Chiplet封装结构与通信结构综述
2022-01-19陈桂林王观武许东忠
陈桂林 王观武 胡 健 王 康 许东忠
1(国防科技大学第六十三研究所 南京 210007)2(战略支援部队31121部队 南京 210042)
在芯片过去几十年的发展过程中,研究者倾向于将更多的功能集成到一个芯片上,形成了今天智能手机和服务器上的片上系统形态[1],以手机上的片上系统(system on chip, SoC)为例,它集成了计算核心、图像处理核心、数字处理核心、通信模块、片上存储等.将多个功能模块集成降低了芯片的功耗,增加了芯片可靠性,更极大地节省了主板空间.不过大量的知识产权(intellectual properties, IP)集成引发了芯片内部的通信问题,此时研究者们引入了一种新的通信范式,即片上网络(network on chip, NoC)[2],用它来代替传统的总线结构.
近年来,随着芯片功能的复杂化,为了符合摩尔定律的规律,SoC芯片的成本正在大幅度提高.首先,在最先进的工艺下完成芯片所有功能单元的设计极大地增加了设计成本;其次,更多的功能单元和更大的片上存储将会导致芯片的面积增加,进而导致芯片良率下降,造成芯片的生产成本提高.针对这些问题,芯片制造商探索了2条解决路径:1)将面积过大的2DSoC做成单片3D(monolithic 3D, M3D)芯片,技术上采取外延延伸,在层间电介质的顶部沉积1层新鲜的硅,以形成有源器件的新表面;2)将大芯片拆分成单个的小芯片(Chiplet)再封装起来.但是由于目前的单片3D IC的工艺制造困难,除了闪存以外,M3D并没有达到堆叠式芯片集成(基于Chiplet集成)所能看到的投资水平.因此随着硅芯片尺寸达到制造极限[3],更多的研究机构和芯片制造厂商开始寻求使用先进的连接和封装技术,将原先的芯片拆成多个体积更小、产量更高且成本更低的Chiplet,再重新组装起来.这种封装技术类似于芯片的系统级封装(system in package, SiP)[4].SiP不同于SoC和分立器件,它是介于两者之间的折中方案,三者之间的比较如表1所示:

Table 1 Advantages and Disadvantages of Chiplet Technology, SoC and Discrete Devices
Chiplet方案正在被学术界[5-8]和厂商[9-20]广泛研究采用.本文收集整理了Chiplet封装结构和通信结构的相关资料,方便读者对其有一个整体的了解.
1 M3D和Chiplet
1.1 M3D
M3D是一种新兴技术,其集成密度比传统的基于硅通孔(TSV)的堆叠式3D IC高出几个数量级[21].近年来,虽然各大芯片厂商已经开始大量生产裸片堆叠结构的3D芯片,但是仍然有产商坚持在研究单体3D芯片,因为随着技术的发展,只要可以克服关键的制造挑战,M3D芯片可以提供更好的成本和性能折中方案.目前三星和高通仍在继续开展研究,并将其看作是SoC摩尔定律缩放的一种延续.
研究表明有2种方法可以实现M3D芯片:一种是外延生长,在层间电介质的顶部沉积一层新鲜的硅,以形成有源器件的新表面;另一种是将高质量硅层或者完整的器件层从牺牲晶圆转移到主晶圆上.IBM在2002年国际电子设备会议上就展示了转移完整器件层的可行性[22].另外CEA-Leti和M3D研究所也已经开发出了转移硅层的技术.该技术是基于意法半导体研究开发的FD-SOI工艺,其中晶圆键合技术是这种工艺的关键特征.另外这种层转移工艺对准精度的要求要比使用硅通孔(through silicon via, TSV)的芯片堆叠技术高出近2个数量级[23],因为它依赖于光刻设备的精度,而不是层转移和粘接设备.
