基于循环神经网络的多阶段图像去噪方法
2022-01-21林煌伟陈钧荣牛玉贞
林煌伟,陈钧荣,牛玉贞,2
1(福州大学 数学与计算机科学学院,福州 350105)2(空间数据挖掘与信息共享省部共建教育部重点实验室,福州 350105)
1 引 言
近年来,随着科技的进步和拍摄设备的普及,人们越来越倾向于用图像来获取信息,但是在图像的采集过程中,常常由于相机抖动、信号扰动等一些外界因素的干扰,导致捕获到的图像质量不佳,出现噪声以及细节丢失等问题,极大的影响了对图像后续的分析处理工作,这就要求对质量不佳的图像进行重建来恢复出高质量的图像内容.
为了解决上述问题,研究者们提出了许多图像重建的方法,图像去噪就是针对图像中出现噪声的问题提出的,研究内容为从一张含有噪声的低质量图片中通过一些技术手段重建恢复出高质量的无噪声的图像.图像噪声有很多种,主要被分为高斯白噪声、椒盐噪声、泊松噪声、脉冲噪声和真实噪声等[1],如图1所示,图1(a)、图1(b)为含有噪声的图像,可以看出,噪声图像中纹理细节丢失严重,导致图像模糊不清.目前,研究者们对图像去噪的研究方法可大体分为两类,即传统的方法和基于深度学习的方法.
常用的传统去噪方法有空域像素特征去噪算法[1-3],变换域去噪算法[4-6]以及结合空域和变换域的去噪算法[7]等.这些传统的去噪方法往往计算复杂且存在纹理丢失等问题,导致无法应用到实际生活中.近年来,随着深度学习的发展,越来越多的基于卷积神经网络的图像去噪方法被提出,成为了目前去噪任务的热门研究方向.基于深度学习的方法就是设计一种合理的去噪方法,然后通过搭建深度学习网络,再使用训练数据集进行网络训练,得到最优的网络模型参数,即可用于图像去噪任务.

图1 噪声图像示例图Fig.1 Example images of noisy images
然而目前现有的基于深度学习的图像去噪方法往往只进行一次性的去噪过程便输出结果,这就容易出现噪声未去除干净或者去噪结果过于平滑,导致细节纹理丢失严重等问题,且无法逆转.针对这个问题,本文提出了一种基于循环神经网络的多阶段图像去噪方法,该方法包括两个去噪阶段,通过调整两个阶段的训练权重可以使得第1个阶段的去噪结果包含部分未去除干净的噪点和更多细节信息,然后将第1阶段提取的特征通过门控循环单元[8](Gated Recurrent Unit,GRU)传递到第2阶段,再进行第2个阶段的去噪.此外,本文还设计了一个估计噪声分布的子网络和一个去噪子网络,噪声估计子网络用于从噪声图像中估计噪声的分布,并将噪声分布和噪声图像拼接,作为网络的输入来训练去噪子网络.通过实验结果表明,本文的基于循环神经网络的多阶段图像去噪方法具有先进的去噪性能.
2 相关工作
2.1 传统去噪方法
图像去噪作为一项重要的图像处理技术,已经有很多经典的方法被提出,传统的去噪方法有空域像素特征去噪算法[1-3]:利用含有噪声图像的像素点与周围的像素点之间的关系进行去噪,一般用滤波器来实现,常见的有均值滤波[9],中值滤波[10]、双边滤波[11]等,然而这些滤波器计算像素的过程中,缺少整体像素间的关系,容易引入一些不恰当的纹理信息使得去噪结果不佳.其次,变换域去噪算法[4-6]将原始图像中相互依赖的图像信息映射到变换域上,使得图像信息与噪声信息相互分离,便可将噪声信息过滤掉,完成图像去噪.常见的变换域方法有小波变换[12]和傅里叶变换[13].除此之外,还有结合空域和变换域的去噪算法[7],结合了之前两种传统方法,典型的代表算法有BM3D[14]算法,效果相比之前的算法好,但是由于其时间复杂度较高且存在纹理丢失等问题,无法直接应用到实际生活当中.
