基于领域知识图谱的短文本实体链接
2022-01-22黄金杰赵轩伟张昕尧马敬评史宇奇
黄金杰,赵轩伟,张昕尧,马敬评,史宇奇
哈尔滨理工大学自动化学院,哈尔滨 150080
实体链接是面向短文本与知识相关联的技术手段,分为候选实体的生成和候选实体的消歧[1],旨在将文本中潜在的实体指称映射到知识库中若干候选实体集合,并从候选集合中找到最佳目标实体来赋予实体指称明确的含义[2]。在数据稀疏、缺乏丰富的上下文情况下实体语义歧义性给实体链接带来了难题[3];同时对于某些领域,实体链接结果受到其他实体语义关联影响,这种影响会导致目标对象不是精准的知识信息。所以,短文本实体链接在领域图谱的实现面临了巨大的挑战[4]。
实体链接技术主要需要克服指称检测和知识库实体的消歧两大难题。短文本往往存在语境缺失的特点,使文本特征实体指称表示比较困难,同时由于指称与实体的字符相似而忽略语义实体之间的相似度量,也导致最终链接效果往往不够理想。
当前,对于实现中文文本传统实体链接主要的方法有深度学习法[5]、图模型法[6]等。针对深度学习方法的实体链接的研究,文献[7]提出基于神经网络(DNN)的堆叠去噪自动编码器来学习上下文的向量表达,来计算给定文档与实体描述文本表示的相似性度量。直接计算指称上下文与候选实体描述文本的相似性会因为描述文本较短、不完整或同义词情况导致链接过程出现错误。为了解决此问题,文献[8]提出利用卷积神经网络对指称上下文进行建模,并考虑指称与上下文的语义度量,通过捕捉候选知识库实体信息与指称上下文的关系进行链接。实体链接的结果有时会语义匹配到与指称不相关的实体,模型链接效果不是十分显示。为更好提高指称与实体的相似度,文献[9]利用下文信息和主题信息来消除候选实体歧义问题,并使用在卷积神经网络来捕捉指称上下文与候选实体之间的语义相似度。但上下文信息的不足易影响实体链接的准确性,为此文献[10]提出利用文本指称上下文的维基百科作为外部补充知识源,通过长短时记忆网络扩展指称特征向量表示,以提高候选实体相似度。虽然通过引入第三方知识库作为补充知识源,提高了实体链接的准确率,但该方法仅仅考虑了维基百科的链接关系,忽略了存在于维基百科中的类别关系。在文本内容之外,文献[11]在实体指称表示的基础上研究实体类别层次特征,验证顺序标记指称的识别精度,提高实体链接的整体性能。在文本表层特征的基础上,增加了文本语义信息的获取,从文本中可以抽取实体类型特征,丰富了文本信息。为避免单个特征在特征抽取过程中被过滤掉,导致融合特征不起作用。文献[12]联合指称检测和深度卷积神经网络实现实体消歧,通过融合指称上下文、实体类型、实体描述文本信息等多种语义特征,一定程度上减少了单特征过滤的偶然性,更好地体现了文本的语义性。融合文本多种特征很大程度上依赖于输入短文本,同时只考虑当前实体指称本文,没有考虑文本中实体与上下文的局部语义关系。文献[13]提出增强型字符嵌入神经网络,将指称位置和信息嵌入到模型以提高链接性能。通过预训练增强输入文本字符,预测并学习不同词语之间的关系有效实现了上下文信息的指称表示。基于以上指称表示与实体的相似性度量为获取较好语义实体,使用多特征拼接来增强文本字符语义特征。为此,文献[14]提出多方法融合的候选生成策略,同时在字符嵌入深度神经网络中加入主题语义学习指称、上下文、候选实体的表示,提高了链接候选实体的准确率。
上述研究工作往往仅考虑指称的上下文和实体描述文本信息,忽略了候选实体之间的相互关联,导致相似度量结果出现多个得分相近或相同的候选实体,无法选取最终的目标实体,为此很多研究者在图模型的基础上来探究工作。
