基于决策树-逻辑回归模型精确识别僵尸企业
2022-01-19吴东鹏王峥童薇叶枫宋楚翘
吴东鹏,王峥,童薇,叶枫,宋楚翘
1.河海大学计算机与信息学院,江苏南京211100
2.河海大学商学院,江苏南京211100
僵尸企业通常被定义为自身发展能力低下、市场竞争力较弱、主要依靠政府补贴或银行贷款而生存的企业[1]。它们通常有“吸血”依赖性和长期性的特点,不仅浪费大量的资金、社会资源,还会抢占市场,并将严重阻碍中国经济的可持续发展。为了改善经济结构,提高供给效率,更好地优化市场配置,迫切需要精准地识别僵尸企业[2]。
目前,识别僵尸企业的主流方法有过度借贷法和连续亏损法[3-7],这两种方法是用于判断僵尸企业的常用方法。连续亏损法将僵尸企业表述如下:不符合国家能耗、环保、质量、安全等标准,持续亏损3年以上且不符合结构调整方向的企业[6]。过度借贷法将僵尸企业表述如下:资产负债率较高,实际经营处于亏损状态,但是外部融资规模较上年有所增加的企业[7]。文献[3]建立了倾向评分匹配(propensity score matching,PSM)模型,比较了过度借贷法、连续亏损法和FN-CHK法的有效性。文献[4]依据连续亏损法和过度借贷法识别中国A股上市公司僵尸企业,并检验了财务独立董事对僵尸企业的治理作用。文献[5]运用过度借贷法测度了中国上市公司的僵尸企业数量及其占比、证监会行业分类标准的僵尸企业行业分布及房地产上市公司中的僵尸企业状况。连续亏损法虽然能够结合中国国情,但其判断标准较为单一,仅仅考虑了企业连续3年正常经营的净利润,而没有从多方面考量企业,具有一定的局限性。过度借贷法有3个判断条件:1)当年资产负债率在前30%;2)当年外部资产规模大于上一年外部资产规模;3)当年正常经营净利润小于0。过度借贷法通常能识别负债率排名前30%的企业,而对于后70%的企业则难以判断,且忽略了银行在僵尸企业识别问题中扮演的重要角色。
在前期实验的基础上发现:上述两种僵尸企业判别方法对于僵尸企业的关注重点各不相同,存在标准不一、弹性过大、泛化性不强等问题。在企业信息较为简单时显然具备较强的识别能力,但随着数据量的增大以及数据维度的增加可能会降低识别效率和准确率,大大增加精准识别僵尸企业的难度。
鉴于数据挖掘、机器学习等算法已在各领域得到了很好的应用,本文将以机器学习算法构造集成模式,实现僵尸企业的精准识别。相较于单一模型,集成模型能更精准地解决分类预测问题,有效提升识别的准确率和效率,于是本文提出了一种决策树-逻辑回归的方法,用于准确识别僵尸企业。具体而言,该方法首先采用统计、分析、数据挖掘等技术对数据集进行预处理;然后经数据处理、特征衍生、特征筛选等步骤构建决策树-逻辑回归集成模型,得到了可以有效利用的数据集。在特征衍生方面,借鉴现有特征挖掘隐藏信息,使得机器学习算法能够更好地挖掘并利用数据集的信息;在特征筛选方面,在剔除了共线性较强的特征基础上检验自变量对于因变量的影响。对于数值型特征,采用多元线性回归分析筛选;对于类别型特征,采用卡方检验筛选。逻辑回归[8]和决策树[9]均可用于解决二分类问题,且它们具有时间复杂度低的优点。若单独采用逻辑回归或决策树,则容易产生过拟合问题,尤其是在数据样本大、特征数量多的情况下难以获得令人满意的效果,于是本文结合两种模型提出了决策树-逻辑回归模型的僵尸企业识别方法。
1 决策树-逻辑回归模型的僵尸识别企业方法
本文提出的决策树-逻辑回归模型的训练过程如图1所示。首先对原始数据集进行数据初步分析和预处理,包括数据表的合并、数据的可视化分析、缺失值的填充以及离群值的处理,其中缺失值由中位数来填充[10];随后开展特征工程工作,目的是提升模型的准确率以及提高模型的训练速度,主要步骤包括特征衍生和特征筛选[11]。

