基于APRIORI-贝叶斯优化XGBoost的电力通信网根告警预测
2022-01-12程路明楼平诸骏豪李凌雁崔晓昱孙毅
程路明,楼平,诸骏豪,李凌雁,崔晓昱,孙毅
(1.国网浙江省电力有限公司湖州供电公司,浙江省湖州市 313000;2.华北电力大学电气与电子工程学院,北京市 102206)
0 引 言
电力通信传输网作为电力系统智能化调度和现代化管理的枢纽,承载着支撑电网安全可靠运行的调度管理业务[1]。当前,以数据为驱动的新兴业务正处于迅猛发展的阶段,电力通信网的安全可靠是海量数据高效传输的基础和关键。而针对大量且复杂的电力通信网运行原始数据和告警数据,如何筛选关键信息进而对通信网告警进行预测,避免规模性电力通信网故障是保障通信网稳定运行的有效途径之一。
电力通信网告警数据通常只反映因网络故障引起的系统相关部件的状态变化,但是由于网络节点和设备之间存在链接,告警信息可能会沿着网络链接传播到与其相连的多个站点,从而产生衍生告警信息[2]。面对繁复的原始冗余数据,难以从中提取根源性告警信息,即故障根本原因,这不仅影响故障排查的精确性和抢修的实时性,也消耗大量的人力物力。目前,多省已开展电力通信网资源信息集中监视平台建设,重点突破根告警预测定位技术,提高网络质量,业务通信通道平均中断时间降低了98.8%,实现告警压缩率0.04%[3]。根告警预测能够协助运维人员预知网络风险,提前聚焦高风险点,及时定位网络可能出现的故障,从根源上排查网络故障,进而提高电力通信网的可靠性,降低区域性衍生告警概率及运维成本损耗[4]。其中设备属性是产生根源性告警的主要因素之一,且其预测技术存在预测精度不高的问题,仍是目前亟待解决的工程难题。因此,如何基于历史告警数据对设备属性造成的根源性告警实现精准预测,是本文解决的重点问题。
现有的网络告警预测研究虽然已经取得了较好的成果,但鲜少区分根源性告警和衍生告警,无差别式修复所有告警信息不仅降低排查效率,增加运维成本,同时可能出现由于未及时排查到根源性告警导致仍然产生大量衍生告警的情况。文献[4-5]提出脏数据预处理(dirty-data-based alarm prediction,DAP)的预测算法,提升数据集精度和机器学习性能;文献[6-7]提出加权告警分析方法和加权增量关联规则挖掘重要告警序列模式,提高通信网络告警预测的精度和效率;文献[8]对通信网络进行状态估计,排除错误告警;文献[9-10]利用聚类算法压缩告警事务集,提高告警关联规则的准确度;文献[11]使用机器学习和深度学习组合算法实现光传输网络的告警分析和故障预测;文献[12]提出了一种基于自学习数据增强的机器学习的告警预测方法;文献[13]采用贝叶斯线性回归分类预测告警顺序模式达到提高预测性能目的;文献[14]采用基于跨层人工智能架构的预测算法,数据量相对较少。
