基于优化深度置信网络的多源异构数据清洗算法研究
2022-01-18程大勇
程 大 勇
(安徽工业职业技术学院, 安徽 铜陵 244000)
0 前 言
随着工业产业信息化的发展以及工业4.0时代的到来,面对海量的工业大数据,系统分析技术的重要性日渐凸显。工业设备的数量及复杂程度倍增,使得工业设备监控大数据出现了PB级的增量趋势[1-2],数据结构也表现出多源异构性、冗余性、不完整等复杂性[3-4]。由于传感器采集到的工业机械设备大数据来源、结构、形式均不同,其中包含大量的高维序列数据[5],而且受到系统噪声与环境噪声的干扰,因此从海量多源异构工业大数据中提取到有用信息的难度较大。
为了提高工业大数据的采集质量,需要采用数据清洗的方法对原始数据进行预处理。目前常用的工业大数据清洗方法主要分为数据统计清洗和平滑降噪清洗。数据统计清洗方法,是指基于数据时间序列模型建立自回归方程,剔除干扰数据和错误数据,从而识别出有价值的故障数据[6]。平滑降噪清洗方法,是指通过调整滑动窗口对原始数据的序列值进行加权运算[7],剔除冗余数据和错误数据以避免干扰,最后保留核心数据的原始特征。但面对工业故障大数据集规模急剧扩张、数据维度呈线性迅速增长的趋势[8-9],这两类数据清洗方法的效率有所下降,需要进一步优化。
针对海量工业大数据的多源异构性特征,在此提出一种基于优化深度置信网络的大数据清洗算法。在Hadoop框架下,基于曼哈顿距离(Manhattan Oistance)法计算多元异构数据的相似度,同时利用经过优化的深度信念网络模式对数据集进行约简,剔除干扰并提取核心数据特征,从而实现对海量多源异构工业大数据的清洗。
