基于IPv6环境的网络信息安全访问控制模型设计
2022-01-25王金威
王金威
(闽南理工学院,福建 泉州 362700)
在传统的网络应用模式中,随着终端用户系统资源的丰富和网络带宽的迅速增加,服务器单点失效的问题影响终端系统资源的利用率[1-2]。而信息技术在协同工作、分布式信息以及资源共享资源等方面显示出的独特优势,使其成为全新的发展热点,同时网络信息安全访问控制也成为当前研究的热点话题。相关专家针对该方面进行了大量的研究,如王海勇等人在区块链环境下,根据用户信用度设计了信息访问控制模型[3]。该模型首先将访问控制策略保存于区块链中,然后再评估用户信用度的基础上获取对应角色的访问权限。当用户信用度达到阈值时,赋予该用户访问权限。贾政民通过优化CP-ABE算法来控制数据的安全访问过程,该模型将文件按不同的访问权限进行分级,然后通过整合多个权限模型结构实现密文分享,再利用权限模型控制存储密文[4]。以上两种模型虽然取得了较为显著的研究成果,由于未能对网络信息进行预处理,导致网络信息安全访问控制偏差以及延时上升,网络信息利用率下降。国外的研究学者也对访问控制模型展开了研究。Aftab M U等中设计了一种动态COI混合访问控制模型,在设置用户授权限制机制的基础上,利用动态COI避免控制过程的过度和管理过载问题[5]。Lobo J等设计了一种基于关系的访问控制模型,在分析网络信息基本概念的基础上划分其所属类别,然后根据访客历史查询信息与网络信息间的关系及其信任值设计控制模型[6]。然而在实际应用中发现上述两种模型存在执行延迟较长的弊端。
IPv6环境既能够克服IPv4环境中网络地址资源短缺的不足,也能够有效避免多设备的接入障碍。因此,针对上述问题,本研究基于IPv6环境设计了一种新的网络信息安全访问控制模型。
1 模型设计
与IPv4协议相比,IPv6协议中增加了“任播地址”,能够支持组播功能的实现。因此,在设计网络信息安全访问控制模型时,为达到更好的控制效果,本研究在建立网络信息安全访问控制模型之前,设计了网络信息预处理过程,通过预处理结果判断信息的不同特征,从而实现更有针对性的安全访问控制。
1.1 网络信息选择与预处理
本文在设计访问控制模型前提取了网络信息的特征,实现对网络信息的预处理。
1.1.1 网络信息特征选择
特征选取的主要目的是选取最优特征子集,这些子集组建的分类模型具有可理解性。特征选择算法是通过一种有效的手段获取高相关特性用于数据降维。基本的特征选择框架如图1所示。
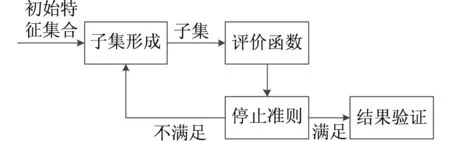
图1 特征选择流程图
图1中主要包含以下四个部分。
(1)子集形成:子集的过程就是特征子集的搜索策略,形成的候选特征子集将会被送入到评价函数中;
(2)评价函数:利用某种评价准则对输入的特征子集进行评判,其中通过既定的评判准则对特征子集进行更新[5-6];
(3)停止准则:通常和评价函数存在关联,主要包含一个阈值,停止搜索的条件就是评价函数满足阈值[7];
