基于LDAP的大数据浏览隐式反馈信息检索仿真
2022-01-22叶承斌李宏亨
叶承斌,李宏亨
(广西医科大学信息与管理学院,广西 南宁 530021)
1 引言
现阶段,所应用的信息检索技术使得用户检索质量有所提高,但是对于用户检索结果的有效性以及准确性却没有更深入的研究。因此,对于如何提高用户检索信息的有效性成为了亟待解决的难题之一。
为此,相关学者进行了相关方面的研究。文献[1]通过观察用户的网页浏览习惯获得用户隐式反馈信息,根据这些信息建立用户行为特征模型,利用向量为用户浏览的每个网页设置了权值,以此来推算用户对某一类文档的爱好程度,并对用户行为特征模型进行实时更新,以此来完成用户浏览隐式反馈信息的检索。但是该方法在查全率方面表现较差,需要进一步深入研究。文献[2]提出了一种基于分布式集群的网络浏览行为大数据分析平台,通过大数据分析平台将分布式计算机系统Spark与HDFS技术相结合,分布式用户的网络浏览数据被存储到HDFS中,再利用Spark进行数据挖掘,并结合决策树ID3算法准确计算出用户的文档爱好程度。但该方法对大数据的分析能力较差,对用户的浏览行为管理效率较低。
为此,在LDAP的基础上,提出了大数据浏览隐式反馈信息检索仿真方法。为获取到更精准的用户浏览行为特征信息,构建了LDAP目录服务架构体系,为后续构建用户行为特征模型提供数据支持。用户行为特征模型将元搜索引擎与Agent技术相结合,利用InfoAgent系统来实现,最大限度地展现用户需求。通过仿真结果表明,所提方法具有较高的检索精度和查全率。
2 基于LDAP的大数据浏览隐式反馈信息检索方法
2.1 LDAP目录服务体系
LDAP通常被用作地址簿[3]来使用,支持用户检索信息,其中可有单个或多个服务器,它是在TCP/IP上运行的一种应用层协议,主要运行过程是一个客户机连接一个服务器,并向服务器发送指令[4],以此构成的客户机/服务器模式是LDAP目录的基础,服务器在接收到指令后在目录上完成指令上的操作。当服务器完成指令操作后,将结果或错误应答反馈给LDAP客户机,或者采用Referral重定向机制向其它LDAP服务器发送请求以此来完成客户机的指令,Referral可扩大无法完成的目录服务至最大范围。无论客户机与哪一个服务器连接,接收到的内容都是一样的。表1为LDAP最常用的Web服务,将LDAP应用到Web已有的关系数据[5]中,实现其功能。

表1 LDAP在Web中实现的功能
LDAP客户机可由LDAP服务器管控,或者由集成了LDAP的应用程序管理。图1为LDAP的总体框架结构,展现了各类设备与服务器在LDAP服务目录中进行访问存储的过程。
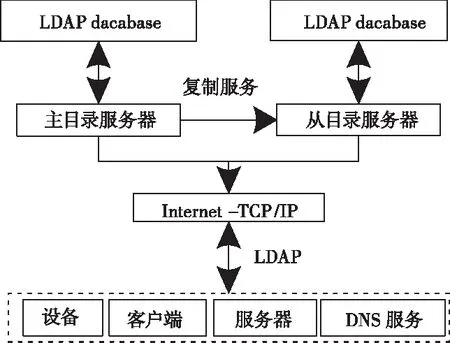
图1 LDAP框架
对LDAP目录服务器中存储的信息进行访问可通过LDAP协议相关的服务器和设备来实现,通过分析该框架可知,目录的主要功能是为数据提供存储的地方,担任着数据库的角色,并可对存储在LDAP目录服务中的数据进行管理,它与基于XML的数据表示是非常重要的两个组件。
