融合注意力机制的学生退课行为预测*
2022-01-15张博健温延龙
付 宇 张博健 温延龙
(南开大学计算机学院 天津 300000)
1 引言
大规模开放在线课程(Massive Open Online Courses,MOOCs),简称慕课,在过去几年里受到了广泛关注并且迅速发展了起来。2020年年末,世界慕课联盟成立,旨在推动慕课进一步创新和发展。根据Class Central的报告显示,新冠疫情使许多人接受了在线教育,各大慕课平台也获利颇丰。截至2020年年底,世界上已有超1.8亿名用户加入了慕课学习[1]。清华大学的“学堂在线”作为国内第一个慕课平台,截至2021年3月,已经吸引了国内5880万用户共注册学习了超1.6亿门课程[2]。
然而,慕课这一模式也暴露了许多问题,退课率居高不下便是其中之一。早在2013年就有研究指出:慕课的退课率高达91%~93%[3]。而最近的一项研究则显示:学堂在线的课程完成率仅4.5%[4]。如此严重的退课现象不仅意味着绝大多数用户半途而废,浪费了时间和精力,还意味着投入慕课的资源利用率极低,存在着巨大的经济和教育资源浪费。此外,极低的完成率也不利于慕课平台的长远发展。因此,近年来,尽早识别潜在退课用户这一研究课题逐渐受到了广泛关注[5]。
目前已经很多研究者在退课行为预测方面进行了大量工作。以逻辑回归(Logistic Regression,LR),支持向量机(Support Vector Machine,SVM)和决策树(Decision Tree,DT)为代表的传统机器学习模型被证明在退课行为预测方面有着良好的性能。然而,尽管应用深度学习的预测策略已经被证明拥有更强的潜力,但目前的研究仍大量基于上述的传统方法,缺少对于更新颖的深度学习方法的尝试。此外,很多研究忽视了慕课用户灵活性修课的特点,采用时序无关的方法进行预测。时序无关的方法无法区分学习周期不同的用户,这不仅意味着模型预测效果的准确率更低,而且缺乏可解释性。在实际应用场景下,慕课平台往往需要在随机的时间点对学生的退课情况进行预测。这就要求模型能够更好地把握时序信息。
针对目前慕课退课行为预测研究存在的问题,本文提出了一种融合注意力机制的时序预测模型。首先,该方法弥补了时序无关模型的缺陷,通过利用长短期记忆网络,从原始的时序数据中学习新的时序隐态表示。其次,为了提取学生学习活动的上下文信息,本文使用多个一维卷积神经网络提取隐态中各类特征的时序模式。最后,融合了注意力机制,使模型能够通过注意力分布强化有效特征。该模型不同于已有方法之处主要在于其使用注意力机制将时序信息与特征信息相融合,从而实现具有更高准确性和更强可解释性的退课行为预测。
2 国内外研究现状
2.1 国内研究现状
国内早期关于远程教育退课行为问题以及慕课退课问题的研究大部分出自教育学和社会学领域。2015年~2017年期间,关于慕课退课行为的研究基本集中于原因和对策分析方面,有王濛濛等[6]、马迪倩等[7]许多研究者从不同方面对慕课用户退课行为的原因进行分析研究,个别研究者也提出了相应的对策。而国内关于慕课退课行为预测技术的研究出现较晚,大致在2017年。2017年4月,卢晓航等[8]使用Coursera平台的课程数据,利用机器学习算法,通过构建滑动窗口模型来动态预测用户的退课行为。