基于Q学习的星地融合协作传输中继选择策略
2022-01-19汪萧萧孔槐聪朱卫平林敏
汪萧萧,孔槐聪,朱卫平,林敏
1.南京邮电大学通信与信息工程学院,江苏南京210003
2.南京邮电大学宽带无线通信与传感网技术教育部重点实验室,江苏南京210003
卫星通信系统因其覆盖范围广、通信距离远、通信容量大、成本低等特点,在导航、定位、广播、应急和救援等众多领域中得到了广泛的应用[1-2]。卫星通信利用现代航空航天和通信技术,为全球固定和移动用户提供无缝连接和高速宽带接入。在地面无线系统难以部署或通信严重拥塞的地区尤为重要。卫星通信在覆盖范围、可靠性及灵活性等方面的优势能够弥补地面移动通信的不足,卫星通信与地面通信的融合能够为用户提供更为可靠的一致性服务体验[3-5]。在这种情况下,研究人员提出了星地融合协作网络(hybrid satellite-terrestrial cooperative network,HSTCN),通过获得空间分集增益提高卫星的通信质量[6]。
在HSTCN中,地面中继节点常见的协议主要有两种:放大转发(amplify-and-forward,AF)和译码转发(decode-and-forward,DF)[7]。由于AF协议是当前卫星通信系统中常用的简单协议,在实际应用中复杂度较低,因此本文采用AF协议进行研究。针对采用AF协议的HSTCN,文献[8-9]推导了系统的平均误符号率。文献[10]讨论了卫星和地面终端不存在直达径的情况,推导出系统的误比特率。文献[11]研究了基于满足用户最低传输速率的功率分配方案。此外,在HSTCN系统中,地面系统往往会存在多个中继辅助传输,为了减少资源浪费,提升系统性能,需要选择合适的地面中继节点进行信息传输。因此,针对多个地面中继辅助传输的HSTCN,文献[12]采用DF传输协议,在单用户场景下选择最优中继链路进行传输并分析其性能。文献[13]通过预测最佳信道质量信息来进行中继选择。文献[14]采用基于马尔科夫链的统计方法,选择出最优中继进行传输。文献[15]在遍历容量和系统能量消耗间进行折中来进行中继选择,同时分析其性能。然而,上述研究并未考虑路径损耗,也没有考虑源节点和中继节点之间的功率分配问题,这就使得所选中继对应的系统容量并不是最优的,从而造成系统性能的下降。
近年来,强化机器学习的发展以及在自适应优化控制、机器人规划与控制、电力系统、智能交通和工业控制等领域大量成功的应用案例,同样也受到了许多无线通信领域的专家与学者的关注与研究[16]。Q学习(Q-learning,QL)是强化机器学习的一种,其学习过程由环境的奖惩引导。QL通过执行动作并从环境中获得反馈来学习包含有限状态的环境。文献[17]首次提出了基于QL的功率分配算法,文献[18]利用QL完成了信道选择和功率分配,文献[19]提出了基于奖励值可变的QL算法,对中继选择和功率分配进行联合处理。
QL算法可以学习和适应不同的信道条件。在HSTCN中,当中继节点数变化时,QL可以结合以前积累的经验,优先选择信道条件好的中继进行传输,节省系统开支。因此,本文提出了一种基于QL的中继选择策略,在所有参与传输的中继节点中,选择一个最佳中继进行传输。首先,针对采用AF协议的HSTCN,在考虑小尺度衰落和自由空间损耗的基础上,得到系统输出信噪比(signal-to-noise ratio,SNR)。然后,设置QL算法中的奖励函数,根据信道状态信息,采用Boltzmann选择策略,以概率的方式优化动作选择,使QL算法尽可能探索所有状态,选出最优状态。接着,在所选中继与直达径间进行功率分配,使用拉格朗日乘子法得到最优功率分配表达式。最后,计算机仿真验证了理论推导的正确性,并讨论了地面中继数目对系统性能的影响。
1 系统模型
在HSTCN中,存在1个源节点卫星S,1个地面终端D,K个采用AF协议的地面中继R,其中系统中的所有节点均配置单根天线。源-中继-地面终端和源-地面终端之间为正交信道且通过时分多址(time division multiple access,TDMA)系统进行传输,系统模型如图1所示。