此外,M3D的高密度集成也是由于其设计制造中使用了单体层间通孔(monolithic inter-tier vias, MIV)技术,这种技术类似于金属对金属过孔,可以实现非常细粒度的3D分区,但是MIV对工艺的要求非常高,图1展示了具有14 nm和28 nm NAND门的逻辑门、M3D采用的MIV和堆叠式芯片采用的TSV外形尺寸比较[24].
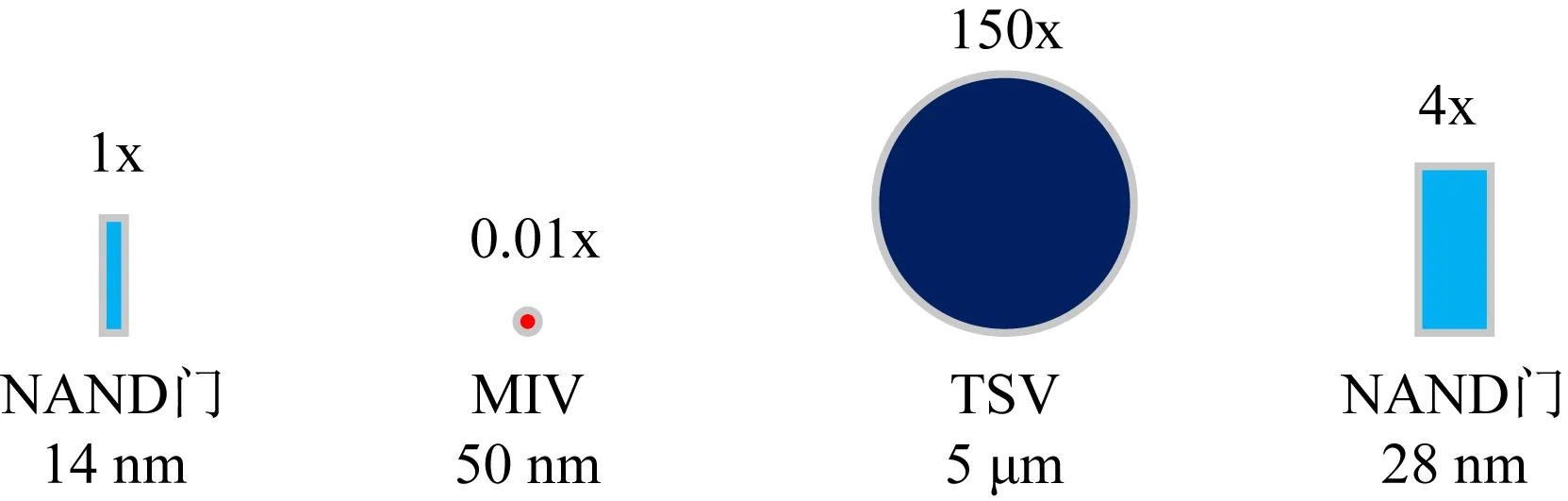
Fig. 1 Relative size comparison of 3D vias and NAND gates (14 nm and 28 nm)
因此,在先进的工艺节点下,虽然M3D可以作为现有工艺节点的扩展,但是由于其精度的要求高和制造的困难程度大,现有的成熟产品只在存储领域有应用[25],在制造工艺取得突破以前,堆叠式芯片仍然是各大芯片厂商的首选方案.