2.2 用户浏览行为特征信息获取
通过观察用户浏览网页时的浏览习惯来获取用户浏览兴趣信息,并根据这些信息建立用户特征行为模型。
首先,对用户建立各自的统计文档,然后依次浏览每个文档,以各个浏览文本描述的特定词的集合方式建立文档的索引方式。为了表示特定词在文档中所占比例的大小,将用户浏览文本空间内的所有词添加一个数值权。数值权也可看作为文档d中的词在文档空间[6]内的坐标信息,即将用户浏览的某一个文档d看作是文档空间中的任意一个坐标点,这样就可以将d描述为从文档空间中初始点到任意一点的向量。对描述文档的词添加权值是文档表示法中的关键。
目前比较常用的添加权值的方法是t*A加权方案。t表示某个特定词在Web文档中出现的次数,因为每个文档的内容不同,所以t的值在每个文档中也有所不同。t的主要作用是判定该特定词在Web文档中的重要程度。A表示全局统计数据,参考A的值可以判断出特定词在整个Web文档中的分布规律。A设定为In(N/n),N表示Web文档集合中包含的文档数量,n表示含有某个特定词的文档数量[7]。含有某个特定词的文档数量与A的值呈负相关,即含有特定词的文档数量越多,A的值则越小,当Web文档集合中的所有文档都包含特定词,则A的值为0。
对于用户浏览的网页文档信息,采用基于向量的方法进行描述,文档d的描述向量V对应的第i个元素可利用式(1)计算
w(d,i)=t(i,d)*A(i)
(1)
式(1)中,t(i,d)表示词频统计数据结果,即词wi在网页文档d中出现的次数为
A(i)=In(N/n)
(2)
在网络大数据系统中,如果直接获取到用户对检索结果的评价反馈,称之为显式反馈。这种反馈结果获取途径较为广泛,但是这种方法使用户无法客观[8]的评价网页浏览结果,很难为后续构建用户行为特征模型提供客观数据,降低了整个网络大数据系统的可用性。隐式反馈则只对用户浏览过的文档作出可用性评价,这种方式不会影响用户的网页浏览行为,只根据用户的浏览行为来判断用户的浏览习惯,所以结果精准度较高。
用户的浏览行为[9]体现了对目标文档的感兴趣程度,可采集这些信息建立用户行为特征模型。用户的浏览行为分为:审查行为:滑动滚动条(s)、网页浏览时间(r);参考类型:追随超链接;存留类型:存留网页文档(g)、打印网页文档(b)、添加标签(p)等。通过分析以上几种用户的浏览行为,即可判定出用户对当前页面的感兴趣程度。为了更准确的区分这些浏览行为体现的用户的感兴趣程度[10],对每一种浏览行为v都赋予一个相应的权值Cv,通过计算权值的大小来推断用户对当前页面的感兴趣程度,计算公式如式(3)所示

(3)
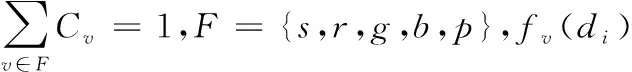
2.3 用户浏览行为特征模型下隐式反馈信息检索
2.3.1 InfoAgent特征模型整体架构