2.2 基于深度学习的去噪方法
随着深度学习在计算机视觉领域取得的强大的效果提升,越来越多的研究者提出将基于深度学习的方法用来解决图像去噪问题.例如:Burger等人[15]提出的使用3层神经网络的CNNs方法,在性能上与BM3D算法媲美,且在处理速度上大幅提升,这是最早的将深度学习方法用于图像去噪的研究工作.Mao等人[16]提出了一个基于编码器-解码器的端到端网络,使用编码解码结构以及跳级连接有效地解决了梯度消失和过拟合问题.Zhang等人[17]提出的结合残差学习和批归一化操作的深度网络,可以使训练更加稳定高效.Liu等人[18]提出的基于空洞卷积的多尺度去噪算法,可以扩大感受野,提升算法性能.虽然这些基于深度学习的方法可以达到不错的去噪性能,但是这些方法往往只进行一次去噪便得到结果,会导致一些去噪结果过于平滑或者噪点未被清除干净的问题,且结果无法逆转.
针对以上问题,本文引入了循环神经网络(RNN)[19],它是一种特殊的深度学习网络结构,与常见的深度学习网络不同的是,它的每个时刻的输入输出都与之前时刻的输入输出相关联,由于这种特殊的性质,使得深度网络可以有前馈神经网络结构以及循环反馈的网络结构,可以用来处理更加复杂的深度学习任务.但是RNN在保存长期依赖关系上经常出现梯度消失和梯度爆炸等问题,对此研究者们提出了广泛使用的长短期记忆单元(LSTM)[20].
LSTM单元可以保留长序列中对当前输出有帮助的信息,并过滤掉冗余无效的信息,文本引入GRU模块[8],它是一种特殊的LSTM,相比LSTM单元下少了输出门,减少了参数量,适用于处理次数较少的循环任务.本文将GRU模块作为网络中一个核心模块,结合循环多阶段去噪过程,可以学习到前后阶段的依赖关系,从而达到更好的去噪效果.
3 本文方法
本文提出的基于循环神经网络的多阶段图像去噪方法,即IterNet,其网络模型如图2所示.网络将去噪过程分为两个阶段,并且每个阶段都要经过两个子网络,即一个噪声估计子网络和一个去噪子网络,并在网络中加入了GRU模块,用于将前一阶段的噪声估计子网络的特征和去噪子网络的特征传递到下一阶段,具体实施步骤如下:
1)IterNet的初始输入为原始噪声图像Nori,放入噪声估计子网络用来估计噪声分布,将得到的噪声分布和原始噪声图像Nori经过通道拼接后,作为去噪子网络的输入,经过去噪子网络将得到第1阶段的输出图像De1;
2)在两个网络中都嵌入GRU模块,将第1阶段中噪声估计子网络输出层的特征和去噪子网络的每个下采样层的特征分别保存在两个不同的GRU模块中,并传递给下一阶段的噪声估计子网络的输出层和去噪网络每个对应的下采样层;
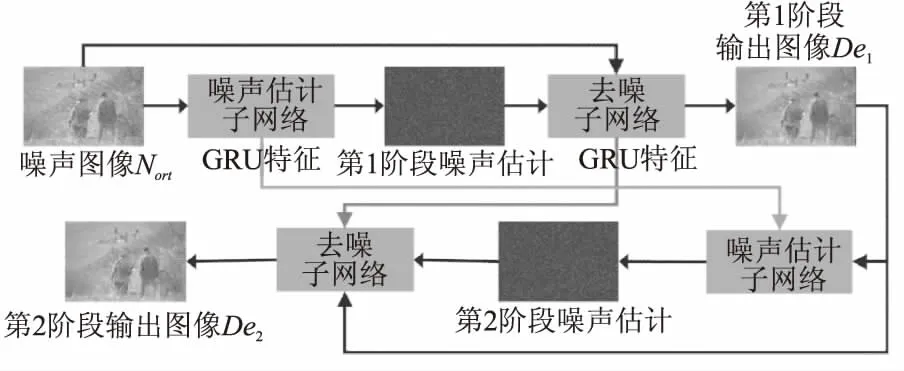
图2 IterNet网络结构图Fig.2 IterNet network structure diagram
3)使用第1阶段的输出图像De1作为第2阶段的输入图像,再经过一次噪声估计子网络得到噪声分布,并与第1阶段的输出图像De1经过通道拼接后,作为接下来去噪子网络的输入,经过去噪子网络将得到第2阶段的输出图像De2,即最终的输出图像.
