HXDSP异构计算框架的设计与优化
2022-01-21宁成明蔡恒雨郑启龙
宁成明,蔡恒雨,郑启龙,2,耿 锐
1(中国科学技术大学 计算机科学与技术学院,合肥 230026)2(中国科学技术大学 高性能计算安徽省重点实验室,合肥 230026)3(安徽芯纪元科技有限公司,合肥 230088)
1 引 言
随着信息化的发展,CPU在处理海量数据时遇到越来越多的性能瓶颈,而且由于多核心处理器的结构复杂,功耗过高使得仅仅增加CPU的核心数无法解决CPU所面临的性能瓶颈[1].在这样的背景下,通过使用CPU与多种计算设备互联组成的异构计算系统加速计算任务已经成为并行计算领域的研究热点之一.
HXDSP系列处理器是由中国电子科技集团公司第三十八所在单核BWDSP100处理器基础上自主研制的双核DSP处理器.每个处理器核都采用分簇架构,最大工作频率为500Mhz,能达到30GOPS和8GFMACS的运算能力,可以满足多种高性能计算领域的需求.设计面向HXDSP的异构计算框架能够充分利用HXDSP的优势,发挥HXDSP的高效计算能力,提高异构系统的处理性能.尤其是在信号处理[2],深度学习[3],数据分析[4]等应用领域,大量的数据和密集的计算迫切需要异构加速.因此设计面向HXDSP的异构计算框架具有重要的学术价值和实用价值.
目前,国际上针对不同的异构系统提出了许多异构并行编程模型,主要有CUDA[5],OpenCL[6],C++AMP[7],OpenACC[8]等,其中CUDA和OpenCL应用最为广泛.虽然CUDA和OpenCL的目标都是通用并行计算,但是也存在着明显的差异.首先,在通用性方面,CUDA由NVIDIA提出并且只能运行在NVIDIA的GPU上,对于其它厂商的计算设备无法适用.OpenCL是由Khronos Group提出的一个跨平台的异构计算的工业标准,是一个面向异构系统的开放的,通用的标准.OpenCL通过将硬件平台层以及存储器模型进行抽象,在软件层面弥补了不同平台设备间的差异,从而使得OpenCL可以支持所有异构系统.其次,在易用性方面,由于CUDA有一套完整的工具链以及丰富的库的支持,使得CUDA在开发使用方面更加方便.然而,OpenCL为了支持不同类型的计算设备暴露了过多的底层硬件细节,增加了编程人员的负担.最后,在性能方面,OpenCL和CUDA各有优点,CUDA在数据并行方面占有优势,而OpenCL在任务并行方面的优势是CUDA所没有的.为了充分发挥多HXDSP设备的计算优势,减少平台软件移植的开销,本文选择OpenCL编程标准设计完成HXDSP的异构计算框架.
在越来越多的厂商和设备支持OpenCL的同时,学术界也展开了对OpenCL的研究和应用.Singhal V在使用异构计算平台进行实时数据分析实验中对比OpenCL,pthread,OpenMP[9]和MPI[10]编程模型发现跨平台的OpenCL是异构计算环境的正确选择[11].Tu C H使用OpenCL加速Linux操作系统内核[12].Nozal R基于OpenCL设计了新的异构并行编程语言,简化异构系统编程[13].在应用OpenCL进行异构计算框架设计方面,国内外学者也做出了大量贡献.坦佩雷大学提出的pocl(Portable Computing Language)是OpenCL的一个开源实现,目前可以支持CPU,GPU等设备[14].首尔大学基于OpenCL提出了针对CPU/GPU异构集群的编程框架[15].国内相关工作包括基于OpenCL设计的面向神威太湖之光异构众核加速器的异构计算系统,提高了国产异构众核加速器的使用效率[16]以及为支持OpenCL设计的异构多核SoC平台[17]等.
本文采用OpenCL计算标准设计并实现面向HXDSP异构平台的计算框架,主要工作包括:1)设计并实现基于OpenCL的HXDSP异构计算框架;2)针对HXDSP异构系统的OpenCL应用程序进行性能优化.
2 异构系统计算框架的设计
2.1 总体设计
2.1.1 CPU/HXDSP异构系统
CPU/HXDSP异构系统如图1所示,该异构系统中包含一个CPU和一个HXDSP板块,板卡上包含4个HXDSP设备,CPU与HXDSP以及HXDSP与HXDSP之间共享一块DDR存储区域.每个HXDSP中包含两个核心,每个核心有自己的内核数据存储空间.为了使两个核心之间的数据交互更加方便,HXDSP采用NUMA的方式来实现两个核心内核数据的互访,两个核心数据存储使用统一的地址空间,但是通过DMA访问对方内核数据的速度慢于访问本地内核数据.基于RapidIO协议实现的交换芯片提供了HXDSP之间的一种快速交互方式,主要包括HXDSP之间的同步控制以及数据传输.在使用交换芯片传输数据时,最快数据传输速率为4.416Gb/s,并且使用交换芯片可以实现数据通信与数据计算并行的效果[18].

