learning 算法在仿真环境结果分析对比,得出本文研究的算法在处理探索环境时一定程度上节约了探索时间和学习时间,且能有效处理探索环境的变化,改善了对探索环境变化处理的机制。
