复杂姿态下的安全帽佩戴检测方法研究
2022-01-22王雨生顾玉宛庄丽华徐守坤
王雨生,顾玉宛,庄丽华,石 林,李 宁,徐守坤
常州大学计算机与人工智能学院阿里云大数据学院,江苏 常州 213164
在日常生产中,工人因安全措施不到位受伤占生产安全事故的大部分[1]。由于国情特殊,工人素质参差不齐,尽管各单位经常进行安全教育,总有心存侥幸者因为各种理由不能保证时刻佩戴。
安全帽佩戴检测经过多年的发展,已经从传统的机器学习方法转向深度学习方法。部分学者使用流行的目标检测网络检测安全帽佩戴情况,例如,文献[2]改进YOLOv2 目标检测方法,在原网络中加入了密集块,实现了多层特征的融合以及浅层低语义信息与深层高语义信息的兼顾,提高了网络对于小目标检测的敏感性,利用MobileNet 中的轻量化网络结构对网络进行压缩,使模型的大小缩减为原来的十分之一,增加了模型的可用性。文献[3]在原始YOLOv3 的基础上改进GIoU 计算方法,结合YOLOv3算法目标函数组成一个新的目标函数,实现了目标函数局部最优为IoU 局部最优,该方法,相比于YOLOv3算法在检测精度上有所提高。这一类方法使用改进的目标检测网络对安全帽进行检测,解决了小目标以及部分遮挡的问题,但没有解决安全帽与人体的相对位置关系。
部分学者通过头部定位的方法检测安全帽佩戴情况,例如,文献[4]提出基于运动对象分割的结果,快速地定位行人,根据行人检测结果,通过头部位置、颜色空间变换和颜色特征判别实现安全帽佩戴检测,该方法中头部位置的判别是根据行人的身体比例的五分之一进行判别,这样的方法不具有普适性。文献[5]通过检测对应图像中身体部位的可见段确定骨架点,然后获取对应于极端节点的线段,并计算其与垂直轴的倾斜度。如果倾斜在一定夹角之内,该线段夹角之内被分类为人的头部。同样的,这样的方法也是针对直立行人,不符合施工人员姿态复杂的情况。此类方法大多针对是直立人员的安全帽检测,而现实的施工作业现场,施工人员的姿态非常多样复杂。
基于复杂姿态的情况下对安全帽识别难度增大的原因,本文提出一种基于头部识别的安全帽佩戴检测方法,通过面部特征识别与头部识别交叉验证,精确定位施工人员头部区域,解决施工人员复杂姿态下头部位置难确定的问题。使用YOLOv4 目标检测网络进行安全帽佩戴检测,并解决了安全帽与人体的相对位置关系,从而对安全帽佩戴情况进行判定。本文主要解决了施工人员复杂姿态下安全帽佩戴检测精度低的问题。
1 安全帽佩戴检测方法
本文设计的安全帽佩戴检测方法流程如图1所示,首先对施工人员的头部进行定位,通过肤色特征识别和头部检测识别分别获取头部区域并进行交叉验证,确定头部区域;接着,使用YOLOv4 目标检测网络对安全帽进行识别;最后根据数据集特征,对安全帽是否正确佩戴进行判定。
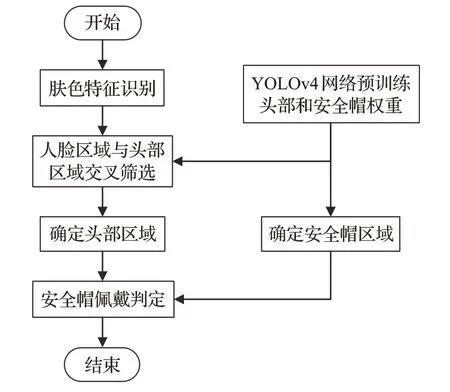