图1 CPU/HXDSP异构系统Fig.1 CPU/HXDSP heterogeneous system
设计基于OpenCL的HXDSP异构计算框架首先要确定的是OpenCL异构计算编程框架与CPU/HXDSP异构计算平台的映射关系.
2.1.2 OpenCL异构并行编程框架
OpenCL异构并行编程框架的主要包括OpenCL平台模型,OpenCL存储模型和OpenCL执行模型,这些模型之间既相互独立,又相互联系,概括了OpenCL编程框架的核心思想.
平台模型:平台模型是OpenCL对一个异构系统硬件的抽象描述.OpenCL平台模型由主机和OpenCL加速设备组成,OpenCL加速设备内部可以划分出多个计算单元(Compute Units,CU),每个计算单元内又包含多个处理单元(Processing Elements,PE),处理单元是OpenCL设备上执行计算的最小单元.
执行模型:OpenCL加速设备收到OpenCL内核任务后,根据主机端的配置自动生成一个N维的索引空间NDRange,OpenCL设备按照NDRange的组织形式并发执行.NDrange中每个工作线程称为工作项,多个工作项可以组织成工作组.当内核执行时,每个工作项映射到处理单元执行,工作组则对应计算单元.
存储模型:OpenCL将异构系统的存储抽象成具有5种层次的存储器模型.主机内存:主机可以直接使用的存储区域.全局存储器:全局存储器中的数据允许所有设备的所有工作组以及工作项进行读写访问.常量存储器:常量存储器是全局存储器中一块特殊的区域,这块区域由主机分配和初始化,对于设备而言,这块存储区域是只读的.局部存储器:局部存储对工作组是局部可见的,由一个工作组内的所有工作项共享.私有存储器:私有存储器是工作项私有的,对其他所有工作项不可见.
2.1.3 OpenCL编程框架到CPU/HXDSP异构系统的映射
通常并行计算应用程序包括数据并行应用以及任务并行应用.在数据并行应用中数据并行计算程度高,单个计算任务就能够充分利用HXDSP板卡上的计算资源.在任务并行应用中,计算任务本身的数据并行计算程度低,但是计算任务间并行程度高,此时可以将多个可以并行的计算任务同时部署到不同的HXDSP上执行.由于在OpenCL命令队列顺序执行的模式下,OpenCL计算设备一次只能执行一个内核任务,为了充分利用HXDSP计算资源并减少能耗,本文针对不同的应用场景设计了一种可配置的映射方式.一种适用于数据并行执行模式,该配置将整个HXDSP板卡作为一个OpenCL设备,充分利用板卡上的计算资源做数据并行计算.一种适用于任务并行执行模式,该配置中HXDSP作为计算设备,每个HXDSP可以同时执行不同的计算任务.第3种配置将板卡上的HXDSP0和HXDSP1作为一个OpenCL设备,HXDSP2和HXDSP3作为另一个OpenCL设备,该配置兼顾了数据并行执行模式以及任务并行执行模式.
平台模型到CPU/HXDSP异构系统的映射:OpenCL平台模型中定义了主机,设备,计算单元以及处理单元.在3种配置模式中,HXDSP处理器核作为HXDSP中最基本的处理单元对应OpenCL处理单元,由两个处理器核组成HXDSP对应OpenCL的计算单元.3种配置中不同的是OpenCL设备的映射关系,在第一种配置中OpenCL设备映射为HXDSP板卡,该设备中包含4个计算单元;在第二种配置中OpenCL设备映射为HXDSP,每个设备中仅包含一个计算单元;在第3种配置中将HXDSP0和HXDSP1作为一个OpenCL设备,HXDSP2和HXDSP3作为另一个OpenCL设备,每个OpenCL设备中包含两个计算单元.平台模型的映射方式如图2所示.
