强化学习在车辆路径问题中的研究综述
2022-01-22牛鹏飞王晓峰张九龙
牛鹏飞,王晓峰,2,芦 磊,张九龙
1.北方民族大学计算机科学与工程学院,银川 750021
2.北方民族大学图像图形智能处理国家民委重点实验室,银川 750021
随着经济社会快速发展及交通基础设施的不断完善,城市物流业是当今社会关注的一个重要话题。2020年全国快递业务量突破750亿件,随着构建新发展格局的加快,未来我国快递业务量仍会保持较快的增长。物流业的快速发展使得对超大型物流系统的快速调度提出了更高的要求。车辆路径问题(vehicle routing problem,VRP)是在车辆数一定的条件下,尽量缩短车辆行驶距离,找到一组总成本最小的路线。同时,根据优化目标不同,可以加入不同约束从而满足不同种类问题的实际需求。
车辆路径问题作为一个众所周知的组合优化问题,最早由Dantzig和Ramser[1]于1959年作为卡车调度问题提出的,并被Lenstra 和Kan[2]证明是NP-难问题。经典的车辆路径问题被定义为:有一个仓库(depot)节点和若干个客户(customers)节点,已知各个节点在二维空间上的位置和客户的需求,在满足约束条件下,使得车辆从仓库节点出发访问客户节点,满足客户需求,最后返回仓库。在不考虑负载的情况下,VRP等价于旅行商问题,应用到现实生活中,研究较多的是有容量约束的车辆路径问题(capacitated vehicle routing problem,CVRP)[3]。当客户的需求不定时,产生了随机车辆路径问题(stochastic vehicle routing problem,SVRP)[4];当客户对需求提出时间要求时,产生了带时间窗的车辆路径问题(capacitated vehicle routing problem with time windows,CVRPW)[5];针对客户当日要求交付的需求,产生了当日交付的车辆路径问题(same-day delivery problem with vehicle routing problems,SDDVRP)[6]。关于VRP的详细描述见文献[7]。
多年来大量国内外学者致力于VRP 的研究,目前求解VRP的主要方法分为常规算法和基于强化学习的算法,其中常规算法包括精确算法、启发式算法等。基于强化学习的算法主要包括基于马尔科夫决策过程的强化学习和近年来方兴未艾的深度强化学习。
本文将首先简略概述基于常规算法求解VRP的各类算法,再对基于强化学习求解VRP 的各类模型进行详细的介绍。
1 基于常规方法求解VRP技术
目前求解VRP 的常规算法包括精确算法、启发式算法和元启发式算法。
(1)精确算法主要包括线性规划法[8]、分支限界法[9]等。这类算法适用于VRP规模较小、结构简单的情况,当VRP 中有较多约束条件时,精确算法无法在有效时间内得到问题的最优解。
(2)启发式算法主要包括节约法[10]、线性节约法[11]和插入检测法[12]等。这类算法适用于规模较大的VRP,面对CVRP、CVRPW 等这些有较多约束条件的VRP 变种问题时,该类算法仍较为快速求解,具有求解效率高、占用内存少的优势,因为该类算法改进目标一直是求解速度,因而问题规模增大时无法得到最优解。
(3)元启发式算法主要包括模拟退火算法[13]、禁忌搜索算法[14]、基于群思想的算法[15-18]等。这类算法具有求解速度快、效率高的特点。但这类算法在求解VRP时容易陷入局部最优而无法得到全局最优解,以及不容易收敛等问题。
表1 对上述求解VRP 的各类常规算法的缺点进行了对比。
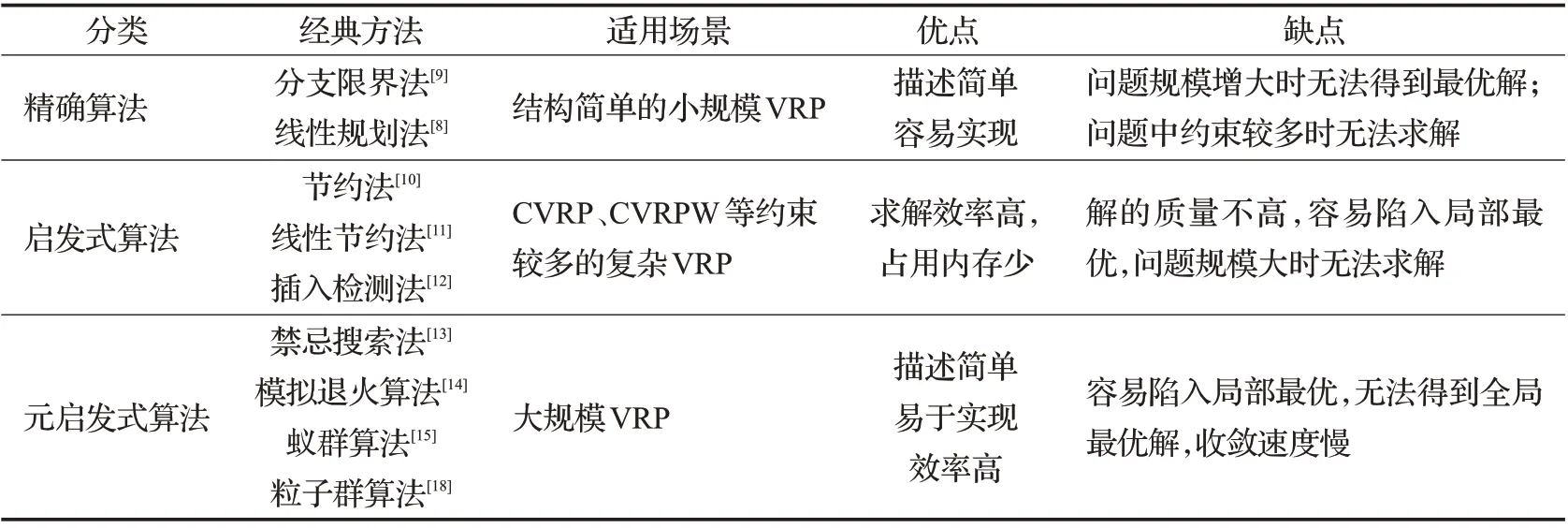
表1 求解车辆路径问题的常规方法优缺点对比Table.1 Comparison of advantages and disadvantages of conventional approaches applied to VRP
2 强化学习概述
2.1 强化学习基础
强化学习(reinforce learning,RL)是人工智能的一个重要分支,它不需要监督信号来进行学习,而是依赖个体(agent)在环境(environment)中的反馈回报信号,依据反馈回报信号对个体的状态和行动进行更正,使得个体逐步实现奖励(Reward)的最大化,从而使得强化学习具有较强的自主学习能力。强化学习的描述如图1所示。