图1 决策树-逻辑回归模型的流程Figure 1 Process of decision tree-logistic regression model
在特征衍生方面,将进一步挖掘数据集潜在的信息,根据数据集本身的部分特征衍生成新的特征,便于后续模型的训练。在特征筛选方面,首先消除特征之间的共线性问题[12]。针对共线性问题,以相关性检验的方法计算不同特征之间的相关系数,将相关系数大于0.7的特征剔除,而将保留的特征分成数值型特征和类别型特征。对于数值型特征进行多元线性回归分析[13],对于类别型特征进行卡方检验[14]。
将已处理的数据集按照75%∶25%的比例切分,分别用于训练和测试。将训练集用于决策树,手动调参确定的决策树参数组合如下:评价标准为基尼系数,内部节点再划分所需最小样本数量为8,叶子节点最小样本数量为10。
决策树的输出结果为一个企业在当年是否为僵尸企业。在一个企业对应的3条数据中,有个别年份被预测为僵尸企业,还有个别年份被预测为非僵尸企业,而企业是否为僵尸企业应该综合3年数据一起判断[5]。为了将每个企业的3年数据作为整体预测,引入新特征僵尸性--企业3年数据中被判断为僵尸企业的次数作为逻辑回归的输入,将逻辑回归的输出作为最终结果。在由此构建的决策树-逻辑回归模型中,决策树用于获取企业新特征僵尸性,逻辑回归则用于僵尸性并入总数据集后的整体预测。数据集中的75%作为训练集,余下的25%作为测试集,可用于检验模型的准确性和拟合效果。
2 实验和分析
2.1 数据来源和实验环境
实验所用原始数据来源于湖南科创信息技术股份有限公司公开的企业信息数据集,该数据集包含了从多角度、多层次、多领域汇聚同行业的相关信息。具体而言,共有45 934家企业在2015-2017年的相关信息,总计137 802条数据样本,每条数据样本为一家企业在某一年的数据信息。实验环境如下:本地环境是CPU为Intel®CoreTMi5-8250U CPU@1.60 GHz(8 CPUs),~1.8 GHz;阿里云环境是CPU为2.5 GHz主频的Intel®Xeon(R)Platinum8269CY(Cascade Lake),睿频3.2 GHz;软件版本为Python版本3.7.3,Tensor Flow版本1.3.1,Keras版本2.2.4。
2.2 数据处理
首先初步分析实验数据集,得到基本信息和缺失值统计结果如表1~4所示。其中:表1为企业基本信息表,表2为企业财务报表,表3为企业现金流量表,表4为企业知识产权表。

表1 企业基本信息Table 1 Enterprise basic information

表2 企业财务报表Table 2 Enterprise f inancial statements

表3 企业现金流量Table 3 Enterprise cash f low

表4 企业知识产权Table 4 Enterprise intellectual property
鉴于部分信息缺失过多难以修复,经筛选最终得到的数据集共包含35 648家企业。在数据集中,每家企业均有2015-2017年的数据信息,共计106 944条数据样本。接着开展数据清洗工作,使用中位数对缺失数据进行填充。
2.2.1 特征衍生
为了使模型更好地学习数据集的特性,生成了一系列有利于识别僵尸企业的特征,如表5所示。将企业连续亏损的年数作为相关特征。由于本数据集仅包含3年内企业的盈利情况,企业连续亏损年数的范围为1~3。

