空间数据挖掘驱动城市疫情监测常态化的作用研究
2022-01-12郭名静
郭名静,景 琳
(1.东华理工大学 理学院; 2.江西应用科技学院 国际商务分院, 江西 南昌 330013)
发型传染病在人类历史上曾多次出现,比如天花、鼠疫、霍乱、甲型 H7N9 流感、SARS(Severe Acute Respiratory Syndrome),以及新型冠状病毒肺炎(Coronavirus Disease 2019,COVID-19)等,给国家和人民生命财产安全造成了重大损失。虽然国内针对COVID-19已经取得重要研究成果,形成了卓有成效的疫情防控方案,但随着全球疫情风险级别的不断上调,城市疫情监测在未来很长一段时间将成为一种常态化工作。疫情监测是预测预警疫情的爆发并监测疫情的发展和结束,指在传染病发生时,在人、植物或动物中进行的针对传染病疫情的监测,监测疫情发展是获取感染区域、规模、密度、时空分布和流动情况,反馈疫情数据给防控部门,协助部署和协调资源,帮助科研人员掌握疫情传播模式和特点,帮助公众远离疫情严重场所,科学预防感染。由于疫情监测工作既涉及患者和医疗资源的大量人流,又需要物流分布信息,还具有时间和专题属性。因此,各种通过传感器网络、定位设备和社交网络获取的空间数据成为当前研究疫情发展过程和辅助发现预测潜在疫情的重要战略资源。
一、空间数据挖掘的研究现状
空间数据是人们认识现实世界的基础战略资源和智慧源泉。信息技术的发展使对空间数据的采集、存储和处理等技术迅速发展,使得空间数据快速增长,远远超出了人们的理解能力。当数据积累到一定程度,必然会反映出某些为人所感兴趣的规律,而这些规律一般隐藏在数据深层。空间数据种类多样,来源复杂,传统的数据库系统已经无法发现隐藏在数据背后的隐性知识,常规的数理统计模式停留在空间数据的处理阶段,只完成了从数据到信息的过程,处理的数据量十分有限。现有的人工智能和机器学习等技术也都不能独立的将数据最大限度利用,空间数据资源中蕴含的最大价值也远没有得到充分的挖掘和利用,迫切需要一种能够将大量数据转换成有用知识的新技术,以解决困扰空间数据利用面临的瓶颈问题。
1989年召开的第一届国际联合人工智能学术会议(IJCAI)催生了从数据库中发现知识 (knowledge discovery in database,KDD)的概念,通过知识发现可以从数据库中获取知识。因为空间数据与空间位置密切相关,所以KDD开始影响空间数据的利用。1994年GIS国际学术会议上,李德仁院士首次提出从地理信息系统数据中发现知识的概念,并率先从GIS空间位置数据中发现了用于指导位置空间分析的知识。随后,空间数据挖掘渗入数据挖掘、知识发现以及地球空间信息学等相关学科,越来越引起全球学者研究和应用的极大兴趣。空间数据挖掘可以为基于位置的空间数据的应用提供有价值的知识,带来巨大价值,成为提升国家综合能力和保障国家安全的新利器,提升政府治理能力的新途径。