基于图像梯度的数据增广方法
2022-01-19刘之瑜张淑芬刘洋罗长银李敏
刘之瑜,张淑芬,刘洋,罗长银,李敏
1.华北理工大学理学院,河北唐山063210
2.河北省数据科学与应用重点实验室,河北唐山063210
3.唐山市数据科学重点实验室,河北唐山063210
万物互联的时代,大数据已经逐渐成为数字经济形式下的驱动力,随着科技的不断发展,大数据必将成为时代发展最主要的“生产要素”。半结构化数据、非结构化数据是大数据的重要组成部分,图像类型数据占比大幅度提高,图像数据已经成为人类获取信息的重要方式之一。搭建卷积神经网络,采用深度学习算法已经成为图像识别领域中的研究热点,而图像数据集的优劣则成为提高的识别精准率的重要因素[1]。
2012年,Krizhevsky等[2]设计的AlexNet卷积神经网络有8层深度,分为5层卷积层和3层全连接层组成,在ImageNet[3]大规模视觉识别挑战赛中取得了突破性的进展,以低于第二名10%的错误率获得冠军并刷新了图像分类的记录。2014年,Simonyan等[4]提出的VGGNet卷积神经网络有16层深度,分为13层卷积层和3层全连接层,在ImageNet大规模视觉识别挑战赛的定位与分类问题上获得了第一名。同年,Szegedy等[5]提出了GoogleNet网络,该网络以Inception结构为创新点,扩大了网络的深度和宽度,提高了网络性能。2015年,He等[6]提出了ResNet网络,即残差网络,拥有152层的网络深度,在ImageNet大规模视觉识别挑战赛的分类任务中取得了第一名。从Krizhevsky等设计的AlexNet到He等提出的ResNet,网络深度增加了19倍,深层的网络拥有更好的网络结构和更高的准确率。然而随着网络层次的加深训练参数也会大幅度增加,例如AlexNet深度神经网络已有破百万级别的参数,需要有足够大的数据量才能进行训练,否则易引起过拟合。ImageNet大规模视觉识别挑战赛所提供的图像数据集图像种类超过2万种、图像样本超过1 000万。目前公开的数据集有MNIST手写数据集[7]、由微软赞助的COCO数据集、谷歌公司出品的Open Image数据集、CIFAR-10数据集[8]等。在实际研究和日常生产生活中通常根据实际需要采集样本生成所需数据集。图像数据样本采集不易,而标注训练样本亦需要极大的工作量,时间成本和财力消耗过大。在没有足够的数据集进行训练的情况下,往往对数据集进行增广操作,人工增加训练样本数据量。
本文提出一种基于图像梯度的图像数据增广方法,通过对输入图像的梯度值进行选择和处理,用精准裁剪的方法进行数据增广。采用部分PlantVillage[9]数据集,在开源的Tensorf low[10]深度学习框架搭建的VGG16模型上进行实验,采用预训练模型初始化网络参数,然后利用训练集再训练,进行微调。将训练集数据增广后训练模型,提高了模型的分类准确率,实验结果证明了方法的可行性。
1 数据增广
大规模数据集是成功应用卷积神经网络的前提。在数据集不足时可以通过数据增广增加数据集。数据增广是以原数据集为基础,在原始数据上做变动,产生相似但又不同的样本来增加数据集的数量,使模型能够得到充分训练,减少模型过拟合。同时,对原始样本的改变还可以降低模型对目标某些属性的依赖,进而提高模型的泛化能力[11]。因此,数据增广不仅可用来解决样本数量不足的问题,还能解决样本不均衡的问题。
图像的数据增广方式有很多,常用的方法主要有以下几种:
1)镜像(f lip),对图像进行水平和垂直翻转,一般采取水平翻转,垂直翻转可由图像旋转180°后执行水平翻转获得。
2)旋转(rotation),将图像进行任意角度的旋转,可能导致图像尺寸的改变。
3)缩放(scale),图像可以向内或者向外缩放,向外缩放会使图像的尺寸变大,往往在对一张图像进行裁剪操作后向外缩放,使图像大小等于原始图像;向内缩放会使图像尺寸变小,此时便需要对图像进行填充。
4)裁剪(crop),从原图像中随机截取部分,然后进行向外缩放,将此部分的大小放大为原始图像大小,通常称这种方法为随机裁剪。裁剪方法中常用的是四角和中心位置的裁剪。
5)色彩抖动(color jittering),对颜色的数据增强,图像亮度、饱和度和对比度变换。
6)高斯噪声[12](Gaussion noise),高斯噪声具有零均值的特点,其数据点可以分布在所有频率上,适量的增加噪声可以有效抑制过度拟合,例如椒盐噪声[13],表现为图像中的随机黑白像素点。
7)生成对抗网络(generative adversarial networks,GANs)[14-16]。GANs由生成器和判别器两个神经网络组成,二者之间相互搏弈,生成器生成与真实样本非常相似的样本,判别器判别生成样本和真实样本,经过训练,生成器可以生成与真实样本相差无几的样本。GANs目前主要应用于图像、视频、文本生成等领域,例如可以用来生成极其逼真的图像[17]。
AlexNet[2]在处理训练样本不足问题时使用了三种方法,分别是裁剪、水平翻转及色彩抖动,扩充了训练样本的同时降低了过拟合;Chatf ield等[18]在用CNN解决图像分类问题时使用了裁剪与水平翻转相结合的数据增广方法,用于探索不同网络框架的性能变化,得出了降低卷积神经网络输出层尺寸并不影响性能的结论;Raitoharju等[19]在使用AI技术分类识别无脊椎动物的任务中,使用了镜像和旋转的方法扩充训练样本,提升了模型精度;Limin等[20]提出了一种随机裁剪方法,将输入图像大小固定,裁剪高度和宽度随机选取,裁剪后将图片缩放到指定大小,达到多尺度增强和纵横比增强的效果。
随着图像处理技术的发展,提出许多新的数据增广方法。Cubuk等[21]提出了一种基于自动搜索的数据增广方法,该方法分为搜索算法和搜索空间两部分,搜索算法从搜索空间中选择最佳增广策略,搜索空间由搜索策略组成,这样神经网络将在目标数据集上产生最高的验证精度;Terrance等[22]提出了Cutout图像增广方法,在训练过程中随机屏蔽图像中某一方形区域,该方法容易实现并可以与现有的数据增强形式和其他正则化方法结合使用,以进一步提高模型性能;蒋梦莹等[23]提出了优化分类的数据增广方法,对测试集所有类别进行分析,找到分类效果不好的单类别进行数据增广,改善网络模型因训练样本不足、结构复杂引起分类效果差的现象。此外,迁移学习[24-25]亦可有效解决深度学习在训练过程中数据不足的问题,其主要思想是从相关领域中迁移标注数据或者知识结构、完成或改进目标领域或任务的学习效果[26]。
2 基于图像梯度的数据增广
在数学中,梯度是一个向量。函数在某点的梯度方向为方向导数最大的方向,梯度的模为方向导数的最大值。函数f(x,y)在点(x,y)处的梯度记作∇f(x,y)。梯度向量为