在2017年年底,郭文锋等[9]使用相关性分析遴选出了用户的五种活动特征,之后利用逻辑回归模型进行退课行为预测,实验证明其选取的五种活动特征对退课行为影响显著,预测表现较好。2018年,孙霞等[10]选择将卷积神经网络和长短期记忆模型进行组合,提出了CNN-LSTM退课行为模型,该模型能够追踪用户在不同时间步长的学习状态,从而动态预测不同阶段的退课行为。之后,杨璐等[11]采用主成分分析法提取了用户的两种学习行为作为主要特征,利用AdaBoost算法进行了退课行为预测实验。2019年,Feng等[4]提出了名为Context-aware Feature Interaction Network(CFIN)的模型。CFIN模型首先利用上下文平滑技术来平滑具有不同上下文信息的特征值,之后采用一种注意力机制将用户信息和相关课程信息融合到模型中。与以往的模型相比,CFIN模型具有更好的性能,并且已经部署于学堂在线系统,用于侦测用户的退课行为。
2.2 国外研究现状
根据谷歌学术检索显示,自2013年以来,关于慕课退课行为预测的研究共有6770条记录,从2019年开始统计,则约有2910条记录。由此可知,近两年关于慕课退课行为预测的研究有非常大的增长。根据对文献的梳理可知,国外关于退课行为预测技术的研究远早于国内,在慕课出现之前是针对远程教育的退课行为预测技术研究,这些研究与慕课退课行为预测研究类似,并且这些研究为之后慕课退课行为预测的研究提供了思路和方法,可以将其归为慕课退课行为预测技术的早期研究。
2006年,Al-Radaideh等[12]尝试用决策树的方法进行预测,实验表明ID3在留一法中表现较好,而C4.5则在十折交叉验证中表现更好。2009年,Lykourentzou等[13]使用了神经网络、支持向量机以及概率集成简化的Fuzzy-ARTMAP(Probabilistic Ensemble Simplified Fuzzy ARTMAP,PESFAM)作为预 测 模 型 的 组 件。2010年,Kovačić等[14]使 用CHAID和CART进行退课行为预测,而Kotsiantis等[15]则组合了1-nearest neighbor、朴素贝叶斯等的方法进行实验。2012年,Gaudioso等[16]的实验表明朴素贝叶斯分类器在退课行为预测方面表现较好。2014年,Kloft等[17]利用支持向量机分类器进行实验,并指出过去几周的特征信息对于之后某个特定的时间点很有用。2015年,He等[18]基于逻辑回归模型提出了LR-SEQ和LR-SIM两个模型,并在实验时使用之前周的信息对当前周的退课情况进行预测。2017年,深度学习的技术开始逐步应用于慕课退课行为预测。Wang等[19]利用卷积神经网络和循环神经网络的组合进行实验,这一模型能够从原始数据中自动提取特征并且表现较好。2018年,Gitinabard等[20]采用了逻辑回归的方法来识别一个学生是否退课。2019年,Gray等[21]基于学位课程项目,使用随机森林的方法来识别退课用户。同年,Ding等[22]采用长短期记忆模型和自动编码的方式从原始数据中学习有效特征的表示作为模型的输入,之后使用一般的神经网络进行监督训练,新的表示使得退课行为预测的精确性提升了17%,并且减轻了过拟合的情况。2020年,Pulikottil等[23]提出了一种基于注意元嵌入的深度时序网络来预测退课行为,并且该模型也达到了非常好的效果。