InfoAgent是以VSN模型和用户行为特征为依据,将元搜索引擎和Agent技术相结合,共同开发的用户个人信息检索系统。构建用户行为特征模型,确保该模型反映的信息最接近用户的需求,从而提高整个特征模型提供的资料精度,加快检索效率。具体如图2所示。
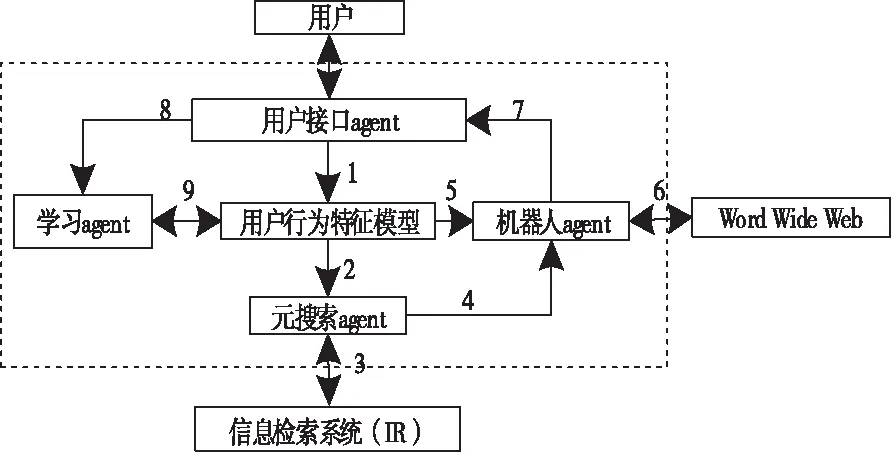
图2 InfoAgent整体架构图
InfoAgent实现精准检索的步骤:
1)根据用户的浏览习惯创建用户行为特征模型q并保存,根据用户不同的浏览行为实时更新模型中的内容。
2)将用户行为特征模型q中所有权值不为零的特征项筛选出来并传送给元搜索agent,作为检索关键词。
3)元搜索agent接收到特征项后,同时向其它信息搜索系统发出查询请求,将所有符合条件的特征项添加到URL列表中。
4)对添加到URL列表中的所有文献进行特征项提取,以此构成文献的特征向量。
5)将提取出的特征向量与用户行为特征模型q进行模式匹配,并进行相关度计算。
6)将特征向量与用户行为特征模型q的相关度与规定的最小相关度Rmin进行比较,如果相关度的值大于Rmin,则以URL为起点,对机器人Rmin下达指令对模型进行启发式搜索,对所有文献进行模式匹配。
7)将搜索结果与用户行为特征模型q最匹配的文献d展现给用户。
8)持续观察用户的浏览行为,并根据式(4)计算出用户的相关反馈值

(4)
式(4)中,0≤fb(d)≤1,B={r,b,l,p,s},cb表示反馈行为的加权因子。
9)根据式(5),实时更新用户行为特征模型。重复操作步骤2),直到用户检索完成为止。
wqk←wqk+β·f(d)·wik
(5)
式(5)中,f(d)表示用户对d的反馈结果,wik表示i的第k个特征值的权值,wqk表示q中第k个特征值的权值,β为学习因子。
2.3.2 检索参数调整
用户行为特征模型是InfoAgent系统的重要组成部分,可对元搜索和机器人下达指令,并通过学习agent更新信息。q中包含了1~N个行为特征模型,每个行为特征模型都反映了一种用户感兴趣的内容,可以表示为:Wq=(wq1,wq2,…,wqk,…,wqu),其中u表示用户行为特征模型库中特征项的个数。
InfoAgent系统在用户的浏览页面设置了Web浏览器窗口,用户在浏览网页时可获得用户的浏览行为信息。将这些信息提供给学习agent,学习agent,对这些信息进行分析整理,并更新q中的内容。隐式反馈值f(d)可以通过计算式(4)得到,q的特征项的权值wqk可通过式(5)进行修改。为了将其它因素的影响降到最低,每完成一次信息反馈后,q自动进行归一化处理,将所有d的特征项的权值小于阈值wmin的进行归零处理。
2.3.3 特征提取和模式匹配
在VSM模型中,d可以以向量的形式表示为
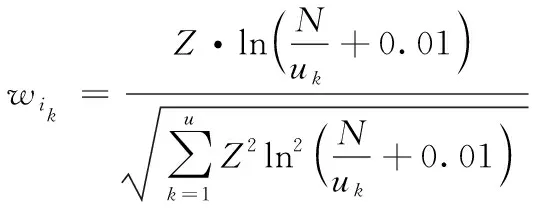
(6)
式(6)中,Z表示d中q的特征项出现的次数,uk表示q的特征项在已经完成检索的d中出现的次数。