1.2 Chiplet
Chiplet的概念最早出现在2014年海思(Hisilicon)与台积电(Taiwan Semiconductor Manufacturing Company, TSMC)的晶圆级封装(chip-on-wafer-on-substrate, CoWoS)[9]产品上,不过真正得到推广是在美国国防部高级研究计划局(Defense Advanced Research Projects Agency, DARPA)的公共异构集成和IP重用战略(common heterogeneous integration and IP reuse strategies, CHIPS)项目[10].Chiplet是指一种IP核,也指代一种设计模式,为了将IP核重用而将其芯片化并单独封装起来.与传统的单芯片方案相比,Chiplet的设计良率更高,成本更小.研究表明当芯片面积小于10 mm2时,单芯片和Chiplet方案的良率差别很小,但是一旦芯片面积超过200 mm2,单芯片方案的良率会比Chiplet方案低20%以上.可以预期,在700~800 mm2的面积上,单芯片方案的良率可能不超过10%.Chiplet的另一个优势是允许将不同工艺下的芯片封装连接起来,对于模拟电路工程师来说,为了适应摩尔定律的变化,在先进工艺的约束下设计放大器变得十分困难.如果采用Chiplet方案,可以在适合的工艺节点设计模拟电路,使用最先进的工艺设计计算核心,提高先进工艺的利用效率,同时也降低了成本.例如Intel在其Chiplet方案Foveros中[11],将计算芯片使用先进工艺实现,将电源管理、模拟电路及各类传感器使用大节点工艺实现.Chiplet还可以将不同公司的芯片结合起来,例如最近宣布的采用AMD Radeon Graphics技术的Intel Core处理器[12].
目前Chiplet的发展很快,各大芯片厂商已经有基于Chiplet设计的产品,如AMD的第1代EPYC处理器[13]、第2代EPYC处理器[14]和第3代Ryzen处理器,Intel的Stratix 10 FPGA[15]和Lakefield处理器[11],Nvidia的MCM-GPU[16],法国CEA的96核处理器[17],赛灵思(Xilinx)的Vertix-7 FPGA[18-19],Marvell的MoChi[20]架构等.这些芯片都是基于Chiplet设计的,但是他们的封装方式和芯片之间的通信方式各不相同.目前主要用于集成电路封装芯片的3种互连技术分别是:引线键合技术(wire bond, WB)、倒装芯片技术(flip chip, FC)和硅通孔技术.
现有的封装结构区分主要通过2个方面:1)多个芯片是堆叠还是大面积拼接;2)芯片的拼接是否通过额外的中介层.基于这2个方面标准封装结构可以分为2D,2.5D,3D.通信结构主要分为2种:传统的总线或者NoC结构、其他基于总线或NoC的创新结构.采用2D封装结构的芯片既可以采用基于总线的通信结构,也可以采用基于NoC的通信结构.但是采用2.5D和3D封装结构的芯片大多使用基于NoC的通信结构.因为在3D封装中基于总线的通信结构设计过于复杂,引线太多,且理想的调度算法不易实现.
2 Chiplet的封装结构
目前Chiplet主流的封装方式有通过TSV进行堆叠,使用硅桥完成芯片的大面积拼接或采用中介层来完成芯片的连接.其中中介层可以分为有源中介层和无源中介层.这些封装方式按照结构又可以分为2D,2.5D,3D.
2.1 2D结构
我们将不通过额外中介层,直接互连芯片的形式称为2D封装,也叫多芯片模块(multi-chip module, MCM)化封装,其中最具代表性的是AMD采用其称为无限结构(infinity fabric, IF)的互连方式将多个Chiplet连接在一起,无限结构主要是由可扩展数据结构(scalable data fabric, SDF)和可扩展控制结构(scalable control fabric, SCF)组成.SDF中的芯片到芯片通信方法是这种多芯片封装方法的关键,该方法由SDF的相关AMD套接字扩展器(coherent AMD socket extender, CASE)组件实现.
第1代EPYC芯片[11]结构如图2(a),基于14 nm工艺实现,由4个Zeppelin die构成的,每个Zeppelin die包含2个CPU核心(CPU complex, CCX),CCX是AMD Zen架构的最基本组成单元,每个CCX整合了4个Zen内核,每个核心都有独立的L1与L2缓存,核心内部拥有完整的计算单元,4个核心共享L3缓存.此外,每个Zeppelin die还包括单独的内存,I/O complex和IF的控制与接口,每个Zeppelin die之间通过IF互连.EPYC芯片面积最终为852 mm2(每个Zeppelin的面积为213 mm2),如果在没有多芯片支持的情况下创建1个32核的单片芯片,最终芯片的面积为777 mm2[26],只节省了10%的面积,但是这种大型模具的制造成本和测试成本比4种小型芯片高出40%.除了成本上的优势外,多芯片设计还比单芯片版本提高了约20%的产量.