图1 安全帽佩戴检测方法流程Fig.1 Process of detection method for wearing helmet
1.1 YOLOv4目标检测网络
YOLOv4[6]是YOLO系列的最新检测网络,在YOLOv3的基础上进行各种先进算法集成的创新。因此本文使用YOLOv4目标检测网络进行安全帽佩戴检测,以期提高安全帽佩戴检测方法的性能。
YOLOv4 输入端的创新包括Mosaic 数据增强、cmBN、SAT 自对抗训练;主干网络创新包括CSPDarknet53、Mish激活函数、Dropblock;Neck的创新包括目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如SPP 模块、FPN+PAN 结构;预测部分输出层的锚框机制和YOLOv3 相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms 变为DIOU_nms。
YOLOv4 使用了CSPNet[7]与Darknet-53 作为特征提取的骨干网络,相比于基于ResNet[8]的设计,CSPDarknet53 模型的目标检测准确度更高,不过ResNet 的分类性能更好一些。但是,借助Mish和其他技术,CSPDarknet53的分类准确度可以得到提升。
为了检测不同大小的目标,需要使用一种分层结构,使得目标检测的头部可探测不同空间分辨率的特征图。为了让输入头部的信息更丰富,在输入头部前,会将来自自底向上和自上而下的数据流按逐元素的方式相加或相连。SPP相较于YOLOv3中使用的FPN[9]网络能够极大地增加感受野,分离出最显著的上下文特征,并且几乎没有降低网络运行速度。且YOLOv4 针对不同级别的检测器从不同骨干层中挑选PANet[10]作为参数聚合方法。因此,YOLOv4 使用修改版的SPP、PAN 和SAM 逐步实现替换了FPN,保留了来自自底向上数据流的丰富空间信息以及来自自上而下数据流的丰富语义信息。YOLOv4的网络结构如图2所示。
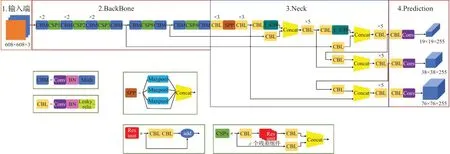
图2 YOLOv4的网络结构图Fig.2 Network structure diagram of YOLOv4
同时,YOLOv4 合理利用bag of freebie 和bag of specials 进行调优处理。与YOLOv3 相比,YOLOv4 的AP和FPS分别提高了10%和12%。
1.2 头部定位方法
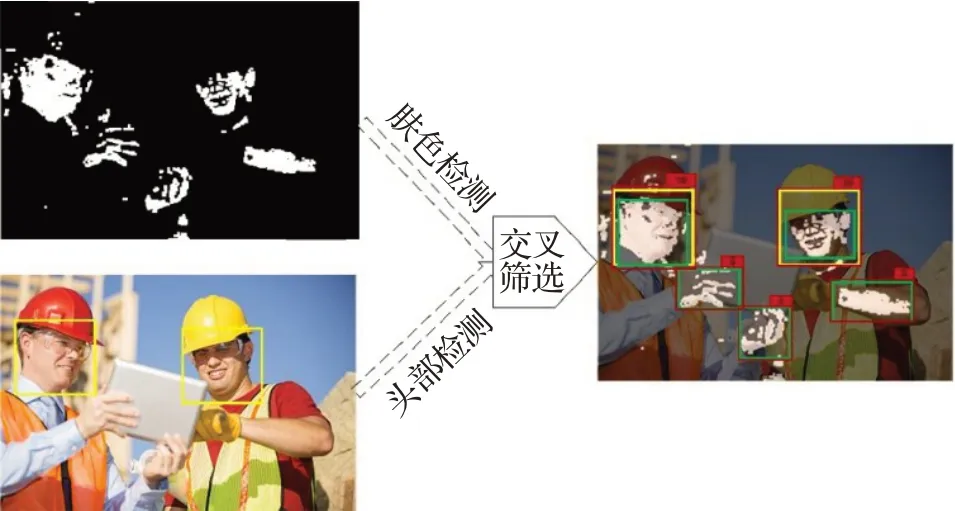
因为施工人员姿态复杂,头部姿态多种多样,单一的检测网络无法准确检测出头部区域。本文提出的头部定位方法用于精确定位施工人员头部区域,解决施工人员复杂姿态下头部位置难确定的问题。主要步骤为:(1)识别肤色特征检测人脸区域;(2)预训练权重检测头部;(3)人脸区域与头部区域交叉筛选;(4)判断图片所有头部区域。