前述内容为本文对慕课退课行为预测研究的简单梳理与介绍。综合国内外的研究情况可知,关于退课问题的研究,2017年以前国内是集中于定性的分析,国外绝大多数研究则利用传统的机器学习方法尝试预测用户的退课情况,如逻辑回归、支持向量机、朴素贝叶斯和决策树这四类方法以及他们的组合。2017年以后,国内外的预测技术研究逐步转向于深度学习技术,除了上述提及的模型外,还有许多表现较好的模型。
3 退课行为的建模
在介绍预测模型之前,本文需要在此明确学生退课的定义,对于退课行为进行建模。本文将退课行为预测问题视为一个时间序列二分类问题。任意一名学生在选择一门课程后,其学习行为日志可构成时间序列数据(一般地,其学习行为日志可按照小时、天、周或月进行划分,本文依照惯例,将时间序列按周进行划分)。本文依据学生在学习课程时的学习活动,即上文提到的时间序列数据,预测学生是否会有退课行为。结果只有“退课”或者“保留”两种可能。
在介绍学生退课行为的公式化表达之前,我们先明确下文将使用的符号。本文约定S表示所有学生组成的集合,C表示所有课程组成的集合,A表示所有学生的学习活动组成的集合。这样,某学生s在选择某课程c后,其全部学习活动的集合可表示为A(s,c)。其中,A(s,c)∈A,s∈S,c∈C。根据上文对于退课行为的时序性定义,学生s在课程c中的学习总时长以周为单位划分为N个阶段,设n∈[1 ,N],t1表示最初的时间阶段,tN表示最后的时间阶段。
在时序阶段tn中,学生s在课程c中全部学习活动的集合可表示为Atn(s,c)。由此可得学生学习 活 动 的 时 间 序 列 数 据:A(s,c)={At1(s,c),…,AtN(s,c)}。设学生s在学习课程c的结果为y(s,c)∈{0,1},其中1表示存在退课行为,0则表示没有。
综上,退课行为预测可被描述为给定一名学生s,已知该学生选择了课程c,在课程学习阶段[t1,tN]内,根据其学习活动序列A(s,c),对于最终是否存在退课行为y(s,c)进行预测。任务目标为求取一个预测函数f,该函数可被公式化表达为f:A(s,c)→y(s,c)。
4 融合注意力机制的预测模型
此节,本文将详细介绍融合注意力机制的时序预测模型。该模型受时间序列预测领域相关研究的启发[24],模型通过捕捉学生学习活动中各特征的时序模式并关注重要的活动特征,实现了更好的预测效果。如图1所示,该模型可分为长短期记忆网络、卷积神经网络、注意力机制、最终预测四个部分。下文将按照此顺序,对于模型进行详细介绍。
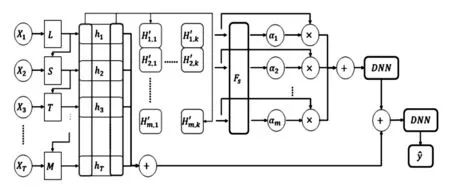
图1 融合注意力机制的时序预测模型
4.1 长短期记忆神经网络
长短期记忆神经网络(Long Short-Term Memory,LSTM)是循环神经网络(Recurrent Neural Network,RNN)的一个变种。尽管某些相关研究是基于朴素的RNN,但是Fei和Yeung的研究已经证明了LSTM在退课行为预测方面的表现较于朴素RNN更好[25]。LSTM采用阈值判定的方法,在神经元内部加入了门控单元,在结构层面上有效地解决了梯度消失的问题。相较于朴素RNN,LSTM的复杂性体现在神经元内部的计算上。然而,学生在慕课平台学习过程中的点击流数据在数值上相对较小,且大量的退课以及退课行为导致在数据处理后,记录学生学习行为的矩阵较为稀疏。这意味着在训练过程中不会有极高的计算代价,梯度爆炸等问题难以出现。因此,LSTM较为适用于提取慕课学习数据中的时序模式。
