基于XGBoost的深圳二手房价格预测*
2022-01-23胡晓伟马春梅孔祥山李凤银
胡晓伟, 马春梅, 孔祥山, 李凤银
(曲阜师范大学计算机学院,276826,山东省日照市)
0 引 言
随着我国城市化进程的加速,城市常住人口不断增加,而发达地区的土地供应不断减少,导致了城市房价不断攀升. 另一方面,二手房的周围配套设施相对比较完善,如拥有成熟的交通、商业、教育环境等,越来越多的购房者开始关注二手房. 但是,二手房信息对购房者不够公开透明,购房者无法客观准确地评估二手房的价格. 在我国,关于房地产价格的评估方法主要有市场法、收益法、成本法等,它们大多适用于不同的市场环境. 这些方法更加注重定性分析,因此受主观因素影响较大.
2004年,Limsombunc等[1]指出影响夏威夷市房价的因素有面积、楼龄、户型、卧室数量、卫生间数量、环境和地理位置,并且根据所选择的影响因素建立了 Hedonic 模型和人工神经网络模型,实验表明神经网络模型的预测效果更好. 2012年,Antipov等[2]在模型中引入了地铁距离、市中心距离以及房屋地理位置这三个区位特征,使得房价预测结果更加趋于实际价格. 但是,他们没有考虑到生活、教育配套等这一重要的邻里特征. 2015年,Fotheringham等[3]加入了空间效应,构建了地理加权回归(Geographical Weighted Regression,GWR)模型,考虑了地理位置对房价的影响因素,预测了伦敦1980~1998年的房价. 由于加入了地理位置这个重要的影响因素,使得房价预测更加实际化. 但是,不同国家房价的影响因素是不同的,如房产税率、浴室数量等因素可能影响美国的房价,而对中国的二手房价格却几乎没影响. 2018年,Denisko与Hoffman等[4]利用北京市在售的二手房数据,加入多类别变量建立随机森林模型,研究了影响房价的因素以及对房价的预测,进一步提高了预测的准确性. Mohd等[5]人在2020年的房价预测的房地产建模技术综述中,介绍了人工神经网络(Artificial Neural Network,ANN)、支持向量机(Support Vector Machine,SVM)、线性回归(Linear Regression,LR)、随机森林(Random Forest,RF)、K近邻(K-Nearest Neighbor,KNN)、朴素贝叶斯(Naive Bayes,NB)、空间分析(Spatial Analysis,SA)、岭回归(Ridge Regression,RR)、套索回归(Lasso Regression,LR)等众多的房价预测模型,对各种模型的优缺点进行了说明,指出要根据实际需要解决的问题选择合适的模型. 陈世鹏、金升平[6]运用襄阳2012年的房屋贷款数据,加入房贷的影响因素,创建随机森林模型进行房价预测,与ARMA模型(自回归滑动平均模型)和多元线性回归模型进行对比,发现随机森林模型有很好的预测效果. 张靖苗[7]以昆明和成都的二手房为研究对象,利用GIS空间分析技术寻求不同城市的住宅价格空间分布规律,构建地理加权回归模型,分析了住宅小区之间的空间分异现象. 近年来,XGBoost模型在关于价格预测问题中得到了广泛应用. 杨贵军等[8]人利用XGBoost算法对消费者汽车消费偏好作了相关研究,为产品研发决策和商品推荐提供了重要参考. 梁佩[9]在传统特征价格模型的基础上加入了空间效应,运用XGBoost模型,以空间因素作为权重,得到一种标准的XGBoost模型. 龚洪亮[10]利用XGBoost模型对武汉市的二手房价格预测作出实验研究,用特征价格理论探究房价的影响因素,但是并未考虑相关地理因素对房价的影响.
本文利用XGBoost模型对深圳二手房价格进行预测. 传统的房价预测主要考虑住房面积、楼龄、户型、卧室数量、地理位置等对房价的影响,很少考虑生活配套、教育配套、交通配套等影响因素. 本文不仅考虑了传统的影响因素,而且考虑了生活配套、教育配套、交通配套等影响因素,结合百度地图进行POI(Point of Interest)处理,利用原始数据集中的经纬度和百度地图API,计算以房源为中心,分别以半径为500 m,1 000 m,2 000 m的地理范围内的地铁、学校、医院等生活配套设施的数量,从而引入了邻里特征,使得房价预测结果更加趋于实际值,提高了预测的准确性.