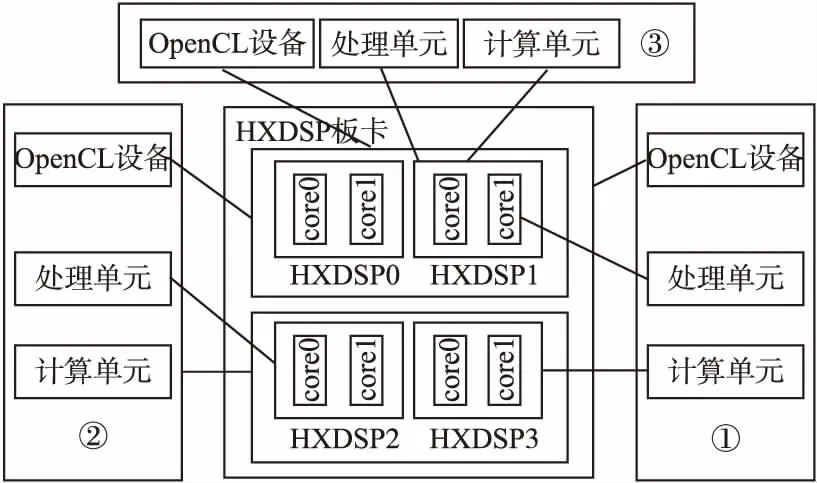
图2 3种配置下的平台模型映射方式Fig.2 Platform model mapping methods under three configurations
执行模型到CPU/HXDSP异构系统的映射:在OpenCL执行模型中定义了工作组和工作项,工作组执行在计算单元上,工作项执行在处理单元上.在3种配置中,每个工作组映射到一个HXDSP上执行,每个工作项映射到HXDSP中的处理器核上执行,区别在于,当OpenCL设备包含多个计算单元时,内核任务可以包含多个工作组在多个计算单元即HXDSP上执行.当OpenCL设备仅包含一个计算单元时,每个内核任务只能包含一个工作组在一个设备即HXDSP上执行.工作项ID与处理核的映射关系如表1所示.
表1 工作项ID与处理核的映射关系
Table 1 Mapping relationship between work item ID and processing core
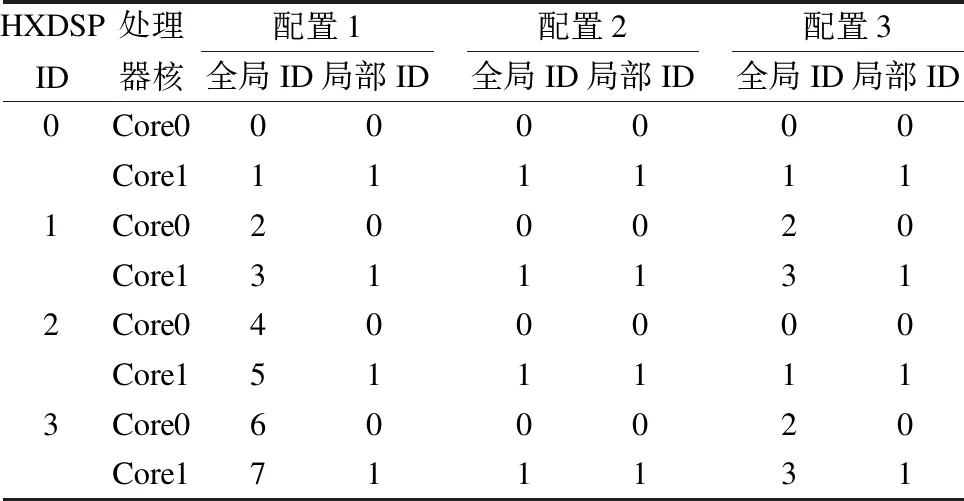
HXDSPID处理器核配置1全局ID局部ID配置2全局ID局部ID配置3全局ID局部ID0Core0000000Core11111111Core0200020Core13111312Core0400000Core15111113Core0600020Core1711131
存储模型到CPU/HXDSP异构系统的映射:在CPU/HXDSP异构平台下,本文将共享存储的一部分存储空间作为主机内存,将共享存储中剩下的存储空间作为全局存储器提供给HXDSP平台使用.按照HXDSP内核数据的访问方式,本文将私有存储器映射到每个核心的内核数据存储空间,同时由于每个核内的数据存储空间也能够通过DMA的方式被另一个核所访问,故也将内核数据存储空间作为局部存储器供两个处理单元访问.存储模型的映射在3种配置模式中是一致的.
根据OpenCL到CPU/HXDSP异构系统的映射关系,本文设计的CPU/HXDSP异构系统运行时内存布局示意图如图3所示.
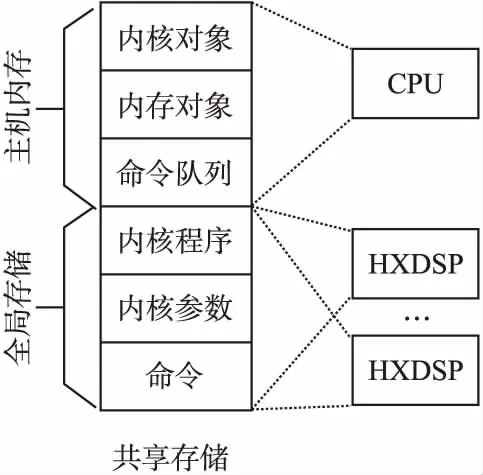
图3 CPU/HXDSP异构系统运行时内存布局Fig.3 CPU/HXDSP heterogeneous system runtime memory layout
本文将共享存储分为两部分,一部分作为CPU内存用来保存OpenCL应用程序数据,剩下的一部分作为HXDSP平台的全局存储用来保存OpenCL内核程序执行相关数据.HXDSP执行内核任务所需要的内核程序以及内核程序参数数据均需要从主机内存拷贝到全局存储中,然后才能被HXDSP访问.