1.2.1 肤色检测
工人施工状态下,露出皮肤的区域基本只有脸部、脖颈、手部区域。因此本文首先对图片进行光线补偿,接着在YCbCr色彩空间上对工人肤色进行聚类,YCbCr颜色空间相较于RGB 便于色度分析[11],RGB 向YCbCr色彩空间的转换[12]公式如式(1)所示:
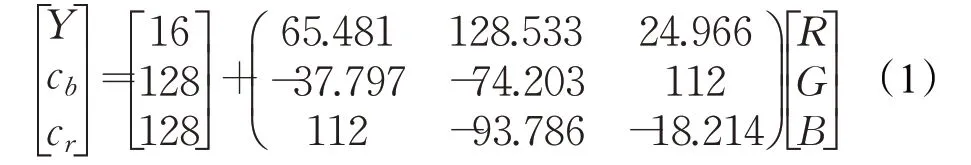
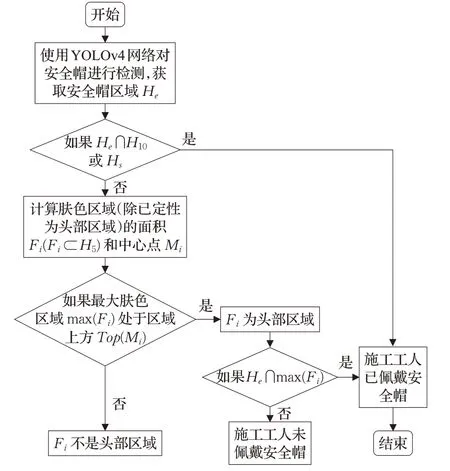
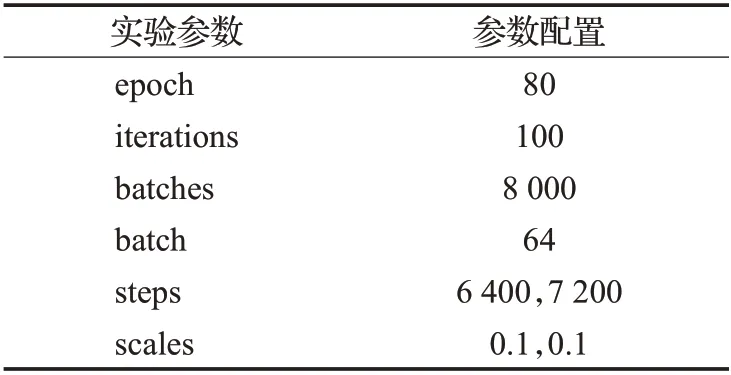
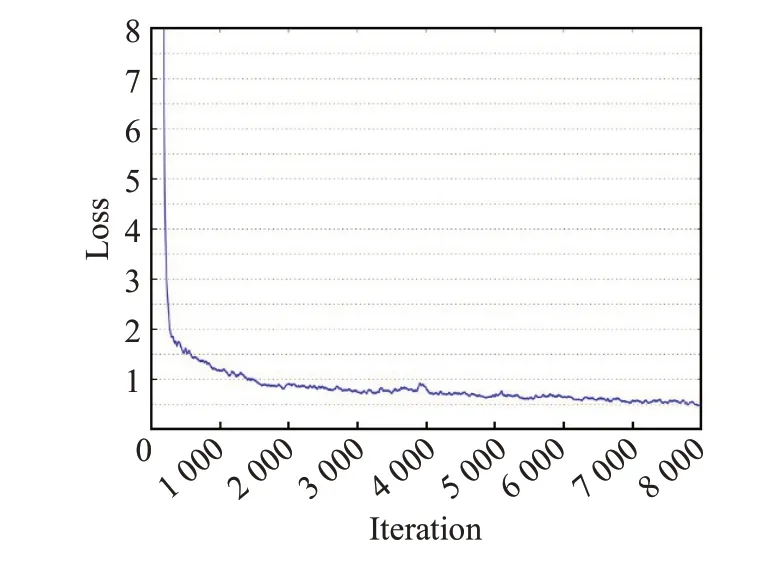
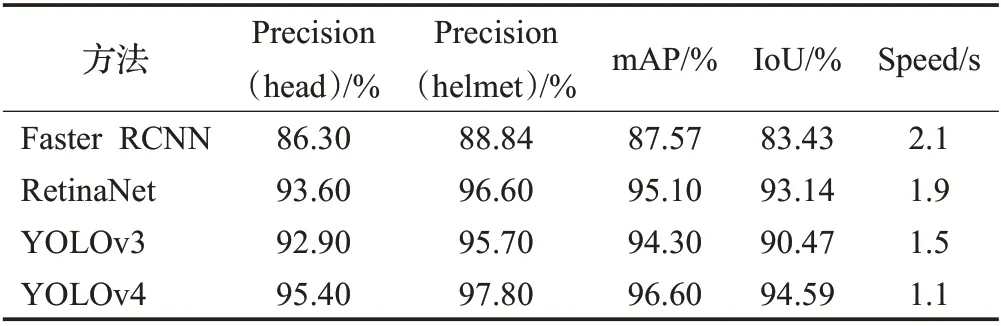
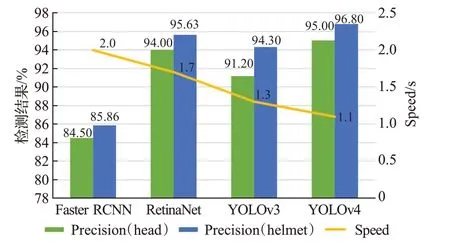
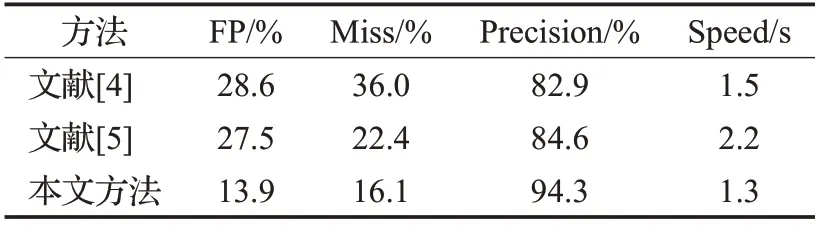
本文使用基于YCrCb 颜色空间范围筛选法对肤色进行识别。实验选取100 张图片对肤色的RGB 特征进行k-means 聚类,再转换得出Y、Cr、Cb范围分别为85 最后在图像相关形态学处理后,将连通区域较大的部分定位,待定为人脸区域,便于后续交叉验证。基于YCrCb颜色空间对肤色进行识别效果,如图3所示。 图3 基于YCrCb颜色空间对肤色进行识别效果Fig.3 Effects of skin color recognition based on YCrCb 1.2.2 头部检测 因为施工人员姿态复杂,头部姿态多种多样,目前没有一个针对施工场景的头部数据集,所以本文使用HollywoodHeads 数据集[14]和YOLOv4 网络预训练头部检测权重。 HollywoodHeads数据集包含来自21部好莱坞电影的224 740 个视频帧中的369 846 人物头部。对于每个人物头部,在几个关键帧上手动标注了头部边界框。该数据集分为训练,验证和测试子集,这些子集在动作方面没有重叠。能见度较差的人物头部(例如,强烈的闭塞、低光照条件)被“困难”标志标记,并被排除在评估之外。 HollywoodHeads 数据集在YOLOv4 网络训练下,AP 值达到95.4%。预训练权重对正常姿态(直立、行走等)的人头检测效果良好,预训练权重效果如图4 所示。但是对于姿态复杂的人头检测,存在漏检的情况。于是,本文就人脸检测区域与人头检测区域进行交叉筛选,从而判断图片所有头部区域。 图4 头部预训练权重效果Fig.4 Effects of head pre-training weight 1.2.3 头部区域交叉筛选 本文提出头部区域交叉筛选方法,为了解决头部检测网络存在漏检的现象。根据本文数据集特点,施工工人在复杂姿态下,部分头部难以检测,但仍能检测出面部肤色特征。