改进YOLOv3算法的车辆信息检测
2022-01-12冯加明储茂祥杨永辉巩荣芬
冯加明,储茂祥,杨永辉,巩荣芬
(辽宁科技大学 电子与信息工程学院,辽宁 鞍山 114051)
近年来,随着现代科技的飞速发展,汽车保有量逐年增多,汽车套牌的犯罪率也逐渐增高。为了减轻对交通管理部门的压力,人们开始对车辆进行识别来确认车辆的型号,然后通过车辆的型号与车牌的匹配关系来确认车辆是否套牌,从而减少了人力管控资源。基于此背景,车辆识别技术应运而生。在车辆识别的方法中最简单方法便是通过图像的方式,即通过交通摄像头拍摄交通图像,然后通过模式识别的方法识别交通图像中的车辆。而要识别交通图像中的车辆,首要任务是检测出图像中的车辆信息,主要包括车牌、车标、车脸。
目前,车辆信息检测的方法众多,可总结为两类,即传统学习方法和深度学习方法。传统学习方法主要通过研究车牌、车标、车脸的特点,提取相应的特征,然后通过滑动窗口的方式对车辆信息进行检测。Zakaria等[1]使用梯度直方图特征和支持向量机相结合的方法进行车辆检测;张小琴等[2]利用车辆的对称特征检测车脸,然后通过提取车脸的梯度直方图特征结合支持向量机的方法识别车辆。上述传统学习方法能够检测出图像中的目标,但是提取车辆信息的特征比较简单,算法稳定性容易受到环境变化的影响。随着近几年深度学习的兴起,RCNN[3]、Fast R-CNN[4]、Faster R-CNN[5]、SSD[6]以及YOLO系列[7-9]等基于深度学习方法的目标检测算法相继出现。Huang等[10]采用Faster-RCNN算法与VGG-16、ResNet-50网络结构相结合的方法识别道路监控中的车标;Chen等[11]使用SSD目标检测算法实现了交通监控视频中的车辆检测以及车辆计数;He等[12]通过卷积神经网络的快速深度学习算法检测视频中的车辆,并与雷达相结合来提高车辆检测的性能;桑军等[13]提出了一种Faster-RCNN算法与ZF、VGG-16、ResNet-101网络结构相结合的车型识别策略;Yang等[14]提出了一种Faster-RCNN与三级级联卷积神经网络相结合的车辆零件检测方法。上述深度学习方法能够自动提取图像中更适合车辆信息的特征,很好地解决了算法对环境的影响,但是对于小尺寸的目标检测效果差,且检测速度较慢,不能满足实时检测的需求。
随着YOLOv3算法的出现,检测速度以及小目标检测性能都有很大提升。Krittayanawach等[15]通过压缩YOLOv3算法模型结构进行车辆检测;Chen等[16]受到YOLOv3算法的启发,提出了一种级联特征金字塔网络的浅层模型用于交通流量中的车辆检测。目前,YOLOv3算法在智慧交通领域中主要应用于交通监控中车辆的检测,而应用于车辆信息检测的研究并不多见。笔者将改进的YOLOv3-fass算法应用于多类车辆信息的检测,旨在更快、更稳定、更精准地实现图像中多类车辆信息的同时检测。
1 YOLOv3算法的原理
YOLOv3算法采用DarkNet-53的网络结构提取图像中车辆信息的特征,并采用多尺度的检测方式实现图像中目标的检测。数据集中的图像归一化到416×416尺寸,送入算法网络结构中进行车辆信息的检测。DarkNet-53网络结构中采用了大量含有1×1和3×3卷积核的残差网络结构。残差网络结构如图1所示。

图1 残差网络结构图Fig. 1 Schematic diagram of residual network
残差网络结构的残差函数为
F(x)=H(x)-x,
(1)
式中:F(x)表示残差网络结构的残差函数;H(x)表示残差网络结构的输出值;x表示残差网络结构的输入值。
