基于正弦注意力表征网络的环境声音识别
2022-01-19彭宁陈爱斌周国雄陈文洁刘晶
彭宁,陈爱斌,周国雄,陈文洁,刘晶
1.中南林业科技大学人工智能应用研究所,湖南长沙410004
2.中南林业科技大学智慧物流技术湖南省重点实验室,湖南长沙410004
3.中南林业科技大学计算机与信息工程学院,湖南长沙410004
环境声音识别主要通过声音对场景进行分类,因采集成本较低而广泛应用于智慧城市、智能交通等邻域。早期的音频识别方法包括模板匹配、隐形马尔科夫链(hidden Markov model,HMM)、高斯混合模型(Gaussian mixturemodel,GMM)、支持向量机(support vector machine,SVM)、随机森林等机器学习方法。随着算力的提高,深度学习技术发展日新月异并进入了各个领域。在2012年,以卷积神经网络(convolutional neural network,CNN)为基础框架的模型AlexNet在ImageNet比赛中1 000类物体的识别上远超深度神经网络(deep neural network,DNN)模型,显示出CNN强大的图像提取能力[1],于是研究人员开始尝试将CNN应用于音频识别。使用CNN对音频进行识别的方法主要将声音转化为音频特征图像,借助自身强大的图像特征提取能力对音频图像进行特征提取,并可以在以下两方面进行改进:1)在输入端口音频特征的选取方面,选择图像上更明显的音频特征,比如梅尔频谱图、对数梅尔频谱图、梅尔频率倒谱系数(Mel-frequency cepstral coefficient,MFCC)等。2)在特征框架的提取方面,采用具有强特征提取能力的CNN模型结构,如深度卷积神经网络、残差网络等。
2015年,Piczak首次将CNN应用于环境声音识别,选用对数梅尔频谱图作为输入特征,以简单的两层CNN作为特征提取器[2]评估ESC-10、ESC-50、Urban Sound 8K这3个数据集,与传统音频识别模型进行对比的结果显示,以CNN作为特征提取器的方法更优。文献[3]将对数梅尔频谱图空洞卷积和LeakyReLU激活函数结合起来,在Urban Sound 8K上得到的准确率为81.9%,随后陆续出现了许多改进的CNN模型,用以提高环境声音识别的准确性。然而,音频图像不同于一般的普通图像,始终包含时间维度的信息,若用CNN提取音频特征,则会忽略时间维度上的信息。为了尽可能地保留音频维度上的特征,研究人员选用循环神经网络(recurrent neural networks,RNN)提取音频。因为在RNN中后一隐藏层特征与前隐藏层特征相关,所以能够有效提取时域维度的特征。文献[4]将对数梅尔频谱图特征与注意力机制、门控循环单元(gated recurrent unit,GRU)相结合,在环境声音识别方面取得了较好的结果。
本文基于文献[5]提出了正弦注意力表征网络(attention sinusoidal representation network,A-SIREN),首先用GRU网络提取MFCC音频特征;然后将正弦表征网络与注意力机制相结合,以周期函数表示隐式神经,更好地抓住了音频重点信息;最后将全连接层与Softmax分类器结合对识别结果进行分类,实验结果表明了本文算法的有效性。
1 基于A-SIREN的环境声音识别
1.1 网络框架
本文结构如图1所示,首先提取音频MFCC特征并将数据划分为训练集与测试集;然后利用GRU网络进一步提取MFCC音频特征,借助A-SIREN模块重新分配MFCC特征中每一帧的权重,使模型专注于音频重要区域;最后将全连接层结合Softmax分类器对音频进行最终判别。

图1 总体框架图Figure 1 Overall framework diagram
因为本文音频长度不一致,所以将音频长度零填充至所有音频中最大音频长度,同时设定A-SIREN层长度为174。最后将全连接层大小设为10,可以表示10种类别的输出概率。网络参数结构如表1所示。

