结合GCN和注意力机制的文本分类方法研究
2022-01-22申艳光贾耀清范永健
申艳光,贾耀清,生 龙,范永健
(1.河北工程大学信息与电气工程学院,河北 邯郸 056038;2.河北工程大学河北省安防信息感知与处理重点实验室,河北 邯郸 056038)
1 引言
文本分类由来已久,利用文本分类技术对大量不同的文本进行科学有效地分类是亟待解决的问题。文本分类有十分广阔的应用,如文章组织、意见挖掘、推荐系统、知识图谱、垃圾邮件过滤、决策过程等[1]。
上个世纪70年代,Salton等人提出了向量空间模型(Vector Space Model),在此基础之上,Feigenbaum首次提出了知识工程(Knowledge Engineering)的概念[6],主要解决的是知识的分类、表示和推理,但这种分类技术由相关领域的专业人员来处理,分类方法过于单一,分类准确率效果欠佳。上个世纪90年代,基于机器学习的文本分类方法逐渐兴起,与基于知识工程的文本分类方法相比,该方法不需要专业人员的参与,并且能够适用于各种领域的文本集合,成为当时文本分类的主流方法,崔建明等人[7]提出了基于SVM算法的文本分类方法,解决了特征工程中的数据高维性和不平衡性的问题。传统的文本分类方法首先建立特征工程,然后经过特征选择,最后经过各种分类算法完成文本分类,现如今深度学习技术的兴起,基于深度学习的文本分类方法占据主流,这是一种端到端的学习方式,有效解决了分类准确率不高的问题。
图卷积神经网络(Graph Convolutional Network,GCN)[8]是近年来的研究热点,非常适合处理具有图结构的数据,例如社交网络、通信网络、蛋白质分子网络等。GCN可以对图结构的数据进行节点分类,边预测和图分类等。早期的图卷积神经网络基于巴纳赫不动点定理,Bruna J等人[9]提出第一个真正意义上的图神经网络(Graph neural network,GNN),其基本思想是基于卷积定理在谱空间上定义图卷积。Yao L等人将提出了Text GCN模型,与其它模型相比准确率较高[10]。Attention机制[11]最早应用在机器翻译任务中,其本质是计算输入的各个部分对输出的贡献权重,Yang Z等人基于层次结构的Attention机制构建了HAN网络[12],并可视化了注意力层。
因此,基于上述问题,提出一种结合GCN和Attention机制的文本分类方法。与传统文本分类方法不同,该方法将文本分类问题转化为图结构数据中的节点分类问题。首先建立整个语料库的大型文本图,然后将该文本图的邻接矩阵和特征矩阵输入到图卷积神经网络中,最后网络的输出与注意力机制相结合,利用注意力机制中Self-Attention机制充分学习文本表示,不断调整网络的输出。与传统的文本分类方法SVM,KNN,TF-IDF相比,该方法准确率较高。
2 基于GCN和Attention机制的文本分类方法
2.1 文本图的构建
