A multi‐agent system for itinerary suggestion in smart environments
2022-01-12AlessandraDePaolaSalvatoreGaglioAndreaGiammancoGiuseppeLoReMarcoMorana
Alessandra De Paola | Salvatore Gaglio | Andrea Giammanco |Giuseppe Lo Re | Marco Morana
Abstract Modern smart environments pose several challenges, among which the design of intelligent algorithms aimed to assist the users. When a variety of points of interest are available,for instance,trajectory recommendations are needed to suggest users the most suitable itineraries based on their interests and contextual constraints. Unfortunately, in many cases,these interests must be explicitly requested and their lack causes the so-called cold-start problem. Moreover, lengthy travelling distances and excessive crowdedness of specific points of interest make itinerary planning more difficult.To address these aspects,a multi-agent itinerary suggestion system that aims at assisting the users in an online and collaborative way is proposed.A profiling agent is responsible for the detection of groups of users whose movements are characterised by similar semantic, spatial and temporal features;then,a recommendation agent leverages contextual information and dynamically associates the current user with the trajectory clusters according to a Multi-Armed Bandit policy. Framing the trajectory recommendation as a reinforcement learning problem permits to provide high-quality suggestions while avoiding both cold-start and preference elicitation issues. The effectiveness of the approach is demonstrated by some deployments in real-life scenarios, such as smart campuses and theme parks.
K E Y W O R D S artificial intelligence, pattern recognition
1 | INTRODUCTION
Creating effective itineraries between points of interest (PoIs)represents a difficult task for users, given the quantity and the variety of constraints to be considered. In general, human mobility is intentional [1], since people move from one place to another in order to fulfil a real-life goal,such as borrowing a book in a library,or seeing an artwork in a museum.Therefore,in the design of an intelligent system capable of suggesting trajectories,the first constraint to be considered is the semantic of the PoIs and the people's movements: realistic trajectories should allow the inclusion of multiple and different semantic classes of PoIs. Furthermore, users may express different personal preferences for PoIs belonging to the same semantic class. If users do not have much time available, for instance,their choice will be biased towards trajectories with the minimum travelling distance or queueing times among PoIs.Moreover, a user moving in an unknown area may find it difficult to proceed among a multitude of PoIs. All these aspects point out the need for automatic tools capable of filtering several information and suggesting trajectories aligned with semantic, temporal and spatial constraints. In this context,Recommender Systems (RSs) play a fundamental role in maximising users' satisfaction in situations where multiple constraints may also be subject to real-time factors [2]. In particular,smart environments,where measurements gathered by a pervasive sensory infrastructure [3] are used to provide intelligent services to users[4],represent a significant scenario which may benefit from properly designed trajectory RSs.Smart museums, for instance, are characterised by customers wishing to spend their visit time for their preferred masterpieces, and conveniently postpone the contemplation of currently over-crowded artworks. Similarly, in a smart campus[5], it is useful to track libraries with free seats or parking spaces with available slots which can be included in the recommendations. Among the most effective recommendation algorithms, collaborative filtering approaches are based on collecting and analysing a large amount of information on users' preferences in order to build a model representing their past behaviour, and predict interesting items for the current users based on their similarity with other ones [2]. In the context of trajectory recommendation, this paradigm assures that suggested trajectories have always been travelled before by other users,thus increasing the reliability of recommendations.However, many approaches for suggesting trajectories show some drawbacks, ranging from the lack of considering semantic information not explicitly related to geographic coordinates,to the need for collecting user preferences explicitly.Moreover, traditional collaborative filtering approaches present an entry barrier in terms of users'past interactions needed to make accurate predictions. This is known as the cold start problem, which arises when a new user, without any previous history, requests a recommendation [6]. Nevertheless, supporting the itinerary decisions of unknown users is especially important in scenarios where users have only few interactions with the RS, for instance, the visitors of a museum. An emerging way [7–9] to deal with this challenging problem lies in adopting a reinforcement learning strategy, considering the two-faced aim of a RS: on the one hand, it aims to maximise user satisfaction with the immediate itinerary suggestion(exploitation of known knowledge), on the other hand, it wants to gain new knowledge about user preferences (exploration of new information) to improve long-term reward,although with some effect on short-term satisfaction. This dilemma is typically conjugated in the context of RSs as a Multi-Armed Bandit problem[7,10].According to this model,using an arm of an imaginary row of slot machines corresponds to selecting an action according to a specific policy.The player (i.e. the RS) has to select which arm to use, and that choice produces the element to suggest.
This work proposes a collaborative and context-aware intelligent system for trajectory recommendation. It is based on a multi-agent architecture that allows to collect and progressively exploit user feedbacks, following a reinforcement learning approach. Semantic, spatial and temporal features of users'movement behaviours are extracted by a profiling agent.A clustering algorithm aggregates users with similar behaviours, originating sets of trajectories that share characteristic traits. A recommendation agent analyses contextual information and current user's past interactions in order to establish its most significant coupling with one of the clusters of trajectories, following a Multi-Armed Bandit policy, and to provide the most appropriate suggestions.Such coupling is dynamically updated accordingly to user feedback, so that the system can refine its recommendations after new knowledge acquisition.We have validated our approach on a dataset of mobility traces of users moving in a smart campus[11,12]and on five public datasets of users visiting attractions in theme parks [13]. The experimental results show that our system provides accurate recommendations,and that the proposed profiling method can correctly identify separate classes of movement behaviour.
The remainder of the paper is organised as follows: Section 2 discusses related work in human mobility profiling and trajectories recommendation. Section 3 outlines the proposed system architecture, discussing the features and the clustering methodology to extract groups of similar users from the data,and describing the Multi-Armed Bandit framework beneath the recommendation agent. Section 4 describes the experimental setting together with the metrics used to evaluate the performance of the intelligent system and analyses our experimental results. Conclusions are presented in Section 5.