故本文将已检测出的肤色区域以及人头区域进行对比筛选,具体流程如图5所示。 图5 头部区域交叉筛选流程Fig.5 Cross screening process of head area 在进行肤色区域及人头区域进行对比筛选时,连通区域较大的肤色区域并不全是人脸区域,存在手臂,双手,脖子等肤色区域。本文数据集样本中,工人姿态复杂,脖子等肤色区域亦可辅助判断头部区域,所以本文保留手臂、双手、脖子等肤色区域,并对所有区域进行评估。当肤色区域与人头区域有重叠时,评估该区域为头部区域,评估值为10;当有且只有人头区域,评估该区域为头部区域,评估值为8;当有且只有肤色区域时,评估该区域为疑似头部区域,评估值为5。令肤色区域为F,人头区域为H,评估值为x则头部区域交叉筛选公式为: 通过设定评估值,进一步确定图片中的头部区域,可以提高安全帽佩戴检测的精确度,也为安全帽佩戴判断方法提供支持。 本文使用YOLOv4网络对安全帽进行检测,再在头部区域判断施工工人是否佩戴安全帽。前文中已经对头部区域进行评估,通过安全帽区域与头部区域的位置判定,本文即可判断安全帽佩戴情况。 根据数据集特点,若安全帽区域He交于评估值为10 和8 的头部区域H10和H8,则判定施工工人佩戴了安全帽。对于头部区域H5(疑似头部区域),包含面部、脖子、手臂、双手等肤色区域,安全帽区域He与H5相交存在手持安全帽的危险情况。本文根据人体结构以及数据集特征发现,安全帽区域只存在头部和手部,即施工人员头部佩戴安全帽和手持安全帽。因此,本文计算所有肤色区域(除已经定性为头部区域)的面积Fi(Fi⊂H5)和中心点Mi,面积计算使用Seed Filling(种子填充法),其思路为: 选取一个前景像素点作为种子,然后根据连通区域的两个基本条件(像素值相同、位置相邻)将与种子相邻的前景像素合并到同一个像素集合中,最后得到的该像素集合则为一个连通区域。下面给出基于种子填充法的连通区域分析方法。 (1)扫描图像B,直到当前像素点B(x,y)==1: ①将B(x,y)作为种子(像素位置),并赋予其一个label,然后将该种子相邻的所有前景像素都压入栈中; ②弹出栈顶像素,赋予其相同的label,然后再将与该栈顶像素相邻的所有前景像素都压入栈中; ③重复②步骤,直到栈为空。 此时,便找到了图像B中的一个连通区域,该区域内的像素值被标记为label。 (2)重复第(1)步,直到扫描结束: 扫描结束后,就可以得到图像B中所有的连通区域; 计算中心点使用image moments(图像矩)求得,对每个连通区域运用计算几何距算法得到中心,数学表达为: 其中,M00是零阶矩,M10和M01是一阶矩,ic和jc是图像的中心坐标。 通过对比肤色区域面积判断手部区域和头部脖颈区域,再根据中心点和安全帽区域中心点的相对位置判断安全帽的佩戴情况。一般情况下,大多头部脖颈区域处在手部区域上方。