1 Hadoop框架下的数据相似度计算
Hadoop是面向海量大数据开发的一种分布式基础架构,更适用于多源异构工业大数据的预处理。Hadoop架构的核心是分布式系统(hadoop distributed file system,HDFS)和MapReduce模型,HDFS可满足海量数据的存储要求,MapReduce可满足海量大数据的并行计算要求。Hadoop框架的文件系统采用仿磁盘设计,可减少节点开销,有助于提升工业大数据的存储效率。HDFS主要负责管理Hadoop框架中各数据节点的存储和调用,数据库的存储方式满足对大文件存储的需要,存储与使用空间也得到了优化。作为Hadoop框架中系统文件的管理者,HDFS还负责向全部数据节点发送信息,以保证框架范围内数据处理信息的共享。
MapReduce并行计算架构的主要组成部分包括负责业务接收的客户端、负责数据匹配的作业服务企业和负责分配的任务服务器,其具体工作流程如图1所示。

图1 MapReduce模块工作流程
MapReduce模块采用并行计算的方式,每个节点都能够独立地进行数据清洗等数据预处理活动,采用多跳通信的方式共享信息,并汇报当前节点的任务完成情况。面对海量的多源异构工业大数据,Hadoop框架中的Sqoop模块能够协助MapReduce模块实现大数据的临时存储,避免核心数据丢失。
Hadoop框架的分布式结构和并行计算方式,使海量的多源异构工业大数据的清洗工作具备了软硬件基础。大数据清洗的内容通常包括数据预处理,距离计算与特征选择,数据清洗与分类,以及清洗结果检验。将传感器采集到的原始数据以数据表、图形、视频和文字等不同形式存储于数据库中,进一步按照数据的基础格式和特征聚类,并基于曼哈顿距离法判断原始数据与中心点之间的距离。