我国制造业上市公司财务舞弊识别的研究
2022-01-25陈巧珍
黄 犚,陈巧珍
(南京邮电大学 经济学院,江苏 南京 210023)
当前,我国经济已由高速增长阶段转向高质量发展阶段,习总书记强调,“制造业是国家经济命脉所系”。党的十九大明确提出到本世纪中叶建成社会主义现代化强国,对制造业高质量发展提出了新的要求。党的十九届五中全会通过的《中共中央关于制定国民经济和社会发展第十四个五年规划和二○三五年远景目标的建议》指出,“要坚定不移建设制造强国,保持制造业比重基本稳定”。推动制造业高质量发展,就要落实制造业的科技创新、产业融合和企业的优胜劣汰,需要完善金融支持机制,健全资本市场,提高直接融资的比重。
近年来,金融领域推行了一系列改革,设立科创板并试点注册制,完善再融资、并购重组等资本市场制度,加大直接融资对制造业的支持;出台了一系列新规,通过信贷指标、绩效评价要求金融行业将金融资源由地产转而投向制造业实体经济,这是迈向“新阶段、新理念、新格局”的政策破局之举。制造业上市公司通过资本市场直接融资,给投资者带来了收益并促进消费、进一步扩大投资,实现中国经济的良性内部循环。
然而,由于IPO市场加速扩容,资本市场违规成本较低,欺诈发行、财务舞弊事件也有所增加,根据国泰安数据库违规信息显示,2018—2020年制造业上市公司财务舞弊违规信息增加了71%。由于上市公司数量的激增和财务舞弊手段的多样性和隐蔽性,涉及的会计科目繁多,产生了大量的高维数据,对财务舞弊识别提出了更高的要求。因此,设计合适的评价指标,构建有效的财务舞弊识别模型,是近年来学界研究的热点。本文采用机器学习的方法来解决财务舞弊识别问题, 克服大数据环境下人工识别弊端,从数据挖掘的角度,对不同的指标和数据进行选取,构建基于多种降维方法的混合分类模型,并在此基础上明确财务舞弊的重要影响指标,从而提高财务舞弊的识别效率,有利于资本市场的优胜劣汰,维护资本市场健康有序发展,实现资本市场服务于制造业和投资者的功能,促进制造业高质量发展。
一、文献综述
1.财务舞弊的识别研究
在我国的会计准则中,财务舞弊是指企业为了获得高额利益,违反会计准则,故意编制虚假的财务报告,隐瞒真实的财务信息[1]。财务舞弊的识别研究主要包括财务舞弊的动因研究和影响因素研究两部分。财务舞弊动因理论主要有冰山理论、Gone模型、舞弊三角形理论和舞弊风险因子理论等。对比中外的财务舞弊现象,发现国外舞弊主要由压力因素导致,中国财务舞弊主要来源于机会因素[2],汪建新(2008)[3]提出舞弊的压力来自于工作和经济,舞弊的机会来源于公司内部控制和外部审计的缺失。范海敏(2015)[4]通过实证研究发现舞弊人员的人品素质、对权势的欲望和公司的内部治理及外部监督等多方面因素造成了财务舞弊现象。此外,企业性质、CEO权力强度、高管背景[5-7]等因素也是我国企业财务舞弊的影响因素。
2.财务舞弊指标的研究
正确选择模型的输入变量以及在众多指标中筛选出关键变量可以提高模型的判别能力。目前,财务舞弊研究的指标选取分为三个方向:第一,基于财务舞弊概念理论,张曾莲(2017)[8]从“压力、机会、借口”这三个方面选取指标,并将财务舞弊的影响因素选为输入指标;第二,基于企业发布的财务报告信息选择财务舞弊研究指标,刘志洋和韩丽荣(2018)[9]利用历史财务指标的波动性作为舞弊模型的输入变量取得了较好的识别效果;第三,考虑指标应具有全面性和代表性,董事会规模[10]、独立董事比、股权结构[11]、监事会规模和企业内部控制等非财务指标对于识别财务舞弊有影响[12],熊方军(2016)认为可以从财务信息和非财务信息两方面选择指标[13]。由于指标变量之间难免会存在相关性,因此,在建立模型之前,需要筛选出重要的特征,目前,较为常用的特征选择方法主要有主成分分析、因子分析、方差膨胀法、Lasso法、Boruta法和Relief法[14-17]等。
