基于改进自回归差分移动平均模型的网络流量预测*
2022-01-25武润升王军良
汪 尧,黄 宁,2,武润升,王军良
(1.北京航空航天大学 可靠性与系统工程学院,北京 100000;2.北京航空航天大学 云南创新研究院,云南 昆明 650000)
0 引言
伴随着因特网(Internet)和5G 通信技术的不断发展,网络提供的业务种类越来越多,相应地,网络出现拥塞的频率也随之增高。网络流量作为网络中最为重要的参数,可以反映网络某一时刻或者某一段持续时间网络业务的被使用情况,因此网络流量的建模分析成为很多学者研究的重点[1-5]。
网络流量生成的经典模型有马尔可夫模型、泊松模型和自回归差分移动平均模型等。这一类模型结构相对比较简单,模型参数较少,但由于网络流量具有突发性与偶然性,这些模型的预测效果不稳定。于是,许多研究对经典模型进行一定程度的改进以提高模型预测的精度与稳定性。文献[6]提出了改进灰狼算法优化支持向量机的网络流量预测模型,结果显示该模型的预测精度高于其它对比模型。文献[7]提出了一种模型参数联合求解的网络流量混沌预测模型,并运用遗传算法对模型参数进行求解,提高了模型的预测性能。文献[8]设计了基于小波变换和极限学习机的网络流量预测模型,使用极限学习机模型对流量数据进行机器学习,预测精度较高。文献[9]提出了一种改进的自回归差分移动平均(Autoregressive Integrated Moving Average Model,ARIMA)方法,该方法通过Box-Cox 指数变换消除了非平稳流量时间序列的长期自相关引起的异方差性。然而,这些改进后的经典模型依然存在预测效果不稳定的缺点。
随着人工智能领域技术的发展,越来越多人运用深度学习的知识对网络流量进行预测。文献[10]提出了一种改进的双线性卷积神经网络,用来对恶意网络流量进行预测分类。文献[11]利用高阶图卷积神经网络获取网络邻域之间的流量作用关系,利用自编码模型对网络流量实现无监督学习与预测。文献[12]提出了一种改进的长短期记忆神经网络预测方法,该方法有效避免模型陷入过拟合,减小了噪声对模型预测造成的误差。文献[13]提出了一种新的端到端的深度学习模型——时空注意力卷积长短期记忆网络,实验表明,该方法比其它基准方法有更高的预测精度。文献[14]基于极限梯度提升的机器学习方法,应用改进量子粒子群算法进行流量分析。文献[15]建立了一种优化的径向基神经网络流量预测模型,并实现了网络流量的量化预测。然而基于深度学习的方法需要大量数据样本,且模型的复杂度较高,当训练样本量较少时,预测效果不够理想。
本文对网络流量进行建模分析:首先对ARIMA模型进行改进,增加了误差扩散因子λ这一参数,使得原先的线性模型能够较好地描述非线性时序数据的变化规律;其次在训练新模型时,对传统的启发式优化算法(粒子群算法)进行改良,通过增加算法的随机扰动项以防止算法在搜索过程中陷入局部最优解;最后对一个具体网络进行案例分析,根据历史流量数据训练得到的网络流量分析模型,并使用给定测试数据集对提出的模型进行验证分析。实验结果表明,与传统的自回归差分移动平均模型的预测效果比较,改进后的模型预测效果更好。
1 模型介绍
对于网络流量而言,由于其自身具有突发性,偶然性与随机性等特点,其数据规律难以直接被数学解析描述,需要根据历史流量数据训练得到模型来对流量进行预测分析。在这里,本文提出一种改进的ARIMA 模型可以有效地进行流量预测。本节将详细介绍这一内容。
1.1 经典的ARIMA 模型
ARIMA 模型是时间序列数据处理与分析的基本方法之一,是将自回归模型(Auto regression Model,AR)与移动平均模型(Moving Average Model,MA)相结合的时间序列分析模型。该模型的参数序列为(p,d,q),其中p为自回归项数,d为使时间序列平稳所需要做的差分次数,q为移动平均项数。ARIMA 模型与AR 模型和MA 模型相比可以通过多次差分运算,来处理平稳性较差的时间序列。其一阶时间序列的差分运算数学表达式为:

n阶差分运算表示式为:

自回归差分移动模型的具体表达式为:

式中:y(d)t为对t时刻的原时序数据做d次差分运算得到的结果;yt为当前t时刻的时序数据值;μ为常数项,通常用历史数据的均值来代替;γi、θi为相关系数;εt为误差项,并假设误差项是均值为0,方差为σ2>0的高斯白噪声。
下面对ARIMA 模型的适用条件和建模过程进行简单介绍。
ARIMA 模型的使用需要时间序列满足的条件:处理的时间序列需要具有平稳性。ARIMA 模型可以通过多次差分运算,来使时序数据具有一定的平稳性。此外,ARIMA 模型要求处理的时序数据具有非高斯白噪声的性质,因此一般需要进行高斯白噪声检验。
建立ARIMA 模型对时间序列进行预处理,具体步骤如图1 所示。
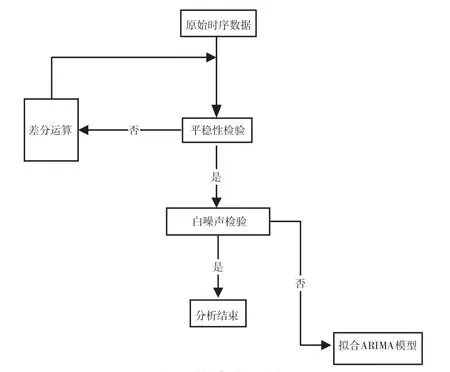
图1 时间序列的预处理
ARIMA 模型是一种经典的时序数据分析预测模型。它的优点在于模型的结构较为简单,且只需要根据源数据的内生变量进行分析与预测而不需要借助其它的外生变量;然而,其模型的本质是线性模型,缺乏对非线性关系的描述能力。因此,本文对经典ARIMA 模型进行改进,在尽可能不提高模型复杂度的情况下,使模型具有分析数据非线性关系的能力。
1.2 改进的ARIMA 模型
传统的ARIMA 模型善于对数据的线性关系进行描述,然而,网络流量数据具有突发性与偶然性。因此本文提出一种对ARIMA 模型的改进模型。改进后的ARIMA 模型在原(p,d,q)基础上新增加了误差扩散因子λ这一新的参数,该参数用来描述随机误差项在网络中的扩增倍数,本文将改进后的模型称作λ-ARIMA 模型。由于存在高斯白噪声εt~N(0,σ2),可能会出现负值,因此在λ-ARIMA 模型中,通过控制平均移动项数q前面的系数值来消除白噪声的负性。其具体数学模型为:

式中:μ为常数项,通常为历史数据的均值;y(d)t为对t时刻的原时序数据做d次差分运算得到的结果;εt为t时刻服从均值为0,方差为σ2的高斯白噪声;γi、θi为相关系数。
根据样本大小为n的历史数据集(y1,y2,…,yn),给出μ和σ的估计值的具体解析式:

对于γi和θi相关系数的取值范围,往往通过经验值给定范围的上界与下界,对其上下界允许存在一定程度的误差,这里不给出其具体的解析式。对于经典的ARIMA 模型,往往通过赤池信息准则(Akaike information criterion,AIC)和贝叶斯信息准则(Bayesian Information Criterion,BIC)确定最优的模型参数。而对于λ-ARIMA 模型,需要根据历史数据得到的预测值与真实值之间的误差尽可能小的准则,得到最优的模型参数,即满足:

显然,该问题是一个非凸的优化问题,经典的解决凸优化问题的算法都不再适用。对于非凸优化问题,往往会采用一些启发式算法,如遗传算法、粒子群算法、模拟退火算法等来进行寻找最优解的过程。本文将介绍一种改进的粒子群算法,以避免算法找到局部最优解而过早收敛。
2 改进粒子群方法
粒子群优化算法(Particle Swarm Optimization,PSO)是一种常见的智能优化算法,它源自于前人对鸟群觅食生理行为的科学研究。其算法流程步骤如下文所述。
(1)初始化:设置最大迭代次数,粒子的维度,粒子每一维度的最小和最大速度,粒子每一维度的最小位置和最大位置;设置粒子群的规模,并在速度区间和位置区间内随机初始化粒子的速度与位置。
(2)个体极值与历史最优解:根据优化的函数目标,设计适应度函数,粒子在迭代和寻找的过程中会出现个体粒子的最优解和全体最优解。其中,个体极值表示每个粒子找的最优解,而粒子群中的最优解称作全局最优解。将本次的全局最优解与历史的全局最优解相比,如果本次得到的结果优于历史的全局最优解,则进行更新,速度与位置的更新公式为:

式中:w为惯性因子;c1和c2为加速常数,一般地,c1,c2∈[0,4];pbestj为第j个粒子的取个体最优解所处的位置;gbest为粒子群达到全局最优解时所处的位置;xj、vj为第j个粒子任一维度的位置和速度。
通过多次迭代,对粒子的位置和速度进行多次更新,当达到设定的迭代次数时,结束循环过程,得到优化问题的最优解。
传统粒子群算法具有解决非凸的优化问题的能力。然而,该算法也存在着一些缺点,容易陷入局部最优解(当优化的目标函数为复杂的多峰函数时)。为了有效解决该问题,本文对粒子群算法进行改进。
本文创新性设置了变异扰动函数,其解析表达式为:

式中:tmax为预设的最大迭代次数;t为当前进行过的迭代次数;b为初始值,且。
可以看出,该函数为递增函数,随着迭代次数的增加,变异扰动函数的函数值越大,粒子位置发生扰动的可能性越大。设ρm为变异概率,当变异扰动函数值大于变异概率时,即ρ(t)>ρm时,粒子的位置发生扰动。发生扰动后粒子所处的位置为:

改良后的粒子群算法收敛速度更快,寻求到的目标函数的最优解优于传统粒子群算法,具有较好的性质。
3 案例分析
航空电子系统是飞机的重要组成部分,被喻为飞机的“大脑”。该系统采用先进的软件、网络和电子信息技术,将机载电子设备集成在信息共享的统一管理平台,是航电系统的重要载体。研究航电系统网络对飞机安全起到了至关重要的作用,因此本文以航空电子网络为对象,对网络中一段时间内流经某一交换机的历史流量数据进行统计分析。
3.1 数据来源
为验证λ-ARIMA 模型对网络流量预测的有效性,本例中的实验数据来自于某一航空电子系统网络,选择9:00—9:27 之间收集得到的流量数据集,数据集大小为143,使用的采样间隔为5 s。对得到的数据进行流量模型的建立与分析,其一段时间内流量数据的变化如图2 所示。
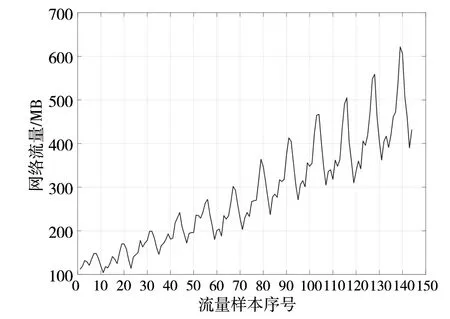
图2 原始网络流量时序
3.2 模型获取
本文使用SPSS 软件对时序数据进行一系列的分析。首先对流量数据进行检验,发现数据进行一阶差分运算后,具有平稳性且为非高斯白噪声,满足ARIMA 模型的基本要求。其一阶差分运算后的时间序列如图3 所示。

图3 一阶差分后的时间序列
本文使用SPSS 软件利用判定准则,得到最优的ARIMA 模型参数,结果自回归项数p为0,移动平均项数q为12。
采用改进的粒子群算法的参数设置为:惯性因子w为1.2,粒子的个数为50,最大迭代次数为500,学习因子c1、c2均为1.4,b为350,变异概率ρm为0.65。本文使用的仿真软件为Matlab2019a,使用改进粒子群算法对模型参数进行求解,并与经典粒子群优化算法和遗传算法进行比较。每种算法各运行10 次,计算算法结果的平均值,不同算法找到的最优目标函数值、迭代次数和算法的收敛时间列于表1。由表1 可见,改进粒子群优化算法的寻优效果要优于经典粒子群算法和遗传算法,且算法的收敛速度更快。

表1 不同算法的寻优效率比较
3.3 模型预测效果
使用λ-ARIMA 模型建立流量分析预测模型,并与传统的ARIMA 模型的预测结果进行分析比较。这里使用平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)来表示预测的准确度计算公式为:

式中:xi为输入值;h为预测函数;h(xi)为实际预测值;yi为真实值;m为训练的样本量。在本例中,从原始数据样本抽取前116 个流量样本作为训练集,剩余的27 个样本作为测试集,预测结果如图5所示。

图5 模型预测效果对比
本文对比ARIMA 模型和改进ARIMA 模型的预测效果,并进行定量分析。在相同的条件下分别运行5 次,将每次的结果与测试集的真实数据进行比较,所得对比结果如表2 所示。

表2 两种算法的平均绝对百分比误差 %
根据表2的数据计算可得:ARIMA 模型的MAPE 均值为17.5%,均方差为1.51%;改进ARIMA 模型预测精度的均值为11.2%,均方差为0.78%。从表2 可以看出,改进后的ARIMA 模型的MAPE 指标均值降低了6.3%。同时发现改进后的ARIMA 模型相比于传统的ARIMA 模型,预测精度的均方差降低了0.73%,稳定性会更高。
4 结语
本文对已有的网络流量时序数据进行分析建模,通过引入误差扩散因子λ,对经典的ARIMA模型进行改进;同时建立目标函数,通过对传统的粒子群算法的改进,增加了算法的随机扰动项,避免陷入局部最优解,加快了算法的收敛速度。由于改进后的模型变成了非线性模型,相比于经典的ARIMA 模型,可以更加准确地描述非线性时序数据的变化规律。最后,本文通过案例分析证明了,相较于经典的ARIMA 模型,改进后的模型的预测精度和稳定性均得到显著提高。
