基于卷积神经网络和投票机制的轨道板裂缝检测
2022-01-19李文举何茂贤张耀星陈慧玲李培刚
李文举,何茂贤,张耀星,陈慧玲,李培刚
1.上海应用技术大学计算机科学与信息工程学院,上海201418
2.上海应用技术大学轨道交通学院,上海201418
高铁产业快速发展,在带来便利的同时也存在着无法及时维护轨道板的安全隐患。为减少交通隐患,及时掌握轨道裂缝情况,需要实现对轨道裂缝的高效检测。其中,无砟轨道因稳定性较好而作为中国主流的轨道结构,但是随着服役时间的增加以及长期受较大昼夜温差等复杂环境因素的影响,产生了大量裂缝[1-2],影响了列车的正常运行。现有的人工检测方法[3-5]受到了照明设备、工作经验、环境变化等因素的限制,不但常常发生漏检和误检情况,而且费时费力,主观性强,不利于客观评估轨道结构安全。
为了解决以上问题,开始以图像处理方法替代人工检测方法,然而传统的图像处理方法很容易受到光照环境和拍摄方式的影响。因此,随着人工智能技术的发展,研究人员通常采用卷积神经网络来处理图像问题。与人工检测方法和传统的图像处理方法相比,该方法只需导入图片就能准确完成检测任务。
卷积神经网络执行图像分类任务时采用的分类决策主要依赖于充当分类器的全连接层。如果将特征图直接展开成一维特征以适配后续全连接层的输入,那么原本特征信息就会丧失其空间拓扑结构而使最终模型取得次优解。文献[6]指出:深度卷积神经网络(deep convolutional neural network,DCNN)从架构上就难以保证平移不变性,而基于数据增强训练的卷积神经网络仍能学到部分不变性。受基于区域的全卷积神经网络(region-based fully convolutional network,R-FCN)启发[7],本文将高层特征图分组后依次进行注意力加权处理和单组预测,以相对独立的弱分类器分别量化分析各组的预测结果,以强分类器汇聚所有弱分类器的预测信息,并输出最终的分类结果。
1 相关工作
1.1 裂缝检测
文献[8]调整检测网络模型的超参数和输入图像的尺寸,利用卷积神经网络实现了对混凝土路面缺陷的准确检测。文献[9]针对裂缝可能存在水渍以及分布不规律等问题,采用深度学习的方法分别对隧道衬砌裂缝进行分类和分割。文献[10]将桥梁裂缝图像划分为较小的桥梁裂缝面元图像和桥梁背景面元图像,然后深入分析面元图像的特点,进而提出了一种基于卷积神经网络的深度桥梁裂缝分类器(deep bridge crack classify,DBCC)用于桥梁背景面元和桥梁裂缝面元的识别。文献[11]利用Deep Labv3+实现了沥青路面的像素级分类。
在轨道板裂缝检测方面,文献[12]首先根据轨道梁裂缝的视觉特点调整相机、光源、拍摄距离等环境因素,获取了裂缝图像;然后采用最大类间方差法获取图像特征,提高了轨道桥梁裂缝的检测率。文献[13]提出了一种非接触式的基于图像处理的轨道板裂缝检测模型,依次执行图像增强和二值化处理以准确定位裂缝位置。文献[14]经调研确定裂缝的表现形式和结构特征,根据红外热成像检测原理研究了环境温度等因素对裂缝检测的影响程度,从而优化了检测条件。
1.2 卷积神经网络
传统的机器学习模型着重于解决聚类以及简单的分类问题,而一旦面对高维特征的映射和多分类问题就难以奏效,因此不适合直接应用到图像分类领域。自从AlexNet[15]在ILSVRC-2012竞赛中以15.30%的错误率夺冠后,深度学习技术逐渐成为计算机视觉和图像处理的主流解决方案。随后的VGG[16]、Inception[17]、残差网络[18](residual network,ResNet)等都试图从主干网络结构寻找突破口,在提升精度的同时权衡浮点运算次数(f loating point of operations,FLOPs)。如果仅以增加模型的深度来提升模型的复杂度,那么浅层的参数就很难更新。为此,ResNet[18]设计残差模块,避免浅层参数无法更新导致的梯度爆炸或者弥散现象。然而,文献[19]认为ResNet[18]的残差模块没有利用全部特征信息,因为以1×1大小、2为步长的卷积核进行卷积丢弃了3/4的特征信息。文献[20]提出了全卷积网络(fully convolutional network,FCN)模型,但执行语义分割时无法充分输出多尺度特征信息。文献[21]在设计整体嵌套边缘检测(holistically-nested edge detection,HED)结构时,为了能够处理多尺度变化问题,在每个下采样阶段取出最后一层特征图放入深监督模块进行训练。文献[22]采用更加丰富的卷积特征(richer convolutional features,RCF),进一步加深浅层特征和深层语义之间的联系。文献[23]构建了特征金字塔网络(feature pyramid network,FPN),旨在影响卷积金字塔式的语义特征层次,反向建立一个含有高层次语义的特征金字塔。
文献[24-26]利用注意力机制凸显有用信息,同时抑制易干扰模型判断的负面信息。其中文献[24]提出了挤压和激变网络[24](squeeze-and-excitation network,SENet),由全局池化层和两个全连接层获取一组辨别通道特征重要程度的掩码。
2 本文模型
图1展示了部分现场拍摄的轨道板裂缝,当光线不足时,裂缝与暗处融为一体,人工以及简单的模型难以区分背景和裂缝的边界,因而无法有效检测裂缝图片。于是本文根据R-FCN[7]中感兴趣区域(region of interest,ROI)的分值确定样本类别的判别方式,以多分类器共同协作的方式完成样本类别决策。本文在训练阶段变换输入的图像信息,从而使每个分类器能依靠随机的特征进行分类判决。这种采用图像处理技术的非接触式方法能够简化检测过程。为减少误检和漏检现象,在分类器中添加注意力机制进行投票式裂缝检测,以此减弱图像背景对裂缝检测的影响程度,达到提升准确率的目的。