1 相关模型介绍
1.1 多元线性回归模型
多元线性回归模型常用于两个及两个以上的影响因素作为自变量来解释因变量的变化. 当多种自变量与因变量之间是线性关系时,所进行的回归分析就是多元线性回归. 多元线性回归模型可表示为
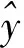
1.2 随机森林模型
随机森林模型是一种重要的基于Bagging的经典集成学习方法,可以用于解决分类、回归等问题. 随机森林模型有很多优点,如极高的准确率、不容易过拟合、可处理高维数据以及容易实现程序并行化等.
使用随机森林进行数据预测的过程如图1所示. 首先,在原始数据集中随机进行有放回的抽样,构成n个不同的样本数据集. 然后,为每个样本数据集构造决策树,构建成n个不同的决策树模型. 最后,根据这些决策树模型的平均值来获得最终结果.

图1 随机森林预测过程
1.3 XGBoost模型
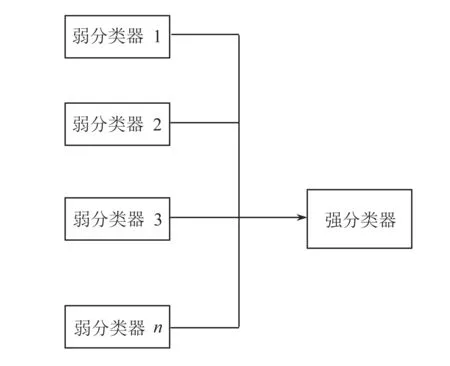
图2 多个弱分类器形成一个强分类器
XGBoost是Boosting算法的一种. 如图2所示,Boosting算法的思想是将许多弱分类器集成在一起形成一个强大的分类器. 因为XGBoost是一种提升树模型,所以它是由许许多多的树模型集成在一起而形成的一个强分类器,所用到的树模型则是CART回归树模型.
XGBoost算法思想是不断地添加树,每一次特征的分裂都会增加一棵新树,且每棵新树都是用一个新函数拟合上次预测的残差,当训练完成会得到K棵树. 预测一个样本的分数,实际上是根据这个样本的特征,每棵树中会落到其对应的一个叶子节点,每个叶子节点对应一个分数,最后将每棵树对应的分数加起来就是该样本的预测值.
XGBoost的目标函数由训练损失函数和正则化项两部分组成,目标函数定义如下
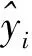
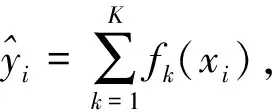
2 基于XGBoost的房价预测
2.1 数据预处理与清洗
原始数据集是利用爬虫程序在链家网站上爬取的,是2019年深圳市二手房交易数据,共1 432条数据. 对数据集进行建模时,首先需要对数据进行预处理和清洗,因为原始数据集中总会有一些缺省值和超出现实的异常值,甚至原始数据集中带有单位. 所以,只有将数据集进行预处理和清洗,才能保证数据的准确性. 对于缺失值可采用同小区均值填充,对于异常值则直接删除,对于有单位的数据则直接删除单位. 此外还对数据集进行了哑变量(虚设变量,通常取值为0或1)操作,即将对象数据类型转换为模型可以识别的类型. 图3为本次原始数据集的房价整体立体图. 从图3可以看出,不同的地理位置整体房价是不同的,越靠近海边房价越高. 即便是位于同一个区域,房价也是不同的. 我们把房源的位置信息称为区位特征. 图4为建筑面积与总房价的散点图,从图4可以看出房价与建筑面积总体上呈线性关系,但建筑面积并非是决定房价的唯一因素,比如同一个小区内亦有高价房和低价房.