表5 特征衍生生成的特征Table 5 Features derived from feature
2.2.2 特征筛选
本节将分别针对数值型特征和类别型特征展开特征筛选工作。
2.2.2.1 数值型特征
计算各个特征之间的相关系数矩阵,删除相关系数大于0.7的特征;然后对保留的特征进行多元线性回归分析,筛选出P值小于0.05的特征,最终结果如表6所示。
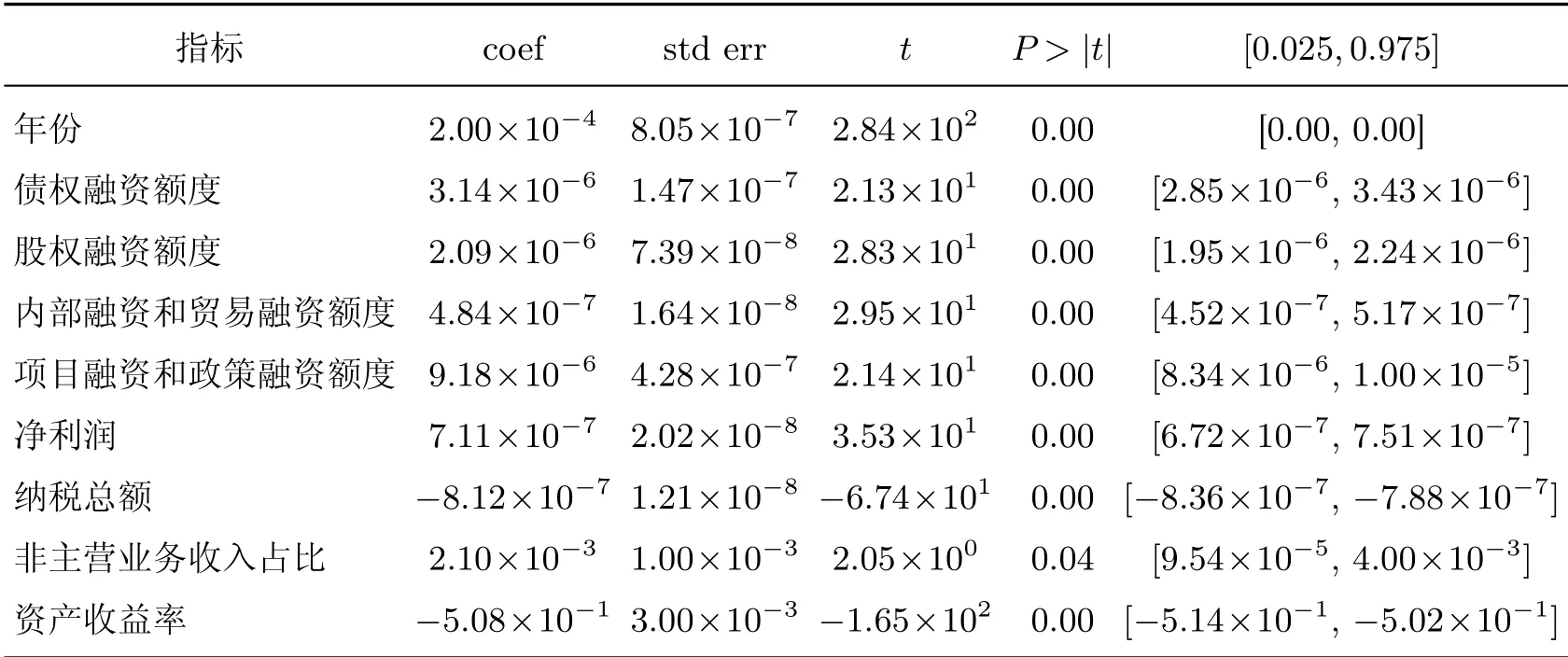
表6 多元线性回归结果Table 6 Results of multiple linear regression
接下来再一次给出相关系数矩阵如图2所示,确定现存特征之间的相关系数不超过0.7。

图2 经多元线性回归筛选的数值型变量的相关系数矩阵Figure 2 Correlation coefficient matrix of numerical variables f iltered by multiple linear regression
2.2.2.2 类别型变量
本文采用卡方检验进行特征筛选,将各个特征的P值排序如图3所示。为了保证不犯第1类错误的概率达到95%,选取P值小于0.05的特征,最终筛选的特征为亏损年数、著作权、区域。将筛选出的数值型特征与类别型特征合并,即可得到最终用于训练的特征,如表7所示。