图1 强化学习示意图Fig.1 Schematic diagram of reinforce learning
2.2 强化学习算法分类
对强化学习算法的分类可以根据有无模型分为基于模型(model-based)和无模型(model-free)的学习算法。在求解VRP中常见的基于模型的学习方法有动态规划法;无模型的学习算法主要有基于价值的时序差分算法[18]、Q-learning 算法[19]、DQN 算法[20]等;基于策略的REINFORC算法[21],价值和策略相结合的Actor-Critic算法[22]、Advantage Actor-Critic 算法等。如图2 总结了一些已经应用到VRP求解中的经典强化学习算法。

图2 强化学习算法分类图Fig.2 Classification diagram of reinforcement learning algorithm
3 基于模型的算法
在强化学习中“模型”指环境,基于模型的强化学习算法意为通过预先给定或通过学习的方式得到MDP模型。最典型的给定环境模型方法是打败围棋冠军柯洁的阿尔法狗算法,通过学习的环境模型方法有world models 算法[23]。在VRP 求解中运用最多的基于模型的强化学习算法为动态规划算法,及由动态规划算法衍生出来的近似动态规划算法和深度神经网络动态规划算法。基于模型的算法通过MDP模型预测以后可能的状态S和动作A,从而对个体行动提供指导,但在现实生活中环境模型可能很复杂以至于难以建模。
3.1 动态规划算法
动态规划算法是由美国数学家Bellman在研究多阶段决策过程的优化问题时提出的,“动态规划”一词中“动态”意为问题是可以通过一个个子问题去求解,“规划”意为优化策略。在给定一个用马尔科夫决策过程描述的完备环境模型下,其可以计算最优的模型。在强化学习中,动态规划算法的目的是使用价值函数求解最优策略,常规的动态规划算法因“维数灾难”无法有效的求解强化学习问题,但后续其他的方法都是对动态规划算法的改进和近似。运用动态规划算法求解强化学习问题就是求解给定策略π时对应的价值V*(S) 。价值V*(S)表示为:

公式表示k+1 轮的价值Vk+1(s)可由前k轮的Vk(S)出来,策略π(a|s)为给定状态s时选择动作a的概率,Ras为给定状态s时选择动作a的奖励,γ为折扣率,为下一步状态的概率乘以价值函数之和。
3.1.1 基于近似动态规划的方法
Secomandi 等人[24]将首次神经网络近似动态规划(network approximate dynamic programming,NDP)方法应用到求解带有随机需求的VRP 中,NDP 是在动态规划中使用神经网络对策略进行近似的新模型,实验结果表明在有随机需求的VRP中,基于rollot策略的NDP算法的性能要优于近似策略迭代的NDP 算法。Tatarakis和Minis[25]对随机需求下有仓库补货的单车辆路径问题(stochastic vehicle routing with depot returns problem,SVRDRP)进行了研究,通过对交付产品的划分,提出了一种近似动态规划算法从而在合理的时间内可得到最优策略。
针对运输和物流中出现的随机优化问题,Powell等人[26]在2012年提出了一个完整的研究框架,其中对近似动态规划(ADP)算法在动态VRP的应用做了细致的说明。Çimen和Soysal[27]将VRP的优化目标从成本最小化更改为排放最小化,从而给出了绿色带时间窗有容量约束的随机车辆路径问题(green stochastic time-dependent capacitated vehicle routing problem,GSTDCVRP)的MDP模型和基于近似动态规划的启发式算法。
Ulmer等人[28]利用近似动态规划的方法对价值函数进行近似,从而提出了有求解随机服务请求的车辆路径问题(vehicle routing problem with stochastic service requests,VRPSSR)的ATB算法。为降低VRP中因客户的随机需求带来的高额计算,Ulmer 等人[29]针对随机服务请求的单车辆路径问题(single-vehicle routing problem with stochastic service requests,SVRPSSR),将客户请求服务的时间以及客户自身的空间位置纳入近似动态规划中,从而生成动态的路线策略。
为降低由交通拥堵引起的成本,Kok 等人[30]针对CVRPW,在近似动态规划算法中加入了避免交通拥堵的策略,结果表明该方法能够有效降低通勤中拥堵时长。Secomandi等人[31]针对只有一辆车的随机需求车辆路径问题(SDVRP),通过有限阶段的MDP进行建模,使用部分再优化(partial reoptimization)的方法对SDVRP进行研究,并通过PH、SH两种启发式算法选择MDP的状态子集,以此来计算最优策略。Goodson 等人[32]提出了基于rollot 策略的近似动态规划框架,并将该框架应用于求解具有随机需求和持续时间限制的多车辆路径问题(vehicle routing problem with stochastic demand and duration limits,VRPSDL)。
3.1.2 基于深度动态规划的方法
Kool 等人[33]提出了结合学习神经启发式和动态规划的深度策略动态规划对VRP 进行求解,模型根据图神经网络(graph neural network,GNN)得到的每个客户顶点特征向量,通过注意力机制计算每个客户顶点被选中的概率,并将这个概率作为动态规划算法对部分解进行选择的策略,最后根据此策略构造最优解。
3.1.3 基于动态规划的方法总结
常规方法通常只能求解静态确定性问题,难以求解带有动态和随机信息的问题。动态规划算法可有效求解静态车辆路径问题和动态车辆路径问题,具有求解范围较广的优势。求解车辆路径问题时,需首先建立MDP模型,设计算法求解该模型,并用rollout策略在启发式算法基础上得到最优值函数,但动态规划算法无法解决客户节点规模大的车辆路径问题。因此,学者们设计出近似动态规划算法,利用神经网络的泛化能力,通过价值函数近似或策略函数近似得到奖励函数,从而不用直接求解贝尔曼方程,解决了动态规划算法带来的“维数灾难”问题。学者们的改进方向主要是近似动态规划算法中神经网络的结构,其主要区别是针对不同车辆路径问题中的各类相关信息进行编码作为神经网络的输入信息,输入的信息越丰富,奖励函数的近似精度就越高,进而近似动态规划算法的优化效果越好。其次是对rollout策略的改进,以减少模型的计算成本和计算量。
相较于传统运筹学有建模不准确的问题,以近似动态规划算法为代表的基于模型的强化学习算法,可以通过智能体与环境不断交互学习到最优策略。在动态车辆路径问题中动态规划算法可以在于环境交互的过程中不断加入获取的随机信息。基于以上优点使有模型强化学习算法适合求解具有动态结构和随机信息的车辆路径问题。
3.1.4 动态规划算法局限性分析
动态规划算法在车辆路径问题等领域中应用较广。但也存在许多问题,比如维数灾难、系统不可知、实时求解效率低、近似动态规划算法虽能有效避免上述问题但也因采用神经网络,其鲁棒性较差。分析原因如下:
(1)维数灾难
现实生活中的车辆路径问题规模较大,以至于通过MDP 建模以后动作空间和状态空间过大,导致动态规划算法失效。因而动态规划算法在求解大规模车辆路径时性能较差。
(2)系统不可知
动态规划算法可求解静态的车辆路径问题和动态的车辆路径问题但需对问题先建模,但实际场景中的车辆路径问题因系统的状态转移函数未知,从而无法对问题进行建模,或对问题进行过理想化处理,使得动态规划算法应用受限。
(3)实时求解效率低
当下车辆路径问题求解的实时性要求不断提高,即需要在较短的时间内给出问题的解,动态规划算法虽能给出问题的最优解,但耗费的时间较长且求解的效率较低。通过神经网络计算的近似动态规划算法虽能比动态规划算法求解算法快,但因当前计算机的性能,算法实时求解能力仍有待提高。
(4)鲁棒性差
目前改进的动态规划算法均是采用神经网络结构,且使用自举采样的方式获取数据,数据的关联性较高,算法的鲁棒性较差,且算法的抗扰动能力较弱。使得近似动态算法在实际生活中的车辆路径问题应用有限。
3.1.5 基于动态规划求解VRP分析对比
表2 将上述基于动态规划求解VRP 的各类模型的训练方法、求解问题、以及优化效果进行了对比。