图1 不同光照环境下的轨道板裂缝Figure 1 Track slab crack under different photograph conditions
卷积神经网络在执行N分类任务时,将高层抽象特征展开或者执行全局池化操作得到低维特征,满足了全连接层的输入要求。然而,这类特征在形成过程中因失去原有的空间拓扑结构而丧失层次感。若分类器用该特征向量执行决策,则整个模型不能达到最优解。为了在一定程度上解决上述问题,本文提出了一种以特征组为单位的分类投票机制。该机制的依据是高层特征图中的特征点都具备一定的感受野,因此每个特征点都能用来描述局部图像类别的信息内容,具体示意图如图2所示。

图2 裂缝分组检测示意图Figure 2 Sketch map of crack detection in grouping stage
主干网络对图像进行特征提取后可以获取高层抽象特征图u∈RC×m×m,再将所有通道上固定位置的特征点提取出来形成低维特征组vi∈R1×C,把分类器和特征组相连接共得到M=m×m组N类别预测结果,最后汇聚所有预测信息以强分类的输出作为当前样本的类别概率。整个检测流程如图3所示。

图3 裂缝检测示意图Figure 3 Schematic diagram of crack detection
图4展示了在图像分类任务中两种不同的处理高层特征图的方法。图(a)将特征图压缩成特征向量,然后将特征向量输入全连接层用于分类决策。图(b)体现了本文的分组策略,首先提取相同位置的特征信息形成多个特征向量,随后交由分类器独立预测,最后汇总所有预测结果输出最终的类别。