习近平总书记强调,现在我国经济已由高速增长阶段转向高质量发展阶段,要坚持新发展理念,使长江经济带成为引领我国经济高质量发展的生力军。推动长江经济带农业农村绿色发展,唱响质量兴农、绿色兴农、品牌强农主旋律,加快推进农业由增产导向转向提质导向,大力推进质量变革、效率变革、动力变革,有利于促进长江经济带农业高质量发展,推进生态宜居的美丽乡村建设,把绿水青山变成金山银山,实现生态美、百姓富的有机统一。
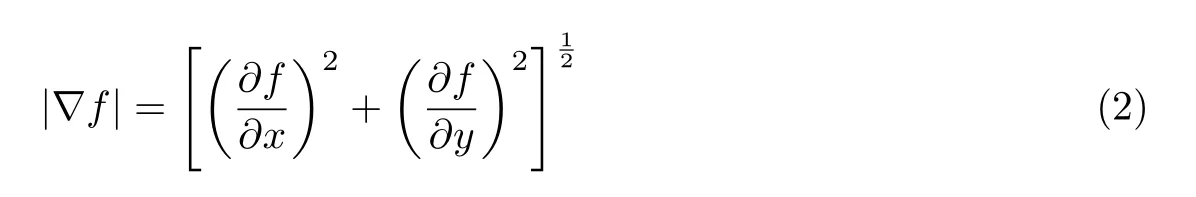
梯度的方向角为