2 | RELATED WORK
In recent years, the proliferation of location-aware technologies, caused by the widespread use of personal smart devices,has allowed a vast amount of studies aiming at understanding various aspects of human mobility. In what follows, some of these studies will be discussed, highlighting the mobility features considered in turn.
A first simple approach for defining groups of people with similar movement behaviours entails the comparison of the single places they visit. In [14], the authors cluster foursquare check-ins by means of topic modelling: users who visit PoIs falling into the same topic are grouped together.This approach does not take into account the concept of trajectory, as it neglects the sequential nature of users' movements. Similarly, in[15], the information on visits distribution is interpreted in a probabilistic manner for building a user mobility profile,which is then used for predicting only the next place to visit.
The research study in [16] defines a mobility index by combining the frequency and geographical range of movements in order to capture temporal and spatial aspects of mobility behaviours. This index implies the calculation of several features such as the number of trips, the number of unique regions where users lingered for a significant amount of time (also called stay points), the specific sequences of visited PoIs,the total distance and travel time.This rich feature set misses more specific considerations on the temporal aspects of mobility, such as its weekly recurrent nature [19].
The authors of [17] characterise human mobility by selecting features as the amount of movement, the distributions of visits to PoIs, the entropy of a user's location history and its degree of predictability. We opted for the adoption of the entropy in our work as the characteristic feature,in order to provide a measure of the uncertainty of users' movements.
In[18],the authors use an event-based algorithm to cluster individuals according to their mobility behaviour.They analyse the periods of presence/absence in particular regions by imposing 6 classification rules, which consider the possible sequence of events during each day of the week. This work introduces the important concept of differentiating users' behaviours based on their weekly mobility patterns, which we also exploit in our work by computing the features separately for each day of the week.
The authors of [8] studied the discriminative power of several features in distinguishing between different datasets of human mobility traces. The features considered include as follows: the convex hull enclosing all users positions, the entropy of individual trajectories and the degrees of freedom required to describe a particular trajectory. Although the convex hull represents an interesting point of view on the spatial representation of trajectories, it goes beyond the scope of this work, where we focus on trajectories settled in a single smart environment with a modest quantity of PoIs(see Section 4.1), thus, multiple trajectories would share the same convex hull.
Our work borrows a mixture of the features proposed in the described studies. Research studies have shown that content information on the visited PoIs provides important contributions to the inference of personal interests, for example a user who visits a PoI with semantic tag ‘vegetarian restaurant’gives information on his diet [19]. This is the reason why we add the sequences of visited semantic classes of PoIs as a mobility feature. Moreover, users' activities show strong temporal cyclic patterns in terms of hour of the day and day of the week [20, 21], therefore, we also take into account the arrival time in PoIs semantic classes, and we compute our set of features separately for each day of the week. In this way, the clustering algorithm will take into account the semantic,spatial and temporal behaviour similarity in the different weekdays.The set of features we adopt is discussed in detail in Section.3.1.A tabular representation of the features considered in the discussed studies is presented in Table 1. The motivations behind the features chosen for this study will be described in Section 3.1, together with the definition of the feature set.
Several surveys provide a comprehensive overview on the trajectory recommendation problem in the tourism domain.The authors of [22] present a set of relevant recommendation paradigms for this scenario by highlighting the type of service offered to the end user,for example suggesting hotels available in a certain period of the year, or finding a specific combination of PoIs reachable within a certain time range. In [23],different approaches that face recommendation as an optimisation problem with multiple constraints dictated by user needs are discussed. In [24], the authors provide multiple points of view on the recommendation problem in the tourism domain,addressing the different methods to gather information about tourists' behaviour, and the composition of a coherent tour both for individuals or groups.
Since a trajectory is a concatenation of visited PoIs, a related research area to trajectory recommendation is the top-k PoIs recommendation [25, 26]. These approaches perform a variant of the matrix factorisation algorithm which leverages several context information [13]. Unfortunately, as shown in[27], the transition probability between different PoIs is nonuniform, meaning that venue visits are not independent of each other.Thus,the sequential nature of a trajectory has to be taken into account in order to perform effective recommendations. In [28], the proposed system expects a visit sequence of semantic PoIs'categories as input in order to match specific geographic routes, resulting in an onerous interaction request from the user. In [13], geo-referenced photos taken in theme parks are used to infer queueing times at attractions, and trajectories with the least amount of waiting time are recommended. The system also maximises user interests scores and attraction popularity. However, this approach requires starting and ending PoIs as input which may not always be known a priori,and heavily suffers from the cold start problem,needing a tree of visit counts in order to select the next PoI in the trajectory.In[29],the set of potentially interesting PoIs for the user are arranged in a graph structure where edges are weighted with the shortest route travel time, and then,a score function is used to filter the paths according to context and users' preferences related to PoIs categories. But users' preferences are collected by means of a form proposed during the registration phase,and a query to the recommender system has to include explicit parameters such as the starting and destination point or the maximum number of PoIs to visit, thus reducing the automation of the approach. All trajectory recommendation systems discussed so far are not collaborativefiltering-based systems, therefore, trajectories never travelled before could be suggested to users.