图4 两种处理特征图的方法Figure 4 Two methods of processing feature maps
2.1 参数量
不断变换输入图像可以让卷积神经网络获得平移不变性。如果对不同的特征组采用权重参数共享策略,并将分类器参数保持相对独立,就可以有效减少模型在预测阶段所需要的参数量。本文模型共设置3层全连接层,每层的节点变量分别为C1、C2、N,每层全连接所需要的参数量为输入节点数量与输出节点数量的乘积。
由于每个特征组的信息是独有的,分类器之间的性能会存在差异。为了减少这种差异对最终预测结果产生的负面影响,本文采用强分类器汇聚弱分类器信息的方式,以M个可学习参数θ来控制预测结果Z的大小,达到模型输出最终类别前能自动识别有用信息的目的。软投票分类器的预测公式为

式中:f为预测函数。对于图像分类任务,VGG[16]将特征图u∈RC×m×m展开成向量。默认的全连接层包含4 096个节点,即在分类子网中C1=C2=4 096。分组模式与展开方式在预测阶段所需参数比例的计算公式为
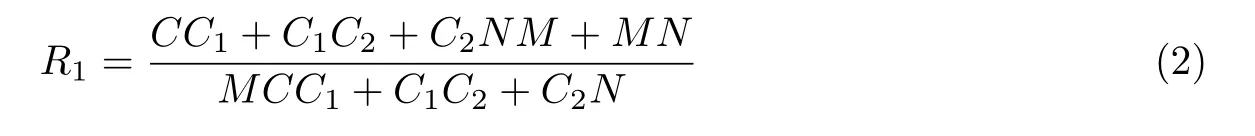
由式(2)可知:当全连接层的节点数量Ci固定时,如果类别数量N较少,那么R1≤1,说明本文模型所需的参数数量较少。在具体实施过程中,本文模型将高层特征分为4组(即M为4)。在预测阶段采用3层全连接层结构执行二分类任务(即N为1),此时根据式(2)算得R1为0.75,即采用本文分类方法能在全连接层结构上减少约25%的参数。然而,各组特征值会重复进入共享全连接层,导致模型整体的FLOPs消耗提升2倍,提升系数计算公式为

2.2 注意力机制
为了区分不同通道的重要性,根据文献[24]把侧重点转移到不同通道之间的关系上,而并不局限于特征的空间关系、多尺度多层次的问题上。整体执行流程如图5所示,SENet[24]中的注意力机制模块以特征图ui∈Rm×m作为输入,随后将每个特征图的通道池化为一组实数,接着调整参数将实数训练成通道对应的权重,最后利用权重对特征通道加权。这样模型可以突显含有重要信息的特征通道,最终输出层次较为分明的特征图。整个注意力加权过程可简化为
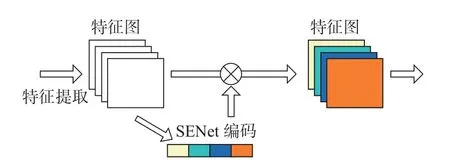
图5 SENet编码示意图Figure 5 SENet encoding diagram

为了专注于跨通道间的信息融合,本文把经过1×1卷积核卷积后的特征图作为注意力模块的输入,因为1×1卷积核只进行通道之间的交流而不会去学习局部像素信息。
2.3 投票式预测
将每组特征预测子网看作相对独立的弱分类器,以加权方式聚合全局信息来预测结果,达到降低方差的目的。在训练阶段,共有M个损失函数用于辅助更新各个分类器的参数。若分类器给出预测分值为[Z1,Z2,···,ZM],激活函数f(Z)以分值作为输入,输出预测概率表示当前样本是裂缝的可能性,则整个集成预测的具体公式为