信息检索系统通常处理的文档为HTML文献,而HTML文献中含有大量的标记信息。这些标记信息作为文献的概括,可直接对标记信息进行特征提取,利用加权因子γc对HTML标记信息中的q的特征项调整权值。
d与q的相关度计算如式(7)
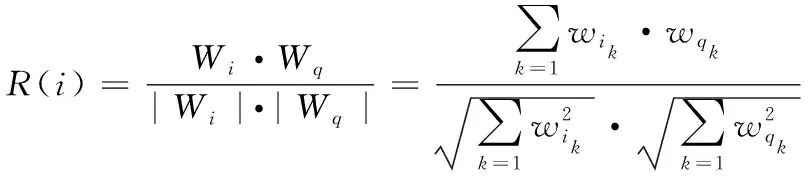
(7)
2.3.4 基于强化学习算法的启发式机器人智能检索
由于机器人agent在文献中的运动是没有规律、没有方向的,若用户一直没有检索到满意的文献,则会花费大量的网络资源来传输资源,降低了系统的有效性。因此需要对机器人agent做进一步优化,使检索的目标相关度更高。利用强化学习算法,对机器人agent的选择路径作出改进,使检索的目标更接近于用户行为特征模型q。对匹配到的相关文献,进行特征提取并与q进行模式匹配,如果d相关度的值大于Rmin,将会加入推荐列表中。
3 仿真研究
3.1 查全率、稳定性实验对比
为验证所提出的基于LDAP的大数据浏览隐式反馈信息检索仿真方法是否合理,将所提方法与文献[1]、文献[2]方法在查全率、查准率及稳定性方面进行仿真对比。实验环境为Windows10系统,3.5GHz主频,8GB内存,借助ImageMatch软件平台进行实验。实验数据来源于中文文本信息资料集SPAN2012,从中抽取120个检索信息构成候选检索信息集。
将所提方法与文献[1]、文献[2]方法在查准率和稳定性方面进行实验对比,结果如图3、图4所示。
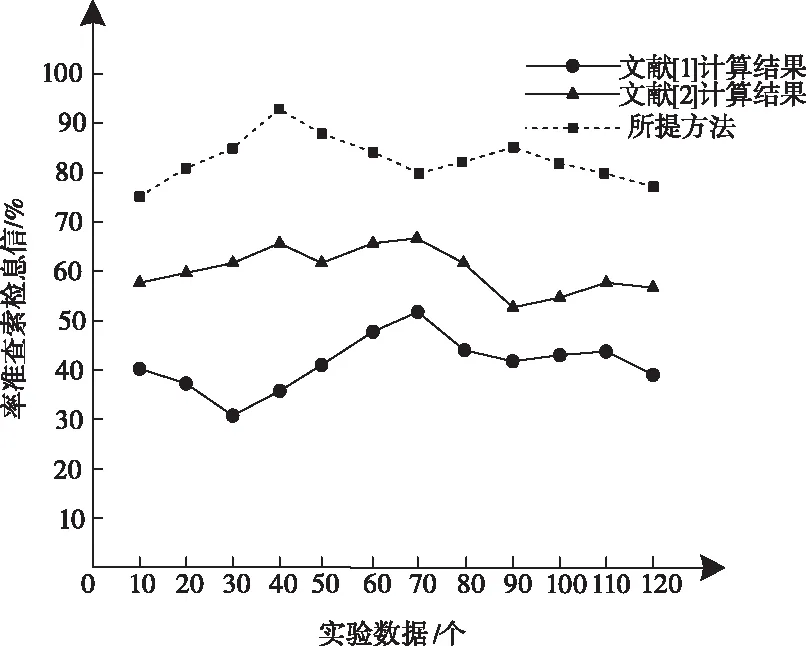
图3 三种方法查准率对比
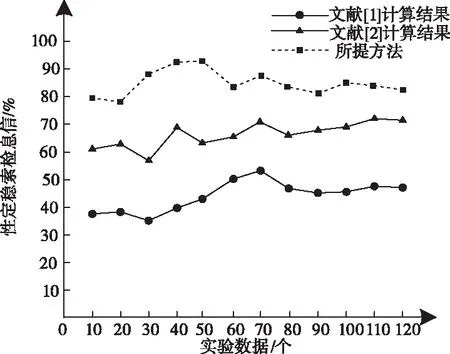
图4 三种方法稳定性对比
从图3和图4中可以看出,由于所提方法根据用户的浏览行为构建了用户行为特征模型,并通过计算特征项的权值调整了检索参数,使得在信息检索查准率和稳定性方面均高于其它两种方法。
3.2 检索精度实验对比
还需对三种方法对文献的检索精度进行仿真对比,建立了20个用户行为特征模型,经过用户浏览行为的增加和时间的推移,三种方法的检索精度如表2所示。
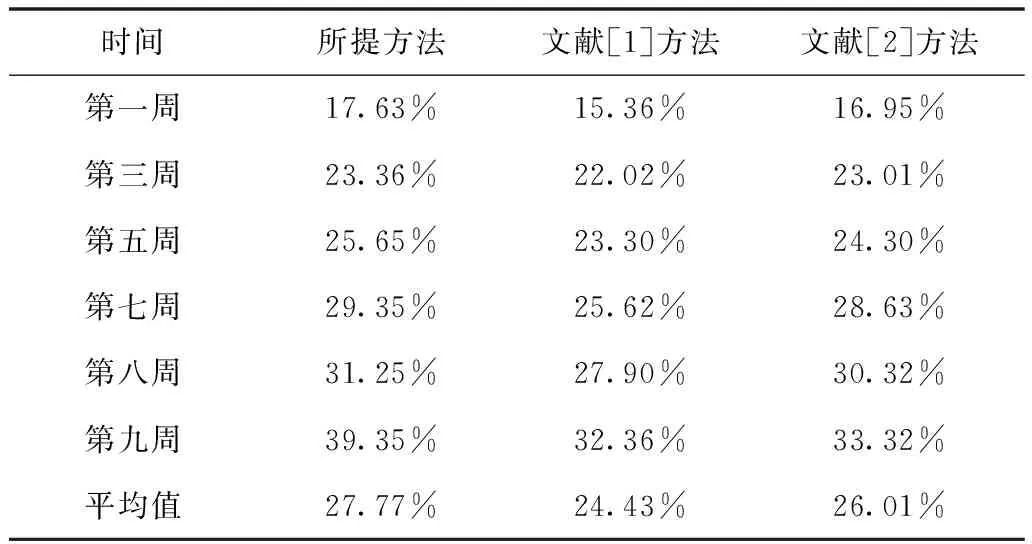
表2 三种方法检索结果对比
从表中可知,在检索初期,三种方法检索精度相差不大,但是随着时间的推移,用户的浏览行为越来越多,用户行为特征模型不断被精化,检索精度也参差不齐。由于所提方法将强化学习算法应用其中,使推荐的文献更接近于用户的需求,所以在检索精度上所提方法效果最优。
4 结论
基于LDAP的大数据浏览隐式反馈信息检索仿真方法。借助LDAP的目录服务,获取到用户的浏览隐式反馈信息,通过分析用户对某一种类型文档的感兴趣程度来构建用户行为特征模型,通过不同的算法使得用户行为特征模型能够最大限度地满足用户需求。通过仿真结果表明,所提方法较传统方法相比有着较高的准确率和检索效率,但是对于所提方法的信息检索的性能还需做进一步提高,以此为研究方向将继续更深层次的研究。