图1 HSTCN的系统模型Figure 1 System model of HSTCN
本文基于AF协议进行分析,信息传输过程可分为两个阶段。在第一阶段,S将信号同时传输给D和K个地面中继,则第i个地面中继和地面终端D接收到的信号分别为ysi和ysd,表达式分别为
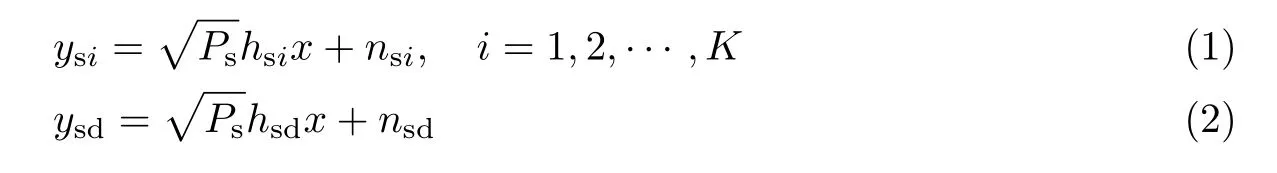
式中:Ps为源节点的发射功率;x为源节点的发射信号;nsi和nsd分别为第i个地面中继处和地面终端处的加性高斯白噪声,其均值为0,方差为σ2=κτB,其中κ为玻尔兹曼常数,B为噪声带宽,τ为噪声温度;hsd和hsi(i=1,2,···,K)分别表示S-D链路和S-Ri链路的信道响应。具体来说,表示卫星信道的小尺度衰落,其服从阴影莱斯(shadowed-Rician,SR)分布;Fsi表示卫星信道的路径损耗,表达式为

式中:c为光速;f为载波频率;dsd表示S到D的距离;dsi(i=1,2,···,K)表示S到第i个中继节点的距离;Gs表示卫星天线的增益;Gi表示地面中继节点天线的增益。
在第二阶段,K个地面中继节点采用AF协议将接收到的信号转发给地面终端。则地面终端接收到的信号为yid,表达式为

式中:nid为第i地面中继节点-地面终端的加性高斯白噪声,其均值为0,方差为σ2=κTB;βi为第i个中继节点处的放大因子,表达式为

式中:Pi是第i个地面中继节点的传输功率;gij=|hij|2表示节点i和节点j之间的信道增益。
在式(4)中,hid=Ei˜hid。hid(i=1,2,···,K)表示地面中继节点到地面终端的信道响应,表示地面链路的小尺度衰落,服从Nakagami-m分布,Ei表示地面链路的信道增益,表达式为

式中:PLi表示Ri-D链路的自由空间路径损耗,单位为dB,由文献[11]可知,其表达式为

式中:did(i=1,2,···,K)表示第i个地面中继节点到地面终端的距离;f表示载波频率。
在已知瞬时信道状态信息的前提下,在接收端通常采用最大比合并(maximal ratio combining,MRC)[20],接收信号表达式为

则在地面终端D处,输出SNR可以表示为

将式(5)代入式(9)可得

当中继数K>1时,基于精确信噪比的一般封闭式功率分配方案比较复杂,因此为了使接收端γd最大,对式(10)进行以下处理[20]:

在使用TDMA系统进行传输时,传输中继数与吞吐量成反比,即信息重复K次,系统吞吐量就降低1/(K+1)[7]。整个通信过程分成两个阶段:第一阶段,源节点将信号传给地面终端,S-D间的容量表达式为