3.1 噪声估计子网络
目前传统的噪声分布估计方法都存在时间复杂度较高的问题,因此本文提出了基于深度网络的噪声估计子网络.目前已经有研究者设计了深度噪声估计网络作为图像去噪的子网络,Guo等人提出的CBDNet[21]的深度去噪方法包含了两部分网络,其中一个就是噪声估计子网络.CBDNet的噪声估计子网络使用全卷积层来构建估计子网络,并在实验中证明了将估计的噪声信息作为去噪子网络的输入之一可以使去噪网络的训练更稳定.然而CBDNet的噪声估计子网络只使用简单的5层全卷积,网络的视野域较小,对噪声的估计具有局部性.因此,本文使用5个串联的残差块[23]以及GRU模块进行噪声分布的估计.图3为噪声估计子网络的结构图,噪声估计子网络的具体实施步骤为:

图3 噪声估计子网络Fig.3 Noise estimation sub-network
1)噪声图像输入噪声估计子网络;
2)噪声图像经过5个串联的ResNet残差块[23]后得到残差特征;
3)残差特征经过GRU模块并保存特征用于传递给下一个去噪阶段;
4)步骤3得到的特征经过一个卷积层压缩通道后输出噪声估计图像.
3.2 去噪子网络
在基于深度学习的图像去噪方法中,设计一个高性能的深度网络是图像去噪任务的关键.本文将选用U-Net网络[22]为基础网络,改进提出一种结合纹理损失的图像去噪子网络.
U-Net网络[22]是一个编码器-解码器结构,它在编码器-解码器对称的卷积层上加上对等连接,从而使得网络的训练能更稳定和更快捷.这种编码器-解码器结构同样可以用于图像去噪任务的研究中来[22],编码器将输入图像下采样并提取有用的特征信息,解码器可以有效地利用下采样和编码的特征重建去噪图像.由于网络中浅层的卷积层提取的特征会包含更多高频信息,但随着网络层数变深高频信息将逐渐减少,为了解决这一问题,我们的去噪子网络仅使用U-Net的前3层和后3层网络结构且保留对等连接;其次,我们在网络的中间层增加了残差模块从而提升网络的特征提取能力.具体地,去噪子网络的前3层下采样层作为编码器,中间层使用12个串联的ResNet残差块[23]作为残差模块,最后3层上采样层作为解码器以达到重建去噪图像的目的.具体改动包括:
1)下采样和上采样层的卷积核均由3×3改成5×5,从而增加网络的感受野;
2)增加残差模块,从而提升网络的特征提取能力,残差模块由12个ResNet残差块[23]组成,残差模块的输入为下采样层所提取的特征,输出为上采样层的输入;
3)在输入和输出之间加上一个全局残差连接,从而解决网络深度太深而导致的梯度消失问题;
4)在每个下采样层上嵌入一个GRU模块,经过GRU模块的计算后可以有选择性地保留有效的信息,并传递给下一个阶段.

表1 去噪子网络的详细层数表Table 1 Detailed layer number table of denoising sub-network
去噪子网络的具体网络层数如表1所示,其中编码器的激活函数均为带泄漏线性整流函数(Leaky Rectified Linear Unit,LeakyReLU),解码器的激活函数均为线性整流函数(Rectified Linear Unit,ReLU).去噪子网络中将U-Net网络分为3个部分,分别为编码器,解码器和残差模块.编码器用于对输入图像进行特征提取;残差模块接收编码器的特征,从而提升网络的特征提取能力,并将残差模块的输出作为解码器的输入;解码器用于重建去噪图像.去噪子网络的网络结构如图4所示,输入图像为噪声图像,输出图像为去噪图像,网络左半部分是编码器的特征,右半部分代表解码器的特征,中间为12个串联的ResNet残差块[23]组成的残差模块.

图4 去噪子网络结构图Fig.4 Denoising sub-network structure diagram
3.3 损失函数
为了在IterNet的训练过程中对每个阶段的输入图像进行约束和优化,我们分别对IterNet的两个阶段进行约束,并赋予不同的权重.由于L2损失函数对异常点的检测较敏感,噪声估计子网络的损失函数使用L2损失函数,去噪网络的损失函数采用最常见的损失函数L1.IterNet的去噪包括两个阶段,第1阶段具体的损失函数如公式(1)所示,第2阶段具体的损失函数如公式(2)所示.