针对图模型方法的实体链接的研究,文献[15]提出LINDEN算法构造语义相关图,综合考虑实体对应的维基百科关联和实体间语义相关性,通过指称上下文与实体文档共现统计计算相似程度。研究在构造实体语义相关图时,考量实体之间相关度的程度较低,导致消歧文本很大程度上链接到概念相关实体,造成实体链接准确率下降。文献[16]提出将上下文语义、主题等特征融入图模型的语义相似度度量方法,来实现候选实体的选择。该方法能够抽取实体特征,提高了实体相关性,有效地实现歧义文本的实体链接,具有较高的精度和召回率。引入外部海量公开数据,相比文献[16]的捕捉实体之间特征,提高实体指称链接的精准性。文献[17]考虑实体相似度、流行度、描述文本信息,以中文维基百科作为知识库支撑构造图模型,通过对候选实体进行相似度排序来获取链接实体。该研究充分利用图模型结构信息,抽取多种语义特征,来计算与指称文本的语义相似度。然而这种方法依赖实体所在的百科页面作为知识源,对于领域实体消歧而言,适用性较差,实体链接效果不是十分显著。文献[18]利用候选实体构造图谱知识库,使用PageRank 算法计算知识库中不同候选实体的权重,选取权重最大实体作为链接实体。该方法在实体链接时,只是简单的对候选实体进行等概率平均分配权重,无法得到区分程度较大的链接实体。文献[19]使用重启随机游走算法优化实体之间的转移概率,通过语义推理模型来预测链接实体。但该方法在计算候选实体之间的相关度出现负值,导致得到的语义相关度出现错误,同时方法没有有效利用指称上下文信息,对文本进行消歧。文献[20]提出深度神经网络语义模型来表示文本指称,并通过与语义知识图保持实体一致性,从而在大型知识图上捕捉语义相似候选实体。该方法通过构造语义知识库来丰富实体语义信息,同时关联语义关系相近的实体,考虑了知识库内语义相关实体关系特征。通过文本上下文建模表示指称,实现了指称到实体的精确链接。
以上提出的图模型方法的研究,能够很好地利用图谱知识库中实体之间的语义关联关系,但由于上下文信息的不充足,不能对实体进行丰富的语义表示,很难获取语义相似实体。
基于以上研究方法,本文在实体链接过程语义知识缺乏的情况下,指称会根据不同环境具有多种语义。为此本文利用深度神经网络来挖掘文本中指称及其位置搭配关系,并在预训练中嵌入候选实体描述文本,从而实现基于领域图谱的指称语义表达。为避免关联候选实体对实体链接的影响,经计算指称实体同一向量空间内相似度来获取得分最高候选实体。利用Fast-newman算法将知识图谱中所有实体节点聚类划分为N个聚类子图,定义相似度最高候选实体所在实体簇为候选集合,并为集合下的聚类实体映构建实体关联图。最终构建聚类实体关联图,采用偏向重启随机游走算法获取实体指称节点的平稳分布,通过实体之间关系权重对候选实体进行排序,得出目标链接实体。本文提出的模型有效的将文本指称链接到图谱知识库中无歧义实体上,消除了文本指称歧义问题;同时在链接过程中,为拉大相关候选实体和指称的相似得分,利用图谱知识库中聚类实体来构造具有结构化语义关系的关联图,通过提出的偏向重启随机游走算法提高了实体链接精度。
1 实体消歧表示
在语境缺失和不相关文本的条件下,为实现实体指称在不同的语境中与领域图谱知识库中候选实体的链接,本文提出字符嵌入的实体消歧模型来挖掘短文本实体语义信息进行实体消歧。模型通过指称建模与实体描述建模将指称和所有聚类实体表示连接起来,送入全连接层,再经过线性处理对相似度进行评分,输出得分最大候选实体所在聚类簇。
实体消歧模型输入短文本以及实体描述文本词典,其中实体描述文本词典还有所有实体描述短文本,该短文本由领域指称词Mention与其上下文组成。在模型初始阶段使用BMES序列标记方案,预测文本每一个字符序列位置,每个字符将会分配一个对应的的位置标签。然后通过随机初始化BERT 参数对这些序列进行预训练获取带有位置增强信息的字符向量,并将其传递给Tree-LSTM编码层进行编码。最终,将Tree-LSTM隐藏层的输出提供给带有注意力的CNN网络抽取文本抽象实体特征,并固定实体指称向量大小,从而对指称和实体进行表示。另外在实体指称与候选实体链接的过程中,由于候选实体集合缺少背景语料知识,实体指称难以区分概念相似同时关联度相近的候选实体。在实体建模部分使用Fast-newman 算法对领域实体进行聚类,划分为不同类别的实体簇。在同一实体簇中通过指称与实体的一致性得到相似度指标,并选取评分最大实体簇来进行候选目标实体的选取。实体消歧模型如图1所示。