YOLOv3算法网络结构的输入图像经过5次步长为2的卷积层进行下采样,分别得到208×208,104×104,52×52,26×26,13×13共5个尺度的特征图。YOLOv3算法将13×13,26×26,52×52尺度上的特征图输入到检测网络中进行多尺度检测。YOLOv3算法将9组锚框平均分配在检测网络的3个尺度上,每个尺度的每个锚点分配3组锚框,共计生成10 647个锚框。YOLOv3算法使用Adam优化器,首先采用回归的方式对锚框进行类别、置信度和预测框的预测;然后根据每个预测框的得分使用NMS算法选出最终的预测框。最后,根据特征图与原图的关系将预测框映射到原图上,完成图像中车辆信息的定位。
置信度的计算公式为
C=Pr(object)×I,
(2)
(3)
式中:C表示置信度;Pr(object)表示预测框中检测到目标的概率;I表示预测框与真值框区域的交并比。
在NMS算法中预测框中目标的得分计算公式为
S=C×Pr(logo|object),
(4)
式中:S表示预测框的得分;Pr(logo|object)表示车标类别的条件概率。
2 YOLOv3算法的改进
在对YOLOv3算法的研究中发现了一系列问题,诸如YOLOv3算法对于小尺寸车辆信息的检测稳定性差,参与运算的参数量大等。针对以上问题,笔者基于YOLOv3算法提出了更适合车辆信息检测的YOLOv3-fass算法。YOLOv3-fass算法的网络结构如图2所示。网络结构主要包括两部分:主网络、检测网络,其中主网络由网络主干和网络支路组成。主网络含有输入模块、卷积层模块、下采样模块、节点1~5模块、残差1、残差2、残差5模块以及池化模块;检测网络含有4个输入,检测层(1)~(4)模块以及卷积层4模块、卷积层7模块、2个卷积层5模块。其中输入模块表示网络的输入图像,卷积层模块表示对输入图像做卷积的卷积层,下采样模块表示步长为2的卷积层,节点1~5模块表示2个下采样模块融合后的特征图,残差1表示含有1个残差网络结构,残差2表示含有2个残差网络结构,残差5表示含有5个残差网络结构,池化模块表示步长为2的最大池化层,检测层(1)~(4)模块表示检测网络的4个输出检测层,卷积层4模块表示4个卷积层,卷积层7模块表示7个卷积层,卷积层5模块表示5个卷积层。
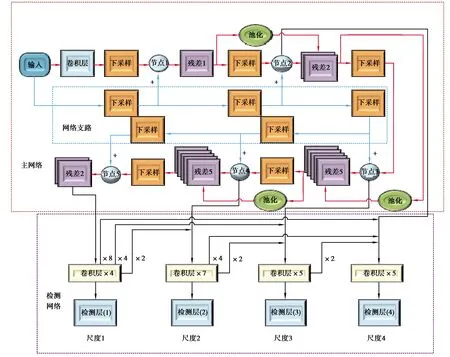
图2 YOLOv3-fass算法的网络结构图Fig. 2 Network structure of YOLOv3-fass algorithm
以下为YOLOv3-fass算法的说明。
1)简化网络结构。 YOLOv3算法含有大量参与运算的参数,一方面会导致车辆信息检测速度的下降,另一方面当数据集样本数量较少时算法容易产生过拟合。为了降低算法的参数量,笔者将网络结构中的残差网络结构和滤波器的数量进行了适度的调整,分别把网络主干中2,4,8,16,32倍下采样后的残差网络结构的数量调整为1,2,5,5,2个,同时把YOLOv3-fass算法的网络结构中所有卷积层的通道数降低50%,从而降低了网络结构的复杂程度,在提高车辆信息检测效率的同时也避免了算法产生过拟合现象。
2)添加网络支路。DarkNet-53网络结构仅采用一个下采样模块作为下采样层,在特征图传递过程中图像特征信息损失较多。为了以上问题,在网络结构中添加了一条含有5个下采样模块的网络支路,使该支路上的5个下采样模块与网络主干中相同尺度特征层的下采样模块具有相同的通道数量,并将网络主干与网络支路上的相同尺度的下采样模块进行特征融合,节点1~5模块便是融合之后的特征图。该设计通过添加网络支路,在特征图传递过程中减少了信息的损失,同时融合了特征图的深、浅层特征,也增强了网络结构的表征能力。