(1)
(2)
Loss=αLstg1+Lstg2
(3)
其中,f(·)表示噪声估计子网络,g(·)表示去噪子网络,concat(·)表示通道拼接,Ngt1表示第1阶段的噪声分布参考图像,Nori表示原始噪声图像,wf和wg分别为噪声估计子网络和去噪子网络的参数,N1为第1阶段噪声估计子网络当输入为Nori时f(Nori;wf)的输出图像,即第1阶段噪声估计图像,De1为第1阶段去噪子网络当输入为Nori和N1经过通道拼接时g(concat(Nori,N1;wg))的输出图像,即第1阶段去噪图像,Ngt2为第1阶段去噪网络当输入为Nori和N1经过通道拼接时g(concat(Nori,N1;wg))的输出与参考图像的差值,N2为第2阶段噪声估计子网络当输入为N1时f(N1;wf)的输出图像,即第2阶段噪声估计图像.最终网络的损失函数Loss为公式(3),α为损失函数平衡因子,本文根据经验设为0.1.
4 实验结果与分析
4.1 实验细节
目前在图像去噪领域,广泛使用高斯噪声作为实验研究的噪声类型,本文首先使用高斯噪声作为图像的噪声.为了训练网络,我们从ImageNet数据集[24]中挑选400幅图像和BSD400的400幅训练集[25]总共800幅图像作为参考图像(无噪声图像),验证集是BSD500中除去BSD400[25]和BSD68[26]所剩下的32幅图像.训练时,使用高斯白噪声加噪的合成数据进行训练.具体地,在参考图像上加入高斯白噪声制作成参考图像和噪声图像的配对数据集,然后将参考图像和噪声图像在图像的同一位置裁剪成128×128像素大小用以训练网络,并用随机翻转和随机旋转进行数据增强,批次大小设置为5,使用Adam优化器来优化IterNet模型,并将学习率设置为2e-4,优化器超参数beta1和beta2分别设置0.9和0.99,其它设置为默认设置.训练的轮次设置为3000,最终得到的模型为训练时在验证集上取得的性能最好的模型.去除高斯白噪声实验选取BSD68[26]数据集作为测试数据集进行测试.本文代码均使用PyTorch深度学习框架.
4.2 去除高斯白噪声实验
首先,我们在高斯白噪声环境下进行实验,为了验证IterNet的去除高斯噪声的性能,我们在测试集BSD68[26]上与其它方法进行对比实验.具体而言,我们将IterNet方法与去噪性能较好的传统方法BM3D[14]和近年来基于深度学习的去噪方法EPLL[27]、WNMM[28]、DnCNN[29]和NNLNet5[30]进行了对比.表2为不同方法在测试集BSD68[26]上的PSNR值对 比结果,噪声幅度σ设置为5、10、15、20、25、30,其中最优结果用黑体表示.在BSD68测试集上,可以看出,无论噪声幅度为5,10,15,20,25,30时,IterNet的PSNR值都比对比方法高,比传统方法BM3D的PSNR值平均高了约0.6dB,与基于深度学习的方法相比,平均高出了约0.3dB.从总体上看,IterNet在不同的高斯噪声幅度下都具有良好的去噪性能.