图像的特征边缘包含了图像大部分的信息,梯度在图像的特征边缘变化明显。本文提出的图像数据增广方法以图像梯度值为研究对象,图像可被看作一个二维离散函数,求图像梯度值即是对这个二维离散函数求导(求偏导),本文仅用到了数值而不考虑方向。
图像梯度常用于边缘检测,在OpenCV中提供了很多用于边缘检测的常用算子,如索贝尔算子(Sobel operator)、普利维特算子(Prewitt operate)、罗伯茨交叉边缘检测(Roberts Cross operator)、拉普拉斯算子等。本文通过Python获取图像矩阵后应用Sobel算子计算图像的梯度值,图1为植物病害图像及其梯度值。图像在某像素点的梯度反映了该图像在此像素点处的像素值变化情况,其梯度值大小反映了变化的速度,由梯度值可以分析图像的特征变化信息。

图1 病叶图像及其梯度值Figure 1 Diseased leaf image and its gradient value
本文将图像的梯度值用于增广图像数据,通过精准裁剪的方式增加样本。选取梯度值中的最大值点作为裁剪图像的中心点,裁剪图像的大小为原图的70%(可调整)。以像素大小为320×320图片为例,采用笛卡尔坐标系,图片裁剪后像素大小为224×224。若裁剪中心点靠近图像边缘将导致裁剪图像的大小缩减。如裁剪中心点在图像右边缘时,裁剪后像素大小只有112×224,此时可将裁剪图像左移使其右边界与原图像的右边界重合,从而保证裁剪图像维持224×224不变,以保留图像的更多信息。增广效果如图2所示。

图2 图像增广图片示例Figure 2 Example of image enlargement
算法的伪代码描述如下:


3 实验与分析
本文选取了PlantVillage数据集中的5种病害图像,分别为玉米灰斑病、马铃薯早疫病、草莓叶焦病、苹果雪松苹果锈病、葡萄叶枯病,使用Tensorf low框架搭建VGG16模型进行训练。
3.1 数据集构建
采用PlantVillage数据集,选取其中513幅玉米灰斑病图像、1 000幅马铃薯早疫病图像、1 109幅草莓叶焦病图像、275幅苹果雪松苹果锈病图像、1 076幅葡萄叶枯病图像进行实验。5种植物病害图像样本示例如图3所示。

图3 5种植物病害图像示例Figure 3 Image example of f ive plant diseases
3.2 网络模型的搭建
模型的训练和测试均是在Tensorf low1.13.2 keras.2.1.5框架下完成的。Tensorf low由谷歌开发和维护,拥有各类应用程序接口,支持多种计算设备包括CPU/GPU/TPU。Tensorf low的灵活性和效率很高,它是一个采用数据流图用于数值计算的开源软件库,能够灵活进行组装图、执行图并支持多种语言。本文使用Python语言构建和执行网络模型,采用VGG16模型对数据集进行训练,输入图像像素大小为224×224,通道数为3,卷积核大小为3×3,输出特征图每次池化缩小一半,网络模型结构如图4所示。
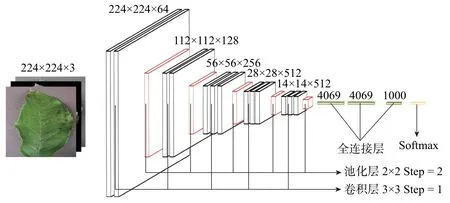
图4 VGG16模型结构Figure 4 VGG16 model structure
其参数数量如表1所示。