3)添加尺度跳连结构。为了提高网络结构中浅层特征的复用率并保证相邻尺度特征图的融合,YOLOv3-fass算法在网络主干的208×208,104×104,52×52,26×26相邻两个尺度之间添加了含有池化模块的3个尺度跳连结构,将下采样模块的输出作为尺度跳连结构的输入,并将3个尺度跳连结构的输出分别与残差2模块中的第1个残差网络结构的输出、残差5模块中的第3个残差网络结构的输出进行特征图的融合。网络结构融合了浅层特征,增强了表征能力,也起到了防止梯度弥散的作用。
4)增加检测尺度。为了更精准地检测小尺寸的车辆信息,在YOLOv3网络结构的基础上增加了1个检测网络的检测尺度。改进的检测网络如图2的检测网络部分所示,首先将检测网络的3尺度检测改为4尺度检测,其次参考文献[17]中的方法,在检测网络中增加了密集连接结构,即各检测尺度之间采用2,4,8倍上采样进行连接,最后将主网络的第2个残差2模块、节点4、节点3、节点2模块分别与上采样的特征图融合之后输入到检测网络中。通过增加检测尺度使锚框的数量增加至原来的4倍之多,提高了车辆信息的检出率;同时将融合特征图作为检测网络的输入信息以及增加密集连接结构,提高了检测网络输入特征图的可靠性。
5)K-均值聚类与手动调节相结合。在本文算法中,检测网络包含了4个检测尺度,每个检测尺度分配3组锚框值,共需12组锚框值,并采用K-均值方法聚类出12组锚框值。由于车辆数据集中标注的车辆信息的形状、车脸及车牌均为长方形且数量占比大,车标的形状多数近似正方形且在数据集中数量占比小,仅采用K-均值方法聚类的12组锚框值准确度不够。因此,笔者采用K-均值方法对车辆信息数据集进行锚框的聚类,然后通过手动调节的方式对聚类出的12组锚框值进行适当的调整。因为车标尺寸较小,所以只需要调整负责小目标检测的检测尺度上的锚框值,即调整前9组锚框值。将每3组中的长宽之差绝对值最小的一组锚框值调整到长宽之差绝对值小于5的范围内。最终,确定的12组锚框值为:(7,7),(19,9),(24,17),(33,29),(46,15),(66,20), (50,50),(94,26),(113,47),(203,76),(270,113),(312,180)。通过K-Means聚类与手动调节相结合的方法进行锚框的聚类,提高了YOLOv3-fass算法检测的准确度。
6) 采用迁移学习机制。针对数据集样本较少的情况,采用迁移学习机制对网络模型进行微调训练。为了加快网络的收敛速度,首先在Pascal voc2012数据集上训练YOLOv3-fass算法模型,生成新的模型权重文件W1,然后把W1文件作为预训练权重文件,在自研的车辆数据集上微调YOLOV3-fass算法模型,得到最终的权重文件。研究中采用迁移学习机制对YOLOv3-fass算法进行微调,一方面在训练过程中能够使模型更快地收敛,另一方面,能够避免算法因数据集样本较少而产生过拟合。
3 实验说明
3.1 实验准备
首先为迁移学习准备了Pascal voc2012标准数据集,然后准备了自研的车辆数据集,用于微调本文算法。车辆数据集中的图片均来自校园和街道,共包含2 000张图像,图例如图3中(a)~(h)所示。使用LabelImg工具在车辆数据集中标记了2 300个车标,2 360个车牌,2 520个车脸。将数据集按8∶ 1∶ 1的比例分成训练集、验证集和测试集,分别用于模型的训练、验证以及测试过程。

图3 车辆数据集图例Fig. 3 Legend of vehicle dataset