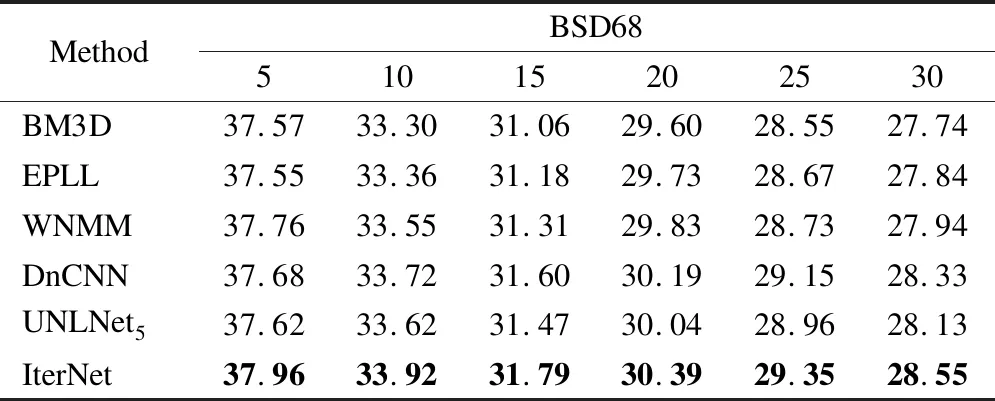
表2 不同方法在BSD68上的PSNR对比结果Table 2 PSNR comparison results of different methods on BSD68
在视觉效果对比实验中,我们所对比的基于深度学习的方法均采用和IterNet相同的训练方式,对比了包括基于深度学习的方法EPLL[27]、DnCNN[29]和NNLNet5[30]以及本文的IterNet.图5为不同方法在BSD68[26]测试集中的Test060图像的视觉效果对比图像,其中,图5(a)为左边大图中方框处裁剪下来的GT图像,图5(b)为σ=20的噪声图像,图5(c)为EPLL的去噪结果,图5(d)为DnCNN的去噪结果,图5(e)为NNLNet5的去噪结果,图5(f)为IterNet的去噪结果.从图5可以看出,EPLL、DnCNN和NNLNet5方法的去噪结果并不能很好地恢复出Test060图像中绳子的完整部分,存在一些模糊;而IterNet经过两个阶段重建出来的去噪图像能较准确地恢复出图中完整的绳子结构,图像在视觉上较为清晰,但仍存在马背上花纹细节部分不够完美的问题.

图5 不同方法在σ=20的去噪视觉效果对比Fig.5 Comparison of denoising visual effects of different methods at σ=20
此外,本文还做了一个IterNet在RGB图像上的去噪性能对比实验,对比实验的对比方法包括CBM3D[14],DnCNN[29],FFDNet[31]和DHDN[32]的RGB图像去噪,表3为不同方法在测试集CBSD68[26]上的对比结果(最优结果用黑体表示),CIterNet表示IterNet的RGB版本.从整体上看,在噪声幅度为10的情况下,CIterNet的去噪性能比DHDN的去噪性能低了约0.1dB,比传统方法和最近的性能较高的其它深度学习方法性能更好;在噪声幅度为15、25和30时,IterNet的去噪性能均取得了最高的PSNR值.

图6 不同方法在CBSD68测试集中的163085图像的视觉效果对比Fig.6 Comparison of the visual effects on image 163085 in the CBSD68 test set with different methods
图6为不同方法在CBSD68测试集中的163085图像的视觉效果对比,图6(a)为左边大图的方框处裁剪下来的GT图像,图6(b)为σ=30的噪声图像,图6(c)为CBM3D的去噪图像,图6(d)为DnCNN的去噪图像,图6(e)为FFDNet的去噪图像,图6(f)为IterNet的去噪图像.从图6中可以看出BM3D产生的去噪图像几乎分不清动物的毛发和嘴角,导致一种模糊的感官效果,而DnCNN的去噪图像和FFDNet的去噪图像虽然能大致上恢复出图像的信息,但高频信息几乎完全丢失,嘴角部分与背景信息像素值重叠在一起.本文所提的IterNet方法的去噪图像与对比方法相比,能重建出清晰的动物毛发纹理和嘴角,但仍存在重建出来的图像有部分伪影的问题.

表3 不同方法在CBSD68(RGB图)上的PSNR对比结果Table 3 PSNR comparison results of different methods on CBSD68(RGB image)
综上所述,本文提出的基于循环神经网络的深度学习图像去噪方法能够有效地去除不同程度的高斯白噪声,无论在灰度图上的去噪表现还是在RGB图像上的去噪表现,从整体上看均优于现有的传统去噪方法以及最近的基于深度学习的去噪方法.我们还解决了实际视觉效果上的部分问题,即模型一次去噪产生的结果过于平滑,损失细节的问题,但仍存在一些不足,如去噪图像视觉上存在细节丢失和一定程度的模糊.
4.3 在其他噪声环境下的实验
当前很多图像去噪算法只能针对高斯噪声去除,而在其他噪声环境下算法去噪性能就会大大降低.本文方法的泛化能力较强,在其他噪声环境下也能具有很好的去噪性能,为了验证本文方法在其他噪声环境下的有效性,我们分别选取了泊松噪声和高斯-脉冲混合噪声做了实验对比.实验步骤与之前的高斯去噪实验类似,我们给图像分别添加不同类型的泊松噪声和混合噪声,合成训练数据集进行训练,最终得到最优的去噪模型.