空间数据挖掘是一种空间决策支持技术,重在最大限度提升数据资源的有效利用能力,实现更为准确的检测、分析和预测,特高决策的针对性、科学性和可靠性。在疫情防控工作中,空间数据挖掘已经渗透入多个环节,特别是在传染病传播的测量传染病的时空分布和模拟验证传染病传播过程两个阶段是最适合空间数据挖掘的分析方法,例如,疟疾分布特征的研究、H7N9疫情流行与环境因素的相关性研究、霍乱疫情爆发风险增加的地区以及SARS疫情监控和位置空间信息分析研究等。
目前,虽然空间数据挖掘取得了一定的研究和应用成果,但海量快变和多源高维的特点又给空间数据挖掘应用于疫情监测带来了新的挑战。在此次COVID-19疫情防控期间,“健康码”技术的应用为政府采集了大量的居民行动轨迹数据,为常态化疫情防控工作的开展提供了宝贵的空间数据。但是伴随着“健康码”的普及,采集的数据的数量、大小和复杂性都在飞速增长,极大超越了常规的事务型数据源,导致数据难理解、难整合,限制了对数据的全面分析和深度应用的能力。鉴于空间对象种类的多样性,“健康码”采集的空间数据来源广泛,每个空间对象基本由多个属性描述,存在空间或非空间关系,增加了空间数据挖掘的维数,带来了高维数据挖掘的困难。这些难点可能直接影响空间数据挖掘的准确性和可靠性,影响空间数据挖掘的正常发展。虽然这些问题越来越被重视,并取得了一定的理论方法和实际应用的成果,但是还不够深入。如果正确解决这些难点,就可能避免利用错误信息而得到可靠性较低的、残缺的,甚至错误的知识,就可能避免因为利用错误信息而导致的疫情防控决策失误。
二、空间数据的加权聚类提取研究
李兰娟院士曾多次公开提出要重视大数据在疫情防控中的应用。李德仁院士也呼吁建立一个基于位置大数据的疫情防控体系,结合多属性特征约束挖掘空间位置数据中所蕴含的空间模式。这种针对区域内对象位置点群的聚集分布特征的发现属于基于空间位置数据的城市空间分布模式研究,通过提取相似或相近密度的聚集点,将其与边界外点区别识别。一般有两种识别方法:一类是根据区域的指标聚集特性来标识区域边界,如均匀格网法;另一类是根据点群的密度值利用等值线形成边界。经典的基于密度聚类方法 (Density-based clustering algorithm,DBSCAN)可以利用数据点群的空间聚类直接提取聚集模式,在处理非规则凸型的位置数据点群时表现出了较好适用性。
(一)传统D BSCA N算法
基于密度的DBSCAN算法可以发现稀疏数据点区域中的密集数据点,该算法利用相似度函数判定数据点的归属类,再根据密度相连原理提取数据点的最大集合,也叫做聚类簇。算法中判定数据点归属的相似度函数是基于欧几里得距离(公式1),其中,位置数据集中数据点的位置坐标为(x,y),其中 i=1,…,n。