表1 整体网络参数模型Table 1 Model of overall network parameter
1.2 M FCC特征提取
选择合适的音频特征可以提高音频识别率。音频特征分为时域特征和频域特征两大类,其中时域特征反映音频序列随时间变化的影响程度。过零点决定音频的频率特征,振幅决定音频的响度变化。为了使音频特征具有更高的保真度,研究人员往往选用较大的采样率,因此时域特征很密集,显示在图像上更像是噪点,很难体现其特征。此外,音频响度虽然对音频识别影响较小,但作为音频判别特征会影响最终识别,因而很少有研究者将时域音频特征作为网络的输入音频特征。
频域特征包含时域信号信息,同时体现音频的频率特征。在现有模型中,常用的频域特征主要包括频谱图、梅尔频谱图、对数梅尔频谱图、MFCC等。MFCC适用于人耳且能准确描述包络特征,于是本文将此特征作为模型输入。将时域特征进行傅里叶变换得到频谱图,傅里叶变换公式为
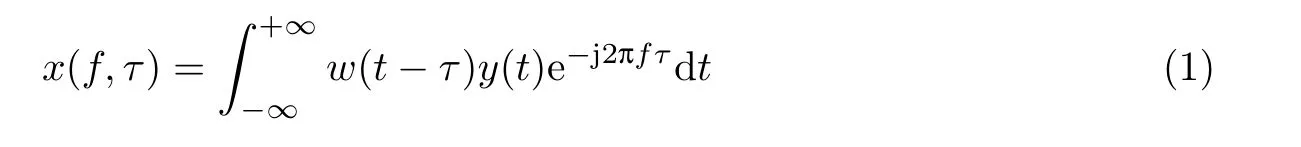
式中:y(t)为时域信号,x为频域信号,w(t−τ)表示中心位置位于τ的汉明窗(Hamming window),f为频率,τ为帧长。将所有音频零填充至最长音频时间长度4 s[6]。
梅尔滤波依照人耳特性设计,主要作用是突出低频,抑制高频。梅尔滤波公式为

式中:fmel为经过滤波后的梅尔频率。对梅尔频谱特征取对数,最后进行离散余弦变换得到MFCC特征。MFCC特征提取可视化如图2所示。

图2 MFCC特征提取可视化Figure 2 MFCC feature extraction visualization
在图2中,红色虚线框代表窗口大小,黄色框代表帧重叠区域。
2 A-SIREN
本文所提出的环境声音识别模型主要包括两部分:GRU网络与A-SIREN网络。
2.1 GRU网络
GRU网络属于RNN的变体,考虑到早期RNN会产生梯度消失与梯度爆炸问题,Hochreiter等对RNN进行改进后提出了长短期记忆(long short-term memory,LSTM)神经网络[7],解决了RNN层次过深所产生的梯度消失与梯度爆炸问题。文献[8]提出的GRU不但在多项任务中超越LSTM网络,而且训练参数较少。因此,本文借助GRU网络使单个门控单元能同时控制遗忘门与输出门,同样具有参数较少的特点。重置门公式为

式中:h(t)为隐藏层向量,包含所有输出的权重;U为输入权重;W为循环权重;σ为sigmoid激活函数;u代表更新门,主要保留当前重要信息;r代表遗忘门,决定信息的保留与丢弃;x(t)为当前输入向量。更新门与遗忘门的公式为

2.2 A-SIREN
本文将注意力机制与正弦激活函数结合为A-SIREN,对音频中重要信息进行高权重分配。其中注意力机制首次在机器翻译领域提出[9],并成功应用于图像识别、音频识别等领域。由于大多数音频数据中包含冗余信息,提取音频中重要信息可以提高机器辨识效率。本文使用A-SIREN激活函数对注意力机制加以改进,首先用正弦函数激活GRU的隐藏层得分使其归一化为(−1,1);然后对归一化结果进行Softmax处理,并为隐藏层分配权重;最后将重新分配权重后的隐藏层作为A-SIREN的输出。正弦激活函数适合表示复杂的语音信号及其导数,可以使关注点更容易集中到重要区域,从而更好地捕捉音频重要特征。A-SIREN公式为

式中:vi代表第i个隐藏层的得分,由当前隐藏层的权值进行正弦函数激活;αi代表第i个隐藏层归一化后的得分,使用Softmax将vi得分映射为0到1之间并作为权重。最后的输出为所有隐藏层得分αi及其对应隐藏层hi的乘积。A-SIREN模型的结构如图3所示,音频帧长远远超过5帧,为了视觉效果仅显示部分图像。