上述预测算法对告警影响因素关联性挖掘不足,导致数据的冗余性较大,价值密度低,预测误差增大,也增加了模型计算的复杂度、运维人员排查故障的难度和成本。同时,现有的机器学习预测算法缺乏对模型复杂度的控制和优化模型的泛化能力,算法训练时间长。
针对上述存在的根源性告警技术研究较少、告警预测精度不足和模型效率不高的问题,本文提出一种基于关联规则挖掘的通信网根告警预测算法,结合根源性告警关键影响因素对根源性告警进行精准预测,有效提升预测精度和时效性,并通过实际光通信网数据验证该方法的有效性,为管理维护人员进行电力通信网根源性故障高效精准运维提供参考。其中,本文的创新点和贡献主要在于:1)针对大量原始告警信息,采用APRIORI算法挖掘根告警关联规则,利用概率函数转化提取关键影响因素,降低贝叶斯优化XGBoost模型中输入数据的冗余度,提高输入数据价值密度,避免无效数据对预测结果的扰动;2)建立基于APRIORI-贝叶斯优化XGBoost的通信网根告警预测模型,利用贝叶斯寻找XGBoost参数最优解,简化模型寻优过程,进而提升模型效率和告警预测精度。
1 基于APRIORI根告警关联因素分析
1.1 数据预处理
本文采用广西省电力通信网实际告警信息记录表作为原始数据集,共13 401条记录,但存在以下缺陷:
1)重复告警。一个设备发生故障时可能会导致其他相关设备发生故障,出现告警传播现象,同时间歇性发生的故障也可能会导致大量的重复告警。
2)属性冗余。原始数据集共包含23个属性,如所属厂家、告警级别、告警对象、确认人、确认时间、设备编码等,但多数属性与告警预测相关性较弱。
3)信息缺失。某些环境或者人为因素会导致告警信息丢失,如网络通道发生故障造成的告警信息无法传送。
4)信息噪声。错误告警可视为信息噪声,将严重影响关联挖掘结果的可靠性。
因此,本文首先对原始数据集进行了预处理,包括对数据进行去冗、去噪、标准化处理,过滤数值严重缺失的记录,对仅有部分缺失的数据暂时保留。预处理后的数据集中每一属性对应元素如表1所示,其中依据不同区域对广西省电力通信传输网络进行划分,包括IT监视二区、IT监视三区、烽火光传输网、华为光传输网、省光传输网A、省光传输网I和中调动力环境7类。
1.2 根告警关联因素分析流程
APRIORI算法具有消除数据冗余、简化数据和关联规则结果全面的功能[15],因此,本文选取APRIORI算法对根告警预测影响因子进行关联挖掘。同时,由于APRIORI算法属于布尔关联规则频繁项集挖掘算法,只能处理离散型变量,不能处理数值型变量,故本文对预处理数据拆分离散化,形成离散型样本集。为进一步详细说明算法流程,本文以样本集中10条数据的7个属性作为APRIORI频繁项集生成的应用示例,抽取数据及属性如表2所示。抽取数据分析仅作为APRIORI算法流程说明,具体根告警关联规则挖掘结果见仿真分析。