TABLE 1 Summary of the features considered in the discussed studies on human mobility profiling

TABLE 2 Notations for the MAB problem formulation
In Ref. [13], geo-tagged photos are also exploited by system in[30],where visual features(such as the colour histogram and other vectorial representations coming from SIFT descriptors) are merged into the matrix factorisation model,allowing a better management of the cold start problem.However,the approach requires a simultaneous use of multiple machine learning algorithms to process photos' contents,which can be computationally demanding. In [31], a first preprocessing phase aims at learning vectorial representations of PoIs from textual information retrieved from Wikipedia.These textual information are merged with user-PoIs visit relationships and PoIs semantic classes in order to compute a profit score for each PoI, and a variant of the travelling salesman problem is adopted to build a trajectory. However, this approach heavily suffers from the user cold-start problem,being unable to recommend trajectories to users with no previous visiting history.
Among the recommendation approaches which leverage clustering algorithms to infer common traits in user behaviours, [32] adopts the k-means algorithm in order to group similar users and suggest elements according to the cluster they belong. Such an approach requires each user to belong to only one group; conversely, in our approach, the cluster of belonging may change over time, according to the online feedback received by the user. The method in [33] provides a different perspective, performing a hierarchical clustering algorithm to aggregate PoIs in order to identify a path of maximum interest for the current user. However, this approach requires the specification of the initial and final PoIs, which may not always been known in advance, especially when visiting an unknown environment. The AGREE model [34] adopts a bidirectional recurrent neural network in order to infer affinity between users' preferences and provide a route suggestion; however, even this approach is not capable of dynamically associating users with groups as new feedback responses are provided. The authors of [35] propose a system to extract relevant features from call for tenders, leveraging the k-means algorithm to infer and suggest the most suitable call for the particular skill set of a given company. However, this clustering approach requires an a priori specification of the number of clusters, making it difficult to set up an online recommender system. In [36], a collaborative neighbourhood-based approach for movie recommendations is proposed. The recommendations exploit the k-means algorithm, which enables the identification of groups of similar users, and the Mahalanobis distance in order to compute the similarities of users belonging to the same cluster. Even this approach fails in accounting for the variable nature of the association of a user to a given cluster,which is an aspect of utmost importance in the design of a dynamic system. The work in [37] adopts the k-medoids algorithm to infer the neighbourhoods of users with shared preferences, as well as items with similar features, and tags labels underlying the same interests. The identified clusters are then refined based on friend relationships retrieved from social media. However, the approach neglects the possibility for users to change their interests over time.
In the broader research field of Recommender Systems,our proposal relates to the collaborative filtering bandit subfield, where existing literature proposes different design choices for modelling the recommendation problem in terms of arms to explore or exploit. In a pioneering work[10], all the individual elements of the application domain are considered directly as arms, their attributes are used as context information to guide future suggestions. A different modelling choice entails considering users as arms whichwill be chosen as potential neighbours [38], this choice allows to add uncertainty in the classic neighbourhood-based collaborative filtering scheme.

FIGURE 1 Overview of the collaborative filtering bandit system for trajectory recommendation
Considering the above review of the state-of-the-art literature,this study proposes a context-aware collaborative system for trajectory recommendation in smart environments equipped with a pervasive structure of sensors for position detection, such as smart campus, museum or theme park.Differently from earlier works, our system focusses on grouping similar users by means of a weekly set of semantic,spatial and temporal features,and dynamically finding the best pair <user,cluster >by means of the online feedback against the recommendation.
3 | MULTI‐AGENT RECOMMENDATION SYSTEM
The aim of our system is the recommendation of trajectories to users in an online and collaborative mode, exploiting a cloud architecture. The system reckons on two agents addressing logically distinct phases, as shown in Figure 1. The aim of the Profiling Agent(Sec.3.1)is two-fold:it deals with the detection of a weekly set of features encoding semantic,spatial and temporal behaviours; it then performs a clustering algorithm to extract groups of similar users.The extracted clusters represent trajectories which share latent parameters mirroring the behaviours of the grouped users. The Recommendation Agent(Sec.3.2)exploits the clusters as sources of recommendations,and suggests a trajectory according to the occurrence frequencies in the chosen cluster. A reinforcement learning subagent (implementing a Multi-Armed Bandit policy) is responsible for the choice of the best-fitting cluster for the behaviour of the current user,whose selection is further refined by means of the received feedback. Context information regarding the crowdedness of the PoIs, and the travelling distances between them is integrated by a Monitoring Infrastructure sub-agent,which is responsible for modifying the probabilities of trajectories extraction according to the data received from physical sensors, for example wireless sensor networks (WSNs) [39],body area networks [40], or other pervasive data gathering technologies related to ambient intelligence [41] and crowdsensing methods[42].
3.1 | Profiling agent

FIGURE 2 Features detection mechanism.Trajectories are processed in order to extract significant semantic, spatial and temporal characteristics, computed independently for each day of the week
The first step of the Profiling Agent is the identification of different groups of users according to semantic, spatial and temporal features. Since human mobility can be modelled as a periodic routine, for example on a weekly basis [19], it is profitable to track separately the behavioural patterns for each day of the week. Therefore, in order to formulate a vectorial representation of user's movements,we chose to adopt a set of 9 features which are computed independently for each day(see Figure 2).
The vectorial representation of a given user u, Fuis defined as follows:

where each Fdis the vector of features computed for the d-th weekday. Each Fdis composed of a set of 9 features:

Generally, PoIs have a semantic tag which refers to the intended functionality and the underlying activity that is to be performed, such as park, school, library [1], or associated to the type of available resources [43]. For this reason, trajectories between PoIs can be interpreted in two ways: as a sequence of integers representing the identifiers of the PoIs, for example PoI 32 →PoI 54; or as a sequence of the semantic tags associated with the PoIs, for instance Library →Park. The latter reflects the concept of semantic trajectory, first proposed in [44]. The generic i-th trajectory tiis thus composed of the sequence of X visited PoIs: td={x1,…,xX}. Some of the behavioural features we adopt are computed separately for each semantic class of PoIs. In such cases, we denote with φjthe single feature value computed for the j-th semantic class,and then, with

the comprehensive value of the q-th feature for the s PoIs semantic classes contained in the considered dataset.As described in Eq.2,we adopted nine features which are now formally defined together with the motivation behind their choice:
· f1→frequency of visits for each semantic class: let φjbe the frequency of visits for the j-th semantic class,which is defined as the ratio

The feature f1is aimed to collect information about all the PoIs, f1=[φ1,…,φs].
The frequency of visits for every semantic class allows to characterise the activities performed by the users,according to the PoIs they have visited most often.
· f2→PoI with longest permanence time:it is defined as the couple

where x is the unique identifier of the PoI, and y is its semantic class. This feature emphasises the predilection towards a specific PoI as a means to assess the similarity between users.
· f3→average permanence time for each semantic class:the stay time in each PoI category is averaged against all visits,thus the single φjfor the j-th semantic class is computed as follows:

and the comprehensive value of the feature is the set f3=[φ1,…,φs].The average stay time for PoIs semantic labels enables a temporal categorisation of users based on which places, and which activities, they spend most of their time.
· f4→ typical arrival time for each semantic class: we decomposed a day into 48 time slots of 30 min each. We then considered the three most frequent arrival times φjkfor each j-th semantic class, with k ∈[1,2,3], thus, the comprehensive feature is composed of the following:

The arrival time for PoIs semantic labels allows to distinguish users based on which portion of the day they prefer to conduct their trips.
· f5→average travel time: it is defined as the ratio

where i represents the i-th trajectory of the current user,and j the j-th PoI in trajectory i.
The travel time enables a categorisation of users based on the quantity of time they invest in their trips, which is an effective feature to identify users who travel for work or leisure, and in the latter case, a means to identify people taking small breaks or longer ones with their family.
· f6→radius of gyration: it is defined as the characteristic distance travelled by a user, centred in the trajectory's centre of mass [45]. Let Nibe the number of samples (e.g.GPS (lat,lon) coordinates) recorded for the i-th trajectory, and Mudbe the number of trajectories for the user u in day d, the computation of the radius of gyration is as follows:

where sn=(latn,lonn) are the coordinates of the n-th sample, and scm=(latcm,loncm) are the coordinates of the centre of mass. If the dataset under examination does not contain a complete set of position measurements for the users, this feature is computed by considering only the coordinates of the visited PoIs in trajectories.
The radius of gyration provides information on the area swept by the user's movements, allowing to distinguish between persons accustomed to travelling long or short distances.
· f7→entropy of movement: it measures the degree of predictability of a user [19]. Let ti={x1,…,xX} be the sequence of X PoIs visited by a user in the i-th trajectory,the entropy is computed as follows:

· f8→semantic trajectories: it is defined as the user's history of visited PoIs semantic classes sequences. Each PoI is associated with a specific semantic label which provides information about the nature of the activity that can be performed. The i-th semantic trajectory sticonsists of the sequence of Y semantic classes associated to the PoIs visited in a day:

Hence, the history of semantic trajectories is defined as follows:

where T is the total number of trajectories travelled by the current user.
Reasoning upon the visited semantic classes allows to discriminate users according to the activities they enjoy during their trips.
· f9→PoI ids trajectories:it is defined as the user's history of visited PoIs ids'sequences.The generic i-th trajectory tiis composed of the sequence of X visited PoIs:

Then, the feature f9is defined as follows:

where T is the total number of trajectories followed by the user. This feature complements f8and allows to obtain more precise information to evaluate the similarities between users,analysing not only the activities but also the specific locations and sequence of visited PoIs.
The Profiling Agent is also aimed to identify the user groups with similar habits. First, we use a min-max scaling approach to project features into the range[0,1].However,not all features have an algebraic interpretation, and an alternative distance measure has to be defined in order to perform clustering. In particular, for feature f2(PoI with longest permanence time),we assign the minimum distance value 0 when the PoIs are identical, an intermediate value of 0.25 when they share the semantic flag, and the maximum value 1 when they are totally different. We adopted the Damerau Levenshtein distance [46] DL(a,b) to compute the distance between trajectories. It is generally used to calculate the distance between two strings, and corresponds to the number of steps needed for converting string a into string b by adding, deleting,substituting single characters, or transposing two adjacent characters. In order to obtain a value in the range [0,1], we then consider the ratio:
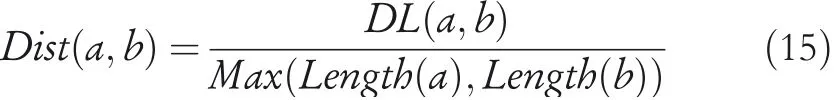
to be the actual distance between two strings, where DL(·)is the Damerau Levenshtein distance, and Length(·) denotes the number of characters in the string. In the scenario addressed here, we consider each single PoI in a trajectory as a single character in a string, therefore, the measure Dist(a,b) discussed above can be used to assess the distance between two trajectories a and b. This formulation allows to compare the behaviours encoded by features f8and f9. In particular, for these features, we consider the histories of trajectories Hui,Hujof users uiand ujas sets,then, we consider the Cartesian product Hi×Hjand compute the average DL distance between all its couples in order to evaluate the distance between the users. A similar reasoning can be done for the f4feature, where each φjkis interpreted as a single character in a string.