在第2代EPYC[12],为了突破以前芯片只能通过边界连接的界限,改变传统的以计算为核心的芯片设计思想,计算核心小芯片(core chiplet die, CCD)变成了可配置单元(每个CCD包含2个CCX),处理器的核心变成了输入输出芯片(IOD),其设计结构如图2(b)所示,其中CCD采用7 nm工艺实现,IOD采用14 nm工艺实现,芯片的封装结构还是2D的.但是采用组合工艺实现的芯片造价比单独7 nm实现的造价低.
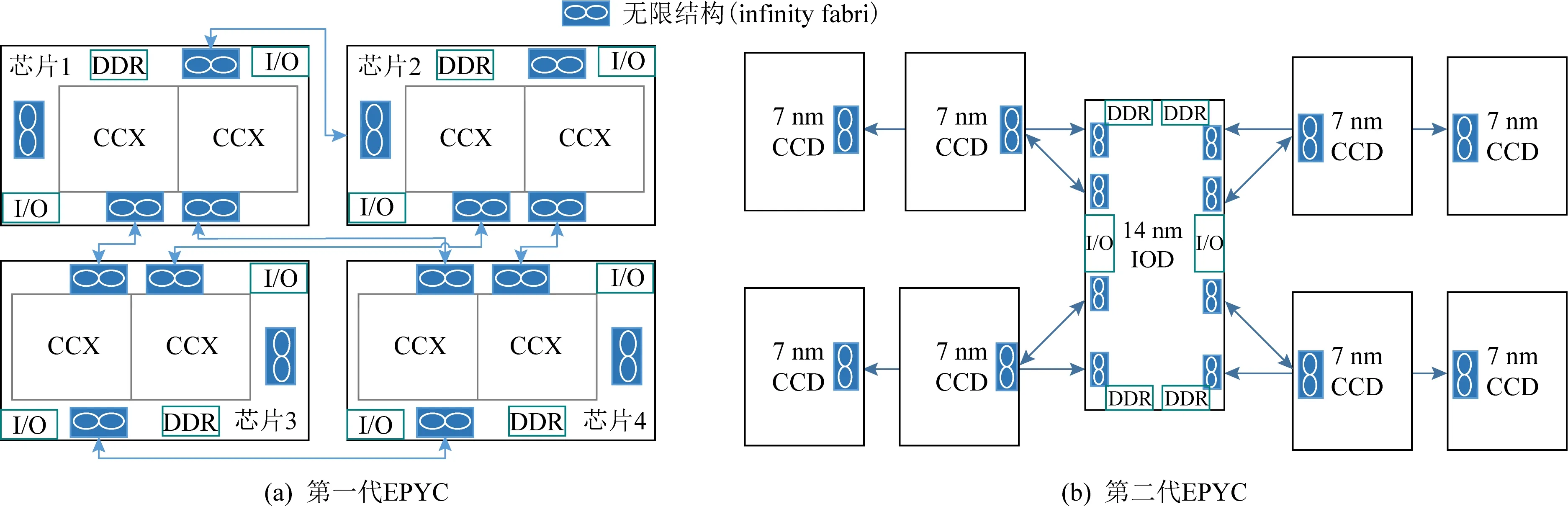
Fig. 2 The structure of EPYC
2.2 2.5D结构
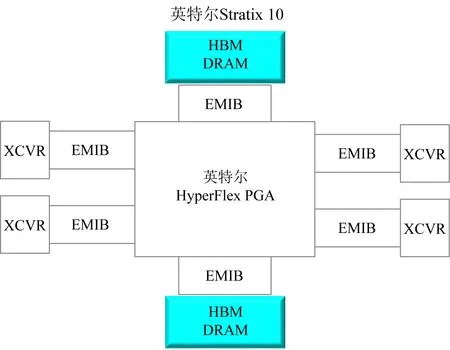
Fig. 3 The architecture of Stratix 10
我们将通过硅中介层来实现芯片连接的封装方式称为2.5D封装[27].具体来说,就是将芯片水平的堆在硅衬底上,硅衬底上带有TSV垂直互连通孔和高密度金属布线,这种只带有TSV和金属连线的硅衬底平台被称为无源中介层(passive interposers)[28-29].2.5D封装是目前主流的封装形式,Intel的嵌入式多硅片互连桥(embedded multi-die interconnect bridge, EMIB)技术[30]、TSMC的CoWoS架构[31]、Marvell的MoChi架构[20]都是典型的2.5D封装结构,其中EMIB技术没有使用全硅中介层,而是在衬底上安装了1个很小的嵌入式硅桥,允许主芯片和辅助Chiplet以高带宽和短距离连接在一起,和大型中介层相比,这种方案实现的花费更小,Stratix 10 FPGA就是使用EMIB实现的.