故可根据这一特征,当且仅当最大肤色区域max(Fi)处于区域上方Top(Mi)时,判断该区域为头部区域,若安全帽区域与头部区域相交,即He⋂max(Fi),则判定施工工人佩戴了安全帽,否则判定施工工人未佩戴安全帽。具体流程如图6所示。 图6 安全帽佩戴判断方法流程Fig.6 Process of judgment method for wearing helmet 本文安全帽数据集由网络爬虫收集,公共数据集选取,实地采集所组成,共8 000张。数据集包含各类施工场景中单人以及多人的各种姿态的图片。并且,本文考虑了正负样本之间的平衡(其中佩戴安全帽的正样本4 500张,未佩戴安全帽的负样本3 500张),同时本文对数据集进行了数据增广,通过翻转,模糊,平移等操作扩充数据集至40 000张。数据样本示例如图7所示。 图7 数据样本Fig.7 Data samples 实验环境配置:GPU 为NVIDIA TITAN Xp×2,CUDA 10.0,Ubuntu 16.04,内存12 GB。 本文实验使用精确度(precision)、误检率(false positive,FP)、漏检率(miss)、交并比(IoU)和平均精度(mAP)来衡量方法的有效性,计算公式如(6)~(9)所示: 其中,TP(true positive)表示被模型预测为正值的正样本;FP(false positive)表示被模型预测为负值的正样本;FN(false negative)表示被模型预测为负值的负样本;TN(true negative)表示被模型预测为正值的负样本。PartAcreage 是检测后框出地安全帽区域,Overall-Acreage是标记的安全帽区域。 3.1.1 YOLOv4网络训练 本文使用YOLOv4 目标检测网络检测头部区域和安全帽区域。本文将安全帽数据集与头部数据集合并训练,按6∶2∶2分为训练集、验证集和测试集,其中对训练集与验证集进行标注。 本文网络训练参数设置如表1 所示,训练学习率(learning rate)为0.001,轮次(epoch)为80 次,每一轮次迭代次数(iterations)为100 次,一共迭代次数(batches)为8 000,每一次迭代训练的样本数为64。学习率变动步长(steps)设置为(6 400,7 200),根据batch_num 调整学习率。学习率变动因子(scales),迭代到6 400 次时,学习率×0.1;迭代到7 200次时,学习率又会在前一个学习率的基础上×0.1,Steps 和scales 相互对应,这两个参数设置学习率的变化。 表1 网络训练参数设置Table 1 Network training parameter settings 最后损失值(Loss)在0.5左右振荡。数据集的训练损失值如图8所示,卷积层特征可视化如图9所示。 