图3 类别型变量经卡方检验的P值顺序图Figure 3 P-value sequence diagram of categorical variables by chi-square test

表7 筛选特征表Table 7 Filter feature table
2.3 建模分析
经过数据预处理、特征衍生和特征筛选,得到可用于最终训练的数据集。选取75%∶25%的切分比例生成训练集和测试集用于训练。为了验证决策树-逻辑回归模型的有效性,与连续亏损法、过度借贷法等传统算法以及随机森林、XGBoost、BP神经网络等机器学习算法建立的模型进行分析比较。在机器学习算法中,常用的模型评估指标为准确率、精确率、召回率、F1-score。
在实验中,机器学习库--XGBoost库选取默认参数,随机森林和神经网络采用随机搜索超参数的方法选取最优超参数组合。
随机森林中的超参数选取可采用网格搜索法,每次选取1个或2个超参数进行搜索,最终选取的超参数为40个决策树分类器。其中:最大深度为5,内部节点再划分所需最小样本数量为50,叶子节点最少样本数量为10。
表8给出了默认参数的随机森林和经过网格搜索后剪枝得到的随机森林。其中:树的最大深度为5,内部节点再划分所需最小样本数量为50,叶子节点最小样本数量为10。由表8可知:默认参数的随机森林在训练集能达到约99.998 7%的准确率,在测试集只有约99.074 7%的准确率,且精准率和F1-score均有1%~2%的差异,存在轻微过拟合现象,平均耗时约为7.42 s。

表8 随机森林剪枝前后的性能指标Table 8 Performance indicators of random forest before and after pruning %
经过剪枝后,随机森林在训练集和测试集均达到99%左右的准确率,表明各项指标的稳定性较好。剪枝后的模型因为限制了树的生长,所以平均耗时大概只有1.64 s,相较于默认参数的模型已大大缩短。
神经网络算法需要多次迭代,耗费的时间代价极高。为了提高训练效率,往往将数据样本分成一个个mini-batch分批训练[15]。本文共有106 944个数据样本,选取batch-size为100。在不同优化器下,神经网络在训练集和测试集的性能指标如表9所示。
在使成本函数最小化的过程中,可以采用随机梯度下降法[16]、带动量的梯度下降法[17]、RMSProp法[18]、Adam法[18]等进行优化。在本地环境下比较各种优化算法,其中神经网络选取的参数如下:隐藏层为2层,各层神经元的数量均为8,隐藏层激活函数为tanh函数,输出层激活函数为sigmoid函数,迭代过程为每轮50次。由表9可知,随机梯度下降算法和Momentum算法在召回率方面能达到100%的精度,也就是能找出数据集中所有僵尸企业,但在精准率方面比RMSProp算法和Adam算法低1%~2%,即可能将某些非僵尸企业误判成僵尸企业,在F1-score和准确率方面也不如RMSProp算法和Adam算法。Adam算法总体上略优于RMSProp算法,于是本文选择了Adam算法进行下一步实验。

