变电站设备缺陷文本数据挖掘及其应用
2022-01-18胡东林陈伟杨鑫张鹏桑江艳
胡东林,陈伟,杨鑫,张鹏,桑江艳
(云南电网有限责任公司昆明供电局,云南 昆明 650011)
0 前言
数据挖掘(DataMining,DM)是当前人工智能、机器学习领域研究的热点,是指从大量数据中发现隐含的具有潜在价值信息的过程,旨在让计算机根据已有数据进行归纳推理,做出正确的决策。随着计算机及通信网络的不断发展,智能电网建设的不断推进以及新能源的接入,电力企业在生产、营销等领域的各个环节积累了海量的数据。充分利用数据资源,开展数据挖掘是电力企业实现精益化管理,提升综合竞争力的重要手段。
在大数据处理中,规模和复杂性之间往往会有一个平衡点,Python语言便是一种折中方案。Python是一种通用型编程语言,具有优雅、简洁、高效的特点,且简单易学,有着丰富的第三方库。从数据采集、分析一直到应用开发层面都有比较成熟的库,使用Python语言进行开发,无需关注过多语言细节,可以将主要精力放到业务本身[1],适用于Linux、Mac、Windows系统,可移植性极强。
1 变电站设备缺陷数据及特点
变电站的正常运行是保证电网安全稳定的基础,与国计民生息息相关,变电运行人员通过信号监测、倒闸操作、定期巡视、特殊巡视等工作来保障变电站设备的正常运行,在工作过程中积累了大量的设备缺陷数据。这些缺陷数据是设备状态的“晴雨表”,对变电站设备运行状态分析以及设备全生命周期管理有着至关重要的意义。
设备缺陷是指生产设备在制造运输、施工安装、运行维护等阶段发生的设备质量异常现象,按照严重程度分为紧急缺陷、重大缺陷、一般缺陷和其他缺陷[2]。
南方电网公司资产管理系统中保存的缺陷文本信息包含“发现时间”、“缺陷设备”、“缺陷等级”、“缺陷表象”、“缺陷描述”等47个类目,涵盖了从发现缺陷到处理闭环的整个流程,除了“缺陷描述”、“遗留问题”、“处理情况描述”、“备注”等四个类目,其余类目均可以从系统中进行模块化选择,便于下一步的缺陷信息统计和分析。由于现场设备种类繁多,缺陷情况各不一样,仅通过模块化选择无法完全涵盖缺陷信息,故“缺陷描述”、“遗留问题”、“处理情况描述”需要手工输入。这些信息以中文短文本为主,包含英文字词、希腊字母、数字、符号等多种样式,不能直接按常规的结构化数据挖掘技术进行分析。国外有学者运用机器学习的方法,对纽约电网海量历史缺陷数据进行挖掘,进而为电力设备故障预测和维修提供相关依据[3]。相较于英文单词组成的文本,中文文本的词与词之间并无明显分界,存在着多歧义、分词难等特点,使得缺陷数据内容没有充分挖掘。
为实现更深层次的信息挖掘,本文以变电站设备缺陷描述文本为研究对象,充分挖掘设备缺陷信息。首先,人工建立自定义词典,对缺陷文本进行分词,进行TF-IDF值统计,生成词云;其次,通过对大量缺陷文本进行机器学习,采用SVM聚类算法,建立缺陷等级预测模型,实现对缺陷的定级预测,为缺陷数据的信息挖掘提供了另一种思路,基本流程如图1所示。