2.1.4 CPU/HXDSP异构系统编译运行时设计
本文根据OpenCL异构并行编程框架到CPU/HXDSP异构平台的映射关系设计CPU/HXDSP异构系统编译运行时框架如图4所示.
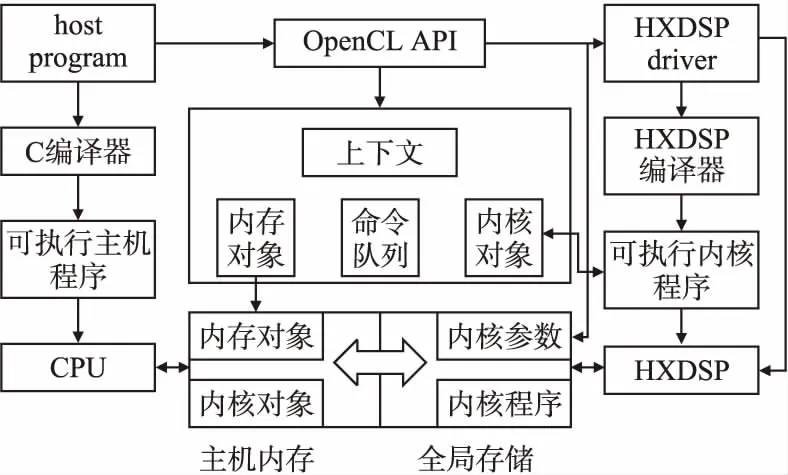
图4 CPU/HXDSP异构系统编译运行时框架Fig.4 CPU/HXDSP heterogeneous system compilation runtime framework
异构系统编译环境包括OpenCL主机端编译环境和OpenCL内核程序编译环境.OpenCL主机端编译环境使用C编译器编译OpenCL应用程序生成CPU上可执行文件.OpenCL内核程序编译环境使用基于LLVM的HXDSP编译器编译内核程序生成HXDSP上的可执行程序.OpenCL主机端程序通过HXDSP设备驱动层调用HXDSP编译程序在线编译内核程序.
CPU/HXDSP异构系统运行时分为主机端运行时和设备端运行时.主机端运行时执行在CPU上,包括OpenCL应用层和HXDSP设备驱动层.设备端运行时执行在HXDSP上.OpenCL应用层负责创建并调度内核任务,HXDSP设备驱动层为主机访问全局存储以及主机与HXDSP之间的通信提供服务,HXDSP设备运行时主要负责加载内核任务并执行.
OpenCL应用层由OpenCL语义规范定义,本部分的重点在于HXDSP设备驱动层的设计以及HXDSP设备端运行时的设计.
2.2 HXDSP设备驱动层
HXDSP设备驱动层主要为OpenCL应用层提供服务.包括主机对全局存储的使用,主机与HXDSP设备之间的通信等服务.相关的主要接口定义如下:
void* share_alloc(size_t size):在全局存储中申请size大小的空间,并返回共享存储物理地址.
void share_free(void* share_ptr,size_t size):释放全局存储空间.
void share_write(void* share_ptr,void* host_ptr,size_t size):主机将数据写到全局存储.
void share_read(void* share_ptr,void* host_ptr,size_t size):主机从全局存储读取数据.
void compile(int target,char*src):编译内核程序.
void wait_event(event e):主机等待事件完成.
void submit(queue cq,command* node):主机向设备提交命令.
OpenCL应用层与HXDSP设备驱动的主要调用关系如图5所示.
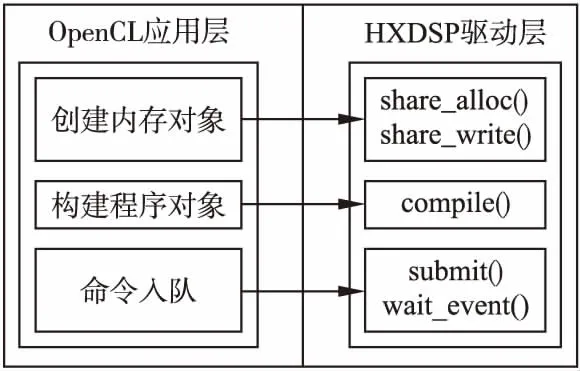
图5 OpenCL应用层与HXDSP设备驱动层调用关系Fig.5 Calling relationship between OpenCL application layer and HXDSP device driver layer
2.3 HXDSP设备端运行时设计
HXDSP设备端运行的程序包括两部分,一部分为HXDSP设备端运行时程序,一部分为OpenCL内核程序.HXDSP设备端运行时主要负责对命令队列中的命令解析以及创建内核任务执行环境,OpenCL内核程序则负责具体任务的执行.