表1 不同属性及其对应元素Table 1 Different attributes and their corresponding elements
表2中10条记录代表10个事务,记为T1~T10,z为0-1变量,z=1表示“事务为根告警”,z=0表示“事务不是根告警”,对选取的指标依次由a~g进行编号。X={a,b,…,g}是影响根告警的因子集合,即项的集合;T={T1,T2,…,T10}是根告警的集合,即事务集。每个事务Ti都是项的集合,即Ti⊆X。
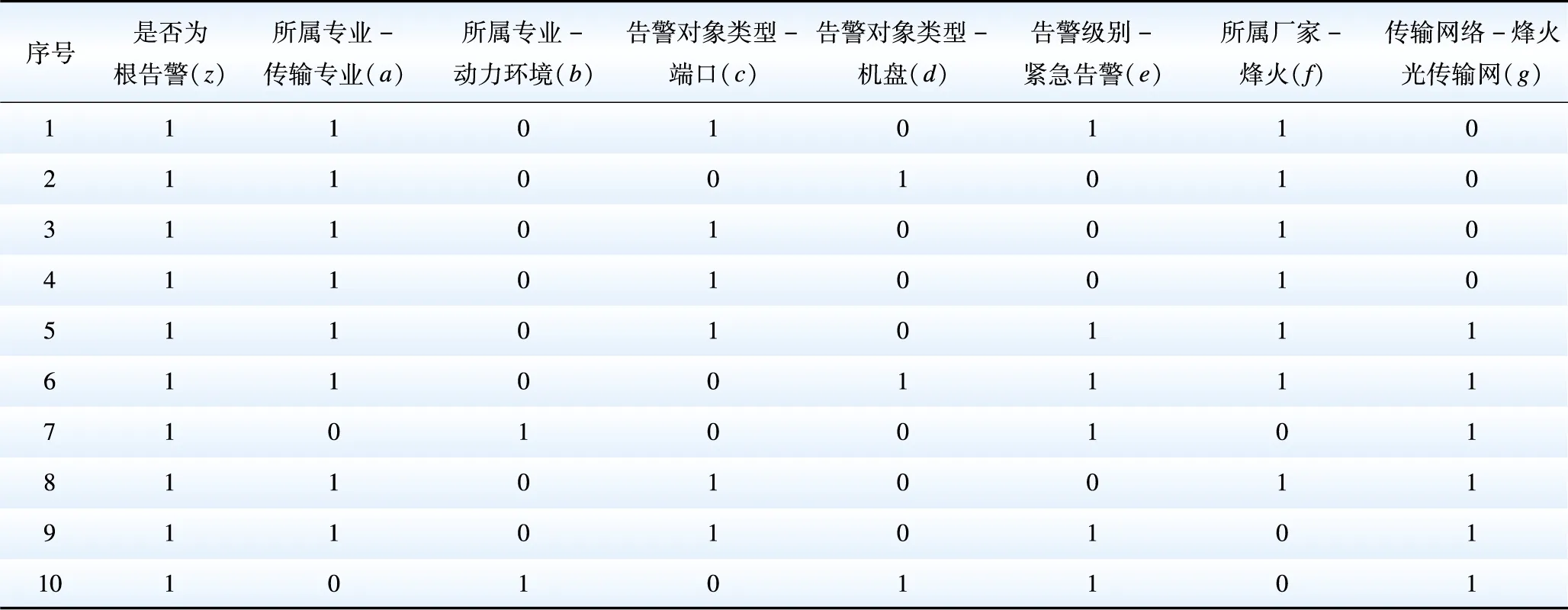
表2 随机抽取数据及元素Table 2 Randomly extracted data and elements
频集的产生需设定最小支持度阈值,项集X的支持度S(X)计算公式为:
S(X)=P(X)
(1)
式中:P(X)代表数据集中项集X的支持数在事务集T中所占的比例,设定最小支持度为50%,APRIORI关联规则生成过程如下:
1)扫描事务集,生成1-项候选集C1,并计算对应项集支持度,选择满足阈值条件的项集组成频繁1-项集L1,如表3所示。
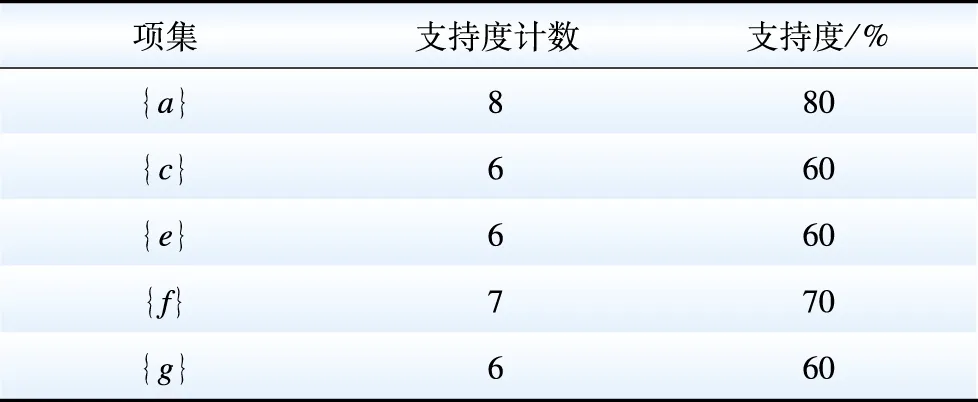
表3 频繁1-项集L1Table 3 Frequent 1-item set L1
2)根据表2产生2-项候选集C2,计算对应项集支持度,选择满足阈值条件的项集组成频繁2-项集L2,如表4所示。

表4 频繁2-项集L2Table 4 Frequent 2-item set L2
3)根据表3产生3-项候选集C3,计算对应项集支持度,选择满足阈值条件的项集组成频繁3-项集L3,如表5所示。

表5 频繁3-项集L3Table 5 Frequent 3-item set L3
由于L3无法继续构成候选集C4,算法结束迭代,最终得到的频繁项集为L1、L2、L3。
4)同时满足设定的最小支持度和最小置信度阈值输出为强关联规则,据此生成根告警关联规则X⟹Y,其中X为前项,Y为后项,支持度S(X⟹Y)和置信度C(X⟹Y)计算公式如式(2)所示:
(2)
式中:P(X∪Y)为事务集T中X、Y两个项集同时出现的概率;P(Y|X)为出现项集X的事务集T中,项集Y也同时出现的概率,其中X、Y均为包含于T的项集,且X∩Y=∅。本文中的支持度指的是表1所列26类元素中若干项存在导致根告警出现的概率,而置信度表现为若干项属性存在导致根告警出现的可能性大小。规定最小支持度为15%,最小置信度为80%,生成的强关联规则如表6所示。由表6可知,所有规则均符合最小置信度阈值要求,输出为强关联规则。