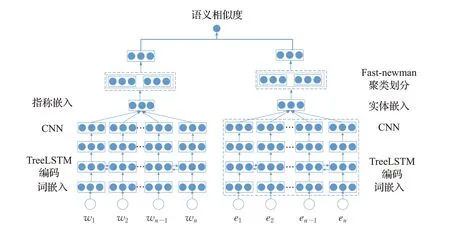
图1 实体消歧模型Fig.1 Entity disambiguation model
1.1 词嵌入
加载实体词典并使用jieba分词工具将中文短文本进行分割,进而实现文本序列中实体指称的完整分割,随后使用词向量模型来对单词序列进行词向量表达。传统方法中一般使用word2vec对单词序列进行训练来获得单词向量,但在缺乏上下文背景知识的情况下word2vec无法表示同一单词的不同语义,给下游实体指称链接的实现带来偏差。
随后Bert 主要使用Transformer 作为核心结构,其框架具体如图2 所示。Transformer 完全使用自注意力机制来训练词向量,并通过自注意力计算出每一个词与所有词之间的关系,由此得出该词在句子中的权重。通过这样得到的词向量能够有效利用上下文信息,增强了文本语义知识信息。
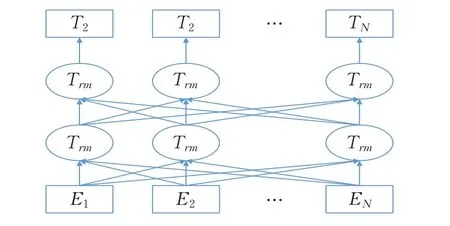
图2 Bert预训练模型结构Fig.2 Pretraining model structure of Bert
为了训练词表示向量,在预训练过程中,Bert 使用掩码[mask]替换文本中部分单词,让Transformer编码器根据上下文来预测这些单词。随机遮住15%的单词作为训练样本,并将其中80%单词用掩码代替,10%单词替换为随机单词,另外10%单词不变。通过Transformer编码器不断进行预测,Bert预训练模型可充分利用词级上下文信息,获得了文本中每个单词的表示向量。
1.2 TreeLSTM编码
为了学习文本深层语义,将位置信息增强的词向量输入到TreeLSTM。随着时间的增加,文本中单词顺序进入网络中,进行线性拼接,由此完成对上下文信息的编码表示。模型利用树形结构学习长距离节点中的语义搭配关系,根据分支结构追踪方向传播,线性表示节点隐层输出。如图3所示,在“心脏病的治愈患者”的语句中,通过对“心脏病”进行语义增强,这个单词比其他单词与上下文的关联度更高。
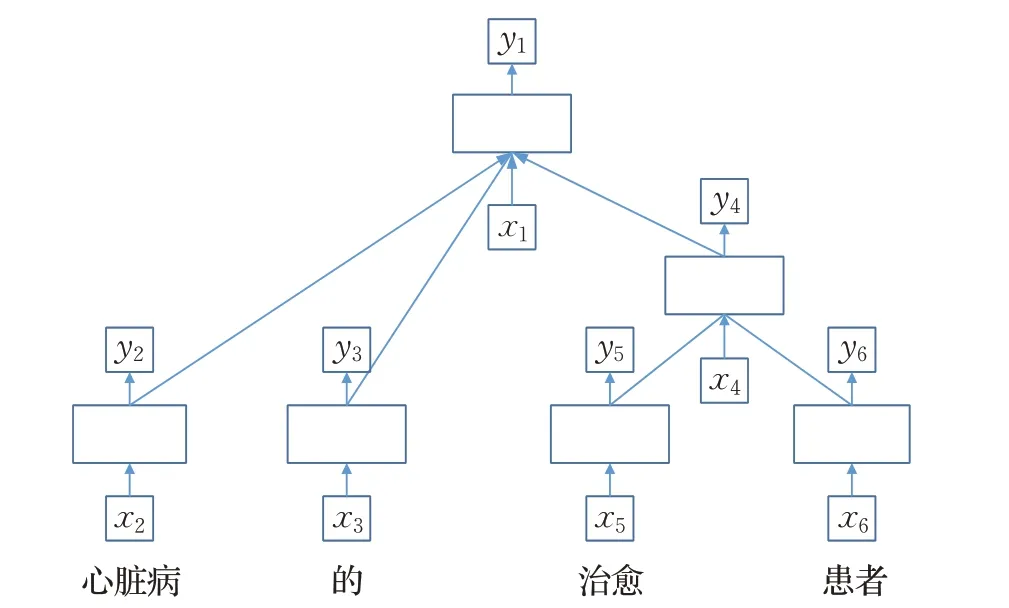
图3 TreeLSTM网络结构Fig.3 Network structure of TreeLSTM
对树网络中的每个节点生成隐向量,x是文本的输入序列,经过LSTM 预测输出y。在多层二叉树部分,xi表示树型结构中每个节点i对应单词的语义向量,当前xi输入是子节点传入父节点y的隐含值。TreeLSTM的计算流程如图4所示。
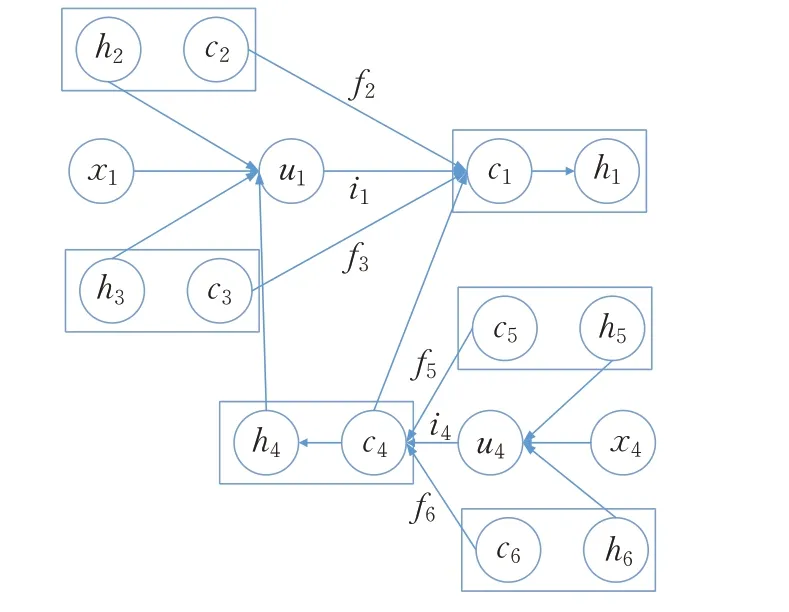
图4 TreeLSTM计算流程图Fig.4 Calculation flowchart of TreeLSTM
在网络中记忆模块由输入门、输出们和多个遗忘门组成,在反向传播过程中通过不断计算门传递来进行权重参数的更新。其中对于节点j、r为节点i的子集合,hkr表示LSTM 的隐藏层,σ为sigmoid 激活函数,⊙表示向量元素依次相乘,b为偏置向量,W和U为权重矩阵,tanh为激活函数。
在每一个模块单元中利用输入门ij将当前词xj信息融入到记忆细胞cj中来控制当前信息的加入,判断当前词xj对全局文本的重要性:
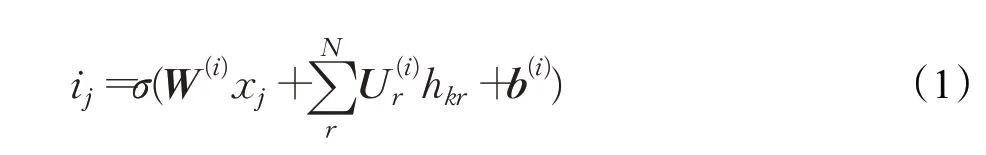
TreeLSTM拥有多个遗忘门fj,分别对应当前单元下不同子单元k,由此网络可以从子节点中选择性的获取语义更加丰富的实体节点信息。遗忘门fj通过将不同时刻下细胞状态ckr融入到记忆细胞cj,来判断所有时刻单元状态对当前时刻的记忆程度:
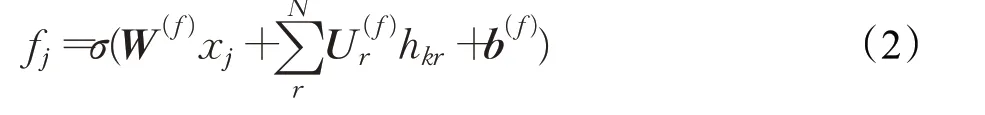
再通过tanh 层产生候选记忆细胞状态uj,为后续细胞状态cj传递记忆候选信息,决定记忆文本中重要信息:
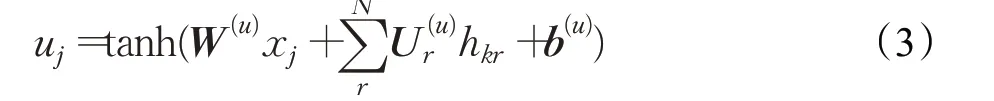
有了遗忘门产生的控制信号ft,候选细胞状态uj,输入控制信号ij,从而利用所有时刻下记忆细胞状态来更新当前时刻细胞状态cj:

利用激活函数处理细胞状态,并与输出相乘得到隐含层的表示:

TreeLSTM为了捕捉远距离实体信息实现实体的精准表示,通过对文本中不同位置信息分配权重,从而去除不相关信息的影响。设TreeLSTM 产生短文本的隐藏向量为H=(h1,h2,…,hN),N为序列长度,重新分配第i个隐藏向量权重为α:

1.3 Fast-newman聚类划分
Newman针对网络社区结构提出了复杂网络分裂的凝聚Fast-newman 算法[21]。在本文中选择Fast-newman算法将领域图谱知识库中的实体进行Fast-newman聚类划分,得到不同类别实体簇,从而缩小链接候选实体的选择范围,有效区分实体类型。开始将领域图谱知识库初始划分为n个实体簇(n为实体节点数目),即每一个实体节点可看作一个独立的实体簇。各实体节点之间链接边的总数为m,其对称矩阵E=(eij)表示为:


其中ki表示实体节点i边数,ai表示与实体节点i相连边的数量占知识库中所有边的比重。
将图谱数据库聚类划分成实体簇,每个实体簇由实体节点组成,为保证实体簇中实体节点相互连接密切,同时实体簇之间连接稀疏。Newman在文献[21]中引入模块度Q值,表示图谱知识库划分后,实体簇之间的连接数目与实体簇内部的连接数目的比例,由此来衡量实体簇的划分质量。模块度Q的计算公式如式所示:
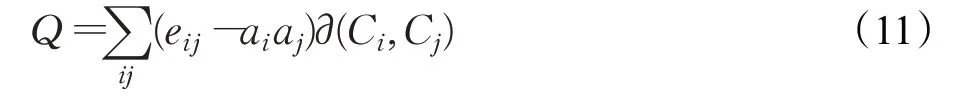
其中Ci为实体节点所属的实体簇,当Ci=Cj时,∂(Ci,Cj)=1,否则为0,Q值范围为[0,1],Q值越大实体簇聚类效果越好。
初始将每个实体节点看作一个实体簇,通过迭代过程不断合并实体簇,使Q的函数值最大化。计算合并实体簇所导致的Q值增量ΔQ,使实体簇沿着ΔQ值增大的方向进行更新,直到整个网络合并划分为一个实体簇[22]。最后通过选取局部最大Q值,获得最好的实体聚类簇结构:

在迭代过程中,随机选择两个实体簇进行合并,选取使ΔQ值最大的两个实体簇归于同一实体簇,直到实体簇都合并完毕,这种方式大大减小了网络聚类的复杂程度。
1.4 语义相似特征
通过将给定短文本和候选实体描述文本分别作为模型输入来获取候选实体向量表示rm和re,再分别计算指称表示向量rm与候选实体向量re之间的相似度,并对比实体指称与候选实体语义特征表示的相似性。
在实体消歧模型中,通过BERT预训练将位置特征加入到字符序列中,以增强文本中的实体信息,并传递到TreeLSTM-CNN中,输出具备语义关系的文本隐含状态序列H,使用指称隐藏序列状态C来生成指称表示rm。将池化层和注意力机制作用在序列隐藏状态上的结果hpool和hattention,分别连接到指称隐藏序列状态上,生成指称隐藏状态表示G:

其中q为指称序列隐藏状态的头位置数,r为称序列隐藏状态总个数。
最后使用全连接层将指称隐藏状态表示G输出为最终指称表示rm。

在实体表示的生成上,将隐含状态序列输入到注意力机制的CNN 网络来发现文本中实体字符特征,并连接全连接层,输出实体表示re。
计算实体表示re的注意得分αej为:

其中hj表示j时刻的隐含隐含状态。
经过训练得到隐藏状态hj的权重αej为:

其中n为总序列数。
最后通过加权输出实体向量表示re,其中re与rm的向量维度大小相同:

利用实体指称与实体表示,对实体表示之间的相似度进行测评并排序得分。衡量实体之间相似特征得分w(rm,re)计算如下。

从公式可以看出,候选实体越接近真实实体指称语义表达,则评分越高。
2 候选实体的选择
聚类算法对候选实体划分为不同类型实体簇,利用式(20)计算指称与知识库中所有实体的相似程度,选取相似度得分最大实体的所在实体簇作为候选实体集合。
所谓目标实体是指能够区分候选实体中概念相关实体,并有效扩大聚类候选实体到指称的相似距离,防止相似度量结果出现多个得分相近或相同的情况,从而精确链接到最高语义关联实体。
为更好地关联聚类实体,构建聚类实体关联图,根据聚类候选实体关联图,采用偏向重启随机游走算法不断进行概率转移。通过算法反复迭代,概率趋于收敛,得出平稳概率分布矩阵,由此得到指称到候选实体的概率得分,并选取得分最高候选实体作为实体链接目标实体。若得分低于阈值,则返回NIL。具体过程流图如图5所示。
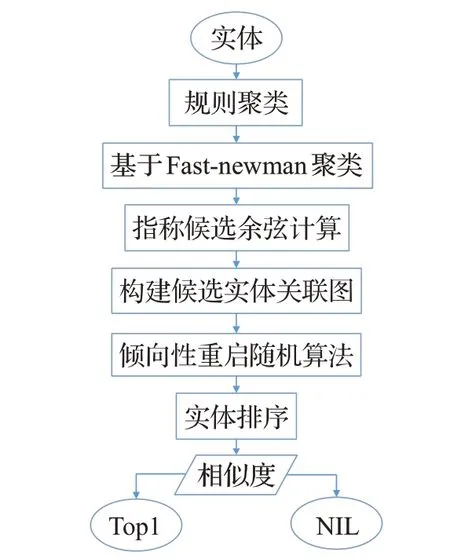
图5 候选实体输出流程图Fig.5 Flowchart of candidate entity output
2.1 关联图的构建
知识图谱中任意两个实体节点之间存在关系,将会拉近实体之间距离,进而提高实体节点的语义关联。定义与实体节点i连接边的数目为实体节点的度,度包含入度分布和出度分布,随机选取实体簇中任意实体节点,计算度分布矩阵。
实体相关特征反映实体集合之间的相关度,本文通过与实体节点连接的关系边及实体间共现得分,来统计聚类实体的关联程度。在已存在关系知识的基础上,仅依靠聚类实体的显性关系,远不能反映实体关联特征,为此使用关系补全的方法,补全聚类实体的隐性关系。由此构造聚类实体关联图如图6所示。
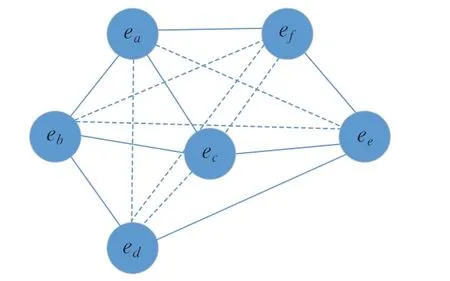
图6 聚类实体关联图Fig.6 Association graph of cluster entity
在关联图中先计算实体度分布ki,其中各节点的度值分别为ka=kb=kc=ke=3,kd=kf=2,赘去度值小于1的实体节点。网络节点邻接矩阵A的表示如下所示:

根据显性连接信息预测未连接实体间关联性,即ea/ed,ea/ee,eb/ee,eb/ef,ec/ed,ec/ef,ed/ef产生隐性关联边的可能性大小。针对无连接边的情况,如果出现两个实体与同一个实体相连接,则两个实体存在语义联系;如果两实体节点不存在实体关系,则自动补全实体间的关系连线。
综上,关联图中候选实体的相关度如式所示:

其中,Ea与Eb分别表示与实体节点a、b存在关系的所有实体节点,|Ea|表示与节点a存在关系的实体集合数目,|Eb|表示与节点b存在关系的实体集合数目,E表示所有实体节点集合。
基于关联图中聚类实体的语义相关性,另外使用openKG公开网络[23],搜索该关联图中聚类实体。将任意聚类实体及其搜索到的相关实体,组合成实体词语条目集合t,Occur(e)代表任意聚类候选实体出现的代表集合。

候选实体间的语义相关度计算如式所示:
其中Occur(ei)∩Occur(ej)为两聚类候选实体同现候选代表集合,Occur(ei)∪Occur(ej)为所有聚类候选代表集合。
根据上述两种实体相关性表达式,得出聚类实体相关性线性组合如式所示:

其中α和β为超参数。
本文引入关联性特征可以大大减少链接过程中关联实体的干扰,有效区分概念相近的候选实体,增大相近候选实体得分距离,提高了实体链接的准确性。
2.2 偏向重启随机游走
解决相似得分最高实体与其他聚类实体的关联性影响,本文将指称实体相似特征、候选实体间语义相关特征融入到聚类实体关联图,实现特征融合的偏向性随机游走算法,从而获取指称链接目标实体。利用1.1 节实体词典及jieba 分词方法分割出的字符串指称,计算算法中任意两实体间的转移概率。算法最终通过迭代过程,得到指称到候选实体的平稳概率分布,并由排序学习得出概率排序结果。算法的特点是根据关联图中实体特征,进行不同概率转移,实现倾向性随机游走。算法迭代过程既考虑到指称相似,又顾及实体关联性,从而精确获取目标实体。实验算法如下所示:
算法偏向随机算法游走

从当前网络关联图中初始节点出发,并以∂的概率游走到下一个节点,或以1-∂返回初始状态,此时节点的状态与周围邻居节点的度k有关。通过邻居节点的度比例大小,预测实体节点的重要程度,并以转移概率w偏向其比例最大的邻居节点,重复上述流程达到平稳分布。算法替换任意两个实体节点间均匀等概率转移,通过指称实体相似度w(rm,rei),以及候选实体的语义相关度Entity(ei,ej),构造线性组合来计算算法转移概率。
指称到实体转移概率wme如式所示:
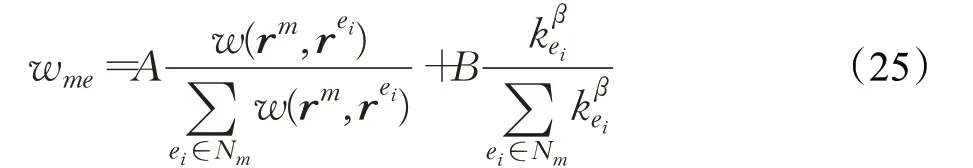
其中Nm表示与指称节点相连接的所有候选实体节点的集合,Ne表示与候选实体相邻的指称节点和其他候选实体节点的集合,ei表示任意实体,kβ ei表示任意实体节点的度调节参数,A、B为超参数。
实体到指称转移概率wem如式所示:

其中E、F为超参数。
实验过程收敛后,根据实体指称到每个候选实体的转移概率大小,考查了候选实体的链接性能强弱。在t+1 时刻,节点转移到实体关联图中其他节点的概率计算如式所示:

其中使用T表示关联图的节点转移概率矩阵,rt表示第t时刻概率分布情况,∂为概率参数,1-∂代表重启随机概率,s为初始状态向量。
当随机过程收敛即函数rt+1 ≈rt时,趋于稳态,得到稳态时刻的解如式所示:

此时根据指称指向候选实体的概率分数,选定目标候选实体:

其中r(e)表示平稳概率分布中指向候选实体e的分值。
3 实验研究
3.1 实验数据集及处理
本文实验采用的数据包括领域图谱数据集和短文本语料数据集。领域图谱数据来源于openKG 发布的OMAHA 七巧板医学术语集。该医学领域知识库由实体、关系和属性组成,抽取数据中5 200个疾病类型作为领域图谱的实体,关系数量为6 500个,每个实体都含有其疾病概念的描述文本。为便于领域图谱实体的可视化,将.xml 格式数据映射到neo4j 图形知识库中。实体领域数据图谱如图7 所示。通过Fastnewman 聚类对知识库中候选实体进行划分,得到每一个实体的类别属性如表1 所示。其中userID、diseaseID 为实体索引,label为实体标签,disease_types 为领域实体标签名称,rating表示关联度。

