雾霾天气车辆检测的改进YOLOv3算法
2022-01-12黄开启刘小荣钱艳群黄茂云
黄开启,刘小荣,钱艳群,黄茂云
(江西理工大学 电气工程与自动化学院,江西 赣州 341000)
高级驾驶辅助系统(ADAS)旨在帮助驾驶员完全避免事故,进而大幅减少道路交通事故。车辆检测是ADAS的重要组成部分,在检测中准确知道并精准定位目标车辆,这对避免交通事故的发生起着极其重要的作用。
传统车辆检测算法采用滑动窗口的策略对整幅图像进行遍历,判断车辆可能出现的位置,接着人工选取某个特征,对目标进行识别。例如刘家旭等[1]提出基于方向梯度直方图(HOG)特征的车辆检测算法,周行等[2]提出基于HOG特征和局部二值模式(LBP)特征融合检测算法。传统算法主要存在两个问题:一是基于滑动窗口的区域选择没有针对性,冗余窗口太多;二是由于目标的形态、光照、背景等多样性,手工设计的特征对于多样性的变化鲁棒性较差。随着深度学习的快速发展,卷积神经网络在计算机视觉领域取得了巨大成功,目前基于卷积神经网络的目标检测算法主要分为两类:一类是以 YOLO[3]、SSD[4]、RefineDet[5]等为代表的分类回归方法,另一类是以R-CNN[6]、Fast R-CNN[7]、Faster R-CNN[8]等为代表的基于候选框的两阶段方法。其中YOLOv3[9]作为性能较为出色的目标检测算法被广泛应用到车辆检测任务中。冯加明等[10]提出通过删减部分残差以降低卷积层通道数并通过k-均值聚类与手动调节相结合的方式提高检测的精度;杜金航等[11]、崔文靓等[12]和胡贵桂[13]利用k-均值重新聚类选取锚点预测边界框,提高检测速度与定位精度;吴仁彪等[14]提出利用卷积神经网络的去雾算法对采集的图片进行预处理。汪昱东等[15]通过在检测网络中加入物浓度判断模块来提高网络的适应性和鲁棒性。