实验中使用的服务器设备的型号为超微6027AX-TRF,内存为32 G,硬盘为2 T,显卡为TITAN-XP,操作系统为Ubuntu 16.04。在实验中采用旋转角度、饱和度、曝光度和色调共4种数据增强策略,具体参数配置如表1所示。在实验中,对本文算法以下指标进行了比较:交并比、查准率、平均精度均值、平均精度、召回率、单张图片检测时间以及模型文件大小(Ubuntu 16.04环境下)。

表1 参数配置
3.2 实验结果分析
分别使用YOLOv3算法和YOLOv3-fass算法迭代10 000次的模型对实例图像中的车辆信息做了检测试验。图4为YOLOv3-fass算法和YOLOv3算法在实例图像上的车辆信息检测对比图,其中图4中的(a)~(d)为YOLOv3-fass算法的车辆信息检测图,图4中的(e)~(h)为YOLOv3算法的车辆信息检测图,图中绿色框为车脸框,红色框为车标框,黄色框为车牌框。可以看出,图4中的(e)(g)(h)出现了车辆信息严重漏检的情况;图4中的(a)(e)(f)(h)出现了车辆信息错检的情况;在图4(a)中,YOLOv3-fass算法能够将图像中远处的所有车脸及部分车牌成功地检测出来,而(e)中,YOLOv3算法仅仅检测出远处的一个车牌,漏检情况较为严重。通过本实验中的两组对比图,可以发现YOLOv3-fass算法能够检测出更多的车辆信息,而且更适合检测图像中的小尺寸车辆信息。

图4 YOLOv3-fass算法与YOLOv3算法车辆信息检测对比图Fig. 4 Comparison of vehicle information detection of YOLOv3-fass algorithm and YOLOv3 algorithm
按照表1中的数据配置训练参数,将YOLOv3-fass算法与YOLOv3、YOLOv3-spp、YOLOv3-tiny算法做了对比实验。为了验证YOLOv3-fass算法的网络结构对算法性能的影响,将YOLOv3算法的DarkNet-53网络结构换成DenseNet201、ResNet50经典网络结构,并做了实验对比。在实验中,以上6种算法在车辆数据集的训练集上进行多尺度训练并迭代10 000次,按照以下的方式保存模型文件:迭代1 000次以内每迭代100次保存一次模型文件,迭代1 000次以后每迭代500次保存一次模型文件,共计保存了28个模型文件。最后在车辆数据集的测试集上对保存的6种模型文件做了测试,并将相应的指标数据记录在表2中。可以看出,YOLOv3-fass算法的单张图片检测时间相比YOLOv3算法缩短了50%,同时交并比、召回率及平均精度均值指标都有不同程度的提高;YOLOv3-fass算法的单张图片的检测速度仅慢于YOLOv3-tiny算法,但是,其交并比、召回率、平均精度均值指标比YOLOv3-tiny算法分别提高了9.26%,9.00%,6.62%;YOLOv3-fass算法与DenseNet 201、Resnet 50、YOLOv3-spp相比,单张图片的检时间分别快17.9,8.5,11.1 ms,且其交并比、召回率、平均精度均值指标也都有大幅的提升;YOLOv3-fass算法的模型文件内存仅比YOLOv3-tiny算法的模型文件大12.7 MB,且远小于其他4种算法的模型文件,降低算法网络的参数量能够提升检测速度,也能够避免算法产生过拟合现象。综上所述,YOLOv3-fass算法不仅在车辆信息的检测速度上有了大幅的提高,而且其交并比、召回率及平均精度均值也都有小幅提高。

表2 6种算法性能指标对比表
如图5、图6所示,实验验证了6种算法的车标平均精度以及3类车辆信息平均精度均值的稳定性,并绘制了车标平均精度和车辆信息平均精度均值的稳定性对比图。