表2 基于动态规划求解车辆路径问题的方法对比Table 2 Comparison of approaches of dynamic programming applied to VRP
4 无模型的算法
无模型的强化学习算法是指MDP模型中的环境参数未知,即在给定状态条件下个体采取动作以后,未来的状态和奖励值未知。因此,个体不对问题进行建模,而是先和环境进行交互,在不断试错中寻找最优策略。无模型的强化学习算法主要分为基于值函数进行优化的算法、基于策略进行优化的算法、值函数和策略结合进行优化的算法。
4.1 基于值函数的算法
基于值函数的强化学习算法通过对值函数进行优化从而得到最优策略。在VRP 中,值函数是对路径策略π优劣的评估,值函数分为状态价值函数V*(s)和状态-动作价值函数q*(s,a),V*(s)表示为:
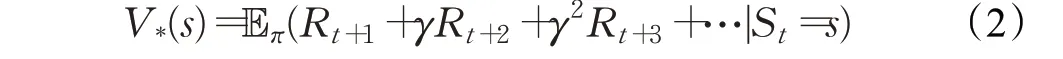
q*(s,a)表示为:
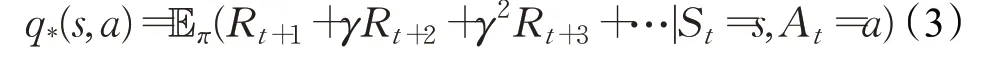
在求解VRP 中,基于值函数的强化学习算法主要有时序差分算法、Q-learning 算法、DQN 算法、Dueling DQN算法。
4.1.1 时序差分算法
时序差分算法由Wang 等人[14]提出,是强化学习的核心算法之一,它结合了动态规划算法和蒙特卡洛方法的原理,是通过部分状态序列来求解问题的强化学习算法。在时序差分算法中,价值函数的更新是通过两个连续的状态和其的奖励值的差来实现的。最基本的时序差分算法的价值函数更新公式为:
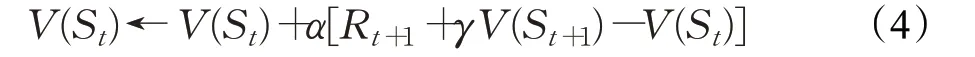
其中α为学习率,Rt+1+γV(St+1)-V(St)为时序差分误差,因此使用这种更新方法的时序差分也被称为单步时序差分。
针对带时间窗的动态车辆路径问题(CDVRPTW),Joe 和Lau[35]提出了DRLSA 模型,通过基于神经网络的时序差分算法和经验放回策略去近似价值函数,然后运用模拟退火算法生成路径。实验表明,DRLSA 模型在有48 个客户节点的CDVRPTW 上优化效果超越了经典的基于值函数近似算法和MSA 算法。该方法解决了当动态请求普遍存在时,该如何给出有效的路径规划。
时序差分算法作为经典的无模型算法,对模型环境要求低,无需训练结束即可获得各类参数的增量。在规模较小的车辆路径问题中优化效果较好,但收敛速度较慢,作为表格型传统强化学习算法不足以解决复杂的车辆路径问题。
4.1.2 Q-learning算法
Q-learning算法是Watkins等人[19]提出的,该算法求解强化学习问题时,使用两个控制策略,一个策略用于更新动作,另一个用于更新价值函数,核心思想为离轨策略下的时序差分控制。Q-learning算法在强化学习的控制问题中应用最为广泛。该算法价值函数的更新公式为:

其中α为学习率,Rt+1为t+1 步的奖励,α为状态St+1能执行的动作。
Zhang等人[34]提出来一种基于查找表的值函数近似VFA模型求解带有随机需求的VRP。具体来说,将当前状态和决策的重要信息存储在一个Q-表中,并用改进的Q-learning算法进行学习。
针对多任务的车辆路径问题,Bouhamed 等人[36]提出了一种基于Q-learning 算法的多任务代理路由调度框架。该模型首先将与任务相关的时间段定义为一个集合,并据此设计出了相应的Q-表,再通过Q-learning算法对Q-表进行更新从而对问题进行求解,实验结果表明,该模型在复杂的VRP 上优化效果接近目前最优方法。
Q-learning 算法因优先执行动作,主动探索能力强。可有效的求解带有随机需求信息的车辆路径问题。但因是把状态和不同的动作存储在Q 表中并一直更新,易使算法陷入局部最优,降低算法的学习效率,搜索耗时较长。更新Q表时Q表一直发生动态变化,所以更新的效果不稳定。
4.1.3 DQN算法
DQN算法是Mnih等人[20]提出的,该模型将Q-learning算法与深度神经网络相结合起来,通常使用DNN 或者CNN来构建模型,使用Q-learning算法训练。DQN算法对Q-learning 的改进主要有以下两个方面:(1)DQN 算法利用神经网络逼近值函数。(2)DQN算法利用了经验回放训练强化学习的学习过程。DQN算法的损失函数如下:

目前,DQN 算法在VRP 中的应用是一个新兴的研究热点,国内外的主要研究成果有:
针对带有多个仓库(depots)的车辆路径问题(MDVRP)和动态车辆路径问题,Bdeir 等人[37]提出了基于DQN 的RP-DQN 模型,该模型框架如图3 所示。RP-DQN 模型中为有效降低问题的计算复杂性,编码器不仅对静态的客户节点位置、客户需求进行编码,并对问题中的动态特征信息进行编码,使用Q-learning 算法对模型进行优化。在客户数量为20、50、100 的CVRP 上优化效果均超过了Kool 等人[38]的方法。首次将深度Q 网络运用到MDVRP 的求解过程中,在客户数量为20、50、100 的MDVRP上RP-DQN模型的优化效果也好于Kool等人[38]的方法。总体来说RP-DQN 模型的泛化能力要高于Kool等人[38]提出的AM模型。
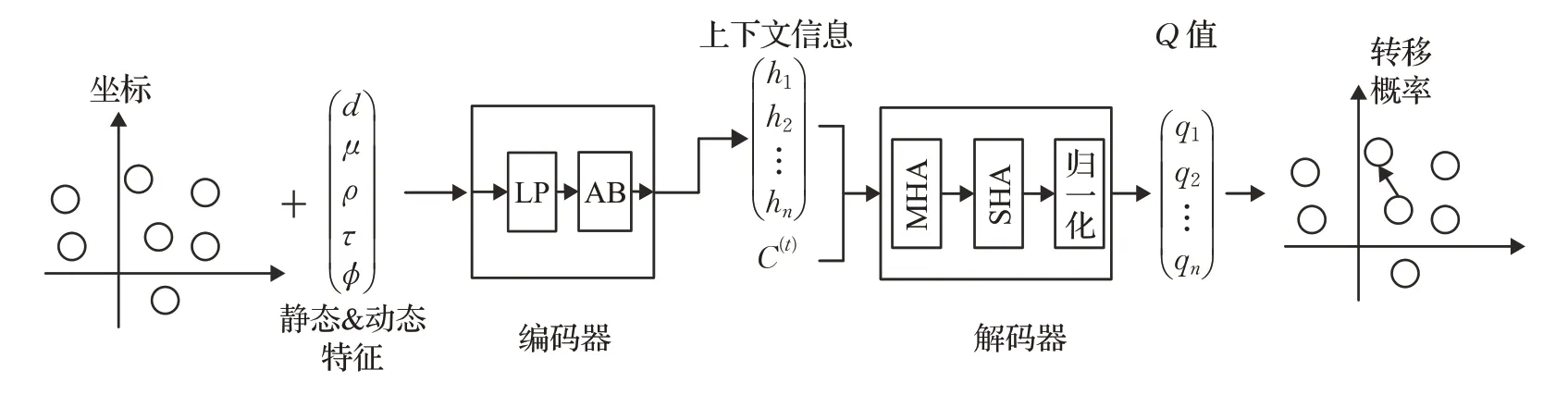
图3 RP-DQN模型示例Fig.3 Example of RP-DQN model
针对客户当日要求交付(same-day delivery)的需求,Chen 等人[39]提出了车辆和无人机的当天交付问题(same-day delivery problem with vehicles and drones,SDDPVD),建模过程中采用和Powell[26]相同的模型架构,并使用Ulmer等[40]提出的路由策略来模拟路线的更新和演变,首先将SDDPVD 建模为MDP 模型,为了使决策快速有效,将动作空间和状态空间进行简化,通过设计DQN算法去近似每个特征向量的值。
4.1.4 DQN算法总结
DQN算法作为具有里程碑意义的深度强化学习算法,不同于传统强化学习算法中值函数线性近似方法,使用多层深度神经网络近似代替Q-learning 算法中的Q-表,从而可以将高维输入值映射到Q-空间。DQN 算法通过一个经验池来存储以前的数据,每次更新参数的时候从经验池中抽取一部分的数据来更新,打破信息间存在的关联,从而可有效求解有状态、动作高维复杂,数据间彼此有关联的车辆路径问题。
基于DQN算法求解车辆路径问题的各类模型主要是通过对DQN算法的状态、动作、奖励的表示做出相应的修改,对价值函数进行映射,通过对价值函数做出评价,以此改进初始策略。但DQN 算法在求解车辆路径问题仍存在很多不足,比如因需对Q-网络进行最大化操作引起过估计问题,DQN 算法只能求解单车辆的车辆路径问题。
4.1.5 DQN算法局限性分析
DQN 算法因运用经验放回机制和设定一个固定Q目标值神经网络,具有较好的收敛性和兼容性。但在车辆路径问题求解中也存在较多问题,例如过拟合问题、样本利用率低、得分不稳定。具体以上问题原因为:
(1)过拟合问题
DQN 算法在训练智能体过程中,会采用Q 网络最大化的操作,从而出现过度适应当前环境的情况,使算法出现过拟合现象。
(2)样本利用率低
DQN 算法和环境交互的过程中,样本之间有很强的关联性,降低了深度神经网络的更新效率,算法需要很长的时间才能达到合适的得分标准,使得DQN 算法在车辆路径问题中的数据样本利用率较低。
(3)得分不稳定
使用DQN算法求解车辆路径问题时,Q-learning学习过程中会对Q值过高估计,容易产生较高误差,导致算法稳定性较差,得分性能不稳定。
4.1.6 Dueling DQN算法
针对无模型的强化学习问题,Wang 等人[41]提出了一种新的DQN 模型:Dueling DQN(DDQN)。不同于DQN 算法,DDQN 算法把在卷积层得到的特征分为状态值和动作优势函数两部分:

式中,Qπ(s,a)为状态s下选择动作a的奖励值,状态值Vπ(s)是对状态s的评价,动作优势函数Aπ(s,a)是对状态s下各个动作优劣的评价指标。
Zhang等人[42]为有效解决车辆路径问题中的供需匹配难题,提出了QRewriter-DDQN 模型。将可用车辆提前调度给需求级别高的客户。QRewriter-DDQN模型由Qrewriter 模块和-DDQN 模块构成,DDQN 模块将车辆和客户之间的KL分布作为激励函数,从而得到供需之间的动态变化。之后,运用Qrewriter 模块用来改进DDQN生成的调度策略。
4.1.7 Dueling DQN算法总结
Dueling DQN 算法是通过改进深度神经网络的结构来提高DQN算法性能。该算法采用卷积神经网络处理车辆路径问题中的初始信息,并使用两个全连接神经网络把Q值划分为状态值和动作优势函数两部分,通过这种改变可以有效地区分出奖励值的来源。因为优势函数存在,Dueling DQN算法可以让一个状态下的所有动作同时更新,加快了算法收敛速度。尤其是在有大规模动作空间的车辆路径问题中,相较于初始DQN 算法Dueling DQN算法能更加高效的学习价值函数。
4.2 基于策略的方法
以上基于值的算法是通过值函数近似方法对价值函数进行参数化比较,从而使个体选择相应动作。另一种常见的是基于策略的算法,直接对策略进行优化,寻找最优策略。常用于VRP的基于策略的算法有蒙特卡洛REINFORCE算法、Actor-Critic算法等。
基于策略的算法具有策略参数化简单、收敛速度快的优点,且适用于连续或者高维的动作空间。策略就是策略参数化,即πθ,参数化后的策略为一个概率密度函数θ。与策略相对应,策略搜索分为随机策略搜索和确定性策略搜索。策略搜索的目的就是找到最优的参数θ,定义目标函数:

定义策略梯度公式为:

更新策略的参数:

4.2.1 蒙特卡洛REINFORCE方法
蒙特卡洛REINFORCE 方法是最简单的策略梯度算法[43],该算法使用价值函数V*(s)来近似代替策略梯度公式里面的Qπ(s,a),首先输入N个蒙特卡洛完整序列,用蒙特卡洛方法计算每个时间位置t的状态价值Vt(s),再按照以下公式对策略θ进行更新:

不断执行动作直到结束,在一个回合结束之后计算总反馈,然后根据总反馈更新参数。pθ(π|s)为每一步动作选择概率的累乘,则lnpθ(π|s)则为每一步动作选择概率对数的求和,∇lnpθ(π|s)为梯度值,L(π)-b(s)为梯度下降的方向,b(s)为策略的平均表现。
自Vinyals等人[44]在2015年提出了指针网络(Ptr-Net)模型求解旅行商问题后,在小规模的旅行商问题上,相较于传统的启发式搜索算法。该模型具有求解更快的特点,这是深度学习在组合优化问题上的首次应用,旅行商问题是VRP的一种特例,因此,研究人员开始将指针网络模型应用于VRP的求解。
Nazari等人[45]针对CVRP构建Ptr-Net—REINFORCE模型,该模型是一个end-to-end的深度强化学习模型,通过Ptr-Net进行建模,在构建指针网络阶段,Ptr-Net中的输入为静态值(客户位置)与动态值(客户需求),其模型结构如图4 所示。不同于Ptr-Net 在训练模型时采用监督式方法,使用REINFORCE 算法对模型进行训练,分别在客户数为10、20、50、100 的CVRP 数据集上进行了测试,取得了比经典的启发式搜索算法CW、SW更好的效果。Xin 等人[46]为解决深度强化学习算法在构造解的过程中无法修改以前决策,提出基于REINFORCE算法的分步SW-Ptr-Net 模型和近似SW-AM 模型。该方法有效提升了Ptr-Net 模型和AM 模型[47]对CVRP 的优化效果。
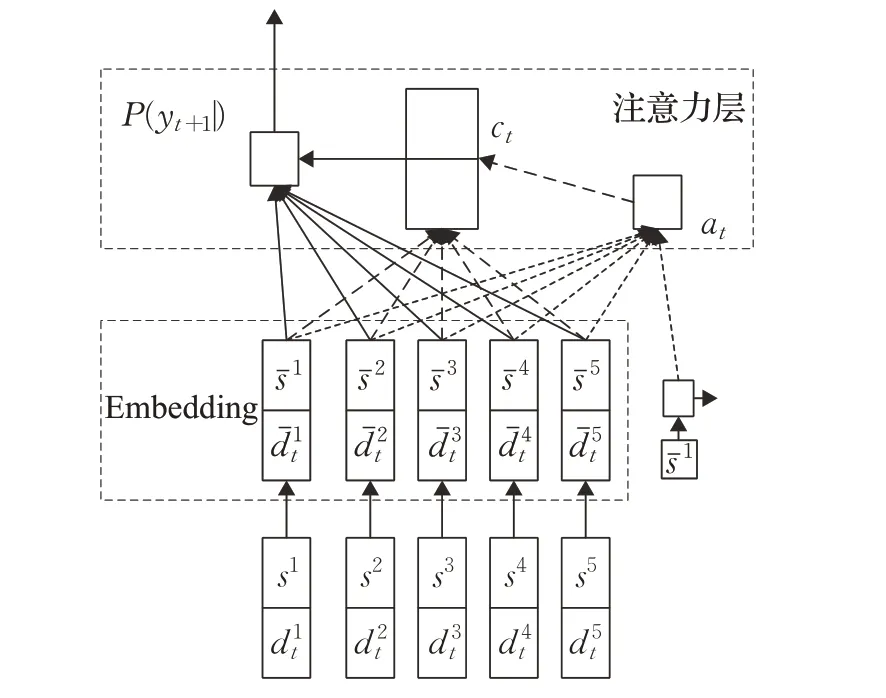
图4 Ptr-Net-REINFORCE模型示例Fig.4 Example of Ptr-Net-REINFORCE model
(1)基于Ptr-Net的深度强化学习模型总结
Ptr-Net 模型使用编码器对车辆路径问题中的初始信息进行编码得到特征向量,再通过解码器对特征向量进行解码,利用注意力机制计算每个客户节点的选择概率,从而构造车辆路径问题的解。所有运用Ptr-Net 模型构造车辆路径问题的构造过程大致如下:
首先通过Embedding 层把每个客户节点的地理位置和需求转化为节点表征向量s,传入循环神经网络中得到上下文信息和隐藏层信息。然后通过解码器对上下文信息进行解码,利用注意力机制按照隐藏层中的信息和上下文信息得到每个客户节点的被选概率,每一步都选择被选概率最大的客户节点加入解中,逐步构造车辆路径问题的解。若使用监督式方法训练模型,需要得到已有最优解的车辆路径问题训练集,车辆路径问题是经典的NP 难问题,因此得到实例的最优解非常困难。且车辆路径问题均可建模成MDP 模型,使用强化学习算法训练Ptr-Net 模型是非常合适的。由式(12)可知,REINFORCE 算法是以反向传播作为参数更新的标准,智能体在探索解空间时,可以不断提升初始解的质量。因而,当使用Ptr-Net 模型求解车辆路径问题时,国内外学者常采用REINFORCE算法对模型进行优化。
Ptr-Net 模型这一新型深度神经网络模型,主要解决输入时序与位置相关的离散个体组成输出时序的问题,是求解具有时间序列特性的车辆路径问题的主要深度学习模型。相较于循环神经网络处理具有自回归问题,Ptr-Net 模型对输入序列长度可变时,直接使用归一化方式输出各个客户节点在当前解码位置的概率分布。但Ptr-Net 模型复杂度较高,且需要大量的采样和局部搜索改善Ptr-Net 模型得到的初始解,使模型收敛较慢。
Kool 等人[38]首次将transformer 模型应用到VRP 的求解中,和大多数seq2seq 模型一样,transformer 的结构也是由编码器和解码器组成。在编码器中作者没有使用transformer模型输入时的positional encoding,从而使得节点嵌入不受输入顺序影响,但仍采用经典transformer 模型中的多头-attention 机制。在解码器中作者为了提高计算效率并未采用transformer 模型解码层的多头-attention 机制,而是只使用一个自-attention 机制。采用加入rollout baseline的REINFORCE算法对模型进行训练,并在CVRP 和SDVRP 等问题的求解上取得了比基于指针网络模型更好的效果,且与经典的运筹学求解器LKH3、Gurobi相比求解效果相差无几。
Falkner 等人[47]针对CVRPTW,提出了JAMPR 模型,该模型由多个编码器和一个解码器组成,编码器采用了self-attention 计算方法,通过加入两个新的编码器产生上下文信息以及增强联合行动空间,解码器使用transform模型的多头-attention机制。使用REINFORCE算法对JAMPR 模型进行训练,模型架构如图5 所示。在对CVRP-TW 的3 种变体(hard、partly-soft、soft)的实验中,该模型的优化效果要好于现有的元启发式算法和基于attention机制的强化学习模型。