以上方法主要存在以下两个问题:一是这些方法大多都是通过k-均值重新聚类锚框的方式侧向提高定位准确性,而分类置信度与定位精度并不是强关联,所以它不能够保证检测框的可靠性;二是目标检测的场景均为晴朗的白天,少有针对雾霾天气进行检测的研究。针对问题一,以YOLOv3为基础网络,加入正态分布模型,将标准差作为定位置信度用来定位,并改进非极大值抑制,引进软化非极大值抑制降低漏检率从而提高定位精度。针对问题二,雾霾天气存在图像退化严重,对比度低,细节信息有损失等问题,严重影响室外视觉检测,笔者添加图像去雾预处理操作,采用单尺度retinex 去雾算法对原图进行图像增强[16],以提高图像对比度。
1 图像去雾处理
1.1 去雾算法
由于雾与霾有着本质的不同,霾的物理模型更加复杂,基于大气散射模型的图像复原方法不适用于雾霾环境下的去雾处理。针对此问题本研究中通过图像增强的方式共选取了单尺度retinex去雾算法、多尺度retinex去雾算法以及McCann retinex算法3种算法对图像进行去雾处理并对去雾效果进行对比。
1.2 去雾效果对比
首先采用单尺度 retinex 算法(single scale retinex, SSR)、多尺度retinex算法(multi scale retinex, MSR)和迭代 retinex算法(McCann retinex)分别对图像进行增强处理,增强效果如下图1所示,可以看出SSR算法表现更好,所以本文中采用SSR算法对图像进行去雾处理。

图1 图像增强效果对比图Fig. 1 Contrast of image enhancement effect
2 YOLOv3及其改进方式
2.1 YOLOv3框架