表6 强关联规则挖掘结果分析Table 6 Analysis of mining results of strong association rules %
2 基于APRIORI-贝叶斯网络的通信网根告警预测模型
2.1 关联规则概率化
利用关联规则概率化确定影响因子的关联度,对APRIORI关联因素分析结果进行转换作为预测模型的样本集,用Ri表示某个影响因子的关联度,反映该影响因子和其他影响因子的关联程度及该影响因子和是否为根告警之间的关联程度,Ri计算值较大时代表关联度较强,反之相反。具体关联度概率化计算如式(3)所示:
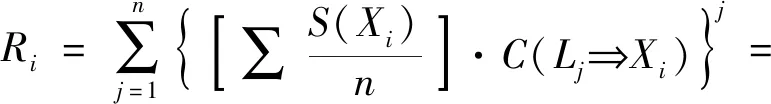
(3)
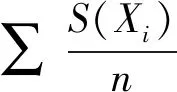
2.2 贝叶斯优化XGBoost预测模型
贝叶斯优化XGBoost预测模型以关联规则概率化后筛选的影响因素作为模型的输入样本集,将贝叶斯优化应用于超参数寻优中,得到光传输网的根告警预测结果。
2.2.1 XGBoost模型
XGBoost是在梯度提升树的基础上对boosting算法进行的改进,将弱分类器集成为一个强分类器,利用分类与回归树模型(classification and regression tree,CART)进行预测,第k棵树的预测函数为:
(4)

XGBoost算法每轮优化的目标函数κ和回归树复杂度函数Ω(fk)分别为:
(5)

将式(4)代入目标函数中,在XGBoost模型训练过程中,每一轮迭代都在现有树的基础上增加1棵树拟合前面树的预测结果与真实值之间的残差,因此第t轮优化的目标函数变为:
(6)

(7)
式中:Gm、Hm分别代表一阶导数和二阶导数;Im代表叶子节点m的集合。
2.2.2 贝叶斯优化
贝叶斯优化算法用于结合历史数据的全局优化,算法核心为概率代理模型与采集函数。由于本文构建的预测模型分布未知,无法根据经验选择最优的模型,因此在仿真过程中概率代理模型使用高斯过程回归模型[16-19],采集函数使用改进概率(probability of improvement,PI)方法。贝叶斯优化超参数的目标函数为:
(8)
式中:X是实验样本集;x*是目标函数达到最优的一组集合。
贝叶斯优化XGBoost算法的实现步骤为:
1)初始化XGBoost模型参数以及超参数取值范围,生成随机初始化点,将APRIORI算法处理后的告警数据样本集和初始化参数作为贝叶斯优化中高斯模型和根告警预测模型的输入变量,得出根告警的预测结果,修正参数改进高斯模型,使其输出结果更接近真实值;