(4)结果验证:验证最终获取的特征子集是否有效。
假设特征选择的过程中的自变量为X、因变量为Y,Fi代表相关特征,其计算式如式(1)所示。
SFi=P(X|S)+P(Y|S)
(1)
其中,S表示特征集中的变量总数。当特征Fi满足公式(1)的要求时,说明特征Fi是相关的,在其他情况下,则认定Fi是不相关的。并且从上述过程中能够看出,被认定的相关特征主要包含两个方面的因素[8-9]:①特征Fi和类标签之间存在紧密关联;②当特征Fi和其他特征共同组成特征子集,则说明特征子集和类标签之间存在紧密关联。
网络信息的冗余特征能够表示为式(2)的形式,即:
(2)
在此基础上,将网络信息进行过滤的主要目的是获取独立的判定准则,同时不考虑各个特征间的相关性[10],采用某种准则获取最优特征子集将其应用于学习算法的输入,具体结构如图2所示。

图2 ReliefF特征选择流程图
1.1.2 网络信息预处理
过滤式特征选择方法最大的优势就是能够以最快的速度降低噪声对搜索特征子集产生的影响,同时加快高维数据处理方式,提升计算速率。为了简化数据降维过程,以下给出数据降维的具体操作步骤。

(3)
协方差矩阵能够表示为式(4)的形式。
C=E{[xi-E(xi)][xi-1-E(xi-1)]}
(4)
其中,E(xi)、E(xi-1)均为期望值。任意取a∈CN×N,那么a为协方差矩阵中N维线性空间V中某次线性变化k的基矩阵,对C进行对角化处理,存在式(5)所示关系。
C=V∧Vk
(5)
令d表示协方差矩阵C的秩,则存在rank(C)=d;若半正定矩阵含有非零特征值,其数量为k,则存在λ1,λ2,…,λk。在此基础上,以前k个特征特征向量为对象[11-12],构建特征向量矩阵如式(6)所示。
V={v1,v2,…,vk}
(6)
如果观测数据是由多个独立数据组成的,其可表示为式(7)的形式。
r=vk+Ar0
(7)
式(7)中,r代表观测数据;A代表未知的混合矩阵;r0代表获取的初始信号。
设定ρi代表信号源分布对应的密度函数,以此为依据获取如下的联合分布函数,如式(8)所示。
(8)
由于不同的信号源不存在依存关系,因此,假设W为A的伪逆矩阵,获取信号r的联合分布函数如式(9)所示。
(9)
结合概率学理论可知,对于随机变量来说,其累积分布函数如式(10)所示。
(10)
其中,z0表示z的初始值。在上述分析的基础上,当网络信息依次经过主成分分析和独立成分分析降维后可以有效完成预处理。
1.2 建立网络信息安全访问控制模型
基于上述处理后的网络信息,在IPv6的网络环境中,需要确保提出的请求和提供的服务都具有较高的匿名性以及动态性,要求访问控制系统能够动态适应这种变化,通过网络的动态变化即可给出对应的访问控制策略。
在复杂的网络系统中,信任机制能够保障不同实体间的信息交互,同时也能够将信任度作为访问控制策略一部分,根据实体的历史行为不断调整信任度[13]。因此,本研究引入信任值以及上下文约束概念构建访问控制模型。与传统控制模型不同的是,本研究设计的控制模型在主体与客体之间增加了角色层,从而形成一个应用了RBCA角色权限控制的模型,其具体结构如图3所示。