3.财务舞弊数据质量的研究
财务数据真实、可靠是进行分析的重要前提,早期的研究运用比较分析法、趋势分析法[18]等方法,通过对比财务数据前后的差异来查找异常数据。估计期望值和估计数据预期分布[19]方法,根据财务数据之前的分布与发展规律预测其之后的分布,检验其与实际值的偏离程度。随着技术的发展,离群数据挖掘法[20]等数据挖掘技术被逐渐运用,从财务数据中根据距离、分布或者深度来挖掘异常值。一类支持向量机[21]等机器学习方法可以学习大量的财务数据并识别数据的流通规律,查找其中偏离正常流向的异常数据。目前,较多使用Benford法则检测上市企业财务数据的质量,通过比较财务数据中数字出现的概率与自然情况下数字的随机概率是否一致,得到异常样本[22]。除了单独使用上述方法之外,还可以将不同方法结合使用,如将Benford法则和logistic模型、广义线性模型、数据挖掘技术[23-25]等相结合,提高寻找舞弊样本点的正确率。
4.财务舞弊识别模型的研究
关于财务舞弊识别模型主要有两类,一类是以logistic模型为主的传统识别模型,如韩丽荣(2015)[26]等人采用指数型变量建立logistic回归模型,对财务舞弊行为进行识别。另一类是以机器学习算法为主的识别模型,将神经网络模型[27]、决策树[28]、文本和电子邮件挖掘[29]、遗传算法和支持向量机[30]等算法应用于财务舞弊识别,并取得了较好的效果。如金花妍(2014)[31]等人构建了支持向量机模型、夏明(2015)[14]等人建立了RBF-BP神经网络模型提高了对财务舞弊行为的识别准确率。
综上所述,财务舞弊领域的研究成果较为丰富,财务舞弊识别方面的理论已经相当成熟,但在指标选择方面尚无公认的标准,大多数研究直接将初始指标纳入模型,而不进行指标的筛选。由于财务指标众多且有多重共线性,指标的筛选是影响分类模型的识别效果的主要因素。本文首先采用局部线性嵌入方法和自适应弹性网方法分别对初始指标进行筛选与降维,得到两组指标数据集,再对初始指标集和两组降维后指标集分别建立AdaBoost分类模型,比较指标降维前后分类模型的识别效果,探寻对财务舞弊识别具有重要影响的指标。
二、模型理论阐述
上市公司的财务指标之间有较高的多重共线性,直接进行分析会高估模型的识别效果,而局部线性嵌入方法使数据降维后保持原有的拓扑结构,自适应弹性网方法可以很好地处理指标间的多重共线性问题,所以采用这两种方法对指标进行降维处理。与其他机器学习算法不同,AdaBoost是加法模型,考虑每个子模型的分类效果,它的核心之处是在迭代时,根据之前模型的分类效果,对于分类错误的样本会在下一次训练时给予较大的权重,这样不断更新样本权重,直到达到设定的迭代次数,提高模型的识别效果。
1.局部线性嵌入方法(LLE)
局部线性嵌入方法(LLE)可以使降维后的数据保持原来的结构,维持数据局部线性特征不变。它的核心思想是某个样本xi,可以用它领域中的k个样本线性表示,如式(1)所示。