本文进一步利用百度地图的API进行POI处理,计算以房源为中心,分别以半径为500 m,1 000 m,2 000 m的地理范围内的地铁、学校、医院等生活配套设施的数量,部分结果如表1所示. 经过对比分析发现,周边地铁、学校、医院等配套设施越多,单位房价越高. 我们把房源周围的地铁、学校、医院等设施配套情况称为邻里特征.

图3 深圳二手房房价整体立体图

图4 建筑面积与总房价散点图

表1 经过POI处理后的部分数据
2.2 数据特征选取
特征选择可以将高维空间的样本通过相关变换的方式转换到低维空间,达到降维的目的,随后删掉冗余和不相关的特征来进一步降维. 这样做可以减少过拟合、减少特征数量(降维)、提高模型泛化能力,而且还可以使模型获得更好的解释性,增强对特征和特征值之间的理解,加快模型的训练速度,获得更好的性能. 本文中特征选取前有楼盘名称、经纬度、成交时间、区域、调价、带看、关注、浏览、房屋户型、所在楼层等35个特征,这些特征有些与房价相关性强,有些则弱,需要使用一定方法降低数据维度. 图5为相关系数热力图,颜色越深表示相关性越大,从图5可以看出调价、带看、关注、浏览、成交周期、区域、子区域、楼盘名称等这些数据维度对房价的影响较小,本文忽略这些特征. 此外,还利用随机森林中的重要性评价来选择相应的维度. 表2是随机森林对特征变量进行重要性评估的结果. 本文排序后选择中位数以上的特征变量,忽略中位数以下的特征变量.
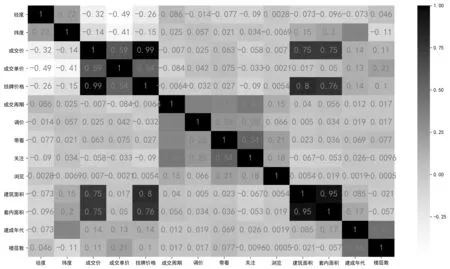
图5 特征变量与房价的相关系数热力图
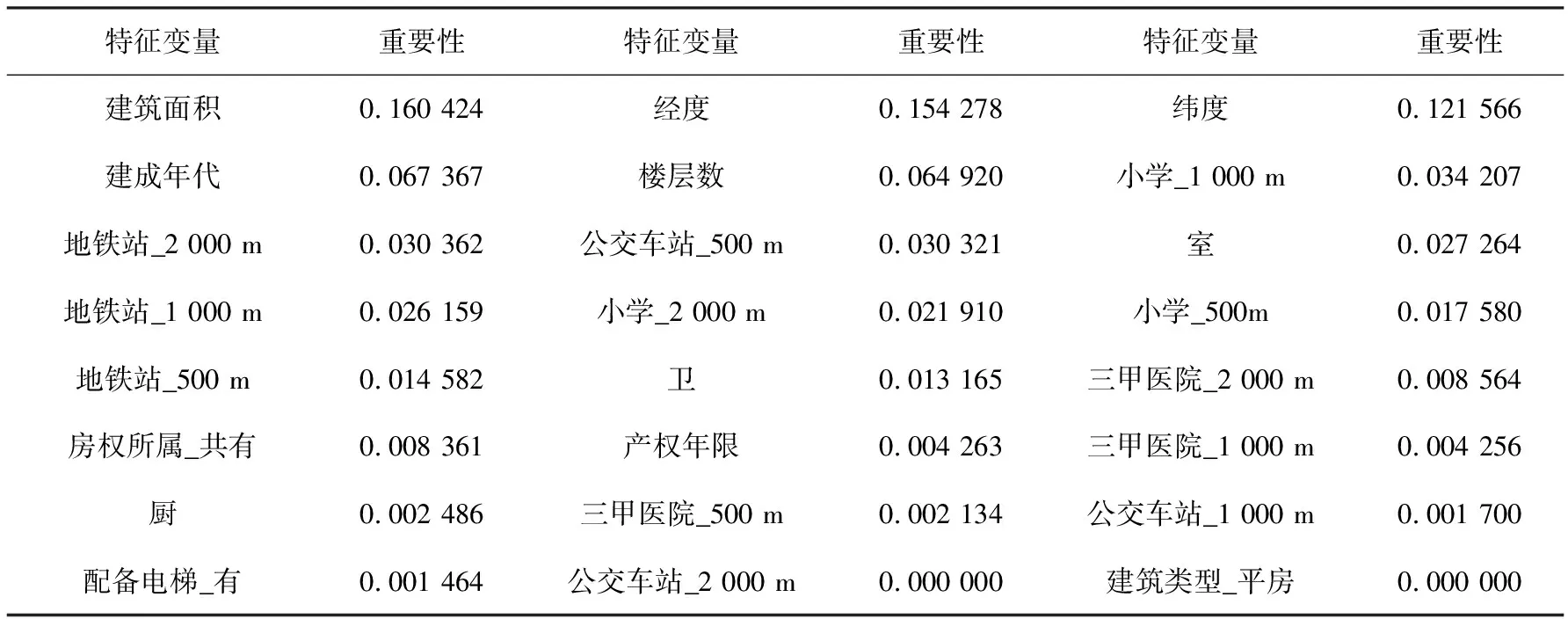
表2 随机森林中的特征变量重要性评价
综上分析可以看出,房地产价格的影响因素主要包括建筑特征、邻里特征和区位特征. 本文结合热力图、随机森林中的重要性评价以及上述三大特征变量,最终选取的特征变量如表3所示.

表3 影响二手房价格的特征变量及其含义
2.3 房价预测