在信号采集和机械故障数据提取的过程中,采用曼哈顿距离来描述高维空间内数据之间的相似程度。假定工业大数据的空间维度为D,xmk为m条工业大数据样本中的第k个特征值,xnk为n条工业大数据样本中的第k个特征值,两者之间的相似度用曼哈顿距离dxmk,xnk来表示:
(1)
计算原始工业大数据的相似度,有助于识别多源异构数据之间较为明显的差异,进而准确地定义数据清洗规则及特征选择方式。利用Hadoop大数据框架和曼哈顿距离计算法,可初步去除原始工业大数据的冗余特征,提升后续数据约简、清洗的效果。
2 基于机器学习的多源异构大数据清洗
将机器学习算法引入工业大数据清洗中,利用深度信念网络模型剔除冗余干扰数据,并提取数据的混合特征,提升故障信号识别的准确率。
2.1 深度信念网络模型的构建与优化
深度学习源于人工神经网络,是机器学习的一种高级形态。以深度学习为基础而构建的深度信念网络模型,摆脱了传统神经网络模型中间隐含层数量的限制,可根据数据集的规模自适应性调整模型的数据分类与处理能力。设深度信念网络模型M包含P层节点(M1,M2,…,MP),输入信息I经过中间层处理后使输出值集合O与理论值的偏差最低。深度信念网络模型在结构上结合了无监督训练与有监督学习的双重优点,它由一层具有监督功能的反向传播网络及若干层无监督的RBM(玻尔兹曼机)构成(见图2)。
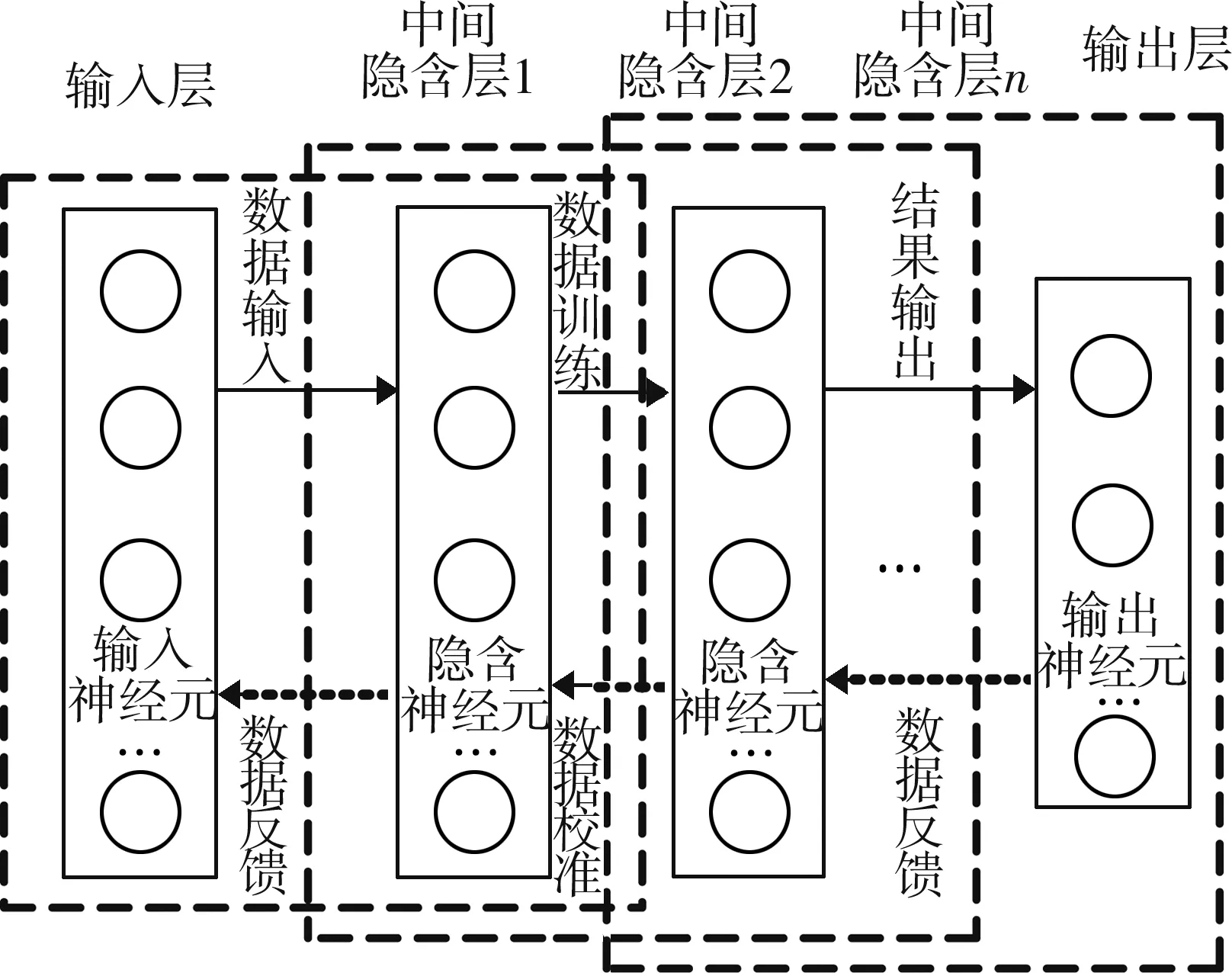
图2 深度信念网络模型结构