FIGURE 3 Users' clusters are interpreted as arms in a MAB fashion.An arm pull corresponds to the extraction of a trajectory from the corresponding cluster. A monitoring infrastructure integrates information about the current user context
3.2 | Recommendation agent
The Recommendation Agent is responsible for providing trajectories' recommendations aligned with users' preferences,which are learnt in real time by means of the received feedback.The main idea is to consider each cluster identified by the Profiling Agent as an arm in the Multi-Armed Bandit (MAB)paradigm (see Figure 3), where a policy infers the best pair <user, cluster >and modifies future recommendations accordingly.
The MAB problem(see notation in Table 2)deals with the tradeoff between the exploration of new actions to accomplish a goal, which involves the accumulation of new information that could increase profit in the long term,and the exploitation of the empirical best action as soon as possible, thus maximising the immediate profit [48]. In the traditional formulation, a k-Armed Bandit problem is composed of k slot machines (also called ‘one-armed’ bandits or arms) with their own reward probability distribution. A gambler tries to maximise,within a limited number of T rounds,the total obtainable profit by pulling the arm deemed most profitable in each round. The pulling process concludes with a reward returned by the selected slot machine.


TABLE 3 QTC evaluation metrics against our UniPa Smart Campus dataset

In our trajectory recommendation setting, in each round t, a policy draws a trajectory to suggest ztfrom a certain cluster of users ck. The trajectory ztis drawn in a probabilistic manner by considering the frequencies of occurrence in ckas probabilities of being selected. In order to perform an offline evaluation of the approach, we adopted the already mentioned Damerau-Levenshtein distance [46]: we compare the recommended ztwith the most ξ similar trajectories in the current user history Ξt, where ξ is a tunable parameter, for example we used ξ=5 because five of the six datasets we considered have an average number of trajectories for users less than 5.
An online deployment of the system may interactively benefit from the real-time user feedback about zt. The system can be used to recommend both semantic or PoIs ids trajectories (see Section 3.1). The trajectories' selection probabilities are influenced from the Monitoring Infrastructure in the following way: the extraction probability of each trajectory is multiplied for the reciprocal of its visited PoIs' crowdedness (i.e. the number of people currently present in the PoI). Then, considering the current position of the user, a distance-based ranking of the trajectories is imposed by multiplying their extraction probabilities for the reciprocal of the total travel distance covered. Indeed, users tend to visit nearby destinations before visiting farther destinations when the semantic meaning behind places is equal [49]. This context integration mechanism is depicted in Figure 4.
For the cluster selection phase, we tested several bandit policies in order to empirically assess which is the best option for every dataset considered:

FIGURE 4 The Monitoring Infrastructure agent is responsible for the integration of context information: PoIs' crowdedness and the trajectories'covered distances are used to refine the extraction probabilities of the trajectories in the selected cluster, and suggest less congested trajectories
· Random: a random cluster is selected in each round.
· ϵ-greedy[48]:a random cluster is selected with probability ϵ,whereas the cluster c*with the highest experimental mean is greedily selected with probability 1-ϵ
· Thompson Sampling [50]: according to the original algorithm formulation,each cluster ckis modelled by means of a Beta distribution (αck,βck)=(1,1) updated against user feedback according to the following rule:

In each round t,all the Beta distributions are sampled,and the cluster corresponding to the highest value is selected.
· Upper Confidence Bound (UCB) [48]: the cluster with the highest upper statistical bound is chosen in each round,adopting an optimistic view which privileges insufficiently explored clusters. UCB algorithms either select the cluster with highest experimental mean or highest uncertainty in its estimate,by choosing At=argmaxckμck+Bound(ck,t)for each round t. Different algorithms adopt distinct upper bounds, which have diverse impacts on the cumulative regrets' lower bound of the policy. UCB1 [48] defines its confidence bound as follows:

where α >0 is an exploration rate. As the number of rounds increases, the confidence bound of the most performed actions decreases exponentially, which means that we are more confident about the estimate of their average reward. In UCB2 [48], the rounds are divided into epochs.In each new epoch, a single action akis performed for a number τ(γi+1)-τ(γi) of times, where τ is an exponential function and γkis the number of epochs in which the akaction was performed. The confidence bound is defined as follows:

where τ(r)=[(1+α)r].The novelty of UCB2 as compared to UCB1 is to ensure that we test the same arm for a significant amount of time before trying a new one, by also allowing to periodically take a break from exploitation, in order to reexplore the other arms.
Another method, KL-UCB [51] uses Kullbeck-Leibler divergence to compute the upper confidence bound for the arms, which has been shown to reach a higher cumulative reward for short time horizon T [52].The KLUCB confidence bound is defined as follows:

The last approach of the UCB paradigm considered in this work is the MOSS [53] algorithm. With respect to UCB1, this method takes into account the number of previous choices of an arm in formulating its confidence bound instead of the general number of elapsed rounds.This ensures a narrower exploration phase. The confidence bound for the MOSS algorithm is defined as follows:

· Exp3 [54] and Softmax [55]: the cluster pulling chance is proportional to an exponential function of either its cumulative reward or experimental mean:

As will be discussed in Section 4.4, KLUCB achieves the best values for the considered performance metrics; thus, it is selected as the MAB policy underneath the Recommendation Agent.
4 | EXPERIMENTAL EVALUATION
In this section, we discuss the experimental setting for evaluating our proposal, describing the adopted datasets (Section 4.1)and performance metrics(Sec.4.2).Then,we perform preliminary tuning of the hyperparameters underneath the MAB policies adopted (Section 4.3), and we evaluate the performances of different MAB policies underneath our system's recommendation agent,by either considering or neglecting the presence of contextual information (Section 4.4). Finally, we compare the performances of our method with different stateof-the-art itinerary recommender systems (Section 4.5).
4.1 | Datasets
In order to assess the effectiveness of our approach, we exploited 5 public datasets1https://sites.google.com/site/limkwanhui/datacodeof geo-tagged PoIs selected in theme parks(Disneyland,Epcot,California Adventure,Disney Hollywood and Magic Kingdom)[13].The theme park datasets exhibit a profit score for the PoIs which represents their popularity among users. We use this score similarly to the crowdedness information provided by the monitoring infrastructure of our system.
Moreover, we also validate our system against a dataset of mobility traces within a simulated Smart Campus (the University of Palermo,UniPa)[11].A smart campus[56,57]is a digitally augmented campus where pervasive instrumented objects and spaces are made responsive to the state of the environment and its inhabitants.In a smart campus,in addition to the ubiquity of users' smartphones [58, 59], several other sensory devices, such as cameras, RFID readers, bluetooth beacons, and Wireless Sensor Networks collect raw measurements that can be exploited by an intelligent system in order to reason upon current context and supply advanced services to users. For these reasons, a smart campus is a great environment to test trajectories' recommendation applications, since there are thousands of students who perform various daily activities within it, and they would benefit from tailored PoIs'suggestions.
Using synthetic datasets also allows to support the empirical evaluation of the clustering phase. We simulated the mobility traces for 150 users during an academic year, each user having 165 trajectories on average. The dataset contains 54 PoIs belonging to eight different semantic classes present in the dataset. Basically, each user's PoI transition pattern is modelled by means of a different fifth order Markov model for each day of the week. Considering the set of 9 weekly behavioural features described in 3.1, we evaluated different clustering quality metrics: the adjusted rand index (ARI) [60]and adjusted mutual information score (AMI) [61] which measure the similarity between true labels and predicted labels assignment; the homogeneity (HO) [62] which measures whether a cluster contains only members of a single class; the completeness (CO) [62] which measures the portion of members of a given class assigned to the same cluster; and finally,the v-measure(VM)[62]which is the harmonic mean between the Completeness and the Homogeneity measures. As already mentioned (see Section 3.1), we adopt the Quality Threshold Clustering (QTC) algorithm, with m=4 (3% of users in the synthetic dataset)and d=0.247(mean value of the inter-users distances matrix). With these parameters, QTC extracts 9 clusters of users, achieving the quality metrics values reported in Table 3. Similar values for HO and CO (0.446 and 0.429,respectively) suggest that the clustering is not biased towards errors in mapping every single ground-truth class of users to a unique cluster (CO) or viceversa (HO). Positive and similar values for ARI and AMI (0.319 and 0.343, respectively) point out how QTC performs well in assigning a cluster to groups of ground-truth users of the same dimension (ARI) and unbalanced dimension (AMI) [63].
The descriptive statistics of all the adopted datasets are presented in Table 4. All the datasets are preprocessed by filtering out users with less than 2 distinct trajectories in their histories.The profiling phase for the theme park datasets cannot benefit from aweekly computation of the mobility features,since the average number of trajectories per user is included in the range [3,5]. Therefore, for these datasets, we cluster users considering the feature f9as described in Section 3.1 without any weekly embedding. In particular, QTC extracts the following number of clusters for the theme park datasets:Disneyland →7,Epcot →7,Calif orniaAdventure →11,Disney Hollywood →10, Magic Kingdom →7. These results suggest that even with several hundreds of users contributing to the trajectories dataset,the different mobility behaviours can be traced back to a limited range of general habits.
4.2 | Performance metrics
Since we state the trajectory recommendation as a Reinforcement Learning problem, cumulative reward and regret can be used to assess the algorithm effectiveness by means of the Damerau-Levenshtein similarity between recommended and followed trajectories,as discussed in Section 3.2.Moreover,themost common metrics to evaluate trajectory recommendation systems can be used:precision,recall and f-score in the scenario addressed here that can be defined as follows [31].