本文中的XGBoost流程图如图6所示,将清洗好的数据进行特征选取、重要性排序和POI处理得到新的数据集,使得新数据集更加接近现实. 随后利用网格搜索对部分参数进行调节,最终得到的结果如图7所示. 从图7可以看出,在测试集上,虽然有个别样本波动比较大,但大部分预测的成交价格与真实的成交价格实际误差较小,尤其是低房价几乎重合,反映出该模型具有较好的泛化能力. 这是由于XGBoost对损失函数进行了二阶泰勒展开,一方面增加精度,另一方面也为了能够自定义损失函数.

图6 XGBoost流程图
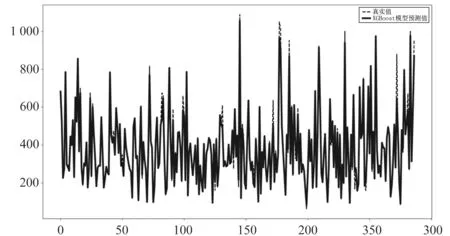
图7 XGBoost模型预测效果图
3 实验对比
3.1 不同模型实验结果比较
本文比较线性回归模型、随机森林模型和XGBoost模型对房价预测的结果. 统一采用Sklearn包中的train_test_split()函数,该函数功能是将原始数据按照比例切分为训练集和测试集. 如果训练集合过小,可能导致欠拟合,所以我们把数据集的80%作为训练集,20%作为测试集.
对于线性回归模型,本文使用sklearn库的线性回归函数进行调用训练. 利用梯度下降法获得误差最小值,最后使用均方误差法来评价模型的好坏程度,预测的结果如图8所示. 从图8可以看出,真实值和预测值间的差距比较大,只有部分结果重合,对于较高的房价预测结果较为不理想,需要更多的维度和更好的模型来预测房价. 基于随机森林的模型计算过程如下:将训练集分成5份,使用网格搜索并进行CV交叉验证. 随机森林可以调节的参数比线性回归模型的参数要多,本文利用网格搜索,对n_estimators和max_depth做了参数调节,并用K折交叉进行验证. 预测结果如图9所示,从图9可以看出,预测结果比线性回归模型要好,这是由于多元线性回归模型是一个单一的模型,而随机森林是多个决策树融合的集成模型. 但是,同样对于部分低房价和高房价的预测较为不理想,效果要稍微略低于XGBoost模型.