LSTM为模型的第一个模块,其输入为表示学生学习活动的时间序列数据。由第3节,已知模型的输入为序列数据A(s,c),数据处理后,序列表示为X={X1,X2,…,XN},其中,Xt∈R1×df,t=1,2,3,…,N,N为按周划分后时间阶段的数量,维度df为学生学习活动特征种类的数量。需要注意的是,由于不同的学生在不同的课程中学习时长不同,因此序列长度为变长序列。在输入LSTM前,需要对序列进行长度补齐并压缩,避免补充的零值对于网络计算的影响。
将某时序阶段的学习活动Xt,上一个时间阶段的模型输出ht-1以及状态向量ct-1作为模型的输入。首先,通过sigmoid函数将线性变换得到的中间结果进行非线性变换,得到向量ft:
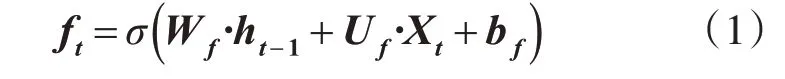
其中,Wf,Uf,bf都为可学习的参数。通过相似的方式,可得到向量it,以及候选状态ĉt。通过向量对位相乘和相加运算,可得ct:
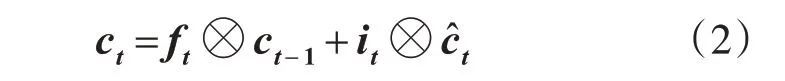
再通过与式(1)类似方式得到ot,最终得到ht:
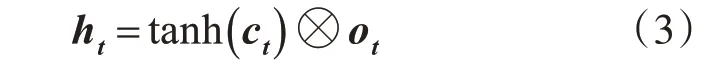
重复上述步骤,直到计算得到最终时间阶段模型的输出hN。全部时间阶段的隐态构成矩阵H=[h1,h2,…,hN],H∈Rdm×N,dm为LSTM层的维度。由此,得到蕴含全部学习活动与时序信息的隐态表示。
4.2 卷积神经网络
在得到包含全部学生活动信息的各时间阶段的隐态表示之后,本文使用卷积神经网络(Convolutional Neural Network,CNN),在整个时间阶段上对各类特征的时序模式进行进一步提取。具体地,在该模型的卷积层中,使用K个1×N的卷积核Cj∈R1×N,j=1,2,…,K。如图1所示,4.1节中提到的隐态矩阵H被相应地划分为K个部分,其中Hi∈R1×N,i=1,2,…,dm。每一个卷积核Cj对Hi进行操作得到H′∈Rdm×k。H'蕴含着由卷积层进一步提取后得到的各类特征的时序模式。卷积核计算如式(4):
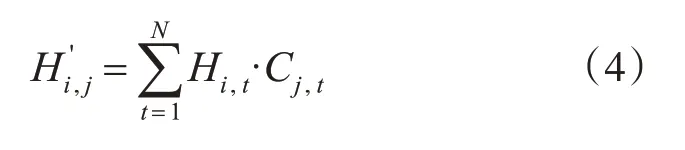
其中,卷积核内的运算为在线性变换后,以tanh函数为激活函数进行非线性变换。如图1所示,隐态向量的列序由卷积核参与计算的顺序决定,行序保留LSTM层中的顺序。
在卷积层中实现这一转换的结果将在下一个阶段使用,注意力机制将作用于这些包含各类特征信息的隐态向量。此外,卷积运算中加权求和的方式可以消除变长序列填充零值对模型的影响。
4.3 注意力机制
注意力机制(Attention Mechanism)是基于人类大脑处理信息的方式提出的,在深度学习中常被用于从大量的数据中提取出关键信息以更好地训练模型。一般的注意力机制通常关注重要的时间序列阶段,忽略了对重要特征的关注。此外,传统的注意力机制会在多个时序阶段上平均特征信息,使得其无法检测到有助于预测的时间模式。