如图3所示,Stratix 10的中心是Intel的HyperFlex FPGA,周围是6个Chiplet,其中4个是高速收发芯片,2个是高带宽内存芯片,物理上连接每个Chiplet到中心FPGA的就是EMIB,它们被封装在1个芯片内.采取这种方案,Stratix 10集成了3个厂商的6种技术,实现了不同厂商之间基于Chiplet的互用性.另外存储芯片中HBM也是采用2.5D堆叠方式实现的.
对于采用无源中介层的2.5D封装结构,无源中介层只作为芯片之间的连接,无源中介层中不含有有源器件,仅包含芯片和TSV之间的金属布线用于信号进入/离开芯片.图4是1个2.5D封装结构的实例.2.5D封装结构通常将芯片面朝下安装在具有一系列微型凸点(micro-bumps, μbumps)的中介层上.目前的μbumps间距为40~50 μm,正在开发20 μm和10 μm的间距技术.μbumps提供从上层堆叠的芯片到中介层里金属布线层的连接.金属布线层采用与常规2D独立芯片上金属互连相同的后端工艺制造.中介层上还使用了1个超薄芯片,用于TSV将输入输出路由到C4凸点.数据从芯片出发,通过1个微凸点,穿过中介层的金属布线层,在通过另一个C4凸点,最后达到目标芯片的顶层金属.
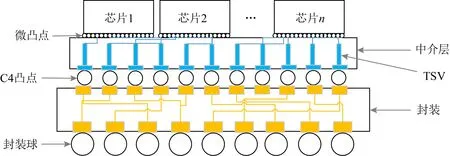
Fig. 4 2.5D packaging structure
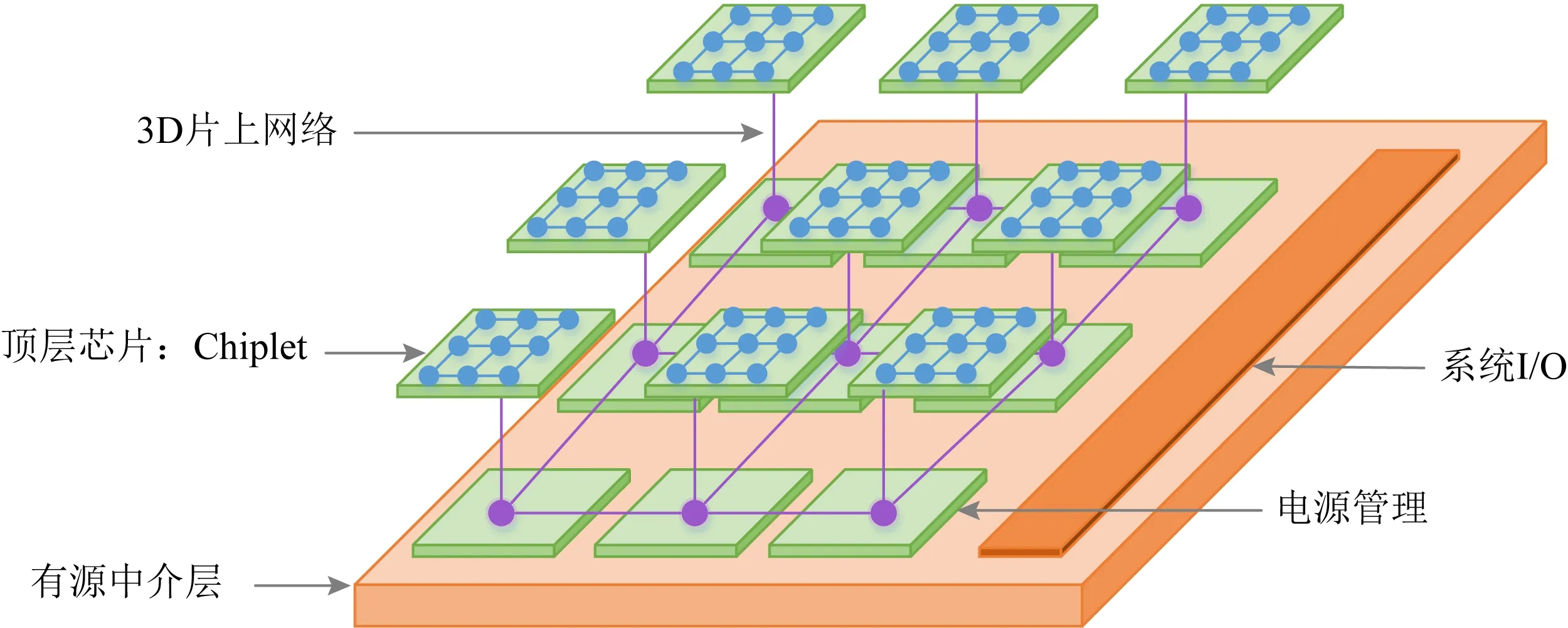
Fig. 5 3D packaging based on active interposer
2.5D的封装设计方式有利于将多个制造商不同工艺的芯片组合起来,无需协调组成芯片的设计方式.但是中介层只有连接芯片的作用,造成了资源上的浪费.因此越来越多的芯片制造商开始在中介层中使用有源逻辑,以进一步优化系统.
2.3 3D结构