式中:Sign为投票函数。本文采用的是软投票的方式,输入为各个分类器预测的类别概率,P为模型最终输出的类别概率。
3 实验
本文采用NVIDIA RTX 2070验证本文算法。将ResNet-18[18]作为主干网络,取消全局平均池化层,再将该模型原本的分类子网替换为分组投票式进行预测。由于轨道裂缝检测是二分类任务,模型采用sigmoid作为激活函数,根据分类器输出的置信度判定当前样本是否为轨道裂缝。
本文以现场拍摄的800幅分辨率大小为1 200×1 400的轨道裂缝图像作为原始数据集,利用图像增强技术将原始数据集扩充至5 000幅轨道板裂缝图像。每幅图像的大小为256×256,并加入5 000幅负样本共同构成轨道裂缝数据集,按照9∶1的比例划分训练集和测试集。初始训练学习率为1×10−4,采用最大池化操作使特征图分为4组特征向量和5个分类器Mi,每个分类器的训练曲线如图6所示。
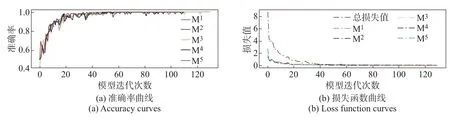
图6 裂缝检测训练曲线Figure 6 Training curve of crack detection
将部分裂缝特征图可视化,如图7所示。当光线较为充足时(见第2行的4个小图),主干网络响应了细微的裂缝。在夜晚拍摄时,因为拍摄时人工照明不均匀,所以图像成像后的对比度较低,导致裂缝无法准确识别。当拍摄距离较近时(见第1行的4个小图),模型仍然能够识别出裂缝并给出响应;当拍摄距离较远时(见第3行的4个小图),模型已无法准确辨别出裂缝区域,而错误地响应了右上角的区域;稍微拉近距离拍摄后(见第4行的4个小图),模型虽然能够准确辨别横向裂缝,但是对雨水冲刷形成的纵向污渍处响应强烈。为了更好地观察不同结构对检测准确率的影响,本文将图像增强技术和投票策略作为自变量进行实验。模型在轨道板裂缝测试集的预测准确率如表1所示,缺乏图像增强技术和投票机制加持的模型预测结果较差,而仅加入图像增强技术就能使准确率提升7.90%,添置投票机制能再次提升1.60%的准确率。

表1 不同条件下的裂缝检测准确率Table 1 Accuracy of crack detection under different conditions

图7 裂缝特征图可视化Figure 7 Visualization of crack feature maps
预测准确率的影响因素除了模型的结构外,还包括每一批训练的图像数量。表2展示了批次大小对预测准确率的影响,由表中数据可知:每一批输入的图像越多,在测试集上的预测准确率就越高。因为输入图片的数量越多,模型越能拟合预测样本,但是过多的图像数据会加重内存的负担。

表2 批次大小对准确率的影响Table 2 Inf luence of batch size on accuracy
本文从测试集选择20幅图像来测试不同模型的预测性能,图8展示了所有模型的预测曲线,横坐标为20幅图像的编号,纵坐标为模型认定该图片为裂缝的预测概率P。图(a)中的蓝色曲线展示了ResNet-18[18]对裂缝测试图像的预测结果,红色曲线给出了每幅图像的标签值。对比两条曲线可以看出:该模型存在1/4的错误预测概率,而从绿色曲线中可以得出正则化能够提升模型预测准确率的结论。其中,第4、6、10、11幅测试图的背景在训练集中出现次数较少,导致多个模型均做出错误判断。正因为如此,当模型过拟合时,所有分类器均错误地认为这4幅图都是非裂缝图的场景,如图(b)所示。图(c)给出了本文模型加入L2正则化后各个分类器的预测曲线。对比图(b)和图(c)可以看出这种因样本不均衡导致的误判现象有所减缓,因为添加正则化等训练策略后削弱了背景样式对模型的影响。分类器对第4幅和第6幅的预测概率约为0.40,并认为第10幅和第11幅很有可能是裂缝图。图(d)展示了图(a)和(c)模型的预测差值,其曲线较大浮动处均为不均衡样本的图像。