RBM作为深度置信网络中的核心组件,能够解决多源异构工业大数据的冗余数据去除和特征提取问题。每一层RBM结构中又包含可视层和隐含层数据,其中预处理大数据经训练后的输入取值具有多样性特征。如果可视层包含了a个节点数据(v1,v2,…,va),隐含层包含了b个节点数据(h1,h2,…,hb),则这两个层级之间的节点权重矩阵W表示如下:
(2)
由于训练多源异构大数据的难度很大,且待处理数据的概率分布位置不一致,因此只能通过实际输出结果与理论输出结果之间的差异来分析输入数据与训练数据的变化趋势。与曼哈顿距离评价相似度的方法相类似,利用RBM的能量函数能够进一步描述出不同来源、不同结构数据之间的差异。对能量函数E(vi,hj)的描述如下:
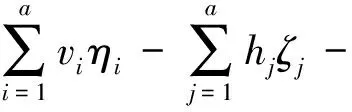
(3)
其中,ηi、ζj是分别与节点数据vi、hj对应的初始偏置值。基于能量函数计算可视层节点和隐含层节点的联合分布概率P(vi,hj):
(4)
其中,分母项是能量函数的归一化系数。通过联合概率函数值的分布观察各节点变量的当前活跃程度,并优化深度置信网络模式。通常情况下,是将原始的工业大数据样本输入RBM层,而中间隐含层各节点处于相互独立的状态。当hj=1时,联合概率的分布满足如下条件:
(5)
式中ξ为二值型Sigmoid函数,在数据训练和输出时可用于调整深度置信网络的分割值区间。当Sigmoid函数的自变量取值范围为(0,1)时,联合概率分布函数会呈现单调连续变化的形态。RBM隐含层的节点被激活后将hj值反向输入深度置信网络,完成对可视层节点状态的重构,以获取原始数据样本的近似值。数据的训练需经过多次反复迭代,使拟合后的实际样本输出值与理论值趋近。
2.2 数据的约简与分类清洗