一个文本图的各个符号的含义见表1。

表1 文本图中各个符号的含义
将语料库中文档和单词转化为节点的形式,如果相邻两个节点的联系越紧密则连接线越粗,建立文本图G=(V,E,A),如图1。
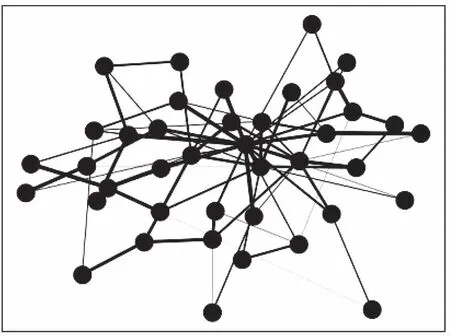
图1 文本图
假设语料库中有N个节点(Node),每个Node具有自己Z维度的特征,定义矩阵X=N×Z,称X为特征矩阵。每个Node之间组成N×N的矩阵,定义矩阵A=N×N,称A为邻接矩阵。
构造GCN,模型简化为
Z=f(X,A)
(1)
引入邻接矩阵的度矩阵D,得到新的邻接矩阵A。
(2)
其中,
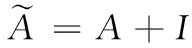
(3)
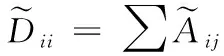
(4)
2.2 注意力机制的引入
Attention机制的本质可以看作是一种ENCODER-DECODER模型,如图2。例如,输入英文句子“He is a teacher”,首先经过编码阶段将输入语句转化为高级文本表示,然后经过解码阶段“翻译”出想要的结果。在输出“教师”时,考虑到输入序列的4个单词“He”、“is”、“a”“teacher”,而Attention机制的作用在于可以为这4个单词赋一个权重,例如将“He”、“is”、“a”赋权值为0.1,而单词“teacher”赋权值为0.7。显然,单词“teacher”的重要性相对其它三个单词更加重要。在编解码过程中,输出序列的每一个单词都充分考虑了输入序列的所有单词,而Self-Attention是Attention机制的特殊形式,输入序列的每个单词都需要和该序列的所有单词进行Attention计算,这样做的目的是充分考虑语句之间不同单词之间的语义和语法联系。
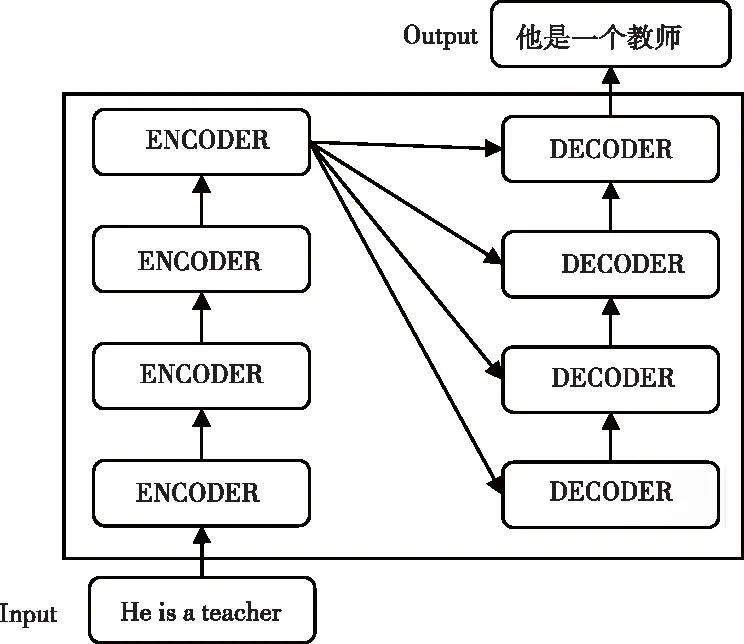
图2 ENCODER-DECODER模型
利用Attention机制中的Self-Attention机制计算Word1和Word2的自我注意力需要经过以下步骤:
1)Word1的词向量为x1,Word2的词向量为x2,通过输入词向量计算得到Attention机制中的Query向量、Key向量和Value向量。
2)计算score得分。其中,
Score=q×k
(5)
3)通过softmax操作进行归一化,保持结果为正,和为1。
4)计算总的加权值,产生输出。其中,
Sum=Softmax×Value
(6)
第2)步到第4)步可以合并,计算公式如下:

(7)
将原GCN的输出引入Self-Attention机制,使网络侧重特征本身的内部联系,最后通过加权平均输出结果,提高模型的表达能力,如图3。

图3 Self-Attention机制
3 实验与仿真
3.1 数据集与技术指标