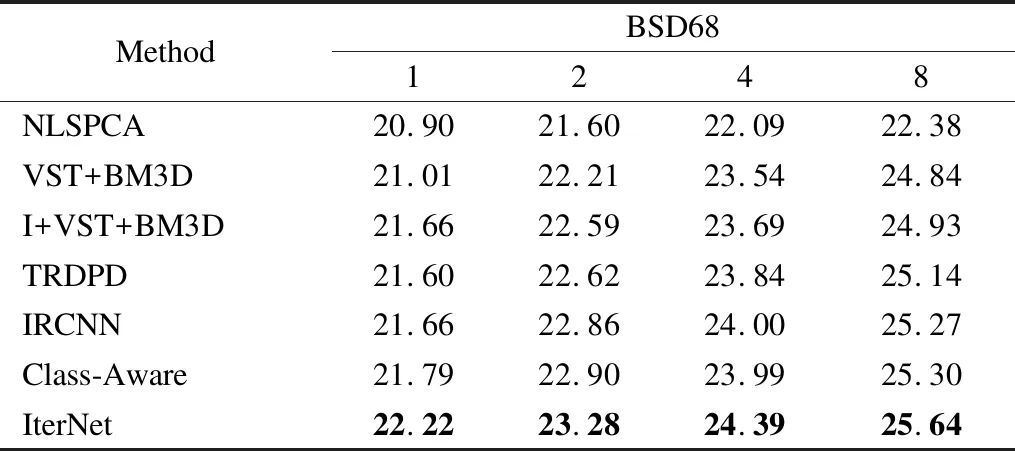
表4 不同方法去除泊松噪声的PSNR对比结果Table 4 PSNR comparison results of different methods to remove poisson noise
对于泊松噪声,与常见的加性高斯噪声不同,它是一种随机分布的噪声,我们使用图像的最大亮度峰值(peak)定义泊松噪声强度,当peak值越大,图像噪声越趋近于高斯分布,当peak值越小,图像的结构越模糊.我们在实验中分别设置了泊松噪声peak值为1、2、4、8,并在测试集BSD68[26]上与其他泊松噪声去除方法进行了对比.选取的方法包括近年来去除泊松噪声效果较好的NLSPCA[33],VST+BM3D[34],I+VST+BM3D[35],TRDPD[36],IRCNN[37]以及Class-Aware[38]方法,如表4所示,其中最优结果用黑体表示.可以看到在peak=1、2、4、8情况下,本文方法比近年来去除泊松噪声效果较好的Class-Aware方法在PSNR值上平均高出0.3dB.从总体指标上看,在不同的噪声强度下,IterNet对于去除泊松噪声的效果都优于所对比的其它方法.
另外,为了更为直观地展现模型的去噪性能,我们还做了泊松噪声的去噪视觉对比,图7为不同方法对于泊松噪声peak值为4时所得到的去噪视觉对比,图7(a)为无噪声测试图,图7(b)为peak=4时的噪声图片,图7(c)为I+VST+BM3D方法去噪结果,图7(d)为Class-Aware方法的去噪结果,图7(e)为本文所提方法的去噪结果,图下为各个图片所对应的PSNR值.可以看到,I+VST+BM3D方法虽然得到了15dB的PSNR指标提升,但是在视觉效果上模糊不清,存在较多的伪影,Class-Aware方法恢复出大部分的图像结构,但是在细节上仍存在较多不足,相比于Class-Aware方法,我们的方法不仅在指标上得到了提升,更恢复出了较多的图像细节,如图中人物嘴部细节,背景人物的手臂轮廓,本文方法比其他方法恢复出的图片更加清晰合理.