(1)
其中,xij表示xi的第j个紧邻点(1≤j≤k),wij是权重系数,假设样本D={x1,x2,…,xm},投影后样本集为d={y1,y2,…,ym},投影时最小化损失函数为:
(2)
在降维前后,保证wij不发生变化或最小变化,降维后的样本将保持原有的结构。
2.自适应弹性网方法(AEnet)
自适应弹性网方法(AEnet)是自适应Lasso方法和弹性网相结合的变量筛选方法,AEnet方法是对L1惩罚部分进行了加权处理,对不同重要性的系数施加不同的权重[32]。自适应弹性网惩罚函数如式(3)所示。
(3)
3.AdaBoost算法
AdaBoost算法是一种集成学习方法,它是对同个训练集拟合多个分类模型,再根据分类模型的分类效果计算各个模型的误差,将多个分类模型线性组合成一个最终分类模型。假设训练集D={(x1,y1),(x2,y2),……,(xN,yN)},初始时样本等权重开始迭代,得到多个弱分类器hm(x),计算每个弱分类器hm(x)的分类误差率(em)与话语权(αm),如式(4)、式(5)所示。

(4)
(5)
em越小的弱分类器越好、话语权越大,即其在最终分类模型中的比重越大,根据每个分类模型在最终模型中的比重进行线性组合,得到最终模型式(6)。

(6)
三、实证分析
1.样本选择
CSMAR数据库(国泰安)将财务舞弊企业定义为因虚构利润、虚列资产和虚假记载(误导性陈述)行为被处罚的上市企业。根据该数据库公布的违规信息总表,筛选出舞弊年份在2010—2019年间的制造业上市企业为舞弊样本,删除因财务异常被特别处理的公司。若某公司此期间的不同年份都发生舞弊行为,则选取最近舞弊的一年作为舞弊年份,根据此方法筛选出99个舞弊样本。在选择非舞弊样本时主要遵循以下几点:(1)行业相同,不同行业有不一样的经济特征,其可比性不高,所以本文选择的控制样本与舞弊样本的行业相同;(2)市值相近,控制样本为在舞弊当年与舞弊样本市值相近的企业;(3)舞弊年度相同,选择与舞弊公司舞弊年度一样的样本,确保控制样本在此期间没有因财务舞弊行为被处罚。为了减少非平衡样本带来的影响,本文将舞弊样本与非舞弊样本比例设定为1:1,由上述信息选取出99个配对的非舞弊样本。由舞弊样本和配对的非舞弊样本,组成99组实验样本。
2.初始指标集
本文在满足指标体系构建的全面性、科学性和可操作性等原则的条件下,选择财务指标和非财务指标构成初始指标集。
国泰安数据库从偿债能力、盈利能力、经营能力、披露财务指标、比率结构、现金流分析等多方面定义了200多个财务指标,全面包含了公司的财务信息。剔除数据缺失的指标和具有明显共线性的指标,本文从偿债能力、盈利能力、经营能力、每股指标和比率结构这5个方面选取了28个财务指标,如表1所示。

表1 财务指标
企业偿债能力能够体现一家企业是否可以长久健康的发展下去,盈利能力是指企业获得利润的能力,经营能力体现了企业对内部条件及其发展的经营决策能力;比率结构反映了公司的资产分布。通常偿债能力、盈利能力、经营能力越弱和比率结构不合理的企业越有可能发生财务舞弊。
根据舞弊三角理论中机会因素可知,舞弊成功是需要机会的。公司治理机制的良好运行离不开内部控制和外部监管的有效结合,如果治理机制存在问题,就会大大增加舞弊行为发生的可能性,因此,企业的治理机制也经常被认为是判别上市公司是否舞弊的因素之一。本文以此为基础得到如表2所示的非财务指标。其中股权集中度体现了公司股权集中情况,股权过度集中会增大股东之间的利益矛盾。董事会是公司治理机制的核心,独立董事的存在会减少董事会被高层控制的可能性,而董事长兼任总经理的情况会增加董事会被管理层掌控的可能性,这样可能会引发财务舞弊行为。监事会体现了企业的内部监督能力,缺乏企业内部监督会增加财务舞弊的发生。

表2 非财务指标
本文的响应变量为上市公司是否有财务舞弊行为,记为y,当企业有财务舞弊行为时,y为-1;当企业没有舞弊行为时,y为1。数值型变量的描述性统计如表3所示。

表3 数值型变量的描述性统计分析
3.数据来源与预处理
筛选出实验样本后,基于指标体系从CSMAR数据库获取2010—2019年的财务数据和非财务数据,按照指标定义处理数据。数据集的划分遵循两个原则:一是训练集样本数不得少于样本总量的一半,确保训练集与整体数据集训练出的模型接近;二是测试集样本量不能过少,确保评估准确率。一般会将2/3~4/5的样本划分为训练集,剩下的样本为测试集[33]。本文尝试以8:2、7:3和6:4划分样本为训练集和测试集进行试验,最终确定最佳比例为7:3,以训练集样本拟合识别模型,再用测试集数据验证模型的识别效果。
4.模型建立
以局部线性嵌入降维方法和自适应弹性网降维方法分别和AdaBoost算法结合建立识别模型作为实验组,比较降维方法的优劣,并以降维前的初始指标建立的AdaBoost模型作为对照组。本文先用训练集样本拟合AdaBoost模型、LLE-AdaBoost模型和AEnet -AdaBoost模型,再用测试集验证以上三个模型的识别效果,比较三个模型的优劣。
(1)AdaBoost模型
AdaBoost模型是指不对初始指标集做降维处理,直接使用AdaBoost算法建立的识别模型。将所有初始指标作为模型的输入特征,对训练集样本建立AdaBoost识别模型,作为降维后模型的对照组(如表4所示),以检验降维方法的效果。其训练集中舞弊样本的预测准确率为72.73%,整体的识别准确率为69.57%。