图1 缺陷文本数据挖掘流程图
2 设备缺陷数据处理及分析
2.1 数据采集
本文抽取2020年期间已归档的1017条缺陷进行分析。
2.2 数据预处理
针对收集的缺陷数据进行初步处理,使其能够被计算机识别,是数据挖掘的基础,内容如下。
1)分词
本文采用隐马尔可夫模型(hiddenMarkov model,HMM)进行分词,隐马尔可夫模型是可用于标注问题的统计学习模型,在语音识别、自然语言处理、模式识别等领域有着广泛的应用[4]。jieba分词库是Python的一个第三方库,采用了基于汉字成词能力的隐马尔可夫模型,并使用Viterbi算法。本文使用jieba分词库将“缺陷描述”类目中词与词之间用空格分开,便于后期数据分析。
2)构建自定义词典
结果初步分词后发现,虽然jieba分词库对一般常见词汇分词效果较好,且具有一定的新词识别能力,但对电力领域特有名词以及相关故障涉及词汇分词能力不足。通过参考中国南方电网有限责任公司缺陷管理办法、设备缺陷定级标准及相关规程,对常见电力设备、部件、缺陷涉及词汇以及线路名称进行录入,提升分词准确率。编制Python程序对每一条缺陷描述进行分词处理,根据缺陷定级分类保存至“紧急”、“重大”、“一般”、“其他”缺陷文件夹,作为语料库。其中抽取11月20日前919条数据作为训练集,剩余98条数据作为测试集。
表1 是对单条缺陷描述的分词效果示例,为使显示更加直观,采用符号“/”作为示例中的分词间隔符。可以看出,在导入自定义词典后,分词效果有明显提升,电流互感器、二次接线盒等专业名词已经能够被区分出来,有利于后期统计分析。

表1 分词效果示例
3)关键词及TF-IDF统计
采用TF-IDF算法对每个词进行词频统计,从而得出关键词进行研究分析。TF-IDF算法是一种统计方法,其主要思想是:词语的重要性随着它在文档中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。词频(TermFrequency,TF)是指某个词或短语在文档中出现的频率,逆文档频率(InverseDocumentFrequency,IDF)是词语普遍重要性的度量,如果包含词语的文档数量越少,则IDF值越大,则说明该词具有很好的类别区分能力。某一特定文件内的高词语频率,以及该词语在整个语料库中的低文件频率,可以产生出高权重的TF-IDF。
计算公式为:

其中,
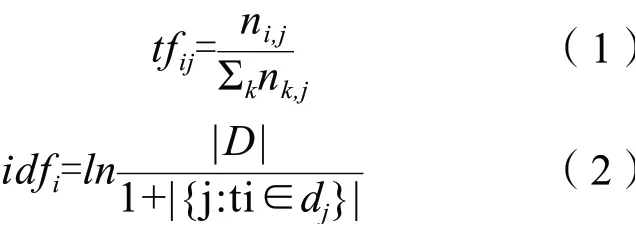
式(1)中,tfij为词频,ni,j为词语ti在文档dj中出现的次数,Σknk,j为文档dj的所有词语数量之和,式(2)中,idfi为逆文档频率,|D|为语料库中的文档总数,|{j:ti∈dj}|为包含词语ti的文件数量。
抽取前5名关键词如表2所示:

表2 前5名关键词汇及TF-IDF值
2.3 生成词云
词云是指对文本中出现频率较高的关键词予以视觉上的突出,并过滤掉大量无关的文本信息,使浏览者第一眼就能抓取关键词。根据得到的关键词及TF-IDF值,利用Python的第三方库wordcloud,对语料库中的关键词进行渲染,予以视觉上的突出,选取前200个关键词,生成词云,如图2所示。

图2 缺陷文本词云效果
3 设备缺陷定级预测模型
3.1 模型建立
本文采用支持向量机(supportvectormachine,SVM)进行缺陷定级预测。SVM建立在计算学习理论的结构风险最小化原则之上。其主要思想是在两类分类问题方面,从高维空间中寻找一个超平面,以作为两类的分割面,从而保证最小的分类错误率。而且支持向量机一个重要的优点是可以处理线性不可分的情况。支持向量机是一种功能强大的分类器,一旦得到了正确的参数,与贝叶斯分类器、决策树分类器、神经网络、k-最近邻算法相比,有可能会不相上下或更胜一筹[6]。在运算速度方面,接受训练后,SVM只需判断坐标点位于分界线的哪一侧即可,从而对新的观测数据进行分类时速度极快。采用SVM定级预测流程如图3所示。
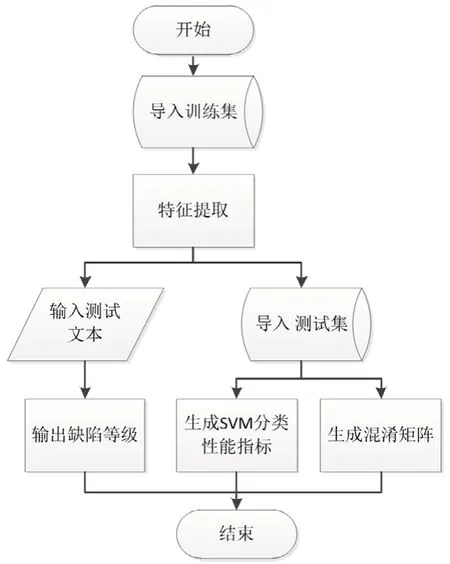
图3 SVM预测定级流程图
编制缺陷定级预测程序,对选取测试集中某一条文本进行缺陷定级预测,效果如表3所示:

表3 设备缺陷定级预测示例
现场人员只需要将设备缺陷描述输入,计算机程序便能够根据训练集进行特征提取,并将输入文本与之进行比对,迅速输出缺陷等级,用作现场参考,从而提高现场缺陷定级的速度,提升工作效率。
3.2 模型评估
本文研究了分词前后的模型分类性能参数,生成SVM分类器性能指标(表4、表5)以及SVM分类结果的混淆矩阵(表6、表7)。

表4 SVM分类性能指标(分词前)

表5 SVM分类性能指标(分词后)
在性能指标参数中,precision表示准确率,计算公式为:

式中,TP表示被识别为该分类的正确记录数,TP+FP表示实际被识别为该分类的记录数。
recall表示召回率,计算公式为:

式中,TP+FN表示应被识别为该分类的记录数f1-score是准确率和召回率的调和均值,计算公式为:

Support表示测试集中该分类的记录总数。
从表4、表5对比可分析出,通过分词后,SVM分类器性能(准确率、召回率、f1-score)总体得分均有提升。
表6 、表7中是SVM分类结果的混淆矩阵表示(其中横纵名称相同的单元格为分类正确数量),因为用于测试的缺陷有“紧急”“重大”“一般”“其他”个4类别,所以是一个44的矩阵,每一行的所有数字之和表示测试集中该分类的记录总数,等于表4、表5中的support值。进行分词后,SVM分类器对测试数据在一般、其他、紧急缺陷的分类上均有提升,但在重大缺陷分类上正确分类数量有所下降。

表6 SVM分类混淆矩阵(分词前)
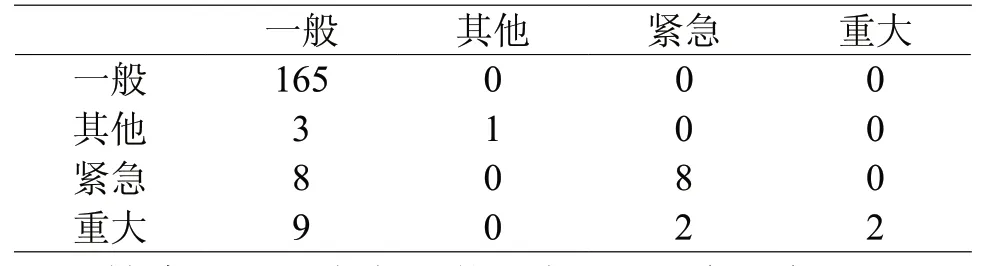
表7 SVM分类混淆矩阵(分词后)
结合SVM分类性能指标和混淆矩阵可看出,除了重大缺陷正确分类数量下降了3条,其他指标均得到了明显优化。随着语料库的丰富和自定义词典的不断完善,预测效果将会得到进一步提升。
4 结束语
1)研究了一种从历史设备缺陷文本中获取关键词的方法,并根据TF-IDF值大小以词云的方式进行可视化展现。
2)建立了基于Python的变电站设备缺陷文本数据挖掘模型,有利于现场人员根据缺陷描述快速对缺陷定级。
3)分析了模型指标参数,为下一步优化缺陷文本分类模型、提升分类准确率提供了思路。
4)自定义词典的录入不完善,导致还有部分电力领域专业词汇被错误切分,需要不断增加电力领域特别是变电站设备缺陷的专业词汇,完善自定义词库,提升分词准确率。
5)研究重点放在设备缺陷信息中非结构化数据的分析,与结构化数据相结合的数据挖掘能力需要进一步提升。