2)在修正后的高斯模型选取待评估的参数组合点,使得采集函数达到最优,同时高斯模型比其余参数组合点更逼近目标函数的真实分布,得到最优参数组合;
3)将全局最优参数组合输入XGBoost模型中进行训练,如果选取的参数组合的误差低于预先设置的阈值,则算法结束,输出对应的参数组合以及模型的预测误差(xi,f(xi));
4)如果f(xi)不满足阈值要求,则将(xi,f(xi))输入到高斯模型中,对高斯模型进行修正,返回步骤2),直至低于预先设置的阈值。
基于APRIORI-贝叶斯优化XGBoost预测模型的具体流程如图1所示。
随着电力通信网中的网络参数和拓扑结构不断发生变化,样本数据集随之更新,本文所提算法可通过调整XGBoost模型中的叶子节点个数、树的深度、叶子节点3个参数重新训练预测模型来适应新出现的样本数据,同时通过调整目标函数中的正则项控制预测模型的复杂程度,防止出现过拟合的现象,保证模型的预测精度和复杂度。
3 仿真分析
3.1 参数设置
本文的实验运行环境为64位Windows10操作系统,处理器为Intel(R)Core(TM)i7-7500U CPU @ 2.70 GHz 2.90 GHz。本文采用随机抽取原则抽取不同量级数据,但在每一量级下控制根告警与非根告警的样本比例为1∶4。

图1 基于APRIORI-贝叶斯优化XGBoost的根告警预测流程图Fig.1 Flowchart of root alarm prediction based on APRIORI-Bayesian optimization of XGBoost
贝叶斯优化XGBoost模型预先设置相关仿真参数取值范围及含义如表7所示。
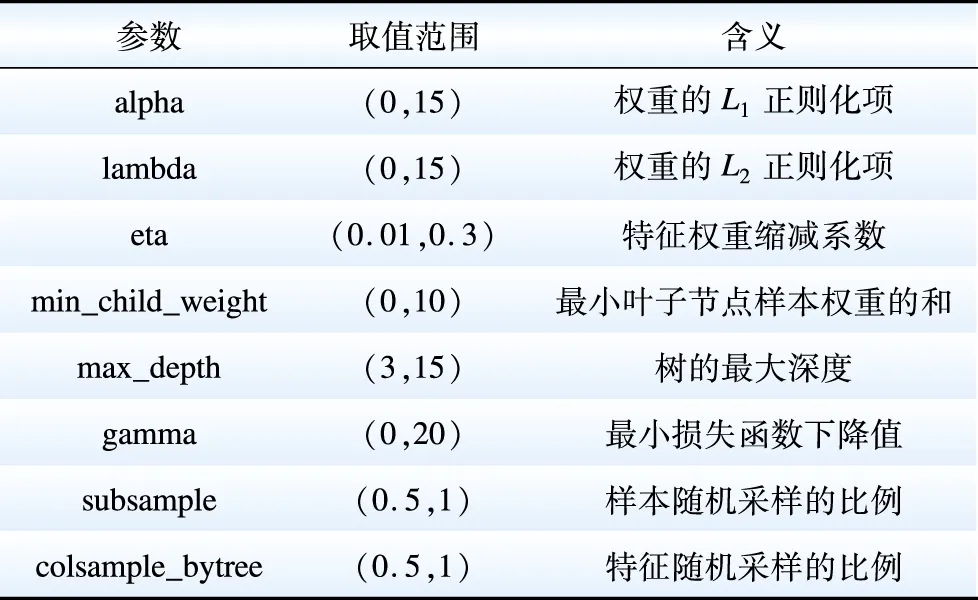
表7 XGBoost参数范围及含义Table 7 Range and meaning of XGBoost parameters
3.2 根告警关联分析结果
为避免关联规则的冗余性,重复对比多次实验结果后选取前项最大项目数为3,最小支持度为15%,最小置信度为80%,对结果进行整合排序后如表8所示,其中规则ID指的是利用APRIORI算法生成的所有关联规则的编号。
由表8数据可得下列结论:1)规则ID17、13、16显示,所属专业因素中传输专业导致通信网根告警的支持度最高(94.493%),其次是所属厂家因素中烽火(82.351%)和传输网络因素中烽火光传输网(82.351%),这3个因素在很大程度上影响着电力通信网根源性告警;相比之下告警对象类型影响较小,如规则ID8、4所示;2)多个因素同时出现时也很可能会导致通信网根告警的产生,如规则ID35、34和55。