图5为6种算法的车标平均精度稳定性对比图,从图中可以看出,YOLOv3-fass算法的车标平均精度提升速度最快,且在迭代2 000次之后车标平均精度曲线趋于稳定,相比之下ResNet 50的车标平均精度曲线在迭代3 500次之后也能达到相对稳定的态势,但其曲线的平滑度以及车标平均精度值均弱于YOLOv3-fass算法;YOLOv3和YOLOv3-spp算法的车标平均精度在训练过程中出现了多次的严重下跌,而且其提升速度和车标平均精度大小均弱于YOLOv3-fass算法;YOLOv3-tiny,DenseNet 201的车标平均精度曲线均严重偏离其他算法。综上所述YOLOv3-fass算法的车标平均精度的稳定性更好,更适合检测车辆数据集中的小尺寸车辆信息。

图5 车标平均精度稳定性对比图Fig. 5 Stability of average accuracy of vehicle logo with six algorithms
图6为6种算法的车辆信息平均精度均值稳定性对比图,从图中可以看出,YOLOv3-tiny算法与DenseNet 201算法的车辆信息平均精度均值曲线位于其他4种算法的下方且严重偏离,其稳定性差;YOLOv3和YOLOv3-spp算法的车辆信息平均精度均值曲线随着迭代次数的增加均出现了不同程度的震荡,而且位于YOLOv3-fass算法的下方;ResNet 50的车辆信息平均精度均值曲线的稳定性以及平均精度均值均弱于YOLOv3-fass算法。综上所述,在车辆数据集上随着迭代次数的增加YOLOv3-fass算法的车辆信息的平均精度均值更加稳定。

图6 车辆信息平均精度均值稳定性对比图Fig. 6 Stability of vehicle information mean average accuracy with six algorithms
通过以上实验对比,可以得出结论,YOLOv3-fass算法更适合车辆信息的检测。为了进一步确认在何种条件下YOLOv3-fass算法能够取得更佳的实验效果,进行了以下实验:首先YOLOv3-fass算法在车辆数据集上迭代10 000次并保存实验模型;然后选择320×320,352×352,384×384,416×416,448×448,480×480,512×512,544×544,576×576,608×608共10个尺寸作为输入图像的尺寸,选择0.5和0.75作为阈值(NMS),进行10次测试实验,并记录在不同输入尺寸、不同阈值(NMS)时实验的交并比和查准率,表3为实验测试数据,其中阈值(NMS)为0.50时对应交并比和查准率各为1时的数据,阈值(NMS)为0.75时对应交并比和查准率各为2时的数据。通过分析数据可以得出,当输入图像尺寸为448×448时,2种阈值(NMS)情况下算法的交并比均能够达到最优值,并且在阈值(NMS)为0.75时,查准率更高。因此在输入图像尺寸为448×448、阈值(NMS)为0.75时,YOLOv3-fass算法的车辆信息检测效果更好。

表3 YOLOv3-fass算法的多条件性能指标
4 结 论
针对研究中发现的一系列问题,笔者对YOLOv3算法进行了改进,并提出了YOLOv3-fass算法。经过实验验证,改进后算法的稳定性更好,且能够更精准地检测出图像中的车辆信息,相比原始YOLOv3算法,单张图像的检测时间降低了50%。另外对比了在不同输入尺寸、不同阈值时YOLOv3-fass算法的交并比、查准率性能指标,最终得出结论,当图像尺寸为448×448、阈值(NMS)为0.75时,YOLOv3-fass算法能够取得更佳的检测效果。但是,本文算法在检测车辆信息时仍存在一定的缺陷,如图像中的车辆信息处于复杂场景中时,易出现错检的情况。今后将针对发现的问题进行相应的改进,提高算法在复杂场景中车辆信息检测的性能。