图5 JAMPR模型示例Fig.5 Example of JAMPR model
Xin 等人[48]提出了一个多解码器注意模型(multidecoder attention model,MDAM)来训练波束搜索(beam search)的策略,MDAM 由一个编码器和多个解码器组成,编码器采用和transformer模型相同的多头-attention机制,每个解码器采用节点嵌入的方式来产生访问每个有效节点的概率。使用REINFORCE 算法对JAMPR 模型进行训练。在对CVRP 和SDVRP 等问题的求解中,相较于所选基准算法该模型的优化效果要更好。为有效地解决具有软时间窗的多车辆路径问题(multi-vehicle routing problem with soft time windows,MVRPSTW),Zhang 等人[49]提出了多智能体注意力模型(multi-agent attention model,MAAM),使用REINFORCE 算法对MAAM 模型进行训练。实验结果表明,求解速度优于Google OR-tools 求解器和传统的启发式算法。Xu 等人[50]以AM模型[38]为基础构建了具有多重关系的MRAM模型,更好地获取车辆路径问题的动态特征。
(2)基于transformer的深度强化学习模型总结
Ptr-Net 模型中因编码器和解码器使用循环神经网络因而存在不能捕获问题的长程相关性,且模型训练消耗大量时间,因transformer 模型中的多头attention 可以提取车辆路径问题中更加深层次的特征,所以学者们借鉴transformer 模型提出了基于attention 机制提出各类新模型,此类深度强化学习模型仅通过attention机制对输入输出的全局依赖关系进行建模,这类模型可以捕获客户节点间的长程相关性且有较高的计算效率。但attention 机制需要极大的计算量和内存开销,所以这类模型的主要改进是通过改变编码器和解码器的个数以及编码方式、解码方式、注意力机制来实现的。因REINFORCE 算法具有自适应性,可自行调节参数,基于transformer 的各类模型常使用REINFORCE 算法作为训练模型的算法,但因为REINFORCE 算法方差较大,训练结果不稳定,研究人员引入带有基线函数的REINFORCE算法,该训练算法加快了模型的收敛速度。
Peng等人[51]结合动态attention方法与REINFORCE方法设计了一种AM-D 模型来求解VRP,动态attention方法是基于动态编码器-解码器结构来改进的,改进的关键是动态挖掘实例的结构特征,并在不同的构造步骤中有效地挖掘隐藏的结构信息,模型架构如图6 所示。实验结果表明,在客户数量为20、50、100 的CVRP 上优化效果均超过了Kool等人[38]提出的AM方法,并明显减小了最优性差距。Lu等人[52]提出了基于迭代的learn to improve(L2I)框架,算法首先给出一个可行解,运用基于REINFORCE 方法的控制器选择改进算子或基于规则的控制器选择扰动算子迭代更新解,经过一定迭代步骤后从所有访问的解决方案中选择最优解。对于CVRP,该模型不仅在优化效果上超过了Google ORtools、LKH3等专业运筹学求解器,还是第一个在CVRP上求解速度低于LKH3求解器的强化学习框架,模型架构如图6所示。

图6 L2I 模型框架Fig.6 Framework of L2I model
Hottung和Tierney[53]提出神经大邻域搜索(NLNS)框架对CVRP、SDVRP等问题进行求解,运用基于attention机制的神经网络对LNS 中的毁坏算子和重建算子进行学习,并用REINFORCE 算法对NLNS 模型进行训练。实验结果表明,在CVRP 实例上NLNS 模型与LKH3 性能相当;在SDVRP 实例上,NLNS 能够在拥有100 个客户的实例上胜过目前最先进的方法。
(3)强化学习与局部搜索算法结合的模型总结
基于transformer 模型和Ptr-Net 模型求解车辆路径问题虽然速度较快,但优化效果仍不及专业运筹学求解器。在组合优化问题求解中,局部搜索算法仍然是主流代表算法,局部搜索算法往往涉及到算法参数设置和问题配置,这些都需要算法设计者有高超的算法设计技巧才能保证启发式算子的效果。学者们基于不同车辆路径问题的特征和算法结构得到合适的参数和策略,运用强化学习方法对局部搜索策略进行训练,扩大了局部搜索算法启发式算子的搜索能力,以此来提高解的质量。目前,求解车辆路径问题的最优算法就是基于强化学习的局部搜索算法。
4.2.2 REINFORCE算法局限性分析
随着计算机计算能力不断增加,REINFORCE 算法已成为深度神经网络模型解决车辆路径问题最常用的训练方法之一。REINFORCE 算法相较于基于值函数的算法,可以表示随机策略,当策略不定时,可以输出多个动作的概率分布。但是REINFORCE 算法也存在很多问题,比如数据利用率低、算法收敛速度慢、方差较大导致算法收敛性变差。分析存在以上的原因如下:
(1)数据利用率低
REINFORCE 算法是回合更新的算法,需要完成整个回合,才能更新状态-动作对。这种更新方式使得整个轨迹的一系列动作被当作整体,若轨迹的收益较低,即使包含一些好的动作,但下次被选的概率仍会下降,使得数据利用率低。
(2)算法收敛速度慢
对于REINFORCE算法,车辆路径问题中的每个样本只能被训练一遍,有些能具有高收益的样本没有被重复利用,这不仅浪费计算资源,还增加算法了的收敛时间,使得算法收敛速度慢。
(3)算法收敛性差
在车辆路径问题中,REINFORCE 算法为控制训练个体的时间,不可能遍历所有状态,只能通过采样得到大量轨迹,但这样的做法会造成REINFORCE 算法与环境交互不充分,那些未被选中的动作有可能对应着较高奖励,因而产生较大方差,导致算法收敛速度变慢。所以经常通过在算法中加入基线函数来避免高方差。
4.2.3 Actor-Critic算法
Actor-Critic 算法是一种基于值方法和基于策略方法相结合而产生的算法。该算法的架构包括两个部分:Actor 部分是基于策略方法的,通过生成动作并和环境交互,用来逼近策略模型πθ(s,a);Critic部分是基于值方法的,判定动作的优劣性,并且选择下一个动作,用来逼近值函数Q(s,a)。Actor 与Critic 之间互补的训练方式相较于单独的算法更加有效。策略梯度函数为:
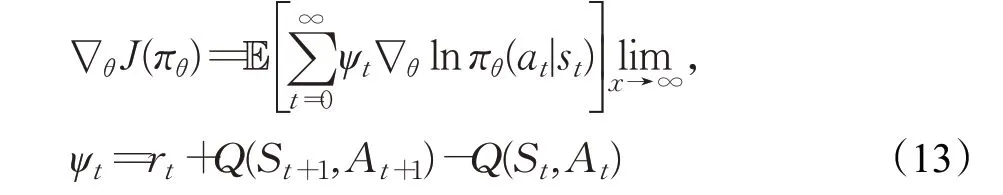
Actor的策略网络的更新公式为:

Critic的值函数网络的更新公式为:

Zhao 等人[55]提出一种改进的Actor-Critic 算法对模型进行训练,首先通过路由模拟器生成大量VRP 实例用于训练和验证,在Actor 网络的编码过程中将静态特征和动态特征分别编码,在基本attention机制[38]中,模型对输入序列的顺序很敏感。为了克服这个问题,采用了图嵌入的方法,Critic 网络由一个Simple 网络和一个Actor网络组成,为加快模型收敛速度,还借鉴了图像字幕[56]中的Self Critic 思想,据此构成了Adaptive Critic网络,网络架构如图7所示。新的Actor-Critic模型在客户点数分别为20、50 和100 的3 个数据集上进行测试。实验结果表明,该模型找到了更好的解决方案,同时实现了5到40倍的加速。还观察到,与其他初始解决方案相比,将深度强化学习模型与各种局部搜索方法相结合,可以以更快的求解速度得到解。

图7 Adaptive Critic 网络示例Fig.7 Example of Adaptive Critic network
在日常生产生活中,一个客户可能总是有他自己的送货点,比如同城快递服务[57]和拼车服务[58],而不是像VRP那样为所有客户共享一个仓库。所有这类VRP可描述为提货和交货问题(pickup and delivery problem,PDP)。Li 等人[56]提出了一种基于异构attention 机制的编码器-解码器模型,其编码层在多头attention注意力方法中加入了异构attention 方法以期更早得到优先级较高的关系,采用Actor-Critic算法对该模型进行训练。在PDP 求解中该模型的优化效果要好于传统的启发式算法。Gao 等人[57]提出了基于图注意力网络的模型用去求解VRP、CVRP。该模型的编码器是由一个graph attention network 组成,模型首先对每个客户位置进行编码得到每个客户顶点的边缘嵌入和顶点嵌入,在通过attention机制计算出每个客户被选择的概率。解码器采用和Ptr-Net一样的架构,为VLNS算法的破坏算子提供一个节点子集作为移除候选。依然采用Actor-Critic 算法对该模型进行训练。
当VRP、CVRP、CVRPW 等问题的规模较大时(多于400 顶点),该模型优于传统启发式算法和现有求解VRP的深度强化学习模型。
强化学习与图神经网络结合的模型总结:车辆路径问题是典型的具有图结构的组合优化问题,因图神经网络能够有效求解具有图结构的问题,所以有学者把图神经网络应用到了车辆路径问题的求解中,运用图神经网络求解车辆路径问题的构造。
过程大致如下:将车辆路径问题建模为图G=(V,E),其中V代表节点集合,E代表边集合。图神经网络根据用户节点Vi本身的二维空间位置和需求、边的特征,以及节点Vi邻居节点的二维空间位置和需求对节点Vi特征向量进行更新,从而得到每个节点的特征向量。为加快模型收敛,研究人员通常把图神经网络求得的用户节点的特征向量加入transformer 模型和Ptr-Net 模型的编码器中,在通过attention 机制计算出每个客户被选择的概率。因为Actor-Critic 算法融合了基于值的算法和基于策略的算法的优点,即可解决连续动作空间问题,还能进行单步更新从而加快学习速度,所以在图神经网络中常使用Actor-Critic 算法训练模型。
4.2.4 Actor-Critic算法局限性分析
Actor-Critic 算法是目前最为流行的强化学习算法之一,结合了基于值算法和基于策略算法的优点,既能应用于连续动作空间,有能进行单步更新。但仍然存在一些问题,比如学习效率低,收敛速度慢。分析存在以上问题的原因如下:
(1)学习效率低
Actor-Critic 算法中涉及到Actor 网络和Critic 网络两部分,Actor网络基于概率选择动作等价于策略函数,Critic网络等价于价值函数。Actor-Critic算法每次更新都会涉及到这两个深度神经网络,而且每次都在连续状态中更新参数,参数更新时有很强的相关性。导致算法学习效率低。
(2)收敛速度慢
Actor-Critic算法中Critic网络收敛速度慢,若Critic网络不收敛,那么它对Actor网络的评估就不准确,导致Actor网络难收敛,使得Actor-Critic算法收敛速度慢。
4.2.5 Advantage Actor-Critic算法
Advantage Actor-Critic(A2C)算法又称同步优势Actor-Critic算法是Mnih等人2016年提出的。在Actor-Critic 算法中Critic 网络输入Q值来对策略梯度进行计算,但这种计算方式存在高方差的问题,从而可以引入Baseline 的方式减小梯度使得训练更加平稳,通过这种改进就能得到A2C 算法。A2C 算法的策略梯度函数为:

A2C算法的优势函数为:

A2C 算法将Critic 网络对Q值的估计改为对优势函数的估计,估算每个决策相较于平均值的优势。A2C算法的整体架构与Actor-Critic算法类似,只是在其基础上加入了并行计算的能力,即整个个体由一个全局网络和多个并行的工作体(worker)组成,每个工作体都包括一个Actor-Critic网络。
Vera和Abad[58]针对固定车队规模的容量受限多车辆路径问题(capacitated multi-vehicle routing problems,CMVRP),提出了基于Attention 机制的Seq2Seq模型,采用A2C 算法对模型进行训练,与经典的启发式算法SW 和CW 相比该模型生成的解具有更低的标准差。
A2C算法使用一个优势函数作为评价标准,这个优势函数用来评价当前所选动作与所有动作平均值之间的差值,从而降低了AC 算法所产生的误差。但运用A2C算法求解车辆路径问题时,智能体在环境训练中的稳定性较差。
4.3 基于动态规划求解VRP分析对比
基于无模型强化学习方法求解VRP 的对比结果见表3。

表3 无模型方法求解车辆路径问题对比Table 3 Comparison of approaches of model-free applied to VRP
5 强化学习算法总结分析
近年来,强化学习在车辆路径问题求解中涌现了很多优秀的算法,在应用过程中这些算法有自己的优势,但也暴露出一些自身局限性,将上述内容进行总结分析,如表4所示。

表4 强化学习总结Table 4 Summary in reinforcement learning
基于模型的强化学习算法求解车辆路径问题时需先构建MDP模型,智能体通过与环境的不断交互,智能体对数据的利用率较高。为增强求解问题的实时性,使用rollout框架对初始策略进行迭代更新,逐步逼近最优解。近似动态规划中使用自举采样法训练神经网络,自举采样得到的数据不是独立同分布的,这样的采样方式使模型稳定性降低。
现在的使用深度强化学习模型解决车辆路径问题时主要的创新点是对深度神经网络架构的设计上,即设计更加契合车辆路径问题的数据结构,主要包括像Ptr-Net 模型和transform 模型这种把问题建模为序列形式的输入,然后基于各类attention机制对客户节点的选择优先级进行排序;因车辆路径问题天然是图结构,可基于图神经网络和基于图神经网络的attention 机制提取车辆路径问题的特征。通过以上方法得到局部解后以自回归的方式扩展得到最优解。因为监督式学习方法不适用与组合优化问题,学者们采用具有反向学习能力的强化学习算法训练模型。深度强化学习模型求解速度远超传统的启发式算法,模型泛化能力较强。
强化学习算法的优势是智能体通过和环境进行交互可以得到最优策略,从而具备解决大规模复杂组合优化问题的可能性,但其也存在着算法执行时间过长、模型不易收敛等局限性。因此,可用其他启发式算法和强化学习融合,主要是使用强化学习算法对启发式搜索算子进行学习,加快求解速度,提高解的质量,相较于人工设置搜索策略,强化学习算法可以扩大搜索空间和提高搜索策略效率,具有较强的优化能力。
6 结论与展望
本文旨在对近年来基于强化学习求解车辆路径优化问题的各类算法进行较为全面的综述,重点分析了各类强化学习算法的机制特点和优劣性。如今在VRP的求解中各类深度强化学习模型不断涌现,本文对这些模型的特点和优化效果进行了总结。基于模型的强化学习算法必须对问题进行建模,但往往车辆路径问题建模过程与现实环境总有差距。在基于编码器-解码器的transformer 模型和Ptr-Net 模型以及图神经网络中强化学习算法都是作为训练模型的算法出现,选择强化学习算法时目的性不强。且强化学习自身存在较强的探索和利用困境,个体不仅要学习以前样本中的动作,还要对未来可能带来高奖励的动作进行探索,但车辆路径问题是高度复杂的大型问题,强化学习常用的探索策略常常失效,探索策略的可扩展性较差。强化学习算法常因为经验样本只被采样一次或随着经验的积累,同一个样本被多次抽样的概率越来越小,从而导致样本的采样率较低。计算机本身计算能力也限制了强化学习算法的效果。且目前基于强化学习求解车辆路径问题的模型,主要都是对客户节点小于100的问题进行求解,很少有作者对大规模车辆路径问题进行求解。因此,未来基于强化学习模型求解车辆路径问题的工作可从以下方面展开:
(1)建立更小误差的环境模型。对于有模型的强化学习算法,精确的环境模型可以减少个体和环境的交互,可以通过模型仿真生成大量样本数据,使得算法快速学习。通过更加科学的方式定义参数,减少人为设定引起不确定性,可增强模型的可靠性。但当数据量较少的时候,学到的模型误差较大,且现实生活中的车辆路径问题的环境动力学较为复杂,从而使得建立精确模型更为困难。
(2)提高数据采样率。针对无模型的强化学习算法数据采样率低的问题,可以重新设计采样方法,使用离轨策略设计并行架构进行学习;针对有模型的强化学习算法采样率低的问题,可以将模型误差纳入模型设计中,从而提高数据采样率。
(3)设计更加高效的模型。目前求解车辆路径的深度强化学习模型中,运用深度神经网络直接求解得到初始解的质量较差,大多数模型都需要与其他方法结合提升解的质量,使得求解时间变长。因而,未来可以对神经网络的理论基础进行深入研究,设计更加高效的深度网络结构和表示方法,得到更加高效模型。尤其是图神经网络与新型注意力机制结合是未来的重点研究方向之一。
(4)选择更加合适模型训练算法。目前基于编码器-解码器求解车辆路径问题的模型,常直接选用REINFORCE算法、Actor-Critic算法等常规的强化学习算法,不同类型的车辆路径问题优化目标不同,能有效解决复杂问题的多智能体强化学习和分层强化学习尚处在探索阶段,如何选用更新高效强化学习算法作为模型的训练方法,对提升模型性能至关重要。这也是一个重要的改进方向。
(5)提升模型稳定性。现有的深度强化学习模型一旦训练完成,就可以求解同类型的问题,泛化能力较强,但是优化效果无法保证,局部搜索算法可移植性差,但优化效果较好。因此,运用更加高效的强化学习算法提升一些经典局部搜索算法的求解速度,是未来重要的研究内容。
(6)提高解决现实工程问题的能力。车辆路径问题和现实生活息息相关,通常具有多约束、动态变化的特点,当前的强化学习算法和深度强化学习模型可以求解的车辆路径问题约束较少,规模较小。深度学习模型的最大优势就是可以在大规模问题上有良好表现,因此,设计更加契合车辆路径问题的深度神经网络架构是有效求解大规模、复杂车辆路径问题的方法之一,这也是未来可着重研究的方向。
强化学习已成为热门的组合优化问题求解方法之一,但就目前而言,基于强化学习求解车辆路径问题的算法模型并不具备真正的工程应用能力。随着研究不断深入和理论不断创新,强化学习将会和其他最新先进技术结合,让强化学习在车辆路径问题求解中发挥更大作用。