图8 20幅测试图像在各个模型上的预测值Figure 8 Prediction curve of different models for 20 pictures
3.1 学习率
当网络随机初始化参数时,通常采用较大学习率辅助参数更新,但是在模型收敛阶段可能导致损失函数一直处于局部极小值附近,于是文献[27]提出了一种学习率回暖策略。在第1阶段,学习率在前h次训练迭代时从0开始线性增加到设定值,即每轮学习率的大小为其中i∈[1,h],l为初始值。在第2阶段,迭代次数到达h′之前,保持学习率为预定大小,让损失函数向极小值方向移动。在第3阶段,采用指数衰减法微调学习率,让损失函数到达最小值。文献[18]将初始学习率设为0.10,仅在第32 000次迭代和第48 000次迭代时将学习率除以10。文献[28]提出了一种余弦退火策略,该方法根据余弦函数在[0,π]区间内下降的特性,将下降周期d与整体迭代次数g的关系映射到这个区间中,具体计算公式为

为了进一步防止网络在训练后期出现学习率过低、无法跳出局部最优解的情况。本文在余弦退火法的基础上采用了多项式衰减法,帮助网络获得最佳检测能力。当时,将再一次进入衰减周期,在接下来的迭代过程中将基础学习率设为原来的rd倍,同时将下降周期也延长为ru倍。
在轨道板裂缝检测实验中,本文将rd设置为0.70,ru设置为2.00,模型迭代次数h和h′分别设置为35和50,则整个训练阶段学习率的变化函数为

3.2 学习策略
本文以交叉熵作为损失函数,用梯度下降法优化参数。在实验过程中,批归一化(batch normalization,BN)层[29]用来加速损失函数的收敛过程,同时将所有卷积核中的偏置项初始化为0。考虑到激活函数和网络参数的适应性,将he_normal[30]作为卷积核参数的初始化方式。
在实验过程中发现:若直接将原始图像输入模型,则会产生过拟合现象。尽管模型在训练集上的预测效果较好,但在测试集上的预测表现糟糕。本文决定借鉴与文献[31]相似的图像增强方式,即随机将原图缩放0.8~1.5倍,随机位置裁剪,随机旋转以及翻转。图像增强技术支持分配随机特征给各个分类器,达到加强模型整体鲁棒性、避免过拟合的目的。
3.3 CIFAR数据集分析
为了进一步证明投票机制有助于提升模型在分类问题上的预测准确率,本节选择ResNet-18[18]和VGG-16[16]作为主干网络测试CIFAR-10和CIFAR-100[32]的数据集。这两类数据集分别拥有10和100个数据类别,每类有5 000幅和500幅图片用于训练,则用于训练的图片共50 000幅,测试图片有10 000幅。在使用VGG-16[16]为主干网络进行消融实验时,为避免只有一个分组,采用双线性插值法将原图像分辨率扩大至64×64。因为属于多分类问题,所以将Softmax函数充当分类器激活函数,直接采用软投票分类器作为最终输出。经实验发现:模型添加了投票机制策略能在CIFAR-10测试集上达到93.40%的准确率,在CIFAR-100测试集上达到70.13%的准确率。
相比于单个分类器进行预测的方法[15,18,31,33-34],本文致力于提升现有模型的预测准确率,而非超越最先进的模型。表3列举了8种模型在CIFAR[32]数据集上的准确率。以ResNet-18[18]作为主干网络,加入投票机制能提升0.37%的准确率。从表3中可以看出:本文模型虽然在CIFAR-10测试集上的准确率低于ALL-CNN[34],但在CIFAR-100测试集的准确率较高。