YOLOv3采用了全新的网络架构Darknet-53(图2),它包含了大量的3×3以及1×1卷积层,通过引用残差模块[17]解决随着网络层数加深模型在训练过程中产生梯度爆炸以及梯度消失的问题。YOLOv3使用了上采样操作,并将大特征图和小特征图上采样后的特征图进行拼接,使网络能够拥有既包含丰富的高层抽象特征又包含精确的位置信息特征的融合特征层。YOLOv3借鉴了FPN(金字塔网络)[18]的思想,在3种不同的规模上进行预测,检测结果分别会有3个不同尺度的输出,它包含了目标的坐标位置,目标是正样本还是负样本,目标属于那个类别的置信度,对于每个尺度的分支而言,在每个网格中会预测出3个结果(因为每个尺度下会有3个锚框)。最后将3个尺度的结果合并进行非极大值抑制(NMS)后输出最终的检测结果。
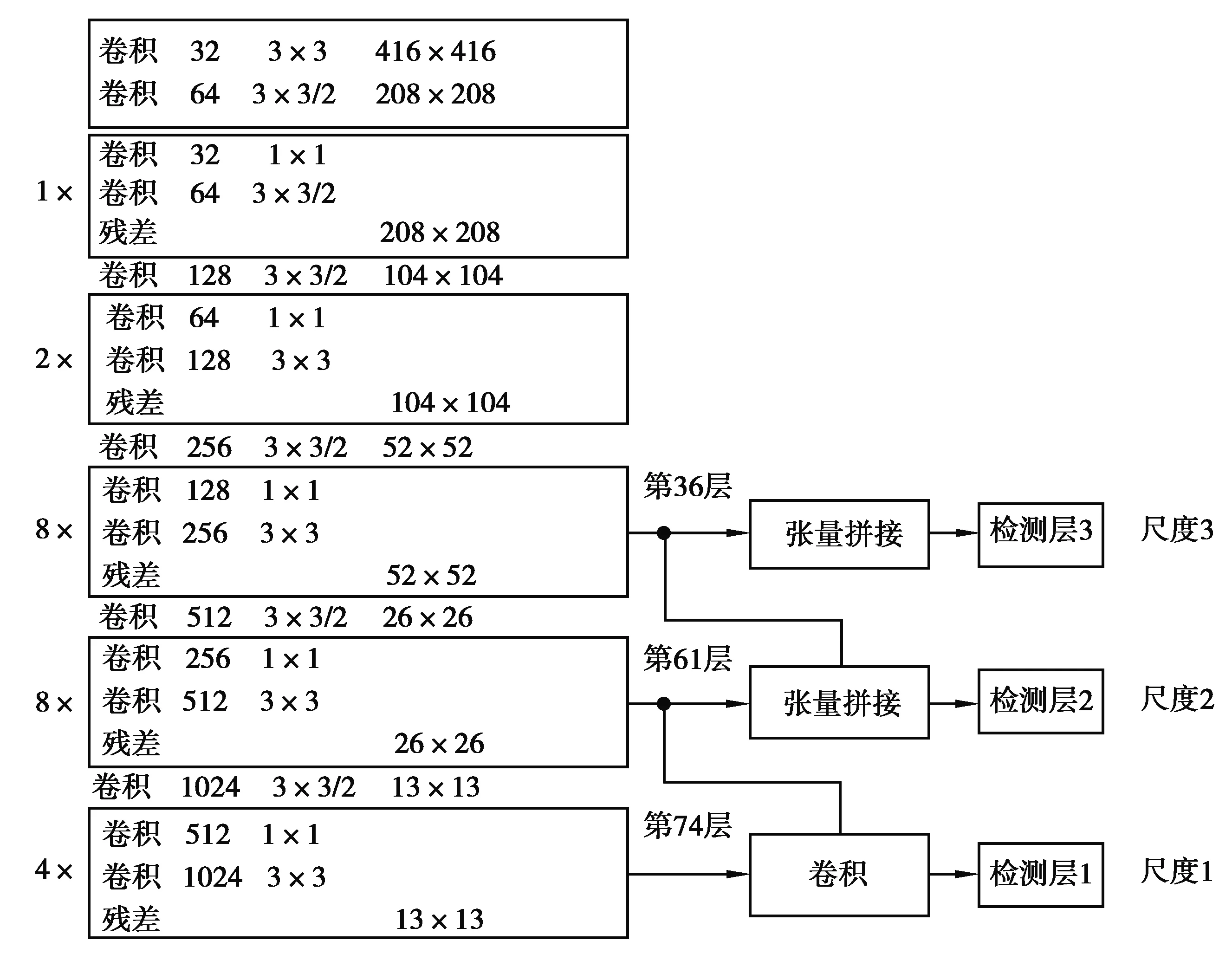
图2 YOLOv3网络结构图Fig. 2 YOLOv3 network structure diagram
2.2 网络输出模型改进
原始算法中目标检测框的输出是以分类置信度为依据的,将拥有高的分类分数的候选包围框作为结果输出,实际上分类置信度与定位精度并不是绝对地成正比关系,选用分类置信度为依据并不能保证检测框的正确可靠。原始算法中目标框只有位置信息而没有概率值,检测框的输出无法以定位置信度作为依据。本研究中提出通过正态分布来对网络输出进行建模,将通过正态分布产生的标准差作为定位置信度。

(1)
(2)
(3)
与原YOLOv3算法一样,这里需要对μtx和μty进行sigmoid操作,将值限定在(0,1)范围内。如果不做约束,预测的边界框容易向任意方向偏移,会导致每个位置预测的边界框可能落在图片的任意位置,这就会导致模型训练不稳定,很难得到正确的偏移量;μtw和μth的处理与YOLOv3相同,不需要通过sigmoid操作,因为长宽的尺度变化可能为1。