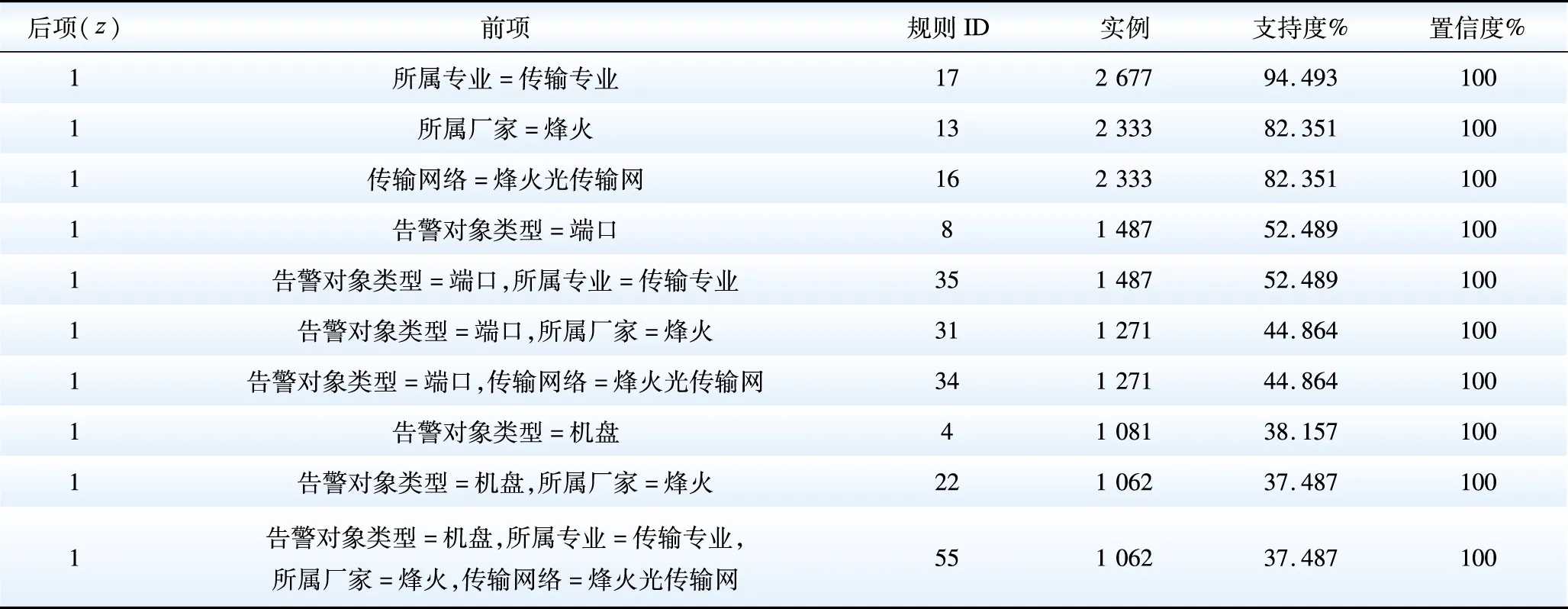
表8 根告警关联规则挖掘结果分析Table 8 Analysis of the mining results of root alarm association rules
3.3 APRIORI-贝叶斯优化XGBoost预测结果
对上节关联规则挖掘结果进行概率化提取的特征包括传输网络、所属厂家、所属专业、告警对象类型和告警级别5个。本文以准确率A、召回率R、F-值作为算法性能评价指标,选取了如下3种算法仿真对比通信告警预测的准确率:
对比算法1:序列模式挖掘算法[20];
对比算法2:基于netica API的贝叶斯推理算法[21];
对比算法3:基于主成分分析优化随机森林算法[22]。
其中,对比指标计算公式如下:
(9)
式中:TP代表实际为根告警并且被预测为根告警的数据;FN代表实际为根告警但未被预测为根告警的数据;FP代表实际为非根告警但被预测为根告警的数据;TN代表实际为非根告警并且被预测为非根告警的数据;α代表A和R的权重比值,本文计算选取α=1。F越高表示实验方法越有效。
3.3.1 关联因素挖掘对预测精度影响分析
为分析APRIORI对本文算法预测性能的影响,选取最佳支持度,首先对比分析不同告警数据量下有无APRIORI以及采用FP-growth关联规则挖掘的算法预测准确率。如表9和图2所示,在预测模型中增加APRIORI算法遴选关键因素,利用APRIORI算法挖掘关联规则的准确率高于FP-growth,3种算法的最高准确率分别为0.855 2,0.847 1和0.831 9,随着数据量的增多,3种算法的准确率都呈现先增大后减少的趋势,这是由于告警数据量增多会造成贝叶斯优化XGBoost预测模型过拟合,导致样本数据继续增加时,模型预测准确率下降。
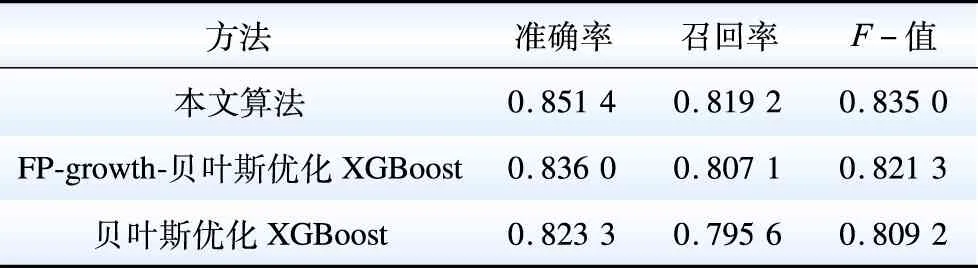
表9 不同算法的根告警预测性能分析Table 9 Analysis of root alarm prediction performance of different algorithms

图2 关联因素挖掘对预测精度影响对比Fig.2 Comparison of the impact of correlation factor mining on prediction accuracy
3.3.2 不同算法预测精度对比分析
在同样场景和参数设置下,如图3所示,APRIORI-贝叶斯优化XGBoost算法的预测准确率、召回率、F-值3个评价指标均有明显提升,各项指标均达到80%以上,本文算法的准确率为85.14%,比序列模式挖掘、贝叶斯网络和优化随机森林算法分别提高4%。