表3 CIFAR-10&CIFAR-100的分类准确率对比Table 3 Contrast of classif ication accuracy between CIFAR-10 and CIFAR-100 %
以VGG为主干网络,各组不同准确率的弱分类器在CIFAR[32]测试集上的损失程度如图9所示。由图9可以看出:即使是最终预测准确率最高的模型(蓝色曲线),所对应的第1个和第3个弱分类器的预测损失率也是最高的。
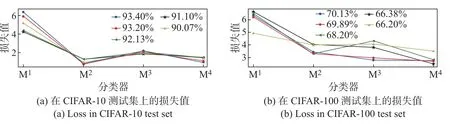
图9 各个弱分类器的预测损失值Figure 9 Loss of each weak classif ier
以CIFAR-10[32]测试集中准确率最高的模型为例,该模型下所有分类器的预测准确率如图10所示,其中图(a)和(c)对应分类器的预测准确率较低,加入投票机制可以有效地集成弱分类器结果而自动过滤掉错误信息,达到提升最终分类器预测准确率的目的。

图10 分类器在CIFAR-10上的表现Figure 10 Performance of classif iers in CIFAR-10
3.3.1 结构对测试准确率的影响
本节添加了消融实验来量化分析在通道加权前小卷积核对准确率的贡献程度,结果如表4所示。因为文献[16]没有给出具体值,所以表中baseline的准确率是基于当前学习环境下多次训练得出的最佳值。在该结构上添加投票模块后能提升0.50%的准确率,在通道加权前添加1×1卷积核能再提升0.10%的准确率。仅添加投票模块的对比模型得不到层次分明的特征图,同时缺乏可学习得到的平移不变性,因此导致模型的泛化能力和预测准确率较差;SENet[24]会使模型出现过拟合现象,进而影响模型在测试集上的预测准确率。

表4 不同的结构和训练策略在CIFAR-10上的表现Table 4 Performance in CIFAR-10 with different structures and training tactics
3×3卷积核相比于1×1卷积核,其优势在于能够学习局部的信息。考虑到模型的输入大小为64×64,经过5次下采样后得到的特征图u∈IRC×2×2。如果采用较大卷积核进行卷积填充,那么特征图中每个特征点已经拥有了全局感受野,此时本文提出的由不完全相同感受野的特征组共同决定类别的集成理念就不再适用,因此采用3×3卷积核的模型在性能方面不如采用1×1卷积核的模型。
将本文提出的投票机制策略和图像增强技术进行叠加,添加2个大小为1×1的卷积层可以让模型的准确率最多提升2.80%。应该明确的是:卷积操作需先于注意力加权执行,使后续的特征图层次分明。若在注意力加权后再进行卷积,则会使通道信息重新交互,破坏已经形成的对比度。
3.3.2 节点数量对测试准确率的影响
全连接层的节点数量同样也会影响最终的分类准确率,节点数量过少可能使模型分类不稳定,而节点数量过多可能造成不必要的计算开支。在VGG[16]模型中,全连接层的节点数量为4 096。为了讨论本文模型在共享全连接层中的节点数量对测试集的影响,测试节点数量分别为4 096、2 048、1 024时的准确率,详细结果如表5所示。当设置节点数量为4 096时,准确率能够达到最佳,相比节点数量为1 024和2 048时分别提升了1.20%和1.00%,但模型的参数量增长了102.97%和66.34%。

表5 节点数量对模型及其准确率的影响Table 5 Inf luence of node number on model and its accuracy
4 结语
为了减少轨道板裂缝检测上的漏检和误检测现象,本文提出了一种结合投票机制和注意力机制的卷积神经网络。首先通过注意力机制突出有用特征,选择随机特征进行分组;然后连接弱分类器分组训练;最后由强分类器汇总弱分类器的结果信息并输出类别概率。相比于其他的裂缝检测方式,该模型在轨道板裂缝测试集上能达到96.80%的准确率,在CIFAR-10和CIFAR-100测试集上的准确率能分别达到93.40%和70.13%,并且可以避免手动提取特征和单一分类器分类决策,在执行类别较少的分类任务时能够有效降低整个模型的复杂度并减少参数数量。