当OpenCL设备包含多个计算单元时,首先选择其中一个计算单元中的一个处理器核作为Master负责控制OpenCL设备中的其它计算单元即HXDSP并与CPU进行通信.当CPU提交任务到命令队列中后,CPU通知Master任务到达,Master对命令进行解析,然后根据解析后得到的内核任务执行配置信息通过交换芯片的send()接口根据HXDSP ID将解析后的数据发送给相关的HXDSP,接着HXDSP便开始创建内核任务执行环境及执行内核任务,并调用wait()接口等待其它HXDSP同步信号.当HXDSP上内核任务执行完成后,HXDSP通过signal()接口向Master发送同步信号告知HXDSP上的内核任务完成,由于此时的HXDSP可能只是完成了整个内核任务的一部分,所以Master需要验证整个内核任务的完成状态,在验证之后通知CPU或是从命令队列中选择下一个命令.
当OpenCL设备中仅包含一个计算单元时,此时HXDSP作为OpenCL设备单独与CPU进行通信,各个HXDSP从各自的命令队列中读取命令,创建内核执行环境并执行内核程序.
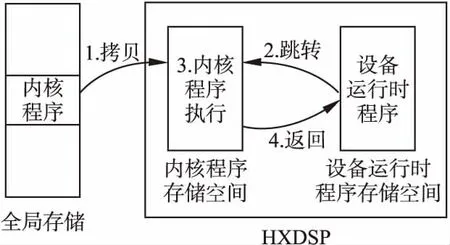
图6 内核程序加载与执行示意图Fig.6 Kernel program loading and execution diagram
创建内核执行环境包括准备内核参数以及加载内核程序.准备内核参数指的是根据HXDSP应用程序二进制接口将全局存储器中内核参数地址与内核程序对应的参数寄存器相关联.加载内核程序时,为了支持OpenCL内核程序的动态加载,本文将HXDSP的片内共享程序存储空间分为两部分,一部分用来加载HXDSP设备端运行时程序,一部分用来加载OpenCL内核程序.在OpenCL内核程序执行前由HXDSP设备端运行时程序将OpenCL内核程序从全局存储器中拷贝到OpenCL内核程序的存储空间,接着HXDSP设备端运行时程序跳转到OpenCL内核程序执行内核任务.内核程序加载方式如图6所示.
3 数据传输与数据访问优化
3.1 数据传输优化
在HXDSP异构计算平台下数据传输包含两个部分,一部分指的是主机与全局存储器之间的数据传输,一部分指的是在多任务执行模式下HXDSP之间的数据传输.对于主机与全局存储之间的数据传输,本文设计并实现了共享虚拟存储器功能.对于HXDSP设备之间的数据传输,本文设计并实现了针对HXDSP平台的通道功能.
3.1.1 共享虚拟存储器
在OpenCL1.2标准中,主机无法访问设备端的指针指向的数据,OpenCL内核程序也无法访问主机端指针指向的数据.OpenCL2.0标准使用共享虚拟存储器解决了主机与设备间关于指针类型数据访问的问题.同时,由于主机和设备可以直接使用共享指针,不需要在主机和设备间进行数据拷贝,从而减少了主机与全局存储器之间的数据传输的时间.
指针数据的共享关键在于保证指针数据在主机地址空间和HXDSP地址空间的地址一致性.共享虚拟存储器内存布局如图7所示.本文将全局存储器的一部分存储空间作为SVM缓冲区,同时在主机端开辟一段虚拟地址空间用来映射SVM缓冲区.由于HXDSP采用的是实地址访问方式,所以只需保证SVM缓冲区的物理地址与主机端的虚拟地址的一致即可.配置过程如下:
1.配置SVM缓冲区的起始物理地址svm_addr以及SVM缓冲区的大小svm_size.其中svm_addr大于0x80000000,因为DDR被映射到了HXDSP的0x80000000以上的地址空间中.
2.在主机进程地址空间中创建.svm段映射SVM缓冲区,并且配置.svm段的起始地址的大小分别为svm_addr和svm_size.
在使用时通过OpenCL定义的规范接口svmAlloc()函数检查获取空闲的SVM缓冲区并将其分配给主机进程使用.
通过这种方式不仅解决了主机与设备间关于指针类型数据访问的问题,而且主机可以直接将数据写到全局存储器中减少了数据在主机内存与全局存储器之间的拷贝时间.