以武汉市中心城区范围内地理坐标为东经114.15°~114.45°,北纬 30.45°~30.7°范围内共计 22843 条新浪微博签到POI数据(表1)为例,每一条POI位置数据包含5个属性,其中,经度和纬度坐标共同构成了位置数据点的地理位置属性特征,商户公司名称、类别和签到次数均为位置数据点的非地理位置属性特征。对餐饮和零售行业高热点和热点区块进行聚类提取,得到3个餐饮行业的热点区块,总共包含98个高热签到位置数据点,签到次数共计120361次(表2)。得到3个零售行业的热点区块,总共包含87个高热签到位置数据点,签到次数共计302915次(表 3)。
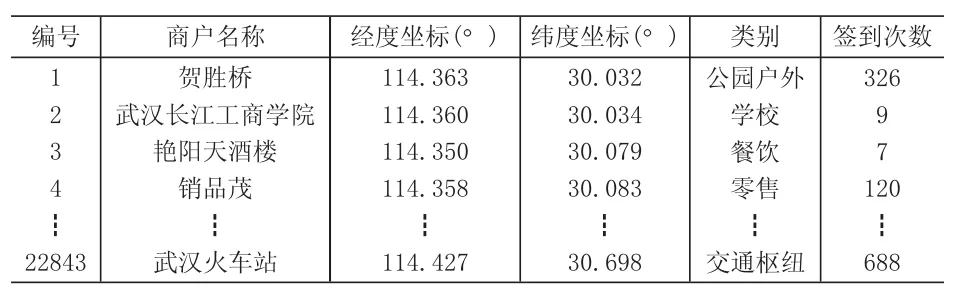
表1 武汉市的新浪微博PO I数据集
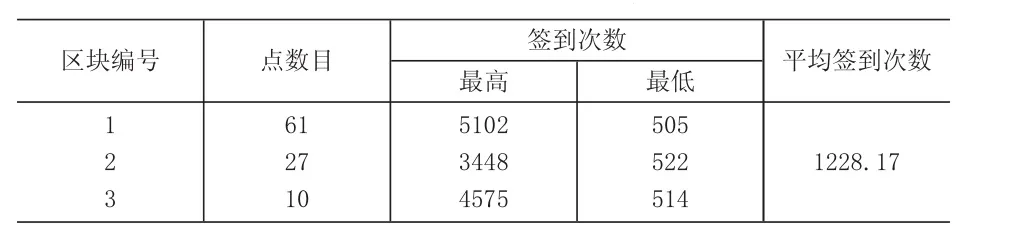
表2 餐饮业热点区块的位置数据点统计(基于密度聚类提取)
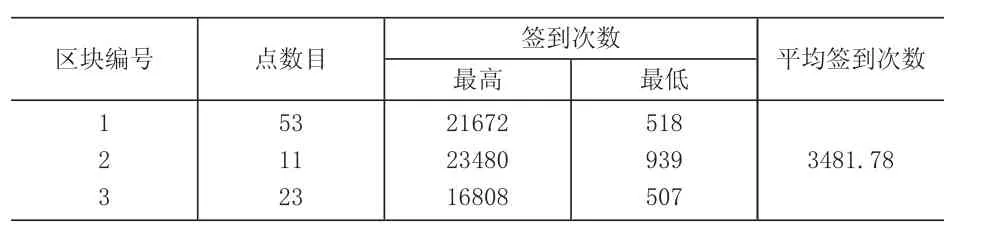
表3 零售业热点区块的位置数据点统计(基于密度聚类提取)
(二)加权D BSCA N算法
DBSCAN算法提取的聚类簇只满足地理位置的高聚集分布,而没有考虑数据点的签到次数属性。因此,对签到次数属性值做变换得到一个按照公式(2)计算权重系数的 w,其中 j=1,…,n。

可见,w取值范围是(0,+1),且 w取值越接近 +1 说明数据点(x,y)的签到次数越高,即该点签到热度越高,在与簇中心点(x,y)距离相等的条件下,则越可能被划入簇中。因此,可得加权DBSCAN算法中相似度函数的距离计算公式(3)。其中,参数ω的取值根据权重系数w的取值范围而定。
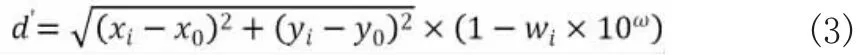
仍然以表2数据集为例,动态加权聚类算法在餐饮行业中提取了3个热点区块,总共包含100个高热签到位置数据点,签到次数共计140191次(表4)。提取了3个零售行业热点区块,总共包含94个高热签到位置数据点,签到次数共计330360次(表5)。
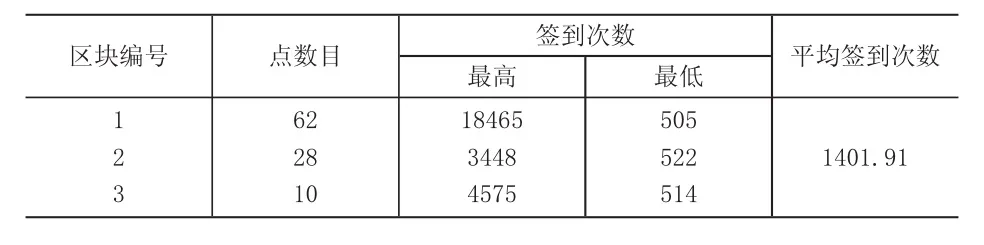
表4 餐饮业热点区块的位置数据点统计(加权密度聚类提取)
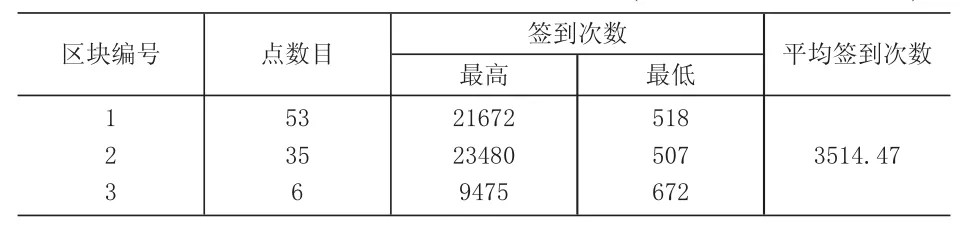
表5 零售业热点区块的位置数据点统计(加权密度聚类提取)
(三)仿真效果对比分析
通过对比仿真结果可以发现,加权DBSCAN算法提取的高热签到点的数目要多于传统DBSCAN算法,以签到次数作为权重系数的加权DBSCAN算法提取的商户网点的受欢迎热度更高。传统DBSCAN算法只是按照地理位置的距离远近判定网点是否归属聚类簇,无法识别出地处较为偏远的高热签到网点,可能会导致某些明显的高热点因为地理位置要素而被传统算法忽视。而加权DBSCAN算法由于考虑了非位置属性,可以避免高热点的遗漏。例如,表5中零售行业的关键区块3是没有出现在传统算法的提取结果表3中,但是区块3的数据点平均签到次数却高达2688,与地处目标城市中心的区块1的平均签到次数差不多。因此,加权DBSCAN算法可以提取更多的高热度的商户集群。