深度置信网络模型可以根据输入的工业大数据集规模大小而变化,中间隐含层的复杂程度也可以调整;但对于多个不同的任务数据集而言,在多源异构环境下数据源中会出现大量冗余或不相关的数据。利用深度置信网络模型清洗原始工业数据,除了需滤除系统噪声和错误数据的干扰之外,还应对数据集进行属性约简处理,以去除过多的冗余干扰数据。多源异构数据的特点是,从多个角度描述设备的故障状态,并提供多个数据源。这些数据源之间存在不同程度的关联,属性约简的作用就是对同源数据之间的关联度进行判断。
假定经过预处理的原始工业数据以数据表的形式存在,数据表t的数量为q,它们共同构成数据表集合T={t1,t2,…,tq},且任意一个独立的数据表ti都包含g个属性C={c1,c2,…,cg}。计算各数据表字符串之间的编辑距离,然后再利用曼哈顿距离法评价和判断字符串之间的相似度,采用插入、删除或替换等多种操作方式测试字符串和数据表之间的曼哈顿距离。曼哈顿距离越大,则表明数据之间的相似度越小。定义字符串si和sj之间的曼哈顿距离为dsi,sj,数据表ti和tj之间的相关系数为ρti,tj。设数据表之间的经验参数阈值为φ:当ρti,tj>φ时,ti、tj之间不存在数据上的关联,而当ρti,tj<φ时,ti、tj之间有一定的关联。最后,筛选和确定字符串之间的曼哈顿距离dsi,sj,删除重复的字符串和数据表,实现数据约简分类。
每一组源数据都是由若干个样本信息组成,如果有两组源数据的全部属性特征一致,则表明存在数据冗余的情况。数据属性的相关度可作为判断属性重要性的依据,数据源组的密度决定数据重复出现的次数。工业大数据清洗的数据源组密度如图3所示。在数据属性空间内,位于低密度空间的对象通常为异常值。参照高密度空间的数据分布特征,对低密度区域空间数据进行属性约简处理,剔除掉多余的重复记录。