表9 神经网络在训练集和测试集的性能指标Table 9 Performance indicators of neural networks in training set and test set %
神经网络的各种超参数对模型的预测能力有着重要的影响。但超参数很多,若用网格搜索法则耗时太多,因此本文采取随机搜索法来寻找局部最优超参数组合。在实验中,以TensorFlow为后端使用深度学习框架Keras中的调参工具Keras-Tuner来搜索超参数。
搜索的超参数为隐藏层的数量和每层神经元数量。其中隐藏层范围为1~6层,以1层为步长;每层的神经元范围为8~64个,以8个为步长。最优超参数组合为4层隐藏层,各层的神经元数量依次为48个、32个、16个、24个。
神经网络模型如图4所示,mini-batch大小为100,优化算法为Adam算法,隐藏层为4层,各隐藏层的神经元数量依次为48个、32个、16个、24个,中间层激活函数为tanh函数,输出层激活函数为sigmoid函数。
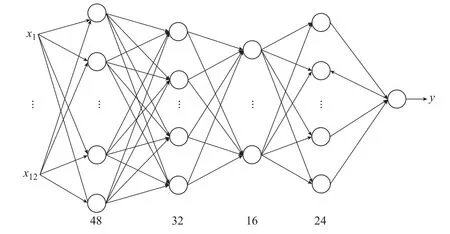
图4 四层隐藏层的神经网络Figure 4 Neural network with four hidden layers
2.4 算法比较
为了比较各种算法在不同实验环境下的差异,本文将已处理的数据集和算法部署至阿里云训练,并与本地的测试结果进行比较。每一次训练随机选取75%的数据样本作为训练集,而将余下的25%作为测试集,在确保每次实验数据集不同的情况下共训练50次,计算平均准确率、平均耗时、平均召回率,F1-score、平均耗时、总耗时等指标。
在阿里云环境和本地环境下,采用决策树-逻辑回归法、连续亏损法、过度借贷法、随机森林、XGBoost、BP神经网络训练已处理的数据集,得到各项指标分别如表10和11所示。