3D封装是指利用TSV将芯片像积木一样垂直堆叠起来,其中利用有源中介层(active interposer)的芯片堆叠方式严格划分属于2.7D.法国CEA提出的96核处理器[17],就是采用基于有源中介层的封装方式,Intel提出的Lakefield架构[11],采用Foveros封装技术,在2D平面上通过EMIB实现芯片互连,在3D垂直方向通过TSV实现芯片的堆叠,内存芯片HMC也是采用3D封装技术.TSMC基于扇出(fan-out, FO)技术[32]提出的InFO封装技术去掉了硅中介层,直接将芯片埋进塑料里,以铜柱实现3D封装互连,应用到手机处理器的封装中可以减少30%的厚度,苹果公司的A10处理器首次使用了这个技术,并使用在之后的A11,A12处理器中.
与完全采用3D堆叠的芯片散热问题[33]相比,借用有源中介层实现的封装芯片降低了功率密度,简化了输电网络,因此散热可以与标准的2D封装媲美.并且有源中介层可以实现电源管理、部分模拟电路以及系统输入输出等功能,可以实现SoC的基础架构逻辑(时钟、测试、调试)和传感器.如图5所示,使用有源中介层的3D封装方式是将先进工艺实现的计算芯片堆叠在大工艺节点制造的基底芯片上,计算芯片和基底芯片通过TSV互连,同时计算芯片之间的通信则是通过基底芯片中的互连实现的.基于此,设计人员可在新的产品形态中融入不同的技术专利模块与各种存储芯片和I/O配置.并使得产品能够分解成更小的“芯片组合”.以Intel第1款CPU混合架构产品Lakefield[11]为例,高性能运算芯片采用10 nm实现,基地硅片采用22 nm实现,集成了CPU处理器、GPU核心显卡、内存控制器、图像处理单元、显示引擎,以及各种各样的I/O输入输出、调试和控制模块.最后这颗芯片的尺寸长宽只有12 mm×12 mm,高度仅1 mm,待机功耗2 mW.