此外,新增的标准差σtx、σty、σtw和σth也需要通过sigmoid将值限定在(0,1)范围内。标准差表明了坐标的可靠程度,0表示可靠,1表示不可靠,这是因为正态分布中,方差越大,分布的变化越大,包围框的估计结果越不可靠。
原始的YOLOv3进行边界框回归时,由于网络预测输出就是坐标本身,计算梯度时就利用了均方误差的方式。本研究中改进的YOLOv3输出的是均值和方差,所以使用了负对数似然损失函数。改进的边界框损失函数L为:
(4)
式中m为网格数量。
2.3 NMS改进
原算法中选择检测框时使用NMS保留得分最高的包围框并将与当前预测框重叠较多的预测框视作冗余,即将所有IOU(intersection-over-union,交并比)大于阈值的框全部删除。但是对稠密物体进行检测时,如果同类的两个目标距离较近,检测时有可能出现误以为是同一个物体而造成漏检的问题。所以针对这个问题对原始的NMS进行了改善。不是将IOU大于阈值的框删除,而是将IOU大于阈值的框通过高斯加权,降低其置信度。改进后的函数如下:
(5)
式中:si为第i个检测框的高斯权重函数;M为当前得分最高框,bi为待处理框,bi和M的IOU越大,最后得到的分类分数就越低;D为放最终检测框的集合。
预测框的输出要以定位置信度为依据,对所有与M的IOU大于一定重叠度阈值的候选包围框使用加权平均操作更新坐标位置,从而达到提高定位精度的目的。公式如下:
(6)
改进后的YOLOv3检测数据如表1所示。
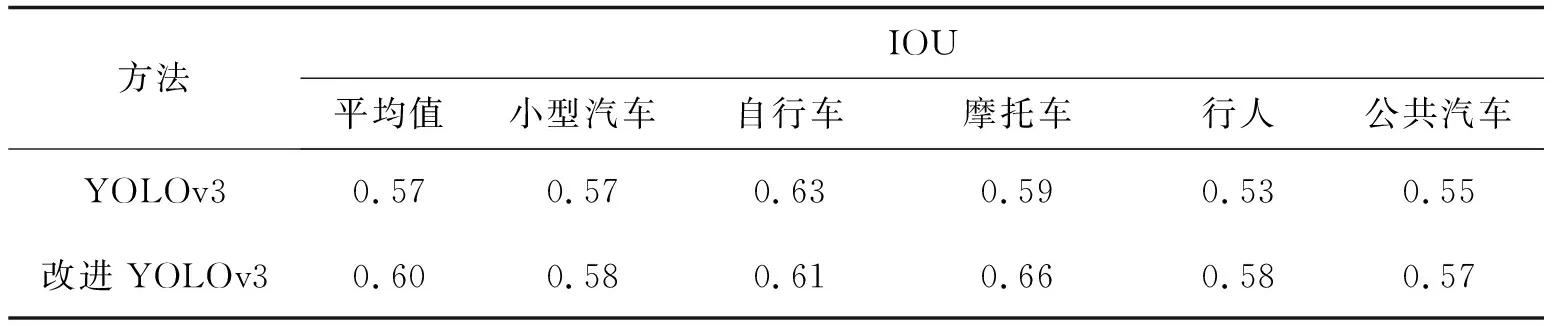
表1 单类别目标IOU检测结果对比
改进后的YOLOv3检测效果如图3所示。