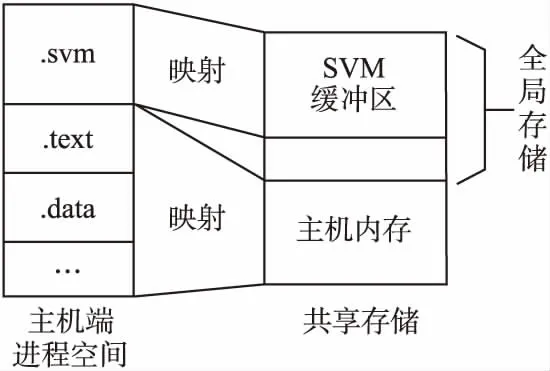
图7 共享虚拟存储器内存布局Fig.7 Shared virtual storage memory layout
3.1.2 通道
通道的作用在于提高不同内核任务之间的通信效率,在任务并行执行模式下,内核任务执行在各个HXDSP上,内核任务间的通信等价为不同的HXDSP之间的通信.本文设计基于交换芯片的通道功能实现在不同的HXDSP之间的快速通信.
首先为了避免通道数据与其他程序数据的冲突,需要在每个HXDSP的内存空间中申请固定的通道缓冲区用来保存通道数据.由于HXDSP平台上包含4个HXDSP设备,所以在每个HXDSP内存中需要创建3个通道缓冲区用来保存来自其它3个HXDSP的通道数据.内核程序在计算完成后将计算的结果通过write_channel()函数根据HXDSP ID发送到指定HXDSP中的通道缓冲区中.接受方通过read_channel()函数根据发送方HXDSP ID从通道缓冲区中获取通道数据.write_channel()函数基于交换芯片提供的发送数据功能实现,最高的数据发送速率为4.416Gb/s.
本文设计的通道的优点在于需要进行数据通信的HXDSP设备无需依赖共享存储采用读写拷贝的方式进行数据通信,可以使用通道进行HXDSP内存到HXDSP内存的数据传输,从而减少了OpenCL内核任务间数据通信的代价.由于发送方在发送数据时不需要接受方阻塞接受,对于接受方而言,可以达到数据预取,数据接收与任务计算并行的效果.
3.2 数据访问优化
数据访问优化指对DDR全局存储器访问优化.通常HXDSP访问片内存储只需要1~2个时钟周期,而访问全局存储器DDR可能需要几十甚至上百个周期,并且HXDSP内部没有数据缓存,因此如果内核任务频繁访问全局存储器会严重影响到程序的性能.为了优化HXDSP对全局存储器的访问,可以在内核任务执行前先将内核的参数数据从全局存储器拷贝到局部存储器即HXDSP的片内存储,然后再执行内核任务.内核任务计算完成后将计算结果拷贝到全局存储器中,从而减少内核任务对全局存储器的访问次数.
4 实验及评估
实验过程主要是对HXDSP异构计算框架性能进行分析.实验环境为Intel Core i5-2400 CPU @ 3.10Hz × 4,HXDSP虚拟平台和BWDSP模拟器.HXDSP虚拟平台是对CPU/HXDSP异构系统的软件模拟,在该虚拟平台中模拟实现了4个HXDSP,并且通过RapidIO协议实现了HXDSP之间的快速通信.BWDSP模拟器是对HXDSP执行核心的软件模拟,BWDSP模拟器能够在Linux系统环境下模拟执行HXDSP端可执行代码.实验在HXDSP虚拟平台上对本文设计的HXDSP异构计算框架进行评估分析.由于BWDSP的模拟器只能模拟使用片内存储,无法提供对片外存储DDR的访问,本章实验参照BWDSP对DDR的配置,以DDR的访存延时[19]分析BWDSP模拟器对DDR访问时间.DDR的访存延时参照公式(1)和公式(2)进行估算,公式(1)为读访存延迟,公式(2)为写访存延时.
latency_read=tRP+tRCD+tCL+tBURST
(1)
latency_write=tRP+tRCD+tBURST+tWR
(2)
其中tRP为Bank为下一次行激活准备进行的预充电时间,tRCD为行激活到列获取命令发送延迟,tBURST为数据在数据总线上BURST传输时间,tCL为列地址读操作潜伏期,tWR为写回延迟.
以DDR3-1333为例,DDR的数据位宽为64位,突发长度BL设置为8.在BWDSP工作频率为500MHz的情况下,tRP设置为7个时钟周期,tRCD设置为7个时钟周期,tCL设置为7个时钟周期,tWR设置为8个时钟周期,tBURST为突发传输长度的一半即4个时钟周期,计算DDR的读访存时延结果为25个时钟周期,写访存时延结果为26个时钟周期.
在使用DMA在DDR与片内存储进行连续拷贝时,一次突发传输可以传输16个字,只有前两个字需要DDR读写访存延迟,剩下的每两个字只有传输时延tBURST.由此可以估算采用DMA连续传输时每读16个字需要53个时钟周期,每写16个字需要个54时钟周期.