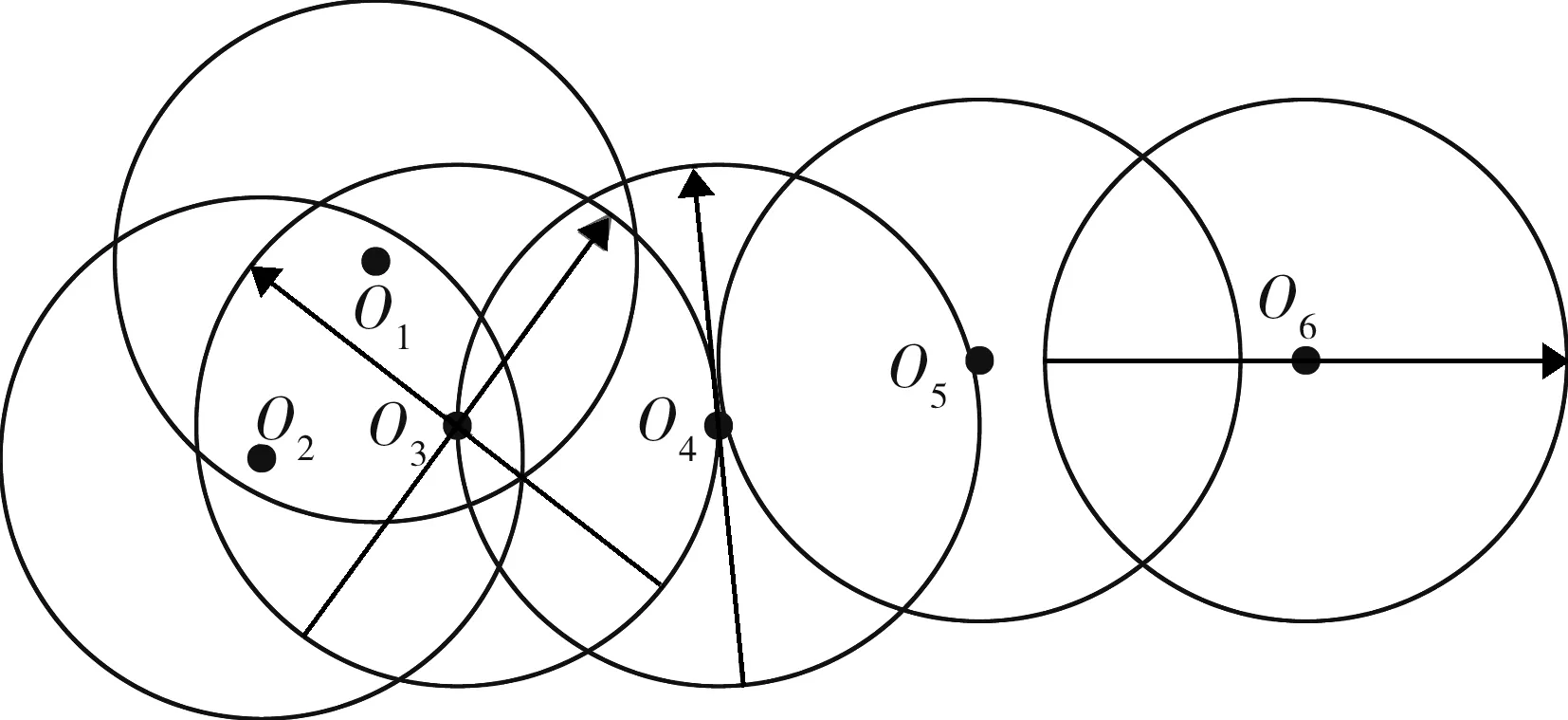
图3 工业大数据清洗的数据源组密度示意图
当一个数据源组出现在密度较低的半径区域(如O6半径区域)内时,若清洗中出现了数据特征相同的情况,则此数据通常被认定为冗余数据。以深度置信网络模型为基础,利用数据之间的曼哈顿距离和能量函数值即可有效去除冗余、错误或不完整的数据。同时,Hadoop大数据框架具有强大的并行计算能力,在其基础上又进一步提高了数据清洗和分类的效率。
3 算法实验与结果分析
3.1 Hadoop集群的搭建与软硬件环境设置
在Linux仿真环境下搭建Hadoop平台,并安装虚拟机。为了提高大数据框架的运算效率,利用HIVE数据仓来存储数据,并通过Sqoop实现数据加载。Hadoop集群由一个主节点(ZA1)和3个从节点(ZS1、ZS2、ZS3)组成。其中,主节点的CPU选用Intel Corei9 7980XE,主频达到3.6 GHz,运行内存16 GiB,储存内存2 TiB;各个从节点的CPU选用Intel Corei7 9700,最高主频达到2.93GHz。Hadoop集群的软件系统设置如表1所示。
Hadoop集群各节点的IP地址如下:
主节点ZA1,IP地址为192.168.2.130;
从节点:ZS1,IP地址为192.168.2.115;ZS2,IP地址为192.168.2.123;ZS3,IP地址为192.168.2.124。
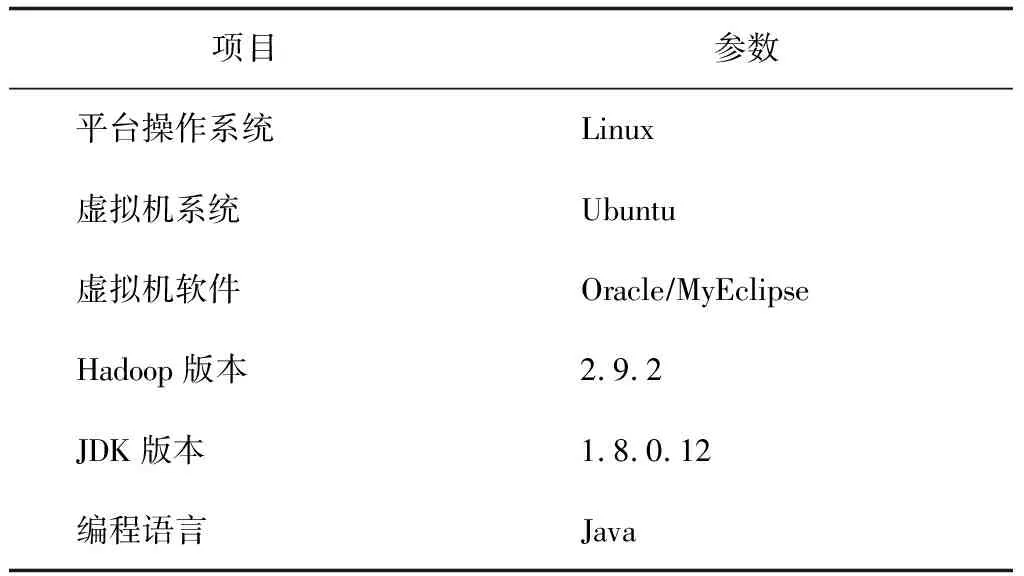