图7 可视化知识库Fig.7 Visual knowledge base

表1 聚类实体知识库Table 1 Cluster entity knowledge base
根据CCKS2019&医渡云[24]公开的病历结构化Yidu-S4K数据集,采集领域疾病相关数据共8 000条(平均字符长度为30),并以比例7∶3 分别作为实体消歧模型的训练集和测试集。为了解决中文短文本链接中的指称语义模糊的问题,使用深度神经网络模型进行指称表示。再经过特征关联图模型减小实体关联性影响,使指称表示准确链接到本地领域图谱最佳目标实体对象上。
在实验训练前加载候选实体jieba 词典,使用
3.2 实体链接准确性对比
抽取测试集合中500句短文本,分别进行实体链接实验。为验证本文模型相似度特征的有效性,进行4种模型的的实验。模型1(BiLSTM+CNN)为文献[13]使用联合优化BERT-ENE 的深度神经网络模型(BiLSTM+CNN)计算指称与候选实体之间的相似度;模型2(TreeLSTM+CNN)构建字符嵌入的BERT 深度神经网络训练指称表示,并计算指称相似度;模型3(聚类实体+TreeLSTM+CNN)通过Fast-newman 聚类算法构建候选实体簇,并结合实体消歧模型计算指称相似度;模型4(聚类实体关联图+TreeLSTM+CNN)在实验3 的基础上进一步融合候选实体语义相关特征并构建实体关联图,计算指称相似度。4种模型的的实体链接效果如表2所示。

表2 实体链接平均准确率对比Table 2 Average accuracy comparison of entity link
对于相同测试集,模型2的实体平均链接准确率比模型1 高0.3%,实验表明使用TreeLSTM 网络在抽取实体指称特征方面性能更好,这是由于在不同背景知识下网络更容易对单词之间的语义关系搭配进行学习,能够更好地捕捉单词的语义信息。相比较模型1 而言,在BiLSTM 的方法中,词向量序列的计算量不断加大,还由于缺乏指称与上下文的关系导致实体指称的歧义性。模型2采用TreeLSTM将隐藏序列表示扩展在树结构中,使用忘记门机制省略无关子树。通过捕捉实体指称与文本中其他单词的关系来增强位置信息,获取有用的实体语义信息。
与模型2 的结果相比,模型3 实体链接准确率提高了3.23个百分点,指称向量表示与模型2得分最高实体所属实体簇进行相似度计算。结果说明引入Fast-newman 聚类实体关联图,可进一步缩小实体链接范围,并提高实体链接准确率。
与其他3 种模型相比,本文提出的模型4 的实体链接平均准确率是最高的,到达了83.98%。在模型4 中,特征关联图结合了实体局部相关性与指称全局相似性特征,有效解决缺少上下文背景下短文本数据中指称表示及实体关联导致链接不一致的影响,为实验模型实体消歧及实体选择的结果减小了误差。
3.3 参数设置
在候选实体链接实验过程,实验参数设置分为神经网络模型参数设置与关联图参数设置。
在实体消歧模型中,使用Adam 优化器对模型进行优化,设置学习率为0.01,批量大小为120,训练次数epoch 为32 个样本,定义文本最大长度为40,层的数目layers 默认为1,初始词嵌入向量的维度为300,指称与上下文窗口长度设置为10,并将描述文本与指称的窗口设置为20。
根据聚类实体关联性,使用实体逻辑边距离及实体共现相关距离相组合表示聚类实体相关特征。相关性特征公式(24)包括α、β两个参数,不断增大参数α值通过实验训练结果选择最优参数,参数训练结果如图8所示。观察训练结果当α=0.52 时,实体间的关联程度最大,实体间相关度达到最优值。
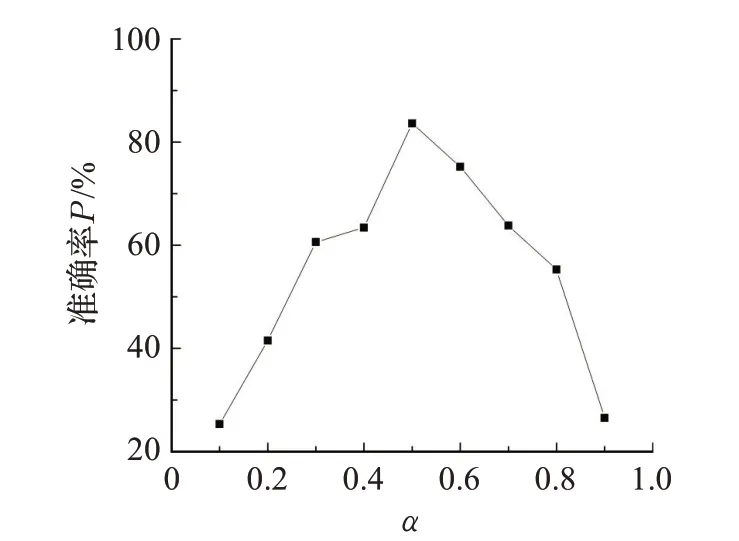
图8 实体相关度参数设置Fig.8 Parameter setting of entity relevancy
通过聚类实体关联图随机节点间的转移概率式(25)、(26)和式(27),选取最优参数A、C、E,分别获取最大转移概率wme、wem、wij,根据参数变化测量概率变化大小,具体情况如图9所示。