互联网+立足于云端,各类信息数据较多。互联网渗透到文化领域中,能够在技术应用、商业模式以及产业组织中发挥重要作用,符合当前时代发展的特点。随着现代信息技术的快速发展,人们的阅读方式也在逐步发生转变。传统的纸质阅读方式逐渐转变为电子书等数字文件,同时,用户的学习模式也在发生变化。在科学技术的带动下,图书馆行业要坚持与时俱进,将先进的思想理念融入到互联网技术和云计算技术当中。此外,应适当创新高校图书馆的知识服务模式,使高校图书馆向着现代化、开放化的趋势发展,为用户信息资源的获取带来更多便利。
由此可以看出通过3D堆叠的SiP封装来进行异质芯片整合将成为后摩尔定律时代重要的解决方案,芯片不再强调制程微缩,而是将不同制程芯片整合为1颗SiP模块.
3 Chiplet的通信结构
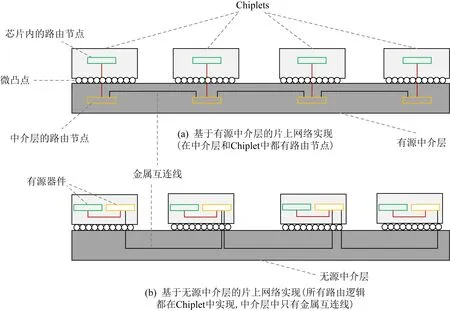
Fig. 6 Implementation of NoC with different interposers
芯片的主流通信结构有总线和片上网络2种,但是目前Chiplet之间的通信没有统一的标准,各个厂商都有自己的通信方案.例如AMD采用的可扩展数据结构(SDF)[13],TSMC采用的LIPINCON技术[31],Intel采用的高级接口总线(advanced interface bus, AIB)[30]和其他厂商的NoC结构[17,34].本文不讨论具体的通信细节和标准协议,只讨论各个产商采取的通信结构.大多数Chiplet之间的通信结构还是基于总线和NoC的创新.例如AMD的第1代EPYC处理器就是类似总线的通信结构,没有路由节点,芯片之间只能进行边到边的通信.第2代EPYC处理器就类似于NoC的结构,中间的I/O芯片是起到节点路由的功能,所有的芯片通信都必须通过它来调度.基于总线的通信结构更加简洁,没有路由节点的开销,但是一旦Chiplet的数量过多,通信就会变得低效,并且只针对边到边的通信结构也不支持多个芯片通信.如果采用路由节点,以2代EPYC为例,芯片设计以I/O芯片为核心,将计算芯片变成可扩展的部分,如图2(b),所有计算芯片通过无线结构和I/O芯片相连,数据的输入输出由I/O芯片统一调配,各个计算芯片之间没有数据通信.这就消除了原先计算芯片之间相连,但是只能边与边通信的限制.并且采用I/O芯片统一调配的方式还可以有效降低芯片通信死锁的风险,缺点是所有芯片的通信都必须通过I/O芯片,一旦芯片过多,需要设计高效的仲裁算法且仍会效率降低.解决方案是采用中介层来实现片上网络.