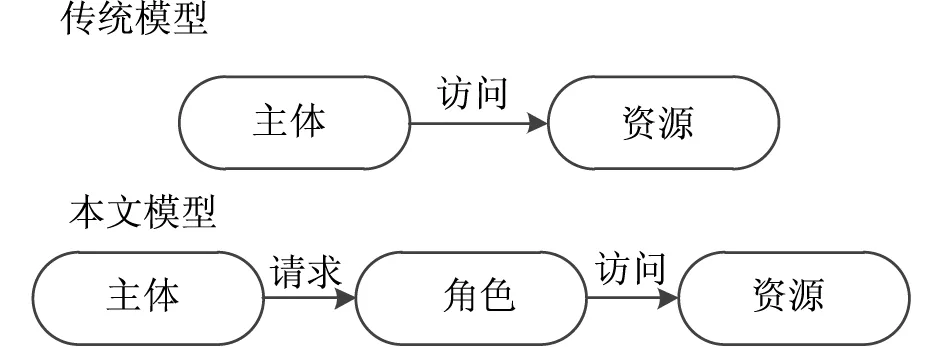
图3 本文模型和传统访问控制模型两者的对比
标准的RBCA角色权限控制模型主要由主体、角色层、资源以及访问请求四个部分组成,它在传统模型的基础上加入了角色层次的相关概念,定义了决策之间的继承关系,同时也反映了职权间的线性关系,确保系统的保密级别。
角色的集成是通过角色访问控制模型将全部角色组织起来,有效反映组织的特权以及职责机构。在RBAC模型中,如果某用户被委派到几个本身就存在冲突的角色上,那么势必会造成安全冲突。此时,静态责任分离机制就会在赋予用户角色时实施约束,从而有效避免安全冲突的产生。在具有角色层次的前提下,需要重新设定固态硬盘,并对其进行静态分离。
上述构建控制模型主要具有以下两方面的优势:
(1)其应用了与策略不存在关联的RBCA方位控制技术,且不局限于特性的安全策略,能够描述全部的安全策略;
(2)RBCA模型具有自我管理能力,通过RABC模型能够更好完成模型的管理工作。
在上述研究的基础上,为了进一步有效实现网络信息安全访问控制,本研究将上下文约束以及信任值同时引入到RBCA模型控制过程中,通过上下文信息确定用户的身份以及使用权限,从而在RBCA模型中完成对网络信息安全访问控制模型的建立[14-15]。这一过程需要满足以下的约束条件:
1)对各个实体之间的交互情况进行监控,同时将信任参数全部反映到授权过程中,当资源请求点的信任度高于或者等于信任值阈值时,才能够赋予其对应的角色权限;
2)在动态方位控制的过程中需要采用信任参数,交互双方能够对信任参数提出要求,当交互双方的信任值高于或者等于信任值阈值时,才能够进行交易。这一过程中,用户和角色间存在多对多的关系,用户针对许可的执行可以利用角色进行联系,进而全面提升对网络信息安全访问控制。
上述过程中,角色和用户两者间的关系如图4所示。

图4 角色和用户两者的关系
综上所述,完成了对基于IPv6环境的网络信息安全访问控制模型的构建,具体流程如图5所示。

图5 模型构建流程
2 仿真实验与结果分析
为验证基于IPv6环境的网络信息安全访问控制模型的综合有效性,设计如下仿真实验。
2.1 仿真实验设计
选取Cora、PubMed、Citeseer三个数据集,主要使用Matlab格式进行信息特征存储,其中共计包含200个文档集合以及10000个特征属性和15个类别。实验在Windows 10系统中展开,电脑配置为I7-4210,内存为24TB。
为避免实验结果过于单一,将文献[3]模型、文献[4]、文献[5]模型作为对比方案,从网络信息安全访问控制延时、网络信息利用率以及控制偏差3个角度,与本文模型共同完成性能验证。
2.2 结果与分析
2.2.1 网络信息安全访问控制延时分析
网络信息安全访问控制延时代表控制指令下达和执行的效率,其能够直接体现不同模型的有效性。因此,分别对比4种模型的网络信息安全访问控制延时,具体实验对比结果如图6所示。