图8 训练损失曲线Fig.8 Training loss curve 图9 卷积层特征可视化Fig.9 Feature visualization of convolutional layer 3.1.2 目标检测网络效果对比 本文从精度、平均精度、交并比、检测时间4个指标评估Faster RCNN[15]、RetinaNet[16]、YOLOv3[17]、YOLOv4这4 个目标检测网络的检测效果,其中YOLOv3、YOLOv4为一阶目标检测网络,faster RCNN、RetinaNet为二阶目标检测网络。对比实验效果如表2所示。 表2 目标检测网络实验结果对比Table 2 Comparison of experimental results of target detection network 从表2 可以看出针对本文数据集,YOLOv4 目标检测网络无论从精度上还是从检测时间上都要优于其余3种网络。甚至,从precision 值以及mAP 值看,YOLOv4作为一阶目标检测网络也要优于Faster RCNN、RetinaNet这两个二阶目标检测网络。YOLOv4作为YOLO系列的最新检测网络,大大提高了本文对头部区域和安全帽区域的检测精度。4种网络对测试数据集检测效果如图10、11所示。 图10 4种网络检测结果对比Fig.10 Comparison of four network detection results 图10展示的是4种网络检测测试图片的各项指标,分析数据可以看出YOLOv4 各项指标都要优于其余3种网络。综合图11 看,工人在直立姿态下,4 种网络检测效果相近,在复杂姿态下,YOLOv4 检测头部区域和安全帽区域效果都要优于Faster RCNN、YOLOv3,而RetinaNet 作为较新的二阶目标检测网络检测效果与YOLOv4 相近,但是检测时间相对弱势。所以,本文选取YOLOv4 作为目标检测网络检测头部区域和安全帽区域。 图11 4种网络检测效果对比Fig.11 Comparison of four network detection effects 为了验证本文方法的效果,对比文献[4]和[5]的安全帽检测方法。文献[4]和文献[5]均采用了头部定位的方法检测安全帽。 3.2.1 头部区域检测实验 本文通过头部区域交叉筛选方法,解决头部检测网络存在漏检的现象。并且施工工人在复杂姿态下,针对部分头部难以检测,本文方法仍能通过肤色特征与头部特征,判断安全帽佩戴情况。实验效果如图12所示,本文方法进行肤色检测,筛选出肤色连通区域,通过种子填充法计算出各连通区域的面积和中心坐标,判断头部区域。图12(b)、(d)为图12(a)、(c)的中间计算效果图,可以计算出图12(a)、(c)中的最大连通区域面积(分别为2 113.0 和1 609.5)和中心坐标((100,117)和(237,89))。实验结果显示方法标记的区域为头部区域。 