不同中介层实现NoC的方法不同[35],为了在有源中介层中实现NoC,我们只需将NoC链接(电线)和路由节点(晶体管)都放在中介层,图6(a)显示一个小型的采取有源中介层的NoC实例,其中NoC的链接和节点全部在中介层上.如果使用无源中介层,不能放有源器件,如图6(b),将路由器的活动组件(例如缓冲区、仲裁器)放置在CPU裸片上,但是NoC链接仍使用中介层的路由资源.这种方法可以利用中介层的金属层进行NoC路由,但要花费一些CPU裸片来实现NoC的逻辑组件.图6中的2个NoC在拓扑和功能上都是相同的.
基于中介层的NoC结构更加高效,但是节点开销较大,不过在大量Chiplets通信的情况下性能更好.NoC提供了统一的接口来连接不同的系统组件.NoC方法不是要求系统设计人员对每个通信模块之间实现特定的接口,而是采用了模块化和可扩展性更高的设计方法,从而使不同的小芯片自然地组合在一起.路由会显著影响网络性能、可靠性和功耗[36].设计不正确的路由算法可能会导致网络中的资源依赖关系,从而导致死锁,这可能对系统造成致命影响.解决死锁的方案有虚拟通道[37-38]和转向模型[39-40],其中虚拟通道必须提前配置且每个虚拟通道都有自己的输入缓冲区,增加虚拟通道的数量会增大NoC的面积,代价很高;另外,在3DNoC中,基于转向的算法要求每个路由节点都与其他芯片层垂直连接,增加了每个芯片层的TSV区域开销,代价也很高.因此,针对这种具有各种拓扑结构的小芯片系统,南加州大学和多伦多大学联合提出了一种模块化的,没有死锁的路由方法[41].该方案无需了解其他Chiplet或中介层NoC的详细信息,每个Chiplet都可以单独设计.从任何一个Chiplet的角度看,系统的其他部分(与Chiplet的总数或者中介层的复杂性无关)都可以看作1个虚拟节点,然后应用了转向限制的边界路由将Chiplet和虚拟节点连接起来,这种模块化的方法易于分析和优化Chiplet的粒度.
4 Chiplet的发展机遇和挑战
本文讨论了Chiplet的兴起和发展.随着SoC的集成度不断增加,先进工艺制程的芯片的研发成本和制造成本呈几何式增长,摩尔定律已经接近极限.为了拓展摩尔定律,芯片设计者将IP硬核逐渐芯片化,形成Chiplet,然后以SiP的形式封装形成系统,这也是摩尔定律的一次革命.目前Chiplet封装和通信的发展仍然充满挑战,首先是封装标准和通信接口不统一,各个厂家都有自己的方案;其次是散热问题,将多个芯片堆叠封装在一个有限空间会造成温度过高;再者是芯片网络通信问题,每个芯片都有自己的通信网络,整个网络如何避免死锁;最后是没有成熟的EDA工具,在芯片设计中30%~40%的成本是工具软件,DARPA的CHIPS项目中的一个关键工作就是EDA工具,Chiplet的互连、封装和测试都需要工具的支持.不过挑战总是伴随着机遇,以下4个方面或许会是Chiplet未来的发展趋势.
1) 任何技术的革命都伴随着多门学科的研究突破,Chiplet的3D封装散热问题可能随着满足集成电、热、力特性的新材料开发得到解决.
2) 工艺技术的创新会推动封装结构的创新,新型引线键合技术、圆片键合技术的开发应用将会推动封装结构由2D向3D的装换.
3) 3D封装结构带来的通信问题可以使用3DNoC来解决,但3DNoC存在更多的死锁隐患,因此未来通信结构的研究会聚焦对3DNoC开发高效的避免死锁的方法.
4) 开发新的集成系统测试工具和方法.
最后,随着5G时代的到来,基于Chiplet的产品设计成本低、上市周期快,未来在穿戴领域、物联网领域都有广阔的应用前景.
作者贡献声明:陈桂林负责论文观点的归纳总结提炼;王观武和王康负责收集Chiplet封装的相关资料;胡健负责收集Chiplet通信的相关资料;许东忠指导论文结构和Chiplet的发展方向.