图3 A-SIREN模型Figure 3 A-SIREN model
3 实验结果与分析
3.1 数据集
本文选取Urban Sound 8K数据集作为研究对象,该数据集由Justin Salamon等创建,包含来自10个类别的8 732个标记声音(≤4 s)[10]。数据集声音类型分别为空调、汽车鸣笛、小孩玩闹、犬吠、电钻、发动机空转、枪声、手持式凿岩机、警笛和街道音乐。
3.2 参数设置
本文采用Tensorf low框架,编程环境为Python 3.7,硬件环境为英伟达(NVIDA)泰坦(TITAN)Xp显卡,CPU为Intel i9。Urban Sound 8K共8 732个样本,随机打乱样本序列后按照8∶2的比例划分训练集与测试集。音频采样率为22 050 Hz,窗口长度为2 048,步长为512,帧之间的重叠率为窗口大小的1/4。实验使用Librosa工具包[11]提取40维度的MFCC特征,4 s音频对应于174帧,则音频MFCC特征维度为40×174。将GRU中隐藏层的神经元数量设定为300,训练时将Dropout设定为0.5,测试时不使用Dropout,以免网络出现过拟合现象。优化器选用Adam优化器,批次大小设定为200。
3.3 A-SIREN实验
Urban Sound 8K数据集中存在类别不平衡问题,其中汽笛与枪声的类别远少于其他音频类别。针对数据集类别不平衡问题,本文采用focal loss损失函数,并与交叉熵(cross entropy)损失函数进行实验比较。Focal loss损失函数在目标检测任务中首次提出[12],主要用于减少易分类样本的权重,使模型在训练时更专注于难分类的样本,从而解决了背景与前景的类别不平衡问题。对于相同的模型,focal loss损失函数与cross entropy损失函数的实验结果如表2所示。

表2 不同损失函数的实验对比Table 2 Experimental comparison of different loss functions
由表2可以发现:focal loss损失函数的准确率高达93.5%,这一结果优于cross entropy损失函数的实验结果,显示出focal loss损失函数在音频数据集的有效性。此外,为了突出模型的有效性,将本文模型与其他模型进行对比实验,结果如表3所示。
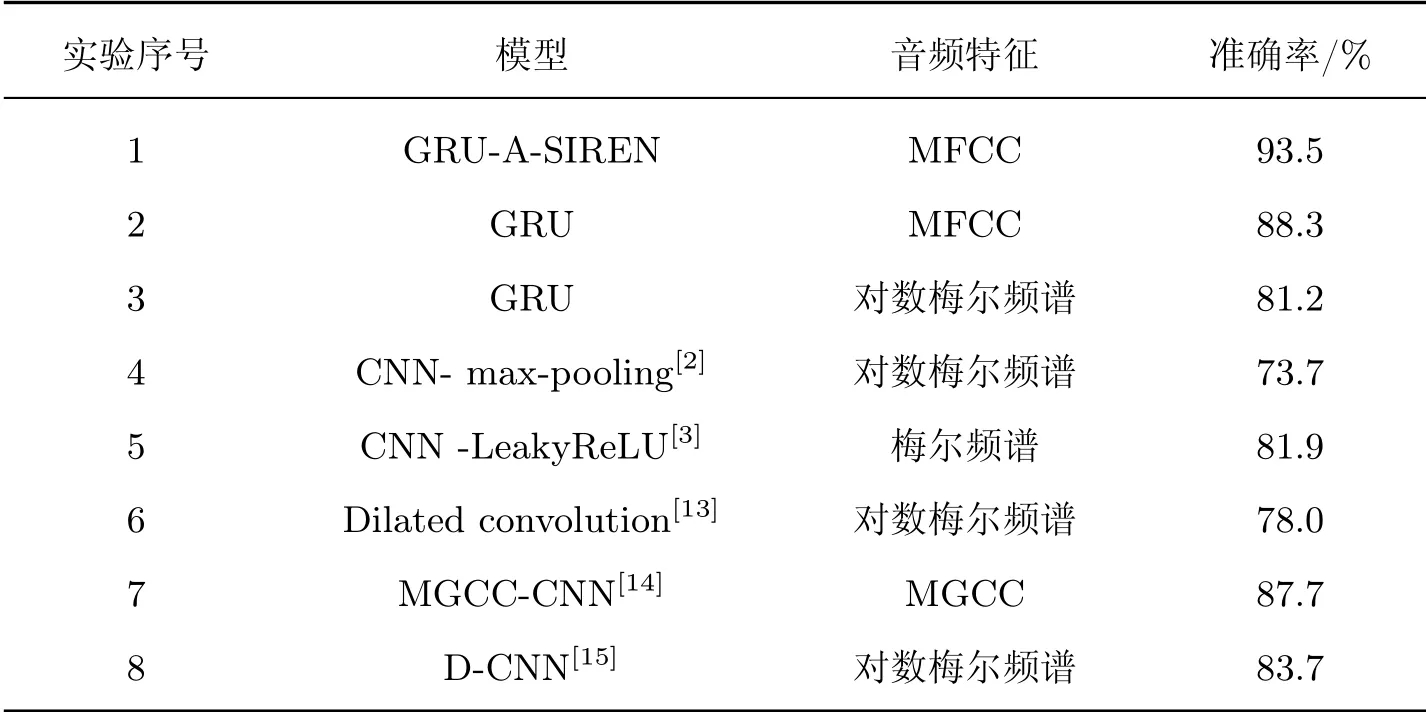
表3 与其他模型的实验比较Table 3 Experimental comparison with other models
将表3中实验1~3与实验4~8进行对比可以得出:以RNN为基础框架的网络在识别效果方面优于大部分CNN及其变体网络模型,如实验3仅用GRU网络模型结合梅尔频谱特征就可以获得较好的实验结果,这一结果超越了文献[2,13]CNN模型的实验结果。音频特征的时间维度不可忽略,而GRU网络在时间维度上具有很强的提取能力,正好可以作为本文的基础模型。将实验1与2进行对比的结果表明:本文提出的A-SIREN模型能将音频特征权重集中于分配于重要区域,从而提高环境声音识别的准确率,比原有GRU网络的模型提高5.2%。
在A-SIREN模型训练过程中,训练准确率与测试准确率随迭代次数的变化曲线如图4中的(a)所示,损失值随迭代次数的变化曲线如图4中的(b)所示。每50次迭代输出一个识别准确率。观察图4测试集与训练集的曲线变化规律发现:训练曲线模型在仅10次迭代时的识别率高达0.78,在第3 100次迭代时达到平稳状态(振幅≤0.005);最终识别率在0.93左右且波动小于0.003,表明该模型经过7 000步迭代已经收敛到最优值附近。在整个训练过程中,在训练集与测试集上的识别率相差小于0.10,且在稳定后训练集和测试集的损失值相差小于0.07,属于正常值范围,表明该网络拟合效果正常,并未出现过拟合现象。因此,A-SIREN模型既能较快较平稳地收敛,同时又能获得更好的实验结果,证明该模型可以有效地学习到音频类别规律信息。