表1 VGG16模型参数Table 1 VGG16 model parameters
3.3 实验设备参数
使用Intel i5-8300H(8)@4.000 GHz CPU和Intel UHD Graphics 630 GPU及NVIDIA GeForce GTX 1050 Mobile GPU加速,Manjaro Linux x86_64操作系统,16GB运行内存。运行环境为Python3.6.8,编译器,Anaconda,Inc.tensorf low2.0.0a0。
3.4 实验结果与分析
VGG16模型对数据增广前后的训练集分别训练30epoch,用测试集测试并比较准确率和loss值曲线,loss值曲线如图5所示,准确率曲线如图6所示。loss值对比图中,valloss1(虚线)为数据增广前训练过程中的loss值变化曲线,valloss2(实线)为数据增广后训练过程中的loss值变化曲线,可以看出数据增广后的数据集训练出的网络模型,loss值更低,曲线更平稳,网络更稳定。

图5 数据增广前后loss值对比Figure 5 Comparison of loss values before and after data expansion
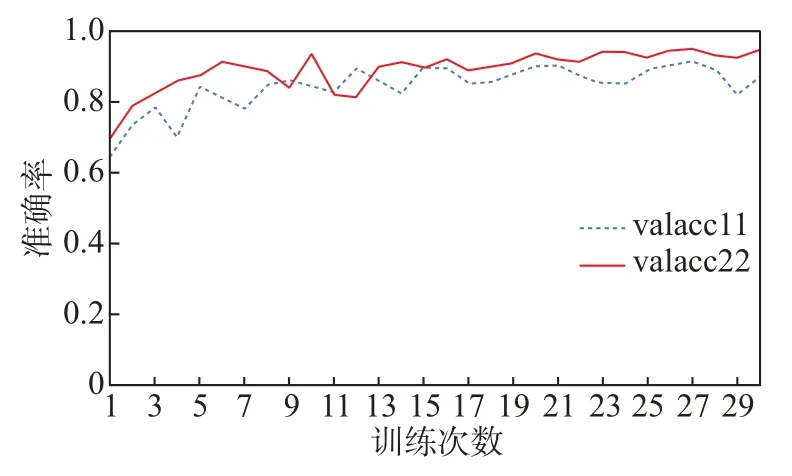
图6 数据增广前后准确率对比Figure 6 Comparison of accuracy before and after data expansion
准确率对比图中,实线为数据增广后网络模型分类准确率曲线,虚线为数据增广前网络模型分类准确率曲线,数据增广后测试准确率明显高于原始训练集训练的网络。分别取二者20次平均准确率,提升达到4.18%。这说明图像梯度指导的图像增广方法可以提升卷积神经网络图像识别的准确率。
选取苹果雪松苹果锈、葡萄叶枯病、草莓叶焦病3种植物病害图像,对单种病害图像数据增广前后进行网络模型的训练和测试,得出3种植物病害的测试结果。经对比分析发现,网络经过数据增广训练后,对苹果雪松苹果锈、葡萄叶枯病两种病害分别提升准确率4%和2%,草莓叶焦病有效减少过拟合,准确率由53%提升至82%,效果显著。详细数据如表2所示。

表2 5种植物病害准确率对比Table 2 Comparison of accuracy of f ive plant diseases %
选取旋转、镜像、放射3种方法分别扩充数据集,并使用已训练好的模型进行测试,分类准确率分别为:87.07%、91.14%、87.85%。经对比本文方法的分类准确率高于以上三者,详细数据如表3所示,说明本方法与旋转、镜像、放射3种方法相比,具有明显优势。

表3 4种数据增广方法准确率对比Table 3 Comparison of accuracy of four data augmentation methods %
4 结语
卷积神经网络克服了人工设计特征提取算子的弊端而被广泛应用于图像识别领域,通过训练卷积层可以自动提取图像特征,达到较好的分类效果。但卷积神经网络的训练需要有足够多的图像数据样本,实际中往往难以获得足够多的样本。本文提出了一种基于图像梯度的数据增广方法以解决此问题,该方法可以自由选择扩充数量和图像大小,有效扩充数据集,通过对比实验证明,通过该方法扩充数据集后,网络模型精度得到提升,在数据集较小的情况下提升更明显,同时可以有效降低过拟合提升模型准确率。