TABLE 4 Relevant features of the datasets adopted for evaluation
Let Trealand Trecdenote the real-life and the recommended trajectory, respectively, and let Prealand Precdenote the set of PoIs in trajectory Trealand Trec, respectively. The three metrics can be defined as follows:

Evaluation is performed for each recommended trajectory against the ξ most similar (according to the Damerau-Levenshtein similarity) trajectories in the current user history Ht,where ξ is a tunable parameter that we set to 5,given that the average number of trajectories per user in five of the six datasets we considered is lower than 5 (see Table 4). A variation of the leave-one-out evaluation is used, where in every iteration, we consider the current user trajectories history as test set, and the histories of all the other users as training set.
4.3 | Recommendation agent parameters tuning
The input parameters of the Multi-Armed Bandit policies adopted in this study vary according to the application scenario.For evaluating the performance of the UCB1 algorithm,the exploration rate has been set as α=2,according to the first proposal of the method[48].Conversely,in order to select the best parameters' values for the ϵ-greedy, UCB2, Exp3 and Softmax algorithms, we performed a comparative analysis of their f -score achieved in different datasets. This evaluation has been performed by running T =100 trials for each user of the six different datasets, considering also the contextual information. The ϵ parameter in ϵ-greedy represents the probability to explore a new cluster;for this reason,we tested values within a range [0,1]. The α parameter in UCB2 controls the amount of exploration performed by the policy, the higher α the higher the upper confidence bound for a given cluster,thus increasing its probability of being explored; we tested the values within a range [0.1,0.9], as suggested in the original study [48]. Finally, the learning rate λ in Exp3 and Softmax controls the focus of the policy on the arm with the largest cumulative reward and mean,respectively,so that the higher λ the higher the exploitation phase of the most profitable arm;also in this case, we verified the values in a range [0.1,1].
The results of these experiments are summarised in Figure 5, which shows the f -score obtained for the ϵ-greedy,UCB2, Exp3 and Softmax policies by varying their input parameters.Even though slightly different values are obtained in the different dataset, a common trend can be noticed. In particular,the best parameter values are those which give more emphasis to the exploitation phase w.r.t.the exploration phase.These are values close to 0.1 for ϵ in ϵ-greedy,and α in UCB2.On the other hand, values of λ close to 0.9 in Exp3 and Softmax cause a longer exploitation phase which ensures a more effective cluster recognition. The same trend will be confirmed by the results discussed in Section 4.4,since policies with narrower exploration phases allowed to reach the highest values for all the considered performance metrics. The values highlighted in cyan in Figure 5 have been chosen as input parameters to the respective policies during the experiments described in the following subsection.
4.4 | Recommendation agent experimental results
The performances of the recommendation agent were assessed while varying the selected multi-armed bandit policies. Since our system extracts trajectories from clusters according to their frequency of occurrence, we perform 10 distinct experiments with T =100 trials for each user (i.e. 100 trajectories are recommended to each user) in order to mitigate the effects of chance on the evaluation.We consider the(lat,lng)pair of the first PoI in each trajectory as the current position of the current user in order to compute the total distance travelled in a single trajectory.

FIGURE 5 Multi-Armed Bandit policies parameters tuning against the six adopted datasets.The bars highlighted in cyan,represent the value chosen for the corresponding policy
Generally, considering user context actually improves the cumulative reward,precision,recall and f-score for every MAB policy, while also decreasing the cumulative regret. In particular, averaging the mean values across all datasets and MAB policies, taking into account contextual information allows to achieve mean reward,precision,recall and f-score score values of about 51%,50%,32%,52%, respectively, while achieving a lower regret mean value of about 35%; this suggests that context information is important in determining the correct users cluster membership. For our UniPa Smart Campus dataset, the improvement in considering contextual information reflects our simulator implementation [11] where users typically prefer to reach closer PoIs under the same semantic class, as suggested in a related research study [49]. The cumulative reward results exhibit a clear lower pattern of values with respect to precision against the theme park datasets,this is due to the nature of the Damerau-Levenshtein similarity measure employed in our computation of the agents rewards,as it also takes into account the temporal arrangement of the PoIs, penalising the asynchronous sequences between recommended and actual trajectories. This aspect is neglected by precision and recall measures, and the reason why this temporal aspect does not affect our synthetic dataset reward values is that the high amount of trajectories per users has given us the opportunity to cluster users with a more fine grained resolution,taking into account the temporal aspects of their weekly movement behaviour patterns,as we discussed in Section 4.1.