图4 训练集与测试集上准确率和损失值的变化Figure 4 Change of accuracy rate and loss in training set and test set
本文以混淆矩阵[16]记录真实样本与预测样本的值,全局把握整体网络拟合效果,如图5显示。
该混淆矩阵显示了所有测试集的预测情况,横坐标代表预测标签,纵坐标代表真实值标签。颜色代表样本数量,颜色越深表示识别出正确的标签数量就越多,对角线数值越大表示模型的识别效果越好。在混淆矩阵中,数字1~10依次代表空调、汽车鸣笛、小孩玩闹、犬吠、电钻、发动机空转、枪声、手持式凿岩机、警笛和街道音乐。汽车鸣笛(类别2)与枪声(类别7)的数据少于其他音频类别的数据,其颜色浅于其他类别的颜色。本文根据混淆矩阵计算出每个类别的精确率Precision、召回率Recall、F1-score如表4所示。
表4显示了混淆矩阵各类指标的结果,其中街道音乐的精确度最低仅为0.86,分析原因如下:在识别街道音乐时,街道音乐会参杂小孩玩耍、车鸣等声音,其识别效果受到了影响,因此精确度远低于其他类别的精确度;同时从图5也可以观察出街道音乐与小孩玩耍的声音相互混淆。

表4 混淆矩阵分析结果Table 4 Analysis results of confusion matrix

图5 GUR-A-SIREN混淆矩阵Figure 5 Confusion matrix of GUR-A-SIREN
4 结语
本文总结分析了以往的环境声音分类系统,提出了A-SIREN模型。首先在音频特征的选取上以MFCC特征作为输入特征;其次在模型的构建上选择对传统的GRU网络模型进行改进,利用GRU网络进一步提取MFCC特征,同时结合注意力机制和正弦函数将音频每一帧的注意力隐藏层得分重新映射。实验结果表明:A-SIREN利用了正弦函数的周期性与可导不变性,故在Urban Sound 8K数据集的准确率比MGCC-CNN模型的准确率高出5.8%。在后续的研究中,我们会继续研究并改进音频模型。