本仿真采用的公开数据集是20NewsGroups(20NG),20NG是文本分类领域的公开数据集,该数据集包含18846个新闻文档,20个类别,其中训练集60%,测试集40%。
在数据集20NG中,TP表示真正类,TN表示真负类,FP表示假正类,FN表示假负类,如图4。
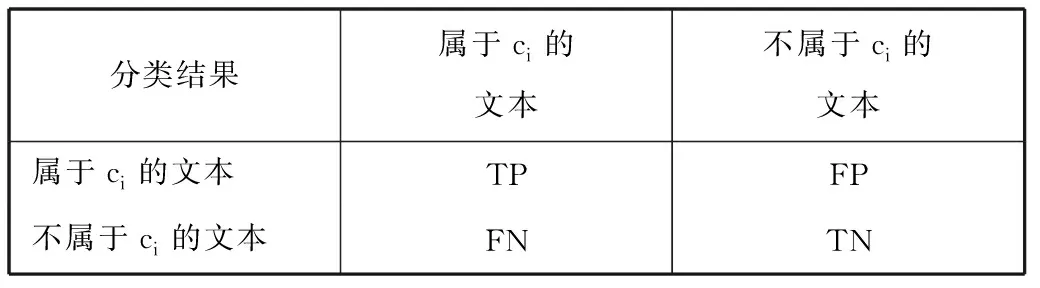
分类结果属于ci的文本不属于ci的文本属于ci的文本TPFP不属于ci的文本FNTN
图4 样本分类
衡量文本分类系统性能的技术指标有正确率(accuracy)、召回率(recall)、准确率(precision),公式如下
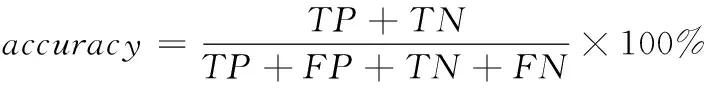
(8)
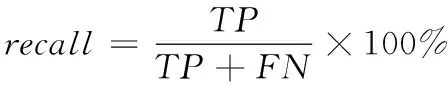
(9)
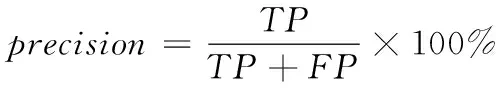
(10)
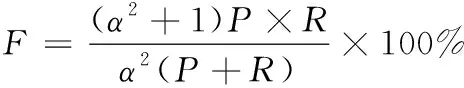
(11)
为了直观有效表示分类的效果,本实验选用precision指标来衡量系统的性能。
3.2 实验环境与仿真结果
本实验的硬件环境为:处理器为i5-9300H,内存为16 GB RAM,显卡为RTX2060。编程语言采用Python3.6.5,结合tensorflow深度学习框架。
设定分类的准确率precision为P,不同分类方法得到的P值见表2:
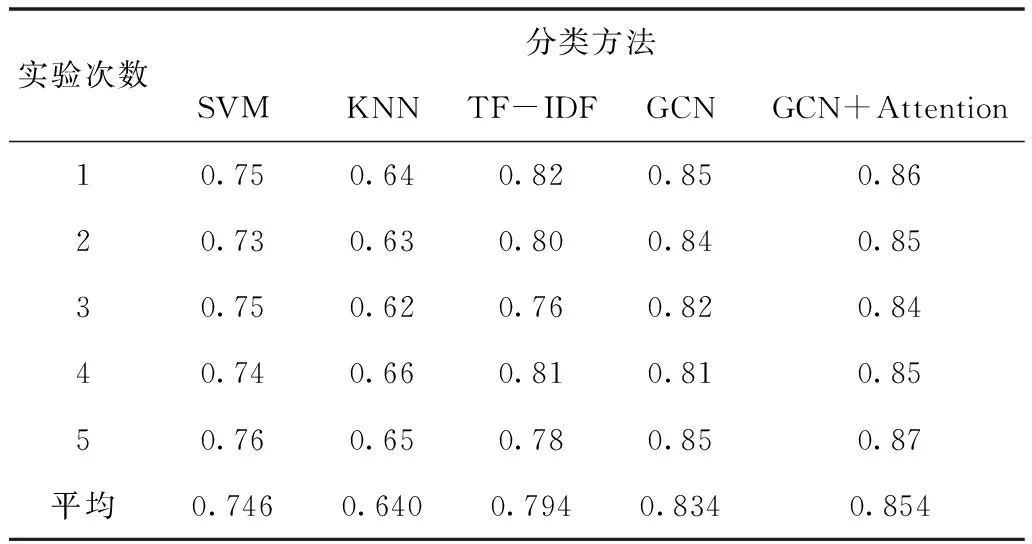
表2 各种分类方法的P值
GCN+Attention的方法比SVM、KNN、TF-IDF以及GCN方法表现良好的原因分析如下:
1)SVM、KNN和TF-IDF方法同属于基于机器学习的文本分类方法,而这些方法都需要经过文本预处理、特征提取、特征选择、分类等过程,由于没有考虑到文档与单词以及单词与单词之间的内部联系,最终分类的准确率表现不佳。
2)GCN+Attention方法与GCN方法同属于基于深度学习的文本分类方法,它能同时对节点特征信息与结构信息进行端对端的学习。由于不需要经过特征提取、特征选择等过程,避免了人工提取特征而引入的误差,引入Attention机制之后,模型更加注重单词与单词之间的联系,增强了文本表示。GCN+Attention方法中文档节点的标签信息可以传递给相邻的词节点,词节点收集全面的文档标签信息,在文本图中充当关键的连接,最终将标签信息传播到整个文本图中。
设定GCN+Attention方法的网络层数为K,在不同K值的情况下实验,如图5。
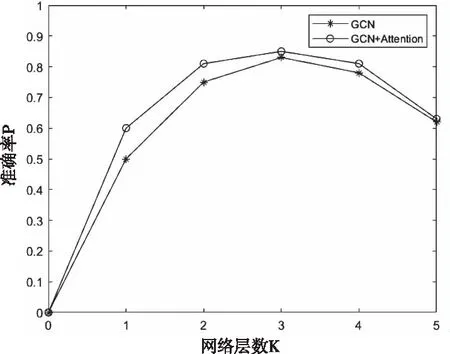
图5 不同K值分类方法的表现
不同K值的分类方法表现不同的分析如下:
图卷积神经网络中文本图的建立需要考虑到语料库中所有单词的信息,建立这些单词之间以及文档与单词之间的联系本身需要消耗大量的资源,而如果网络层数过多会导致计算更加复杂,文本表示也更加抽象,使得每个节点的词嵌入更加靠近,对后面文本图的节点分类产生干扰。