表4 AdaBoost模型训练集效果
变量重要性是指该变量引起的信息增益减少量的归一化值,可以用来判断模型中每个变量所起作用。图1由大到小展示了AdaBoost模型中各变量的重要性,如图1所示,对AdaBoost模型产生重要影响的变量排名前三的是应付账款周转率、每股未分配利润和每股净资产,而每股净资产、流动资产比率、每股收益、股权集中度等变量的重要性较为接近,企业性质、独立董事比等变量的重要性相对较小。

图1 变量的重要性排名
(2)LLE-AdaBoost模型
LLE-AdaBoost模型是将局部线性嵌入方法与AdaBoost算法相结合的分类模型。不同于线性降维方法,局部线性嵌入不体现新指标与原始指标之间的联系,因此,将新指标分别命名为f1、f2、f3、f4、f5、f6,并将样本在新指标上的分布展示出来。首先对数据进行维数测定,得到数据的本质维数是6维,其次用局部线性嵌入方法将初始指标降到6维,分别命名为f1、f2、f3、f4、f5、f6,舞弊样本和非舞弊样本在这6个新指标上的表现分别如图2和图3所示。如图2所示,舞弊样本在指标f1、f5特别突出,其次是f2;如图3所示,非舞弊样本f3指标最为突出,其次是f2、f6指标比较突出。这表明舞弊样本和非舞弊样本在这6维新指标中的表现存在差异性,可以通过这6个指标识别财务舞弊。
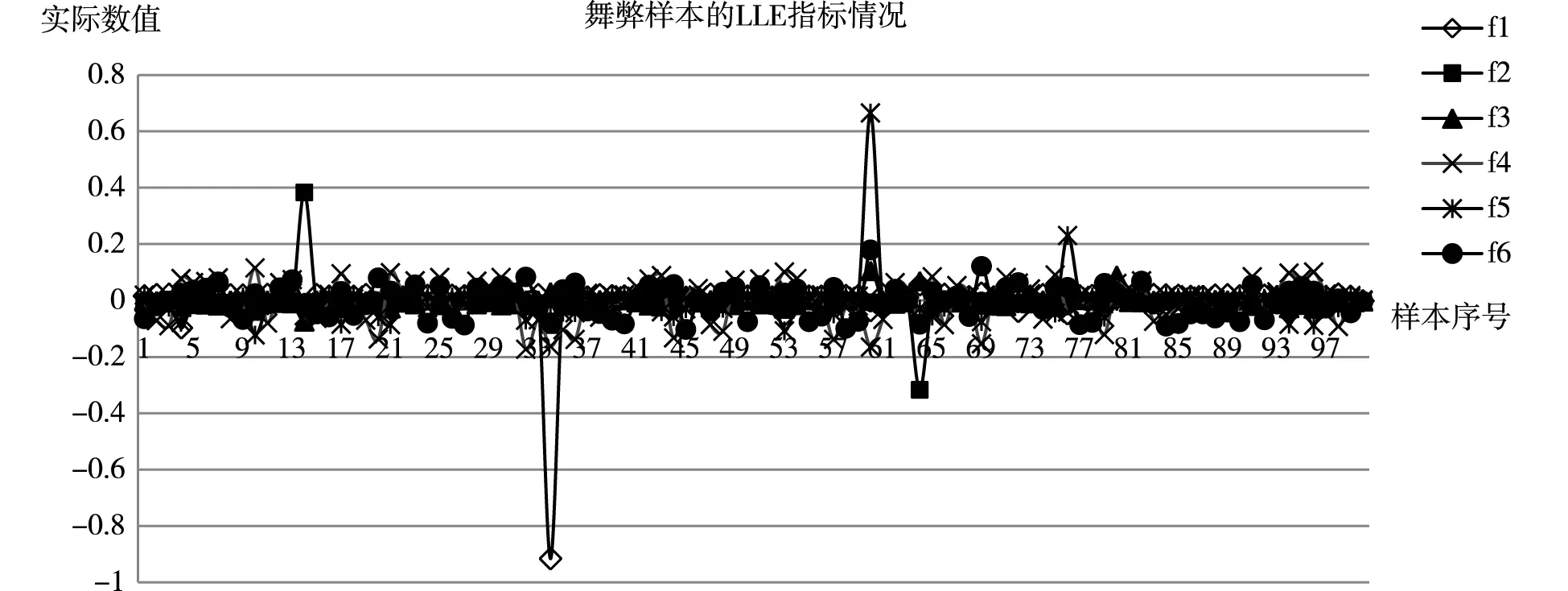
图2 舞弊样本的LLE指标情况