三、加权的空间数据挖掘对疫情监测的作用
(一)热点区块探知对疫情监测关键区域探知的支持
根据武汉市卫生健康委员会2020年5月28日发布的《武汉市新冠肺炎疫情动态(2020年5月27日)》数据,截止2020年5月27日24时,全市累计报告确诊病例50340例。其中武汉市中心城区内的江岸区6563例、江汉区5242例、硚口区6854例、汉阳区4691例、武昌区7551例、青山区2804例、洪山区4718例、东西湖区2478例。对比加权DBSCAN算法提取的热点区块空间位置分布情况,不管是在餐饮业还是零售业,最密集的高热区块正好覆盖了武汉市主城区内确诊病例数最多的四个行政区,即江岸区、江汉区、硚口区和武昌区。因此,对空间数据挖掘来探知行业热点区块,能准确发现疫情可能爆发或具有高传播性的关键区域,支持相关部门疫情防控工作的开展。
(二)多属性加权聚类分析对疫情监测科学性的支持
一旦感染区域分布与疫情实际传播情况存在偏差,就有可能严重影响疫情防控工作的顺利开展,甚至会造成人民生命财产的重大损失。因此,要保障城市应对重大疫情的疫情监测工作常态化的顺利开展,全面考虑空间数据的多个维度才能最大程度准确获取疫情可能爆发的重点区域或感染区域的空间分布。加权DBSCAN算法提取的热点区块和高热点是综合了空间数据的地理位置坐标属性和签到次数,考虑了重要的非空间位置属性可能对判定位置点的分类归属的影响,使提取的关键区块的空间分布模式更科学合理,避免了对某些距离相对较为分散的关键高热点的遗漏。
(三)基于数据驱动知识发现对疫情监测大数据特性的支持
疫情监测工作需要获取感染区域、规模、密度、时空分布和流动情况,发现疫情可能爆发的区域位置。这种空间分布模式的探究需要对数据实时处理,而不是事后的问卷调查和统计分析。疫情监测的原始空间数据来源多样、数据体积巨大、数据量增长速度快速,具有典型的大数据特征。聚类分析属于以数据驱动知识发现的第四研究范式,相比较传统的实证研究、统计分析以及问卷调查等研究方法,直接聚类提取知识的研究方法更适合于具有大数据特征的空间数据挖掘分析。
四、结论
要保障城市疫情监测的常态化,提高城市对公共卫生突发事件的应对能力,就必须探索对多维的、大体量的空间数据的高效处理方法,挖掘疫情传播的空间分布模式,发现并预测疫情可能爆发的重点区域。空间数据挖掘能够科学探知城市疫情防控关键区块或关键点,能够合理指导疫情防控重点区域的工作部署,还能够应对未来海量的疫情监测大数据的处理和分析。通过对空间位置数据的直接加权聚类提取,可以发现空间数据的某些属性与疫情爆发和传播的空间分布模式的必然关系,为城市疫情监测常态化工作实施提供重要科学依据。