图7 不同方法在peak=4时的去噪结果的视觉效果对比Fig.7 Comparison of visual effects of denoising results of different methods at peak=4
对于混合噪声,我们选取了高斯白噪声和随机值脉冲噪声的混合噪声[39]进行实验.实验中,我们将高斯噪声σ分别设置为10、20,将随机脉冲噪声比例Ratio分别设置为0.15、0.30,合成不同程度的混合噪声图像来训练网络,并在20张灰度测试图Set20[39]上与其它去噪方法进行实验对.得到的PSNR平均值如表5所示,其中最优结果用黑体表示.我们选取了去除高斯噪声的BM3D[14],PGPD[40]方法以及专门去除高斯-脉冲混合噪声的Two Phase[41]、WESNR[42]和PGB[39]方法进行对比,可以看到在4种混合噪声强度下,我们的方法得到的PSNR值都高于所对比的方法.
综上所述,我们所提出的方法不论在泊松噪声还是高斯-脉冲混合噪声环境下都能表现出良好的去噪性能,我们的模型具有较强的泛化能力.
4.4 消融对比
为了证明循环次数对实验结果的影响以及噪声估计子网络的有效性,本节对于方法中的循环次数和噪声估计子网络分别做了消融对比实验,所用噪声为高斯白噪声.

表5 不同方法去除混合噪声的PSNR对比结果Table 5 PSNR comparison results of different methods to remove mixed noise
本文的去噪方法共包含两个阶段,即循环次数为2,我们分别验证对比了在循环次数为1、2、3、4情况下网络模型训练300轮后所得的PSNR值,表6展示了网络在不同循环次数下在数据集BSD68[26]上得到的PSNR值.其中选取的循环次数对应的列用黑体表示,IterNet-i表示循环次数为i的网络,i的取值为{1,2,3,4},可以看出,在循环次数为1时,网络在噪声幅度为15、25和50时的PSNR值均为最低,在循环次数为2、3和4时,PSNR值增益不大,仅在0.002左右,证明循环次数为2、3、4次时,网络性能相近,然而循环次数越多所耗费的时间也更多,因此,综合考虑到循环次数与网络运行效率的关系,本文将循环次数设置为2.

表6 不同循环次数在BSD68上的PSNR值对比Table 6 Comparison of PSNR values of different cycles on BSD68
其次,本文还做了有噪声估计子网络和无噪声估计子网络的消融对比实验,来验证本文所提出的噪声估计子网络的有效性.我们在数据集BSD68[26]上分别对比了无噪声估计子网络和有噪声估计子网络在噪声幅度为σ=15、25、50的情况下得到的去噪结果.其中IterNet1表示无噪声估计子网络,IterNet2表示有噪声估计子网络.如表7所示,其中最优结果用黑体表示,可以看出在噪声幅度为15、25或50时,IterNet2得到的去噪结果均比IterNet1的结果好.图8为有噪声估计子网络和无噪声估计子网络在噪声幅度σ=30的情况下的视觉效果对比,图中右侧大框是左侧小框部分的放大图像,可以看出,两个网络都有效地去除了噪声,而IterNet1的去噪结果图与IterNet2的去噪结果图相比平滑很多,损失了较多的纹理细节.

表7 无噪声估计子网络和有噪声估计子网络情况下的去噪结果对比Table 7 Comparison of denoising results with and without noise estimation sub-network

图8 噪声幅度σ=30的情况下无噪声估计子网络和有噪声估计子网络视觉效果对比Fig.8 Comparison of the visual effects with and without noise estimation sub-network when the noise σ=30
综上所述,我们所提出的噪声估计子网络是有效的,它可以为去噪子网络提供更多的噪声信息,从而使去噪子网络重建出效果更好的去噪图像.
5 结 论
本文针对现有的基于深度学习的图像去噪方法普遍存在的问题,即网络只进行一次去噪时得到的图像过于平滑或过多的噪点未被去除且结果无法逆转,提出了一种基于循环神经网络的多阶段图像去噪方法.首先,我们设计了一个噪声估计子网络,用于估计前一阶段的输出图像和参考图像之间的噪声分布;其次设计了一个去噪子网络,并在网络结构的基础上嵌入了GRU模块用于保存前一阶段去噪过程中的特征并传递给下一阶段;最后再将噪声估计子网络与去噪子网络合并成一个循环去噪网络进行两个阶段的去噪,我们的实验证明将循环次数设置为2能够获得更合理的性能表现.实验结果表明,无论在高斯噪声、泊松噪声还是高斯-脉冲混合噪声环境下,本文所提出的方法的客观评价指标在整体上均为最优的,并且视觉效果更合理,模型具有较强的泛化能力和去噪性能.