图3 非舞弊样本的LLE指标情况
最后用6个新指标对训练集建立AdaBoost分类模型,该模型记为LLE-AdaBoost模型,该模型拟合效果如表5所示,其训练集舞弊样本识别率为39.39%,整体预测准确率为50%。

表5 LLE-AdaBoost模型训练集效果
(3)AEnet-AdaBoost模型
AEnet-AdaBoost模型是指将自适应弹性网方法与AdaBoost算法结合的分类模型。首先采用自适应弹性网方法对初始指标集进行降维处理,最终筛选出了7个重要的指标。自适应弹性网系数体现了指标的重要性,从该系数观察,股权集中度的系数最大,说明股权集中度对模型的影响最大,其次是总资产净利润率、资产负债率等指标对模型有着次要的影响,应付账款周转率对识别模型的影响相对最小,筛选出的指标及系数如图4所示。
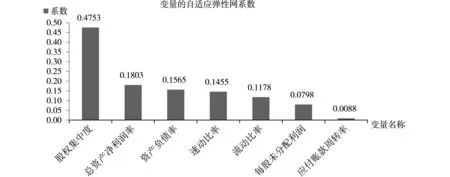
图4 变量的自适应弹性网系数
利用筛选出的指标对训练集建立识别模型AEnet-AdaBoost,得到的模型效果如表6所示,其舞弊样本的预测准确率为62.12%,整体预测准确率为65.94%。