第二阶段,信号通过地面中继节点参与协作传输传到地面终端,此时系统的总容量表达式为
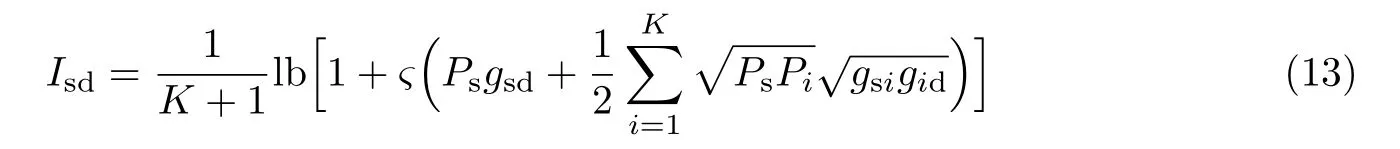
2 基于Q学习的中继选择算法
2.1 Q学习理论
QL算法是为任何Markov决策过程找到最优的行动选择策略。QL算法由有限、离散的状态集合S={s1,s2,···,sn}和动作集合A={a1,a2,···,an}和学习策略ε:S→A组成[16]。该算法通过与外界环境状态s∈S进行交互,根据动作选策略ε选择动作a∈A并反馈给环境,环境状态此时变成s′∈S,并接受来自环境的反馈。在反馈学习中,与当前行为相关的即时奖励记为r(s,a);QL算法根据此策略不断更新奖励值并生成Q矩阵,Q矩阵可以反映出智能体与外界交互的学习结果。学习的最终目标是找到每个状态的最佳策略ε∗(s)使长期期望回报最大,表达式为

式中:E[·]为期望函数;η∈(0,1)为常数时间折现因子。由文献[16]可得式(14)的最大值为

式中:R(s,a)为r(s,a)的数学期望;Ps,s′(a)为状态s在动作s′的作用下达到a的转移概率。
QL可以通过式(16)的迭代规则得到Q矩阵
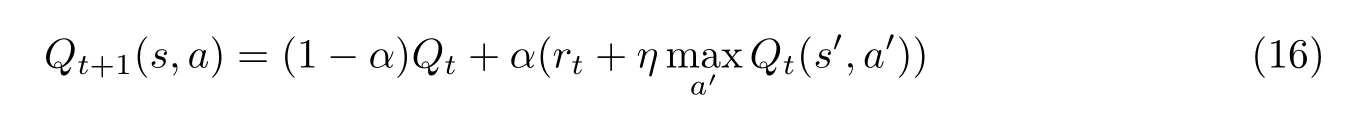
式中:α=1/(1+visit(s,a)),α∈(0,1]为学习率;visit(s,a)为(s,a)被访问的总次数。随着t→∞,每对(s,a)的Q值都能够逐次更新,最终Qt(s,a)将以概率1收敛到最优值Q∗(s,a)。
2.2 最佳中继选择
最佳中继选择将信道选择过程建立成一个有限的Markov决策过程,状态空间S、动作空间A、回报函数r设置如下:
1)状态空间S,每个地面中继节点各表示一种状态,则S由K个状态{s1,s2,···,sK}组成;
2)动作空间A,由K个动作{a1,a2,···,aK}组成,其中执行动作ai时总能进入状态si;
3)回报函数r,系统的目的是执行动作后选择出最优地面中继节点进行传输,获得最大吞吐量。因此,将输出端SNR的值作为回报值,在此阶段,进行等功率分配,即PS=Pi=P/2,表达式为

4)Q矩阵Q(st,at),Q矩阵由每个状态-动作对的Q(s,a)值所组成。最初Q矩阵的各项都为0,在QL算法中,用户选择一个动作at∈A并观察下一个相应的状态st+1∈S,同时更新Q矩阵。由于状态空间和动作空间都是1×k的集合,则k维Q矩阵包含了所有状态-动作对所对应的Q(s,a)值,表达式为