4.1 基本性能评测实验
本节实验以向量加法为例测试HXDSP异构计算框架的基本性能,实验结果如表2所示.
本节实验在HXDSP异构计算平台上测试的异构计算程序性能指标包括数据传输时间、内核编译时间、创建执行环境的时间以及内核任务执行时间.数据传输时间指的是主机将参数数据写到全局存储以及从全局存储中读取结果的时间.内核编译时间指的是在主机端动态编译内核程序的时间.创建执行环境的时间指的是主机端配置内核任务执行环境以及设备端创建内核任务执行环境的时间.内核任务执行时间指的是内核程序在仅使用一个HXDSP处理器核执行的时间.其中内核编译时间及创建执行环境的时间为平均时间.通常使用异构计算并行编程框架一方面会带来内核任务执行效率的提升,另一方面也会带来一些额外的时间开销.内核任务执行效率的提升主要来自于在异构并行编程模型下使用多个处理器核同时执行内核任务.额外的时间开销主要包括数据传输时间,动态编译内核程序的时间以及创建执行环境的时间.若要使得异构并行编程模型下的程序性能高于传统编程模型下的程序性能,那么内核任务提升的效率必须要大于额外的时间开销.
表2 基本性能评测实验
Table 2 Basic performance evaluation experiment

向量长度数据传输时间内核编译时间创建执行环境的时间内核任务执行时间200036us141us224us540us400081us141us224us1080us6000102us141us224us1620us8000129us141us224us2160us
4.2 数据并行实验
实验以向量加为例,将向量加内核任务部署在HXDSP板卡上使用4个HXDSP同时执行,分析异构计算并行编程模型使用数据并行执行模式在HXDSP异构计算平台上运行的程序性能.并将异构计算并行程序性能与传统编程模型下程序在HXDSP上运行的程序性能对比,分析程序在两种不同编程模型下的性能差异,实验结果如表3所示.
表3 数据并行向量加法实验
Table 3 Data parallel vector addition experiment
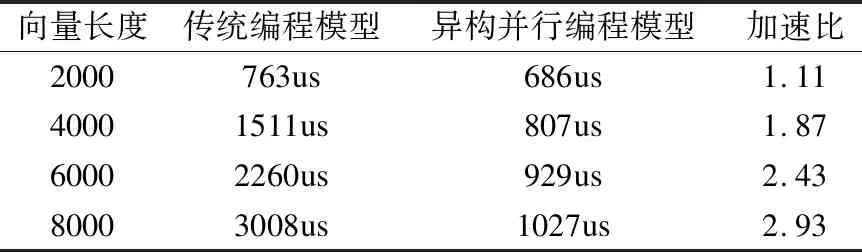
向量长度传统编程模型异构并行编程模型加速比2000763us686us1.1140001511us807us1.8760002260us929us2.4380003008us1027us2.93
实验使用4个HXDSP八个处理器核并行执行内核任务,理论上程序性能的提升效率应接近8倍.但是从表3的实验结果中得知实验中程序性能的加速比最大只有2.93.原因在于向量加运算本身耗时较少,使得内核任务提升的效率与使用异构计算并行编程带来的时间开销的比值较小.
4.3 多任务并行实验
实验2是采用数据并行执行模式,单个内核任务在HXDSP板卡上的实验.对于内核任务并行程度低,但是多个内核任务间可以并行执行时,CPU/HXDSP异构计算平台依然能够利用多任务并性模式充分发挥平台的计算能力.本节实验以矩阵乘加为例分析任务并行执行模式下的程序性能,矩阵乘加的计算公式为RES=A×B+C×D.其中RES,A,B,C,D为5个N×N的矩阵.实验过程包含3个内核任务,两个矩阵乘内核任务分别计算A×B和C×D,一个矩阵加内核任务负责对两个矩阵乘的结果求和,3个内核任务分别运行在3个HXDSP上.实验中两个矩阵乘的内核任务分别在两个HXDSP上并行执行,并且每个内核任务都采用两个核心计算,理论上当数据量增大,矩阵运算成为程序性能瓶颈时加速比应接近4,实验结果如表4所示.
表4 多任务并行矩阵乘法实验
Table 4 Multi-task parallel matrix multiplication experiment

矩阵维度N传统编程模型异构并行编程模型加速比10930us1102us0.84206664us2446us2.723021662us5992us3.624050336us12881us3.90
从实验结果可知,随着数据量的不断增大,加速比不断增加,实验结果最好的加速比为3.90,符合理论预期的结果.同时,由于HXDSP异构计算平台包含4个HXDSP,根据实验结果可以预测当有多个可以并行执行的内核任务时,若充分利用4个HXDSP,那么理论上最大的程序性能加速比应趋近于8.