FIGURE 6 Performance metrics of different MAB policies against the adopted datasets. The MAB policies are as follows:(1)Random; (2)ϵ- greedy; (3)Thompson Sampling; (4) UCB1; (5) UCB2; (6) KLUCB; (7) Exp3; (8) Softmax; and (9) MOSS
In regard to the assessment of the performances of the MAB policies against the various datasets, Figure 6 summarises cumulative reward and regret, precision, recall and fscore values. Each coloured bar represents the mean value of the corresponding metric, with error bars which show the 95% confidence interval of the mean. The random policy uniformly pulls every cluster without any heuristics, thus collecting the lowest performance metrics. The ϵ greedy policy is the second best performing policy, pointing out how even with few iterations, the agent is able to assign high probability to the real cluster of the current user.Thompson Sampling have a wider exploration stage with respect to ϵ greedy, thus collecting a slightly lower accuracy.Amid UCB algorithms, KLUCB has the highest performance metrics values, and this is attributable to the Kullback-Leibler divergence which significantly increases the upper confidence bound value for the highest rewarding cluster, thus narrowing the exploration phase of incorrect clusters. With regard to policies with exponential pulling probabilities, Exp3 exhibits higher metrics values with respect to Softmax, suggesting that focussing on the arms'experimental means allows for a wider exploitation of the real users' clusters. Summarising, best performances for the trajectory recommendation problem with MAB policies are achieved with KLUCB, and in general, with policies having narrower exploration phases. This highlights how user feedback has a high informative value on its cluster membership and the potentially rewarding trajectories. In light of these results, we consider KLUCB as the MAB policy beneath our Recommendation Agent.
4.5 | Comparative analysis
In this section, we compare our approach against three stateof-the-art itinerary recommendation baselines. In order to perform a fair comparison, we follow the experimental protocol described in [13] considering, for each trajectory in the ground truth, a recommended trajectory that shares the starting and ending PoIs. For this simulation, we adopt the KLUCB policy for the recommendation agent as it resulted to be the most proficient policy (see Section 4.4), we then consider the travelled distance as contextual information for the monitoring agent. As baselines, we selected the following three methods:
· PersQ [13]: uses the Monte Carlo Tree Search method to find an itinerary maximising the interest of the user(calculated considering the labels of the PoIs in the training itineraries), the popularity of the visited PoIs (calculated as the frequency of visit for all users in the dataset),as well as minimising the queueing time at the PoIs (calculated starting from the knowledge of how long it takes to make a turn in the particular attraction);· IHA [64]: employs a heuristic search algorithm to propose the itinerary which maximises both user interests and PoIs popularity, respecting a given user's budget in terms of travelling duration;
· PersTour [65]: infers user interests from its visit durations with a comparison to other users, it then employs two weighting approaches to evaluate the contribution of PoIs popularity and interest preferences for the active user.
In order to make a clear comparison with the state of the art, experiments were performed by exploiting the 5 public datasets discussed so far. Table 5 shows the precision, recall and f-score of PersQ [13], IHA [64], PersTour [65], against our approach. The method we propose exhibits the highest precision values for all the considered datasets, with an improvement which ranges from 39.2% to 181.6% with respect to the baselines. Considering the recall, our methodshows an improvement ranging from 1.3% to 116.8%compared to the other baselines, with the exceptions for the California Adventure,Disney Hollywood and Magic Kingdom datasets, where our approach achieved lower recall values compared to PersQ. However, our approach outperforms PersQ's in terms of fscore in all the dataset, except Disney Hollywood. The different results provided by the two approaches can be explained by analysing the general recommendation paradigm they adopt. In particular, we chose a collaborative filtering paradigm,meaning that only trajectories already travelled by other users in the dataset will be recommended to the current user. Conversely, PersQ belongs to the content-based paradigm, meaning that the approach may propose trajectories never travelled before and which may be of potential interest for the current user. These considerations both implies that in our approach, the suggested trajectories will not overfit on the particular current user's interests (causing lower recall values), and that they will instead be effectively travelled trajectories coming from the identified cluster of similar users (causing higher precision values). Finally, our approach has greater versatility than other methods, which consists in letting the user cluster membership change over time based on feedback, and in overcoming the need for providing the starting and ending PoIs of the itinerary, which are instead required in PersQ and IHA.

TABLE 5 Comparisons in terms of precision, recall and f-score with state-of-art baselines against 5 real life theme park datasets [13]
5 | CONCLUSIONS
In this study, we presented a novel approach for trajectory recommendation in smart environments. Suggestions are provided by exploiting two agents that are responsible for the profiling phase,where users are grouped on the basis of similar behaviours, and for the recommendation phase, where the associations between groups and itineraries are computed by solving a Multi-Armed Bandit problem.Differently from other works that are mainly based on geographic features, the proposed system also exploits context information in the form of travelling distance and crowdedness of PoIs. Moreover, one major contribution lies in the adoption of the reinforcement learning paradigm for modelling the trajectory recommendation problem as a MAB policy, which allows to reduce the amount of information required from users in order to drive the collaborative filtering process. We assessed the effectiveness of our approach against six datasets, measuring five different metrics, and comparing the results with those achieved by three different state-of-the-art itinerary recommendation methods. The experimental results showed the importance of context information in providing more relevant recommendations, and the superior accuracy of MAB policies with narrower exploration phases, for example KLUCB. The choice of the proper context and its integration with the MAB policy represent the most critical points for guaranteeing the effectiveness of the suggestions. Future work can concern the evaluation of different sources of contextual information. For instance, assuming the system is aimed to provide suggestions to the students of a smart campus, relevant information can be inferred by analysing the lessons timetable, or considering the activities performed by friends or colleagues. Moreover, context information can be exploited directly from the MAB policies beneath our recommendation agent, using heuristics such as LinUCB [66]or Exp4 [54].
ACKNOWLEDGEMENTS
This research is partially funded by the Project SmartEP, P.O.F.E.S.R. 2014/2020 Regione Siciliana.
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are available from the corresponding author upon reasonable request.
ORCID
Marco Morana https://orcid.org/0000-0002-5963-6236
杂志排行

CAAI Transactions on Intelligence Technology的其它文章
- Constrained tolerance rough set in incomplete information systems
- Nuclear atypia grading in breast cancer histopathological images based on CNN feature extraction and LSTM classification
- Low-rank constrained weighted discriminative regression for multi-view feature learning
- Modified branch-and-bound algorithm for unravelling optimal PMU placement problem for power grid observability:A comparative analysis
- D‐BERT:Incorporating dependency‐based attention into BERT for relation extraction
- Steganography based on quotient value differencing and pixel value correlation