式中:Q(s,a)∈ℜk×k。每次迭代过程根据式(13)更新Q(s,a)值并储存在Q矩阵中。
对于状态s,用户若在早期选择了使Q(s,a)值最大化的动作,则在此后的探索中可能被束缚于此动作,而不去探索其他未尝试的动作,这些动作可能有更高的Q(s,a)值,那么该策略就存在风险。为了使用户能遍历所有动作而引入Boltzmann选择策略。该选择策略为每个Q(s,a)都赋予一定的概率,若Q(s,a)值较高则动作a被赋予较高的概率,反之则动作a被赋予较低的概率。具体概率赋予的方法为[21]

式中:P(ai/s)为在当前状态s下选择下一动作的ai概率;T>0为退火过程中的温度参数,T值的大小会决定选取Q(s,a)值的优先程度。若T值较小,则该策略赋予较高的概率来选择此动作。相反,若T值较大,该策略会使其他的动作有较高的概率。为了保证QL能够在时间上从“探索”平滑地过渡到“利用”,T值以较大的初始值逐渐减小至值Tfinal,即Tfinal=Tµ,其中µ为退火因子。
本文提出的基于QL的中继选择策略实际上是以最大化系统容量为准则,通过QL算法选择最优中继。并且Boltzmann选择策略使算法不会总选择回报值最大的动作,而是以一定概率选择其他可能的动作。基于QL中继选择策略流程如下:
1)初始化,将Q矩阵初始化为零矩阵,设置参数η、T、Tfinal、µ,随机选取一个状态s∈S作为当前状态;
2)动作的选择和执行,计算当前Q(s,a)值,利用Boltzmann选择策略从动作空间A中以概率P(a/s)选择并进入动作a;
3)获得奖励,中继节点被激活,源节点选择动作后,当地面终端通过式(17)获取奖励值r时,通过反馈通道将奖励值发送给源节点,更新矩阵的Q(s,a)值;
4)更新退火温度,每次迭代结束时更新退火温度T,即Tfinal=Tµ;
5)重复2)~4),直至结束。
结合Boltzmann选择策略,QL中继选择流程如图2所示。随着训练次数的增加,退火温度逐渐减小至最终退火温度Tfinal,训练过程结束。然后根据Boltzmann选择策略,选择Q(s,a)值较高的动作,实现系统吞吐量最大化。QL中继选择算法流程的伪代码如下:

图2 QL中继选择流程Figure 2 QL relay selection process

2.3 功率分配
当QL算法选出最佳地面中继节点时,根据式(8)优化问题可以表示为

用拉格朗日乘子法构造的拉格朗日函数表达式为
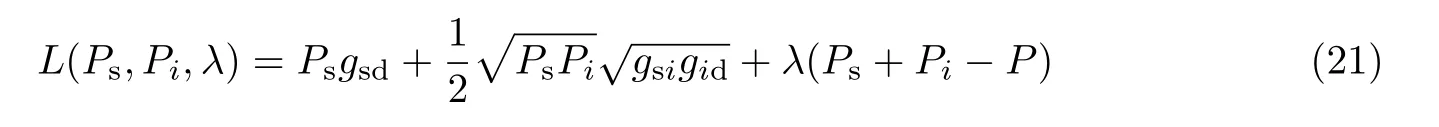
式中:λ为一阶拉格朗日乘子。由式(21)可得最优功率分配为

在上述情况下,当采用最优地面中继节点进行传输时,根据式(13),此时系统总容量表达式为

由于误码率(bit error ratio,BER)可以描述为一个系统的整体接收信噪比的单调递减函数,因此系统整体接收SNR的最大化也等于BER的最小化。选出最优中继节点进行传输时,对于不同的数字通信调制方式,BER可以统一表示为[22]