表1 Hadoop集群的软件环境设置
为保证各个节点之间的正常通信和任务分工,需要按照地址顺序添加节点,管理员可通过后台设置修改节点的IP地址和权限。在Hadoop集群的各节点计算机上安装SSH程序包,并配置主机的公钥、私钥权限。待系统启动后,首先格式化硬盘,启动HDFS、MapReduce以测试系统的功能。然后,将待处理的工业数据源加载到HDFS中,并在Sqoop模块中设置对应的参数。
3.2 查准率与查全率对比
去除冗余数据的效果,是衡量大数据清洗算法性能的主要标准之一。在此,以查准率(RP)和查全率(RR)作为主要性能指标,验证本次清洗算法的有效率。查准率用于衡量数据集中准确识别重复记录的比例,查全率衡量用于识别重复记录中真实值所占比例。
(6)
(7)
式中:ζ1为准确识别相似数据记录的数据数量;ζ2为真实条件下不应视为重复记录却被认定为重复记录的数据数量;ζ3为真实条件下属于冗余重复记录却未被检测出的数据数量。
从不同工业大数据来源中随机采集10 000条不同结构类型的故障数据构成数据集,其中包含564条错误数据、314条缺失不完整数据和788条冗余重复数据。将全部样本数据随机分成10组,利用本清洗算法计算各组数据的查准率和查全率,同时引入文献[6][7]的数据清洗算法参与对比,统计结果见表2、表3。
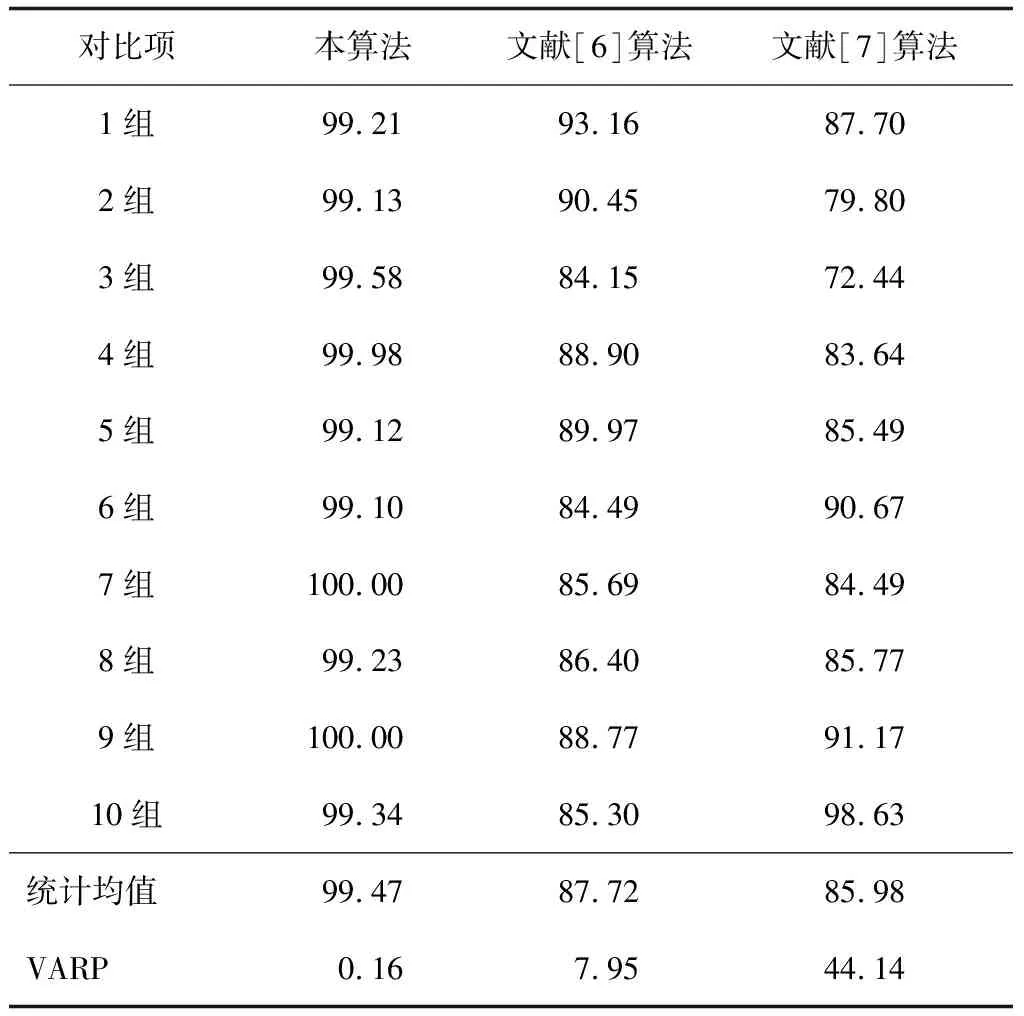
表2 查准率结果对比 %
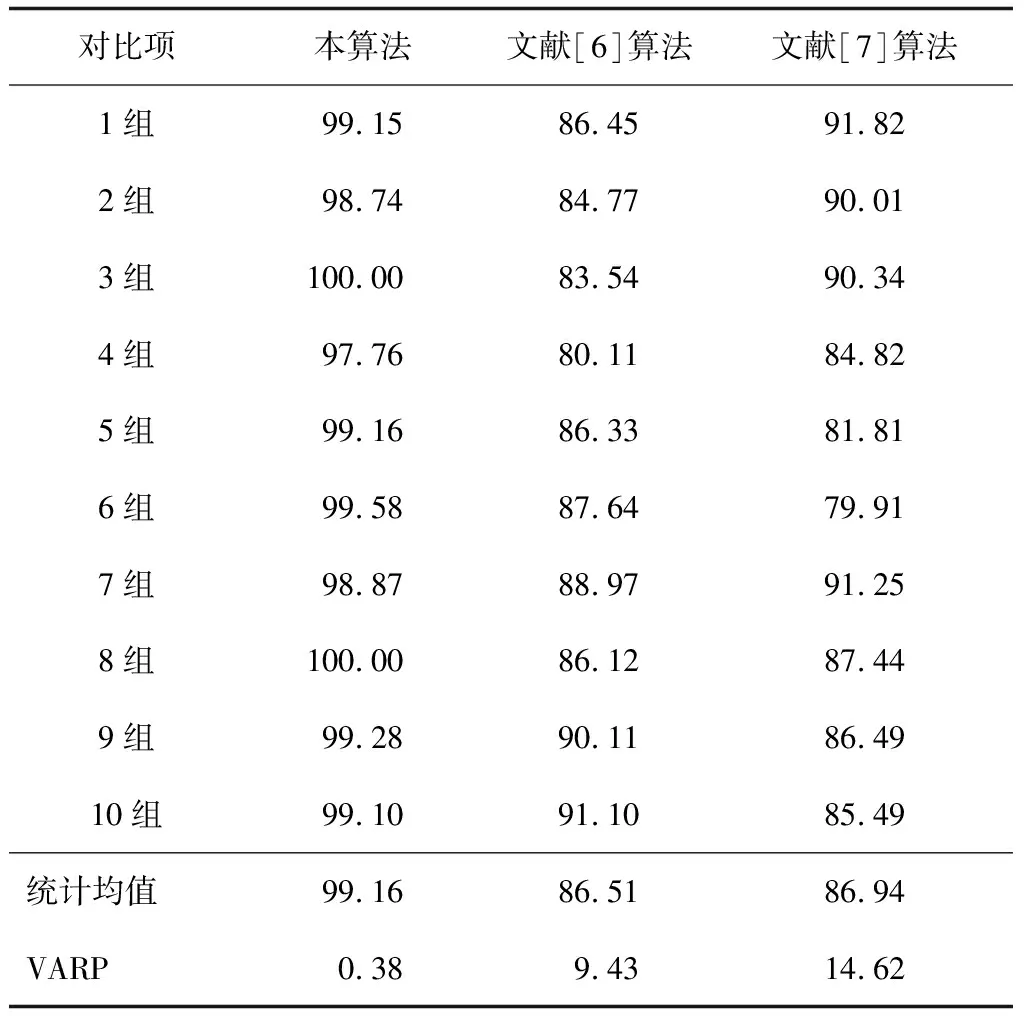
表3 查全率结果对比 %