4.4 数据传输与数据访问优化
本节实验在数据并行实验和多任务并行实验的基础上对异构计算平台程序进行数据传输与数据访问优化.
在对数据并行实验进行优化时,首先在主机端使用共享虚拟存储器减少主机与全局存储器之间数据传输的过程,然后在HXDSP板卡执行内核任务计算之前由每个HXDSP使用两个处理器核并行地将两个参数数据从全局存储器中拷贝到局部存储器即HXDSP片内存储,之后再执行内核任务,减少内核任务对全局存储器的访问次数,实验结果如表5、表6所示.
表5 向量加实验优化结果
Table 5 Vector add experimental optimization results

数据量优化前优化后加速比2000686us638us1.084000807us702us1.156000929us792us1.1780001027us851us1.21
表6 向量加数据传输与数据访问优化时间
Table 6 Vector add data transmission and data optimization time

数据量数据传输优化的时间数据访问优化的时间数据拷贝消耗的时间200036us25us13us400081us50us27us6000102us75us40us8000129us100us53us
多任务并行实验使用了3个HXDSP执行3个内核任务包括两个矩阵乘内核任务和一个矩阵加内核任务,两个矩阵乘内核任务并行执行.在对实验3进行优化时,针对矩阵乘内核任务,首先将内核任务所需的两个参数由HXDSP的两个处理器核并行地从全局存储拷贝到局部存储,然后再执行矩阵乘计算,最后将计算结果以通道的方式发送到矩阵加内核任务所在HXDSP设备的通道数据缓冲区.对于矩阵加内核任务首先从管道中读取数据,然后执行计算任务,最后将计算结果拷贝到全局存储器中.同样地,本次实验在主机端使用共享虚拟存储器减少主机与全局存储器之间的数据拷贝时间,实验结果如表7、表8所示.
表7 矩阵乘实验优化结果
Table 7 Matrix multiplication experiment optimization results

矩阵维度N优化前优化后加速比101102us977us1.13202446us1586us1.54305992us3181us1.884012881us6280us2.05
表8 矩阵乘数据传输与数据访问优化时间
Table 8 Matrix multiplication data transmission and data optimization time
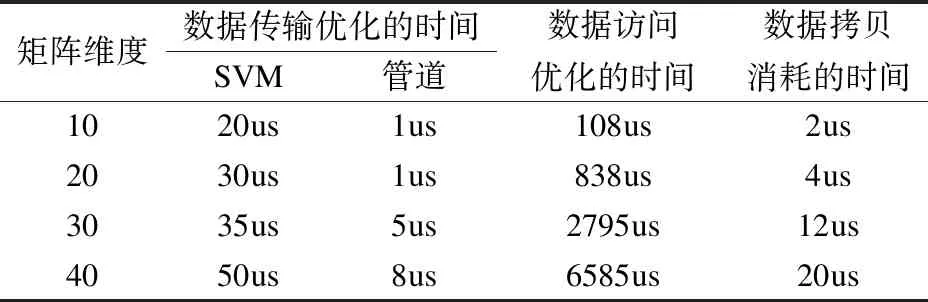
矩阵维度数据传输优化的时间SVM管道数据访问优化的时间数据拷贝消耗的时间1020us1us108us2us2030us1us838us4us3035us5us2795us12us4050us8us6585us20us
从实验数据可知,数据传输量越大,全局存储器访问次数越多,相应的数据传输优化以及全局存储器访问优化的结果越好,实验结果最好的加速比为2.05,相对于传统编程模型下的程序性能加速比为8.02.实验结果表明,数据传输优化和全局存储器访问优化可以有效的提高程序性能,在使用HXDSP异构计算平台时应重点关注数据传输与全局存储器访问对程序性能的影响.
5 总 结
本文采用OpenCL异构并行计算规范设计并实现了面向CPU/HXDSP异构系统的异构计算框架.针对不同的并行计算应用场景,设计了不同的OpenCL设备映射方式.在HXDSP异构计算框架完成的基础上,本文针对CPU/HXDSP异构系统OpenCL应用程序进行性能优化,包括数据传输优化以及数据访问优化.针对主机与全局存储之间的数据传输本文设计了共享虚拟存储器进行优化,针对HXDSP之间的数据传输本文设计了基于交换芯片的通道进行优化.根据全局存储与局部存储的访问效率不同本文针对全局存储访问进行优化.
本文通过实验评估了CPU/HXDSP的基本性能,并将OpenCL应用程序与传统编程模型下程序性能对比,证明了HXDSP异构计算框架的可行性并且能有效地提升程序性能.在未来的工作中可以针对OpenCL内核任务的调度进行优化以进一步提升OpenCL应用程序的性能.