表6 AEnet-AdaBoost训练集效果
(4)模型预测效果对比
以上对训练集拟合了AdaBoost模型、LLE-AdaBoost模型和AEnet -AdaBoost模型,为了比较各个模型的识别效果,表7展示了三个模型在测试集上的预测结果。如表7所示,在测试集中,AdaBoost模型舞弊样本识别准确率为63.64%,整体识别效果为66.67%。使用LLE降维后的指标建立的分类模型效果没有得到提升,其整体识别效果仅为51.67%。AEnet-AdaBoost模型识别效果最好,舞弊样本识别的准确率为66.67%,整体的识别准确率为75%,较降维前识别效果提高了8.30%。
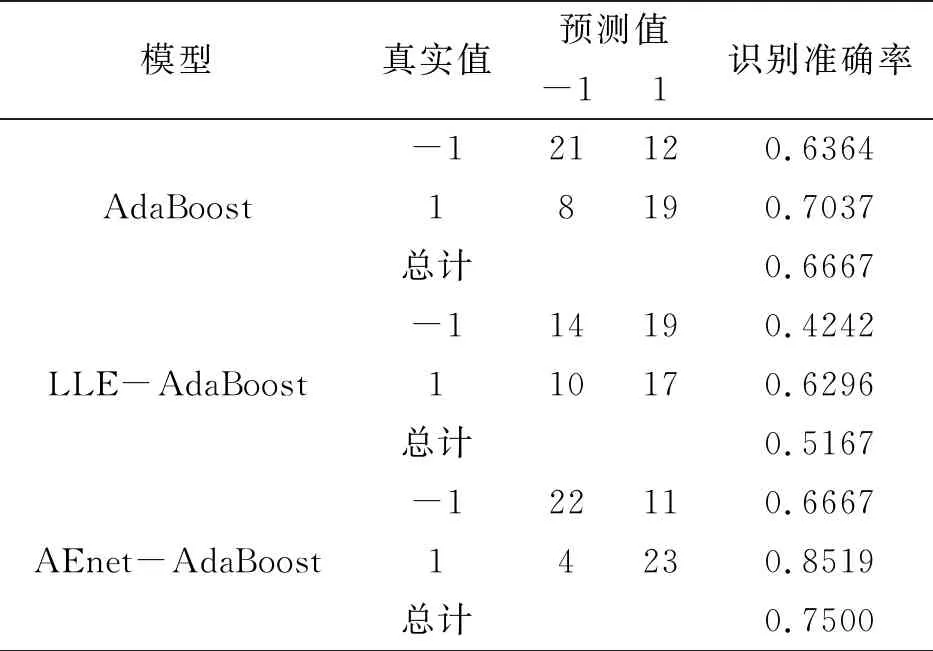
表7 测试集模型预测结果对比
在模型的变量重要性方面,不同的机器学习方法衡量重要性的标准不同,遵循模型在测试集上的准确性即预测准确率才是判定模型好坏的最佳准则[34],由于AEnet -AdaBoost模型的预测准确率最高,表明自适应弹性网方法从初始指标中筛选出了更加重要的变量,并赋予变量自适应弹性网系数,该系数越大说明变量越重要,因此,通过自适应弹性网方法,研究发现股权集中度、总资产净利润率、速动比率、资产负债率和每股未分配利润等指标对于识别财务舞弊行为具有显著的作用。
四、结论与启示
本文在制造业上市公司中,以2010—2019年期间同一年度发生财务舞弊的公司和非舞弊公司为实证研究对象,从偿债能力、盈利能力、经营能力、每股指标和比率结构等5个方面选取了28个财务指标,从公司治理机制的角度选取7个非财务指标,共计35个指标建立指标体系,使用局部线性嵌入方法和自适应弹性网方法对初始指标进行降维处理,建立了AdaBoost识别模型,经过实证分析得到以下结论。
其一,通过比较AdaBoost模型、LLE-AdaBoost模型和AEnet -AdaBoost模型,发现局部线性嵌入方法的降维处理降低了模型的识别效果,自适应弹性网方法降维后的模型整体识别准确率为75%,比降维前提高了8.30%,说明自适应弹性网方法具有较强的变量筛选能力,有助于快速地识别主要的影响指标,提高舞弊识别效果。自适应弹性网方法可以通过筛选出的重要性指标提高财务舞弊的甄别效率,局部线性嵌入方法的降维处理无法分辨指标对识别模型的影响。
其二,通过自适应弹性网方法,发现非财务指标中股权集中度对于识别财务舞弊的作用最大,说明企业股权结构对于研究企业舞弊行为十分重要。财务指标中总资产净利润率、速动比率、流动比率、资产负债率、应付账款周转率和每股未分配利润等指标对于分析财务舞弊行为有重要的作用。
上述研究结果也对保护投资者权益、公司治理和有效监管有一定的启示作用。投资者应该收集上市公司历史经营状况,分析其财务信息和公司管理层架构。尤其是速动比率、流动比率、资产负债率和每股未分配利润等指标,若是债务较多,其资产的流动性和变现性较差,说明该公司有经营风险,投资者还可以从每股未分配利润指标直观地了解公司的经营情况,若是该指标为负值,则体现了公司目前尚有亏损,还没有扭亏为盈,需要谨慎投资。投资者发现有问题的公司时应积极举报,充分发挥外部监督人的作用。
上市公司应保证合理的股权结构。研究可知,股权集中度指标对于识别财务舞弊有着重要作用,股权过于集中不利于股东间的监督制衡,从而增大财务舞弊发生的概率,因此,企业一方面要优化股权结构,保证各股东意志的正常体现;另一方面,要保证监督部门的独立性,发挥其应有的作用。公司治理要有风险意识,内审部门重点关注偿债能力指标,对这些指标设定一个风险阈值,保证企业正常发展的同时,资产具有较好的流动性和变现性,可以随时应对市场风险和突发意外。
落实金融支持制造业高质量发展的目标任务,离不开制度环境的完善。监管部门应加强证券执法和司法工作,从严设置财务舞弊退市量化指标,加强退市执行力度,加强对审计人员技能和素养的培训,用先进的技术方法定位财务报告中虚假的信息,提高审计效率。