图3 图像检测效果对比图Fig. 3 Comparison of image detection effects
由表1可以看到改进的YOLOv3与原算法相比IOU提高了0.03,表明改进后的算法在定位精度上有所提升。由图3可以看到改进的算法与YOLOv2算法相比可以检测出更多目标车辆,与原YOLOv3算法相比,检测框包围目标更加精确。由图3对比可以看到第一辆白色轿车的检测框,很明显改进的YOLOv3算法在定位上更加精确。原始的YOLOv3算法中多目标聚集在一起的时候会出现了误检的情况,如上图中的左边第2辆轿车,原YOLOv3算法中出现了2个检测框,显示此处有2辆车,很明显这是误检,而通过改进的YOLOv3算法准确识别出了它是一辆车。经过多次连续检测,改进前后的算法在检测速度上基本没有改变,检测一张图片的时间基本都在0.19 s左右,这表明了改进后的YOLOv3算法没有影响检测的速度。
3 实 验
实验测试在darknet框架下进行,训练及测试的计算机硬件配置为Intel(R) Core(TM)i5-8625U CPU@1.60GHz,GPU为NVIDIA GeForce MX250,操作系统为Ubuntu18.04;mAP的计算采用voc2007的方式,阈值设置为0.5。
3.1 实验数据集
本实验中用于目标图像检测的标准化数据集是从RESIDE数据集中抽取的有雾图片与清晰图片共计300张作为训练集,图片主要针对交通道路上容易出现的人、小型汽车、摩托车、自行车以及大型公共汽车5大类进行训练。整个训练过程使用批量随机梯度下降法来优化损失函数,训练大约迭代了55 000次,实验动量系数设为0.9,初始学习率设为0.01,权重衰减值设为0.000 5,批量大小设为32。由图4可以看出迭代至40 000次之后,损失函数明显下降,40 000次之后下降逐渐变得缓慢,最后损失函数稳定在0.5左右。