图12 安全帽佩戴判断方法Fig.12 Judgment method of wearing helmet 3.2.2 安全帽检测对比实验 在施工人员为复杂施工姿态下,文献[4]使用的方法失效,其检测人体的上部1/5 区域的方法只适合直立的施工人员;文献[5]使用的方法相较文献[4]的方法有所提高,但是还是存在漏检的现象,主要是因为其通过计算骨架点与垂直轴的倾斜度来判断头部位置,也是适用于直立的施工人员。 根据表3数据显示,本文方法在精度和速度上均优于文献[4]和文献[5]的安全帽检测方法,实验使用本文数据集,上述两种方法对于部分样本失效。然而从图13可以看出,本文方法不受限于工人的姿态。 表3 安全帽检测方法结果对比Table 3 Comparison of safety helmet detection method results 图13 安全帽检测方法效果对比Fig.13 Comparison of safety helmet detection method effects 同时,本文方法通过头部区域与安全帽区域的位置关系,判断安全帽佩戴情况,可以检测出手持安全帽这类危险情况。如图14 所示,当头部区域与安全帽区域相交时,则判断施工人员佩戴了安全帽。当手持安全帽,或者未带安全帽的情况下,头部区域与安全帽区域未相交,则判断施工人员未佩戴安全帽。 图14 安全帽佩戴检测实验结果Fig.14 Test results of wearing helmet 本文挑选不同环境条件下的样本测试其检测性能,选择小目标、目标尺度差距大、部分遮挡等不佳条件的样本,测试效果如图15 所示。发现本文方法在目标尺度差距大、部分遮挡以及目标模糊的情况下检测效果均表现良好。但是在小目标的情况下,仍存在漏检的情况,本文在后续的研究中会进一步深入探索。 图15 本文方法在不同环境条件下的检测效果Fig.15 Detection effects of method in this paper under different environmental conditions 本文首先采用YOLOv4 网络预训练头部和安全帽的权重;接着利用YCbCr颜色空间对施工人员进行肤色检测,通过头部区域交叉筛选确定头部区域;最后通过安全帽区域与头部区域的位置判定,即可判断安全帽佩戴情况。实验结果表明,本文方法对不同姿态的施工人员安全帽佩戴检测有较好的结果,由于头部区域的圈定,安全帽佩戴的检测精度也要优于以往方法。然而,因为方法使用肤色特征和网络检测互补检测头部区域,所以在人物目标极小的情况下效果不太理想。在以后的研究中将对其进行深入研究,以期提高模型的效果。



1.3 安全帽佩戴判断方法
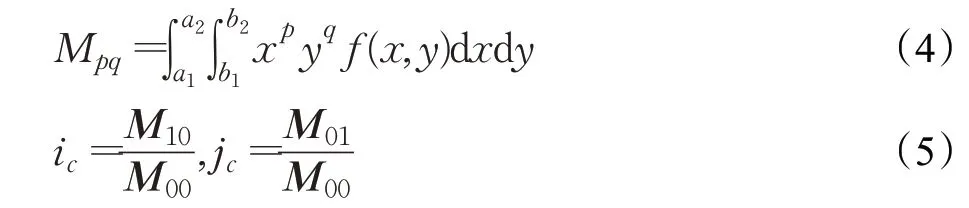
2 数据集

3 实验分析

3.1 目标检测网络效果对比实验


3.2 安全帽检测方法对比实验



3.3 本文方法在不同环境条件下检测效果

4 结束语