表10 阿里云环境的性能指标Table 10 Performance indicators of Alibaba Cloud environment %
在运行速度方面,连续亏损法最简单,运行时间最短,该算法无论是在阿里云环境还是本地环境下均能在0.6 s内完成1次预测。本文的决策树-逻辑回归集成模型在运行时间方面与同为集成模型的随机森林和XGBoost相比表现更好,约为1.5 s即可完成1次预测。BP神经网络单次运行需要50次迭代;过度借贷模型在训练时涉及到数据的重新排序,因此以上两种模型运行时间较长。
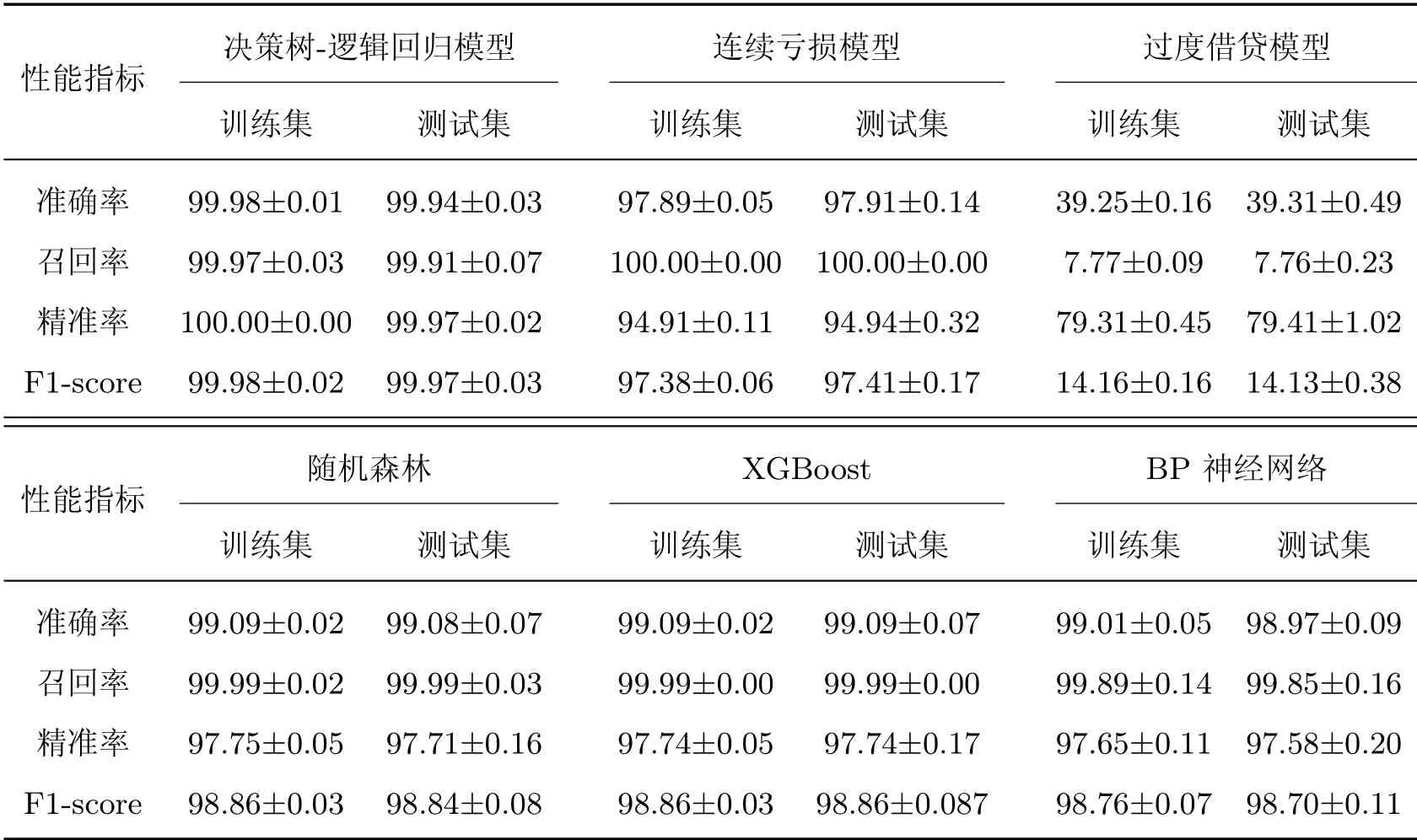
表11 本地环境的性能指标Table 11 Performance indicators of local environment %
在预测准确率方面,决策树-逻辑回归集成模型最高,在训练集和测试集上均能获得99.98%以上的准确率,说明该模型能达到精准识别僵尸企业的目的。过度借贷模型只能判定资产负债率在前30%的僵尸企业,而无法判定资产负债率在后70%的企业,因此其整体指标较低。连续亏损法能有效识别僵尸企业,故本文提出的决策树-逻辑回归模型在特征衍生时借鉴其思路,并结合机器学习的多次迭代训练进一步提升了识别准确率。其余模型尽管在准确率这一指标上没有决策树-逻辑回归模型高,但其召回率均能达到或接近100%,说明它们也能将数据集中的僵尸企业基本找出来,但仍存在部分错判现象。F1-score是综合精准率和召回率的指标,由此可以得到决策树-逻辑回归模型在精准率和召回率方面均比其余模型稳定高出1%左右。
在阿里云环境下,决策树-逻辑回归模型、连续亏损模型、过度借贷模型、随机森林、XGBoost、BP神经网络的平均耗时分别为1.45±0.03 s、0.51±0.02 s、78.67±0.38 s、1.66±0.14 s、5.09±0.67 s、110.33±24.74 s。在本地环境下,决策树-逻辑回归模型、连续亏损模型、过度借贷模型、随机森林、XGBoost、BP神经网络的平均耗时分别为1.53±0.17 s、0.42±0.05 s、79.55±5.23 s、1.63±0.25 s、3.54±0.04 s、78.66±5.61 s。综上所述可以得出以下结论:在上述几种模型中,决策树-逻辑回归集成模型在各数据集上的表现最佳,能根据数据集中企业的信息以极高的准确率预测出该企业是否为僵尸企业,同时在运行速度方面也优于其他集成模型。
3 结语
传统的用于僵尸企业识别的方法较为单一,存在局限性,于是本文针对如何精准识别僵尸企业的问题,提出了一种决策树-逻辑回归模型的僵尸企业识别方法,并在阿里云和本地环境中进行对比实验,验证了该方法的有效性。以后将从大数据的角度收集更多上市公司的相关信息,形成结构化的数据集,比较该方法在规模更大、维度更多的数据集下的性能表现。