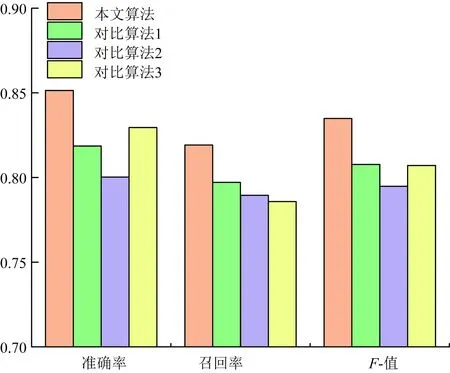
图3 4种算法预测结果对比Fig.3 Comparison of prediction results of 4 algorithms
为验证算法的高效性,本文选取算法执行时间作为反映算法复杂度的指标[20-22],对不同告警数据量下的4种算法执行时间进行了仿真对比。如图4所示,本文算法的执行时间整体最短,同时随着数据量的增多,本文算法执行时间的增长速率变缓,在较大的数据样本下仍能维持较短的执行时间,在数据量达到10 000时,本文算法的执行时间相比于序列模式挖掘算法、贝叶斯网络及优化随机森林分别降低18%、19%及12%。在未来感知互联的通信网络中,面向海量的网络数据,显然本文方法具有更好的预测效果,能够在较短的时间内快速获取有效信息,及时排查和定位网络故障,降低资源投入和网络风险。

图4 不同告警数据量下算法执行时间Fig.4 Algorithm execution time under different alarm data volume
3.3.3 不同支持度对预测精度影响分析
本文设置支持度从10%至50% 变化,分析在不同支持度下算法的预测性能。仿真结果如图5所示。
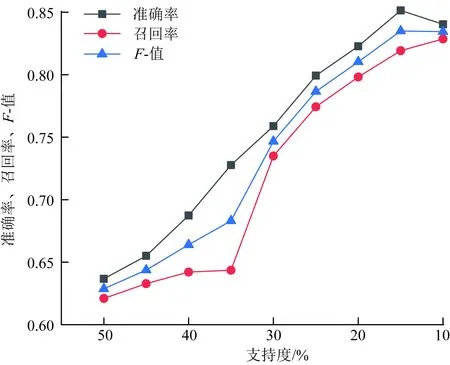
图5 不同支持度下告警预测性能Fig.5 Alarm prediction performance under different support levels
由图5可知,随着支持度的减小,告警预测的准确率和F-值先增大后减小,这是因为随着支持度的减小,挖掘出的告警关联规则增多,将小概率的关联规则纳入预测模型的先验知识,能够提升预测精度,然而过多的关联规则会导致降低有效关联规则的占比,对预测精度造成影响。因此,由仿真结果分析可知在支持度为15%时算法整体性能达到最优,因此本文在关联规则挖掘时设定最小支持度为15%。
4 结 论
为及时排查和预测电力光传输网络的根源性告警,本文提出一种基于APRIORI-贝叶斯优化XGBoost的根告警预测方法,利用电力通信光传输网的告警数据关联分析精准预测高风险根源性告警,为运维人员提供必要的数据信息,进而高效快速定位高风险点,及时排查故障,降低网络风险概率和运维成本。仿真实验结果表明,与现有的告警预测方法相比,本文所提方法能在多方面提升预测精确度和整体性能,具有较好的可行性和优越性。
在今后的研究中将重点研究频繁模式树、泛化序列模式、关联分类算法等改进关联分析算法,进一步提升数据挖掘效率,实现挖掘效率和预测准确率的高效优化。