为了使注意力机制更好地应用于退课行为预测,本文借鉴时间序列预测领域的方法[24],构建了基于时间模式的注意力机制。
如图1所示,4.2节中的H'将作为注意力层的输入向量,将LSTM层得到的隐态的所有行向量加和得到的h′∈Rdm×1作为查询向量,使用双线性打分模型作为注意力打分函数。打分函数输出的中间结果通过softmax激活函数得到注意力分布。计算公式可表示为
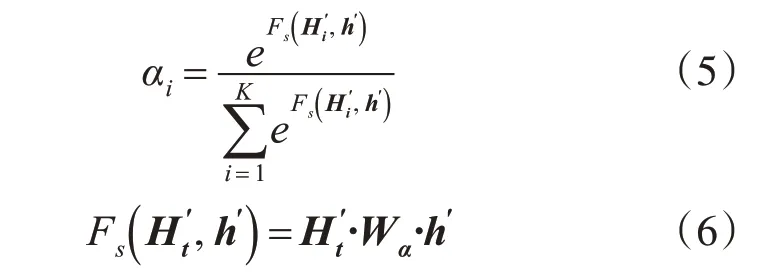
其中,Fs表示打分函数,Wα为可学习的参数。最后将注意力分布的权值同H′的行向量加权求和得到上下文向量attnN∈R1×K:
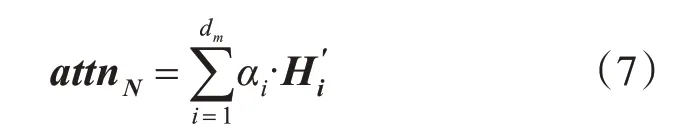
该结果包含了原始输入的时间模式,并且通过注意力分布关注了重要的特征信息。
4.4 预测最终结果
在得到加权增强后的特征表示后,将其输入全连接层进行进行线性变换,并将这一结果和h'对位相加,得到h*∈Rdm×1用于最终预测。最后再通过全连接层进行线性变换,使输出结果维度为1×1,使用sigmoid激活函数将这一中间结果取值映射为0~1之间,即代表用户退课的预测概率ŷ:
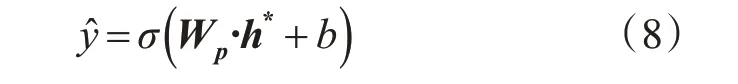
ŷ即为预测结果,若ŷ>0.5,即认为该学生将退课,反之则留存。
5 实验与分析
5.1 数据集及评价指标
5.1.1 数据集简介
本文实验所使用的数据集是学堂在线(XuetangX)的公开数据集。此数据集可分为四个部分:学生学习日志、学生退课结果、学生基本信息、课程基本信息。其中,学生学习日志记录了学生在慕课平台上的每一次操作,每条记录由活动类型与时间戳组成;学生退课结果记录了学生选课后最终是否退课。训练集中共有29165540条日志数据,共157943人次的记录,其中80%的数据用于训练,20%的数据用于验证。测试集文件中共有12944862条日志数据,共67699人次的记录;课程信息文件提供了6410门课程的信息;用户信息文件提供了9627148名学堂用户的基本信息。是目前信息最丰富的可用于退课行为预测研究的公开数据集。
5.1.2 评价指标
本文选取大多数研究者[4,8,10~11,17,19,22~23,25]采用的AUC-ROC(Area Under the Curve of ROC)分数和F1分数作为评价指标。用于慕课退课行为预测的数据集的正负样例往往不平衡,所选取的两个指标可以在正负样例不均衡的应用场景下,较好地评判模型的性能。
5.1.3 数据处理过程
因为本文提出的模型为时序模型,所以需要将日志类型的数据根据时间戳处理为时间序列数据作为模型的输入。处理过程可以概括为:提取特征、转化为one-hot向量、聚合one-hot向量三个步骤。其中,转化为one-hot向量指的是将学生的每次活动记录转化为形如[0,0,0,0,1,0]的向量。此向量的维度为日志中记录的学习活动的种类数量,一个向量表示着对于学生学习活动的一次统计。聚合one-hot向量指的是将时间窗口内(本文将时间窗口大小设置为七天)的全部one-hot向量进行加和,得到的向量即为学生在此时间段内全部学习活动的统计结果。通过这种方式,对学生学习过程中的每个时间段分别进行统计,最终得到完整的时间序列数据。