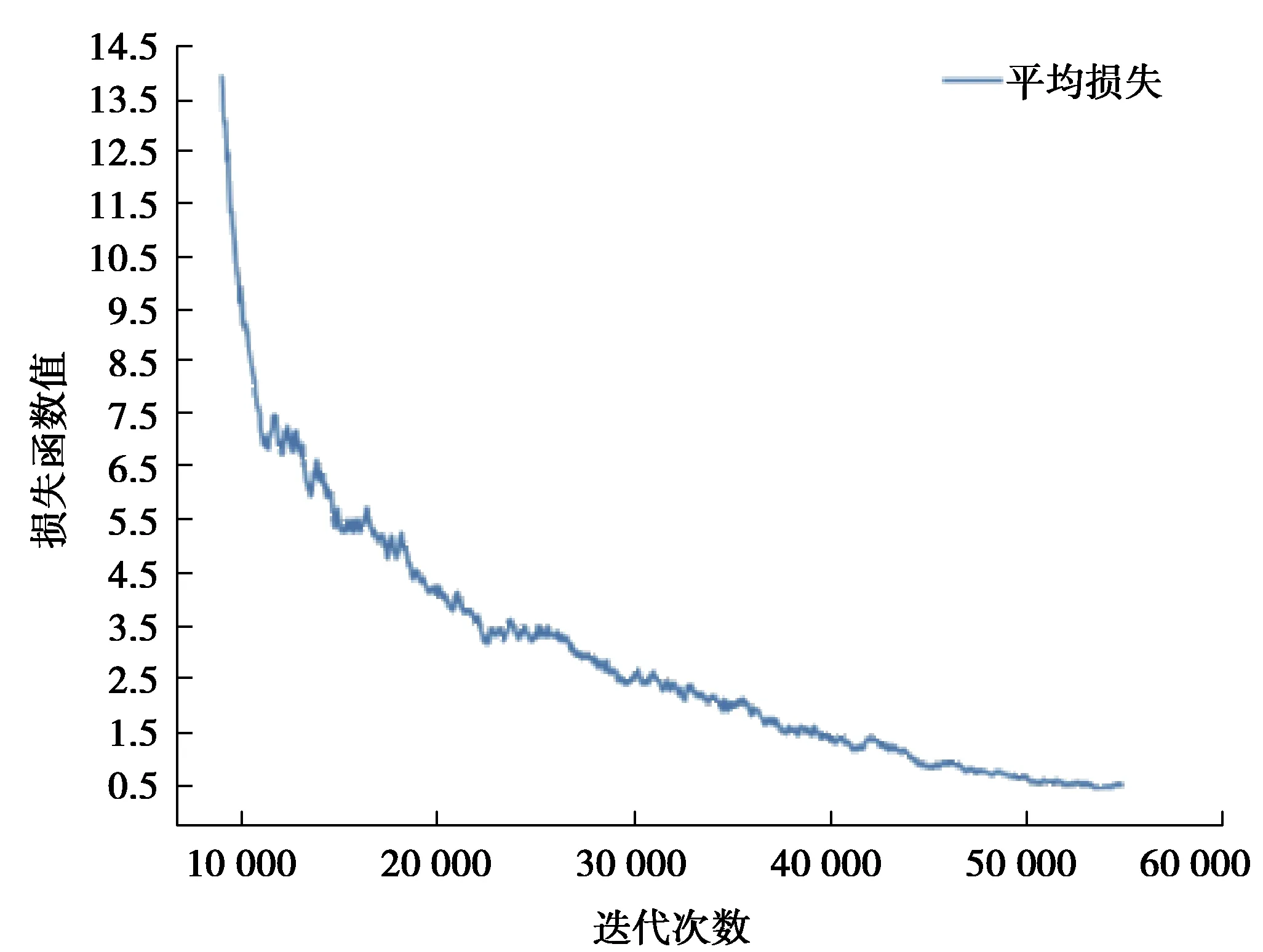
图4 损失函数图Fig. 4 Loss function diagram
3.2 检测结果与分析
为了验证本文算法的有效性,首先将改进的YOLOv3结合NMS算法与原YOLOv3算法进行对比,然后再分别将不同去雾处理算法结合本研究中改进的目标检测算法与原YOLOv3算法进行对比,实验结果如表2所示。由表2可以得出以下结论:在不改变分类精度的前提下通过引入定位置信度以后,目标的定位精度提高了0.1%;经过本文算法-SSR检测得到的平均精度相对于原YOLOv3模型提升了0.44%,说明本文设计的检测算法较原YOLOv3算法检测效果更好。
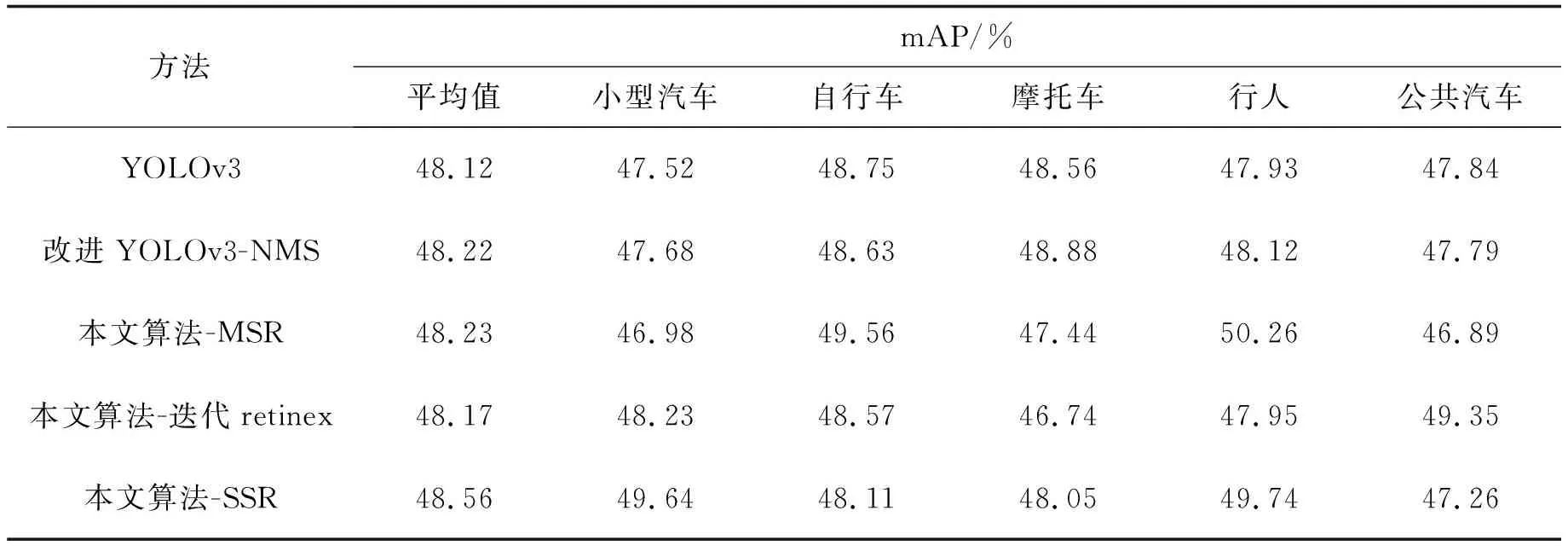
表2 不同方法在数据集上的检测结果
为了测试实际雾天检测效果,设计了针对3种去雾算法的实际效果对比实验,实验得到的检测效果如图5所示。从图中可以看出,本研究中设计的改进算法与原算法相比,在雾霾天气情况下可以检测到更多目标,目标定位也更加精确。

图5 雾霾天气图像检测效果对比图Fig. 5 Comparison of haze-weather image detection effects
4 结 语
为了提高雾霾天气车辆定位的准确性,通过改进YOLOv3的定位方法,使用标准差替代分类分数作为定位置信度,并通过单尺度retinex算法对图像进行预处理。实验结果表明,通过以上方法得到的检测结果对不同场景环境均可保证较高的检测准确率。但是本文中提出的算法仍然存在一些问题,如针对严重遮挡的目标的检测存在定位不精确,以及对经过去雾处理后的图片仍存在一些目标没有识别的情况,这将是后期工作需要改进的重点方向。