3 仿真结果与分析
本节通过计算机仿真来验证理论分析的正确性,同时分析了相关参数对系统性能的影响。本文协作传输机制采用QPSK调制,直传采用BPSK调制[15]。仿真参数设置如下:地面中继K=5,选用静止轨道上的卫星进行通信,载波频率为f=2 GHz,卫星天线增益GS=50 dB,地面中继节点的增益Gi=1 dB(i=1,···,K)。噪声带宽B=5 MHz,噪声温度τ=300 K。考虑卫星信道服从SR分布,参数为{λ,b,Ω}={5,0.251,0.279},而地面链路服从Nakagami-m分布,信道参数为{m,Ω}={1,1}。在QL算法中,设置折现因子η=0.8,退火的初始温度T0为1060,且以µ=0.9的负指数规律递减至最终温度Tfinal=0.1。
图3比较了QL算法、随机选择策略及理想中继选择传输策略的系统容量。可以看出,所提出的QL中继选择策略的性能接近于理想中继选择策略,均优于随机选择策略。当系统总容量相同时,与随机选择算法相比,QL算法所需的系统传输功率较小,在有限的功率资源下可以获得较好的传输性能。随着系统传输总功率的不断增加,QL算法的曲线上升幅度逐步逼近理想中继选择策略。因此,采用QL算法的中继传输可以有效地提升系统性能。

图3 K=5时不同方案的系统容量Figure 3 System capacity of different schemes when K=5
图4对比了不同中继数情况下QL算法中继选择策略和随机算法的系统容量。一方面,从图4中可以看出,随着系统传输总功率的增加,QL算法的性能优于随机选择算法;另一方面,随着中继节点数的增加,QL算法可供选择的中继节点增加,提高了选出最优中继节点进行传输的可能性,进一步提升系统容量,同时也表明了QL算法的实际应用价值。

图4 QL和随机选择算法在不同中继数下的系统容量Figure 4 System capacity of QL algorithm and random selection algorithm under different relay numbers
图5比较了不同中继数下QL算法和随机选择算法的BER性能。从图5中可以看出,与随机中继选择算法相比较,QL中继选择策略能显著的提高系统的BER性能。在中继数相同时,随着系统传输总功率的增大,与随机算法相比,QL算法能够提升系统的可靠性。随着中继数的增加,QL算法的曲线变陡,性能差异变化明显,选择最佳中继节点的概率也随之增加。

图5 两种算法在不同中继数下的误比特率Figure 5 Bit error rate of two algorithms under different relay numbers
图6对比了当系统传输总功率P=10 dBW时,不同算法中选择作为状态的中继平均数。在QL算法中,选择Q值大的作为状态并放入状态空间。在源节点与其他节点不交换信息的情况下,通过QL的自学习能力找到合适的中继作为状态,降低了系统的复杂度。随着中继数的增加,所提算法选择作为状态的中继数大大减少,极大提升了系统选出最佳传输中继的效率。
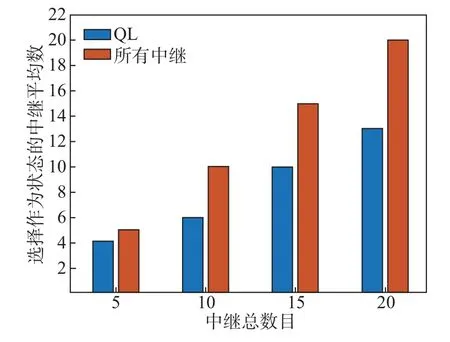
图6 不同算法选择作为状态的中继平均数(P=10 dBW)Figure 6 Average number of relays selected as states for P=10 dBW in different algorithms
4 结语
HSTCN是未来移动通信的重要组成部分,它的合理使用有利于提升卫星通信的可靠性和有效性。本文提出了基于QL的星地融合协作传输中继选择策略。首先,卫星将信号同时传输给地面终端和地面中继节点,得到中继节点采用AF协议时系统的输出SNR。然后,设置QL算法的参数,在Boltzmann选择策略的引导下进行中继节点选择。接着,在接收端进行功率分配,进一步提升系统容量。最后,计算机仿真验证了所提中继选择策略的正确性,并且表明QL中继选择策略优于随机中继选择策略。随着地面协作中继节点数目的增加,QL中继选择策略能为系统提供更多的增益,为QL算法在HSTCN中的应用提供了理论支持。