图9 关联图转移概率参数设置Fig.9 Transfer probability parameter setting of correlation graph
根据折线曲线变化选取A=0.40 ,同理选取C=0.50,E=0.52。关联图综合指称相似及实体相关特征,考虑实体语义信息,通过偏向重启随机算法,最大概率使实体指称节点倾向于相似最高候选实体,大大提高了目标实体的预测精准度。
3.4 评价方法
为判别实体链接的最终效果,实验指标从精确率P、召回率R、调和平均值F1 三方面评判最终实体链接的有效性。利用测量数据,对基于特征关联图的实体消歧模型进行训练,链接候选实体。若实体指称在图谱知识库中不存在候选实体,则链接结果定义为NIL。使用Tnil表示在图谱知识库中链接到NIL的指称集合;使用Treal表示在图谱知识库中链接到候选实体的指称集合。另一方面,使用人工的方法根据测量数据在图谱知识库中对实体指称进行实体链接,以Snil表示人工链接到NIL的实体指称集合;以Sreal表示人工链接到图谱知识库候选实体的指称集合。
分别统计系统与人工链接知识库候选实体的数目,进而计算指称链接到图谱知识库中实体的精确率Preal、召回率Rreal。

其中Treal∩Sreal表示预测结果与实际实体相一致的实体指称集合,Snil∪Sreal表示为实际链接到图谱知识库的实体指称集合。
根据精确率Preal和召回率Rreal,计算指称链接结果为实体的调和平均值Freal为:

另外针对链接结果为NIL,计算准确率Pnil、召回率Rnil:

其中Tnil∩Snil表示预测结果判定为实际NIL 的实体指称集合。
根据准确率Pnil和召回率Rnil,计算指称链接为NIL的调和平均值Fnil为:

综上,根据调和平均值衡量系统综合效果,如果精确率越高,系统链接到实际候选实体的准确率就越高;如果系统遗失实际候选实体的数目越少,系统召回率越高。
3.5 实验结果及分析
为验证实体链接的最终效果,设计基于聚类实体关联图的实体语义消歧实验。文献[13]在不考虑候选实体相关度的情况下使用长短时记忆网络来实现实体链接。文献[10]在实体链接中使用带有双重注意力机制的长短时记忆网络来完成指称实体与实体的语义表示,并构建最新本地知识库,获取指称到实体的链接。文献[25]考虑实体稠密及稀疏性定义无向候选实体相关连接图,通过提出的MINTREE对实体指称和候选实体形成最小生成树的语义距离权值,并用生成树的权值来度量链接候选实体的匹配程度。通过上述实验并于本文方法实验进行对比,得到的最终性能指标如表3 所示。实验对比显示本文提出的模型在准确率、召回率、F1 值都高于其他3种模型实验结果。
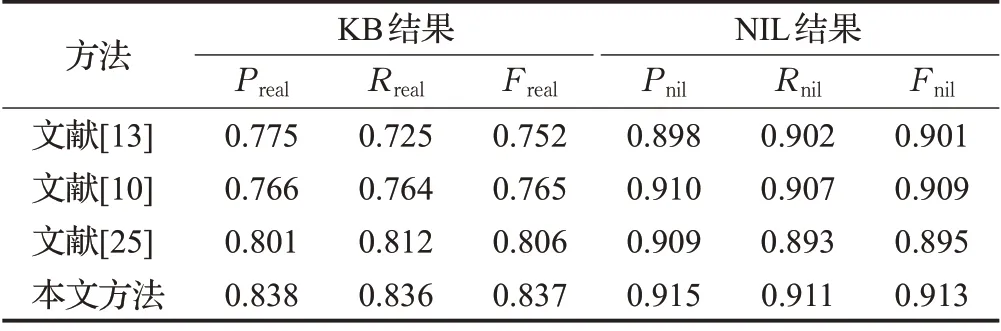
表3 模型实验结果对比Table 3 Comparison of model experimental results%
实验说明首先在指称与候选实体相似度特征表示上,与文献[13]相比较,本文中位置信息增强的TreeLSTM+CNN能够更好地捕捉实体信息并实现指称与候选实体的语义关联表示。与文献[10]相比,本文使用聚类算法考虑候选实体的类别特征,在引入候选实体关联性的条件下,构建实体关联图,结合实体消歧模型完成实体指称与候选实体的链接。与文献[25]相比较,本文提出的模型链接效果在验证集下,F指标值上提高了3.1个百分点。在实体链接上,本文采用偏向重启随机游走算法实现基于聚类实体关联图的实体语义消歧。在随机转移过程中实体指称自动倾向最大相关实体,通过计算图网络中各实体的平稳概率分布提高实体链接匹配程度。综上比较,实验结果验证本文提出的方法具有可行性,能够有效提高实体链接性能。
4 结束语
为解决实体链接问题,本文提出了深度神经网络与关联图相结合的实体链接模型。首先对短文本中的实体进行指称表示,捕捉实体指称与实体间的语义相似特征。然后利用Fast-newman 聚类算法对图谱知识库中的实体进行划分,通过相似度计算获得候选实体集合并在同一空间下构造实体相关特性的实体关联图,减小了候选实体相关性对链接的影响。最后,采用偏向转移随机游走算法,实现实体指称的精准链接。实验表明该模型能够有效减小关联性对目标实体链接的影响,从而提高实体链接的性能。