由数值统计结果可知,本算法的绝对值和稳定性远优于另外两种清洗算法,查准率和查全率均值分别达到99.47%和99.16%,其VARP值分别达到0.16%和0.38%。随机抽取第5组数据作为实验抽样调查样本,检测工业数据清洗中字符串的匹配准确率,其统计结果如图4所示。
随机抽取的这一组数据中,字符串匹配准确率的变化趋势均与表2、表3中的一致。由此可见,本算法的字符匹配准确率相对更高。
3.3 工业大数据的清洗效率对比
以上述实验中随机采集到的10 000条不同结构类型的故障集为实验对象,并将故障集随机分成10组,对比10组工业大数据的清洗效率。对每组数据的处理时间进行累加,对比总体耗时,统计结果如图5所示。
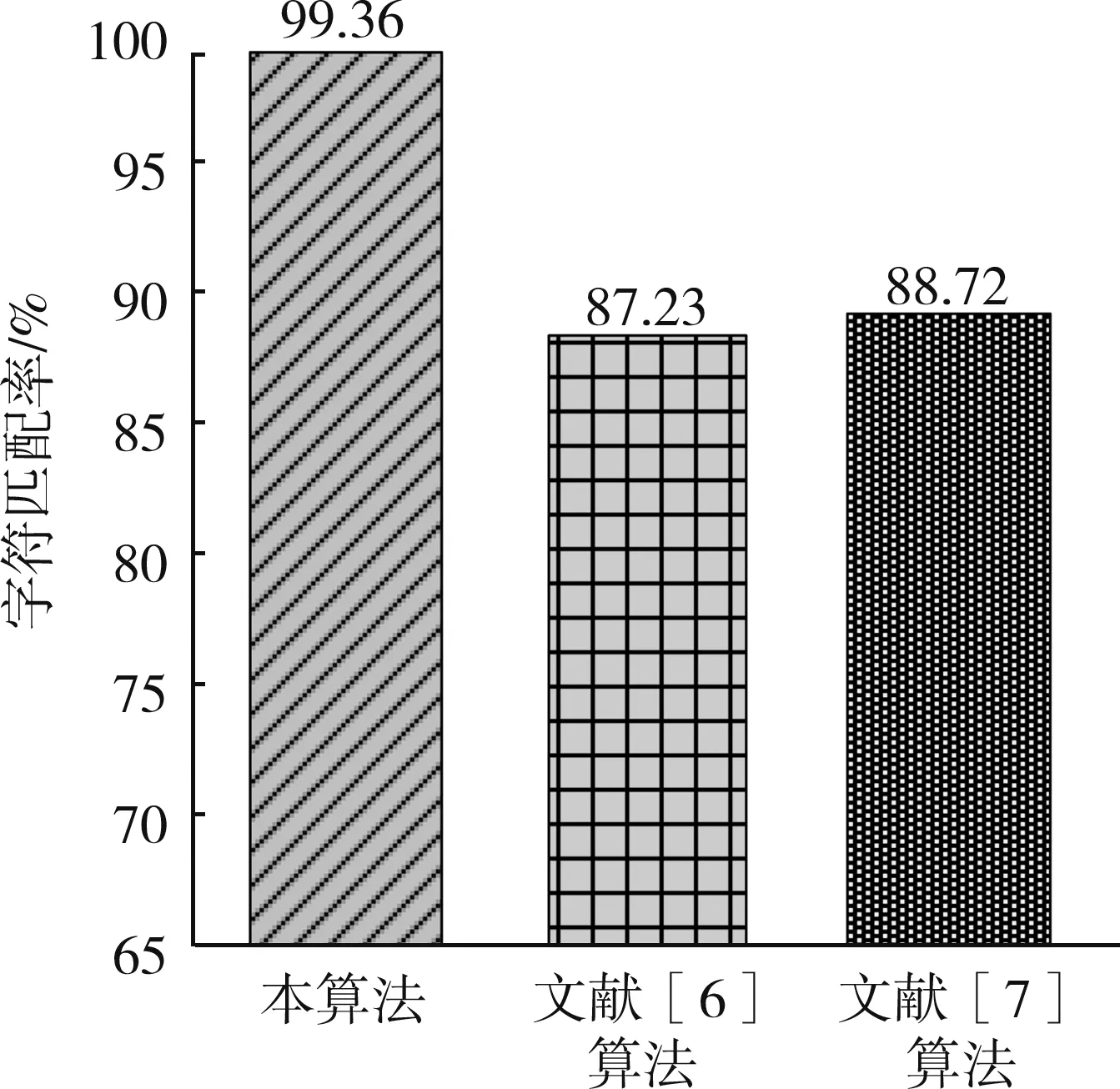
图4 各算法的字符串匹配准确率
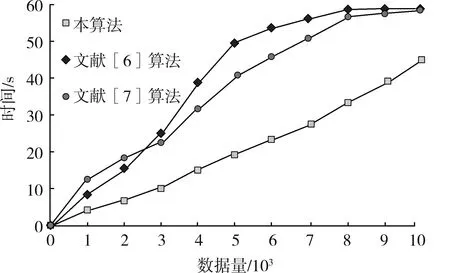
图5 数据处理的总体耗时对比
在10组数据的处理过程中,本算法的耗时更为平稳并呈线性变化,完成任务后的总体耗时更低;而文献[6][7]算法的结果有较大差异,也出现了不同程度的波动,在数据处理初段和中段效率较低,导致总体耗时高于本算法。
4 结 语
随着工业产业信息化的发展,工业大数据总量巨增,其结构也日趋复杂,这给基于工业大数据的故障检测和设备在线监控带来更大挑战。原始工业大数据中包含大量的冗余、错误或不完整数据,经过清洗可以去除其中绝大部分脏数据,对数据清洗算法进行优化有助于提高工业大数据分析和使用效率。本次研究中利用深度学习算法中的深度置信网络模型,提高了原始数据清洗效率,减少了数据误处理现象。实验结果表明,本次研究提出的工业大数据清洗算法在清洗效率上具有一定的优势,比传统清洗算法的查准、查全效果更佳。