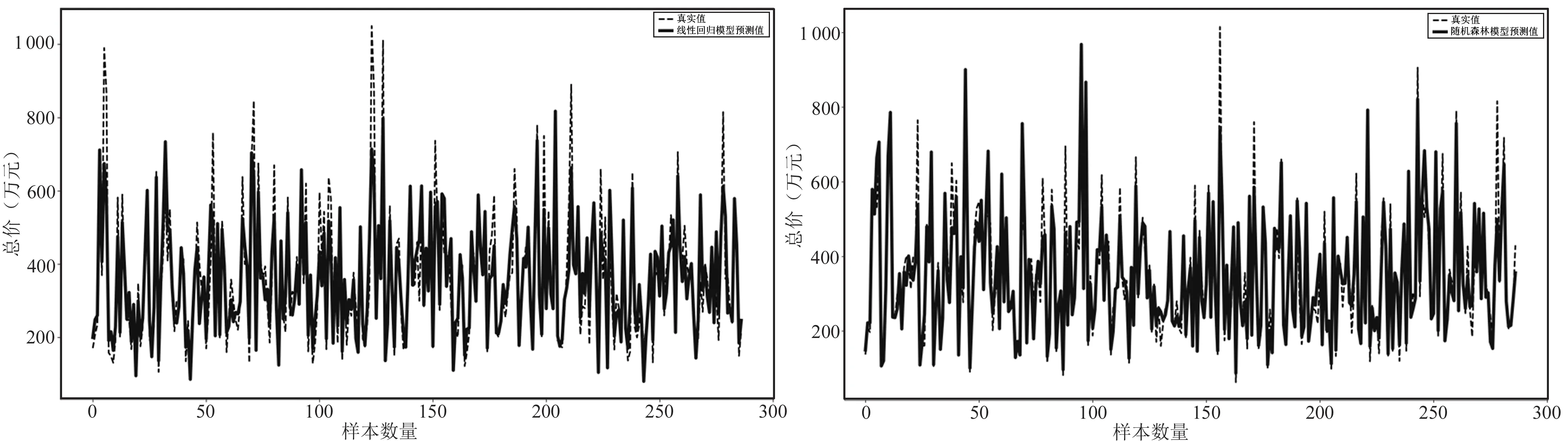
图8 线性模型预测效果图 图9 随机森林模型预测效果图
XGBoost模型在房价预测上具有良好的效果,而合适的数据集同样重要. 本文的数据集中引入了POI这一特征,而图10表示的是没有POI处理的数据集在XGBoost模型下的预测结果. 图10显示,虽然XGBoost模型的预测准确度是最好的,但没有经过POI处理,准确度也会受到一定的影响. 因此可以得出,POI的数据处理,对房价预测具有积极的作用.
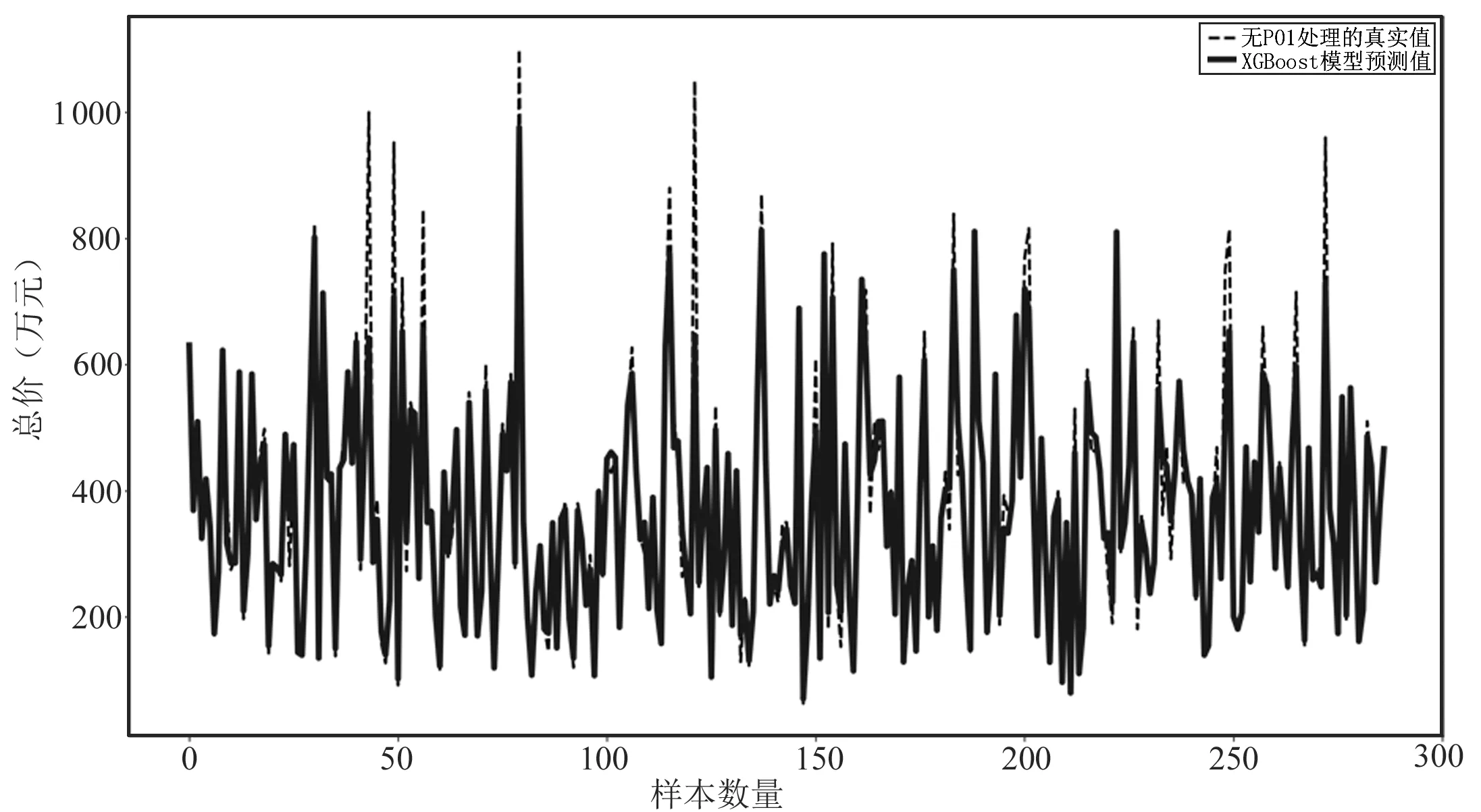
图10 无POI处理的数据集在XGBoost模型下的预测效果图
3.2 不同模型数值比较
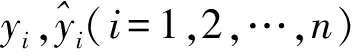
(1)决定系数(R-Squared,R2)一般用在回归模型中,用于评估预测值和实际值的符合程度,其值取值范围是[0,1],越接近于1说明模型越准确,表示自变量越能解释因变量的方差变化,值越小则说明效果越差.R2定义如下
(2)平均绝对误差(Mean Absolute Error,MAE)用于评估预测结果和真实值的接近程度,其值越小说明拟合效果越好. MAE定义如下
(3)均方误差(Mean Squared Error,MSE)是指预测值与真实值之差的平方的期望值. MSE可以评价数据的变化程度,MSE值越小,说明预测模型描述的数据具有更好的精确度. MSE定义如下
(4)均方误差根(Root Mean Squared Error,RMSE)是MSE的平方根.
本文从测试集中分别计算线性回归模型、随机森林模型和XGBoost模型的4种评价指标值,结果如表4所示. 从表4可以看出,线性回归模型拟合结果最差,XGBoost拟合结果最好. 表5是部分预测值与真实值的对比.

表4 模型结果比较

表5 部分房价预测值与真实值对比
4 结束语
本文构建了房价评估的三种机器学习的模型,并以二手房的价格预测展开实证研究. 对数据的预处理,特征选择,POI增加维度,模型建立,网格交叉验证,使得房价预测结果更趋近于真实值. 在保证准确度的情况下,尽可能的对模型进行了优化,最终使得XGBoost模型的R2值达到了0.951 25. 在实际中,影响房价的价格并不仅仅只有本文列出的特征,可能还有小区的停车位、周围环境、物业管理等额外因素,在后续工作中我们再考虑上述额外因素,进一步提高模型的精度,提高预测的准确度.