与卷积神经网络[13]类似,图卷积神经网络的卷积核类似于一个滑动的窗口,设窗口大小为H。在不同K值,不同H值的情况下实验,其准确率见表3。

表3 不同K值,不同H值的准确率

表4 标准偏差
根据表3的数据,计算当K为固定数值,H分别为5,10,15时两种方法的标准偏差以及计算当H为固定数值,K分别为1,2,3时两种方法的标准偏差,得到标准偏差数据,见表4。其中,计算标准偏差的公式为
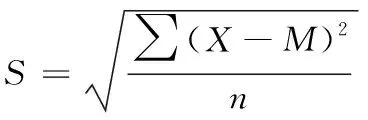
(12)
其中,S为标准偏差,X为样本数值,M为样本平均数,n为样本数。
通过分析表3和表4得到的实验数据,可以得到如下结论:
1)不管K与H为何值,GCN+Attention方法均比GCN方法的准确率高,引入Attention机制之后提高了分类的准确率。
2)当K值为固定数值时,取H为5,10和15,其S值较小,P值波动较小;当H为固定数值时,取K为1,2,3,其S值较大,P值波动较大。所以,GCN+Attention方法中网络层数(K值大小)的影响要比滑动窗口(H的大小)的影响要大。
分析得到以上结论的可能原因如下:
图卷积神经网络的本质也是卷积神经网络的一种,而卷积神经网络的卷积核大小一般都是由经验值设定的,但是网络的层数却不是由经验值所确定,He K等人将ResNet网络[14]的层数设计到了152层,但是卷积核的大小却没有设计的相对较大。
最后,选择最佳的K值与H值(K=3,H=10),实验5次取平均之后的准确率,如图6。SVM、KNN、TF-IDF、GCN和GCN+Attention方法分别用不同的填充图案表示,GCN+Attention的方法表现良好。

图6 各种分类方法的准确率
4 结束语
传统的文本分类方法普遍存在分类准确率不高的问题,针对此问题,本文提出了一种结合GCN与Attention机制的文本分类方法。与传统文本分类方法不同,GCN+Attention机制的文本分类方法是将整个语料库构建成一个大型异构文本图,并将文本分类问题转化为节点分类问题,有效避免了人工特征工程。仿真结果表明,本方法实现了较高的准确率,但需要注意的是,GCN+Attention的方法在文本分类问题中网络层数不宜设置过大。
文本分类的应用前景十分广阔,但也面临着许多挑战。未来针对文本分类的研究还可以从以下几个方向进行:①短文本数据例如微博评论、视频弹幕、手机短信等形式的迅速扩增,短文本数据分类难度增大,这给文本分类领域带来了更多的机遇与挑战。②图卷积神经网络正处于迅速发展阶段,可以尝试将图卷积神经网络与其它神经网络相结合来解决文本分类领域的问题。③虽然提出的分类方法提高了准确率,但这是在牺牲时间成本的前提下实现的,如何在保证准确率的前提下缩短时间是未来的研究方向。