5.2 对比实验
5.2.1 实验设置
本文对LR模型、SVM模型、RF模型、GBDT模型、3层DNN模型、LSTM模型、CFIN模型以及本文所提出的模型进行了比较分析。我们按照上节所述流程将数据处理为时间序列数据后进行数据归一化,输入上述模型进行训练,最终对比不同模型在测试集中的预测表现。对于LR模型、SVM模型、RF模型、GBDT模型,本文采用5折交叉验证法配合网格搜索的方法找寻最优参数,最后以最优参数训练模型完成预测。对于CFIN模型,本文直接使用文献[4]设定的最优参数和公开代码进行实验。对于3层DNN模型、LSTM模型以及本文提出的模型,学习率设置为0.0001,使用Adam优化器多次调整参数以训练模型。
5.2.2 实验结果
最后使用最优数据结果。实验结果如下。
由表1可知,传统的机器学习模型在整体上表现不如深度学习模型。对于传统的机器学习模型来讲,由于在慕课退课行为预测问题中输入的序列是变长的,在实验时引入时序的概念非常困难,对于深度学习模型DNN也是如此。对比LSTM模型和DNN模型可知,LSTM模型有着更好的预测效果,这证明了引入时序概念的合理性。CFIN模型使用了注意力机制增强预测效果,但是其采用的是直接训练的方法,忽略了时序的作用,因此同LSTM模型的效果相比提升非常小,训练的时间成本也较高。本文所提出的模型兼具注意力机制与时序模型的优点,在AUC-ROC分数和F1分数方面的表现都优于上述方法,且具有更好的可解释性。
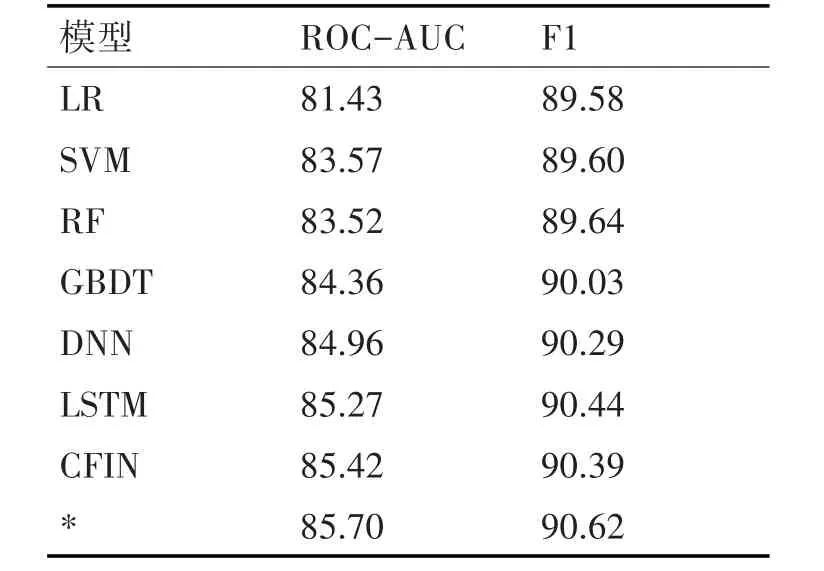
表1 不同模型的预测效果对比(%)
5.3 消融实验
为了确定本文所提出的模型中各组件对慕课用户退课行为预测效果的贡献程度,在此采用消融实验的方法,从完整的模型入手,逐步去掉模型的部分组件,之后通过实验来观察消融组件后模型的效果。实验结果如表2所示,A表示完整模型,B为去掉注意力机制后的模型,C为去掉CNN组件后的模型。
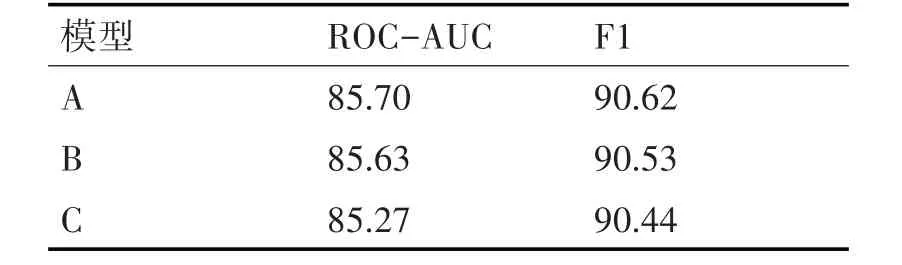
表2 消融部分组件后模型的预测效果(%)
分析表2结果可知,各部分组件都对慕课退课行为预测的效果有贡献,其中,对预测效果贡献最大的是CNN部分,而注意力机制对预测效果的贡献相对较小。
6 结语
本文提出了一种融合注意力机制的退课行为预测方法。该方法不仅作为时序模型有着更强的应用性与可解释性,而且恰当地使用注意力机制和卷积神经网络提高了预测表现。消融实验的结果进一步证明,该方法的全部组件有效,且有其合理性。在公开数据集上的实验证明,相比于其他模型,本文所提出的方法在慕课退课行为预测任务上实现了更好的效果。
慕课退课行为预测还存在诸多值得挖掘之处。比如在研究过程中,本文尝试过在不同时间阶段进行动态预测,但发现DNN、LSTM与本文提出的模型在最初几个阶段的表现都不太令人满意,由此,本文认为未来的研究可以尝试在不同时间阶段区间构建不同的模型进行预测,这样有机会达到整体最优。此外,由于现有数据集中收录的课程周期较短,与时间阶段相关的研究受到限制,期待未来有更多的公开数据集可供研究,从而更好地帮助学生与慕课平台。