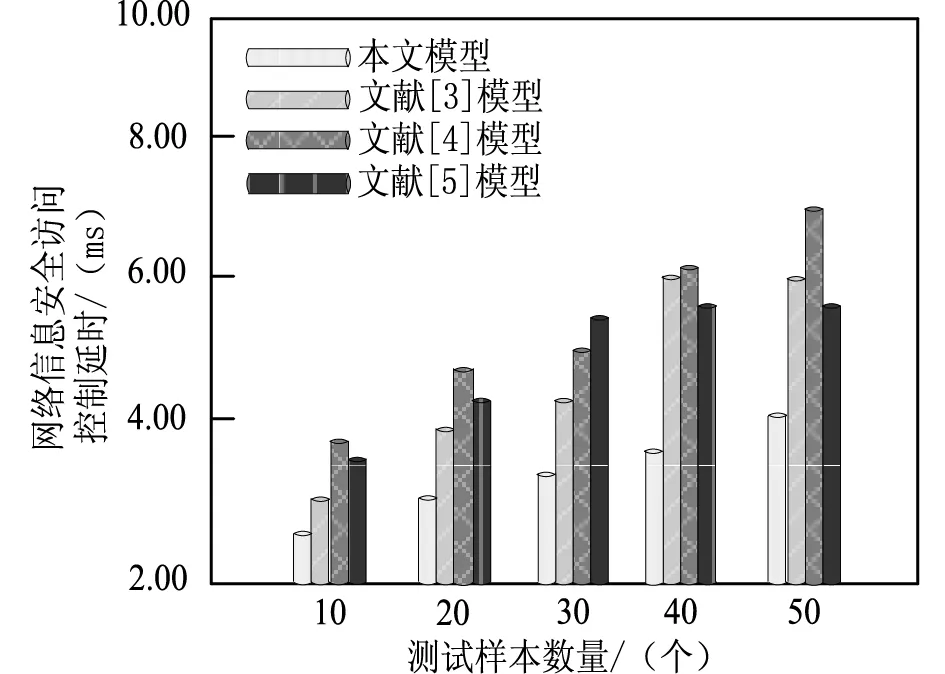
图6 不同模型的网络信息安全访问控制延时对比结果
分析图6中的实验数据可知,在测试样本数量不断增加的情况下,不同模型的网络信息安全访问控制延时也在不断增加。但是本文模型的控制延时始终少于3种对比模型,其实验过程的最大值仅为4ms。这是因为本文模型对网络信息进行降维处理,全面提升了数据的安全性,剔除存在安全隐患的信息,从而使得控制过程的延时得到有效降低,且明显低于另外两种传统模型。
2.2.2 网络信息利用率分析
网络信息利用率是一项延伸性的指标,可以根据模型对信息的利用率来反映模型处理完了信息的能力。因此,在接下来的实验对比阶段,以网络信息利用率为对象对不同模型展开性能测试,结果如表1所示。

表1 不同模型的网络信息利用率对比结果
由表1可知,在实验次数不断增加的情况下,本文所构建模型的网络信息利用率始终保持在96%~99%之间,一直处于相对稳定的状态,而3种文献模型的网络信息利用率则在不断下降。产生这一结果主要是因为本文模型在模型建立前期,对网络信息进行了预处理,通过PCA有效降低了信息维度,确保全部网络信息的利用率得到大幅度提升。
2.2.3 控制偏差分析
控制偏差是一项直观性的指标,通过控制偏差的多少可以直接反映不同模型的控制效果。控制偏差越低,则说明控制效果越好;反之,则说明控制结果不理想。因此,为了进一步验证不同模型控制结果的优劣,测试并对比4种控制模型的控制偏差,具体实验对比结果如图7所示。
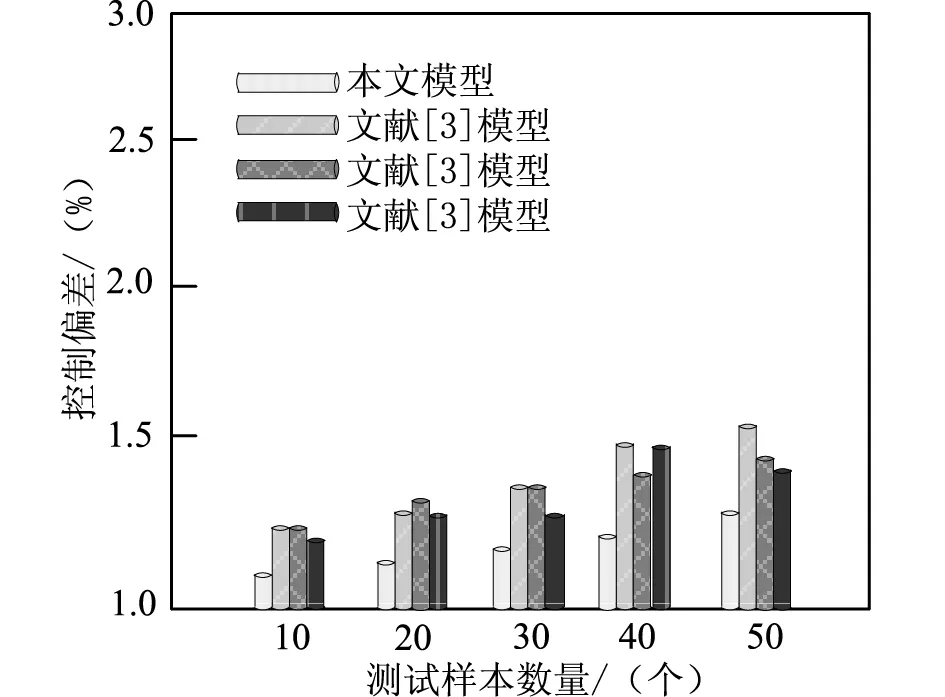
图7 不同模型的控制偏差对比结果
分析图7中的实验数据可知,与文献[3]模型、文献[4]模型以及文献[5]模型相比,本文模型的控制偏差更小,始终保持在1.3%以下。这是因为本文模型由于加入了网络信息预处理操作,整体的控制偏差明显更低一些,同时也验证了在本文模型中加入降维方法的正确性和可行性。
3 结论与展望
针对传统模型存在的一系列问题,本研究提出并设计一种基于IPv6环境的网络信息安全访问控制模型。仿真实验结果表明,该模型能够有效降低网络信息安全访问控制延时以及偏差,同时提升网络信息利用率。
尽管本文模型增加了对网络信息的预处理过程,并引入了信任值以及上下文约束概念构建访问控制模型,但预处理可以使网络信息中的无效信息被剔除,且利用上下文约束概念在主体与客体之间增加了角色层,避免了用户冲突,这也使得这些步骤不会对模型计算和存储开销造成较大影响。此外,相比于IPv4环境,IPv6环境的地址空间更大,支持组播和对流功能。本文模型可以很好地满足在IPv6环境中使用要求,因此,也同样适用于IPv4环境。
限于知识水平以及研究时间,本文模型仍然存在一定的不足,后续将重点针对以下几方面的内容展开深入研究。
(1)现有的信任机制还需要进一步进行完善,同时还应该考虑在信息交互的过程中,要给予交互实体一定的奖励,全面提升其信任度;
(2)进一步提升网络信息的安全性,同时确保得到的上下文信息真实性以及可靠性。
