“There be”存在句there功能计量研究
2022-01-09徐晓琼李炳蔚
徐晓琼 李炳蔚
(湖南农业大学,湖南 长沙410125)
“There be”存在句中there的功能一直以来是各个语言学派研究的热点。传统语法将存在句中的there称作“预备there”,或“先行there”并同“先行it”相提并论。结构语法认为there充当“临时主语”[1]。认知语言学则认为There起一个触发语的作用[2]。而功能语言学认为there有指示功能和引导存在句的功能,起指示功能时there重读,引导存在句的时候弱读[3]。同时功能语言学还认为“There be”存在句中there位于句首的功能就只是为了提供一个话题,站在信息传递的角度,其实就是将信息焦点置于句末,所以“There be”结构就是一种信息整合结构[4]。与之相补充的有,徐盛恒[5]认为There是零位信息,它的作用就是引出另一个新信息。另外夸克(Quirk)[6]等人认为,在言语交际的过程中,人们在一般情况下不习惯用新信息来开头,因此there的功能就是给交际双方提供一个起点,从而引发新信息。
本文与功能语言学同样认为there是零位信息起引出新信息的作用,但与之不同的是本文基于信息论通过直观的数据定性定量相结合来分析there的功能。信息论是专门研究信息的有效处理和可靠传输规律的科学。近年来,基于信息论的语言学研究有:徐先蓬等[7]在信息论的视角下用信息量衡量了《红楼梦》和《神雕侠侣》中动介兼类词语法化程度,张南薰[8]用冗余度的计算公式测算了日语对外网络新闻翻译中冗余度的变化规律,王泓等[9]用信息熵②来反映文本的词汇丰富程度,这些研究都给语言学的研究给予了数据支撑并且带来了新的研究思路。受到以上研究思路的启示,本文将在信息论的视角下研究there的功能。
一、There的信息量、冗余度分析
(一)信息量
信息论创始人香农(Shannon)[10]提出“信息是用来消除随机不确定性的东西”,因此信息量就是通过信息消除不确定性的程度。“太阳从东方升起了”这条信息并没有减少不确定性。因为太阳从东边升起是客观事实,所以这句话没有意义,即信息量为0。“吐鲁番下雨了”(吐鲁番年平均降水量日仅6天)这条信息比较有价值,因为按统计的概率吐鲁番明天不下雨的概率高达98%,吐鲁番下不下雨这个事件是随机且不确定的,因此这条信息把发生概率为98%的事件——非常大概率的事情(不下雨)否定了,即在很大程度上消除了不确定性,因此它的信息量非常大。这条信息事件发生的概率仅仅是2%但是它的信息量却非常大,太阳从东方升起的这个事件发生概率很大,但是它的信息量却非常小。从上面两例得出以下结论:事件发生的概率和信息量的大小成反比。
(二)信息量计算

此公式p(x)是表示事件出现的概率,公式(1)log前的负号表示事件发生的概率和信息量的大小成反比。
本研究选取的单词和句子全部来自British National Corpus(BNC)英国国家语料库。并依据BNC语料库发布的一亿词词频表(前5 000词),计算每一个单词的信息量[11]。
为了把每一个单词出现的概率用频率来替代,在这里引入贝努利大数定律。贝努利大数定律说明了当试验次数非常大的时候,事件发生的频率可以近似地当成事件发生的概率。假设N(A)表示事件A在N次独立重复事件中发生的频数,p表示事件A发生的概率,对任意的ε有:
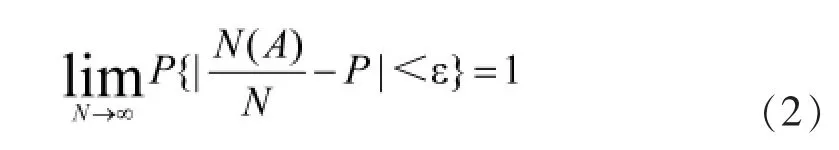
N(A)/N表示的就是事件A发生的频率,当N的数量足够大的时候,频率和概率的差值小于一个极小的数的概率趋近于1。这意味着此时可以将频率近似地当作概率。对于整个语料库,单词的总数相对于每个单词出现的频率,是极大的。因此可以把语料库的单词数量近似地当作是无穷大,根据贝努利大数定律式(2),在计算每一个单词出现的概率时,只要得出单词的频率,就可以把单词出现的频率当作是概率,带入信息量的计算公式进行计算,即可得到每个单词的信息量。如there在一亿词中出现频率是239 460次,频率约为0.24%,因此带入公式(1)=-log20.24%,得出there信息量约为8.75bit.
韩礼德(Halliday)[12]认为非重读的there和be动词构成的小句结构都是存在句,所以在BNC语料库中,there分为表示存在意义的非重读there和具有指示功能的重读there。本研究从BNC语料库中随机抽取100条关键词为there的语句,统计发现表示存在意义的there约占70.8%,指示功能的约占30.2%,分别估算出信息量约为9.23bit、10.41bit。所以本研究的There表示为存在意义的信息量约为9.23bit,即在一个语料中如果是表示一个存在意义的There出现,它需要消除不确定性的程度大概为9.23bit。所以“There be”句型句首there为信息量相对较小的一个词(见表1),由它来引导存在句减小了受者的理解负担,为引入信息量大的NP做铺垫。表1是来自BNC语料库出现频率前5 000的部分单词的词频表,信息量根据公式(1)计算得出。

表1 BNC语料库中部分序数前5 000词频率与其信息量
(三)冗余度
冗余信息指超出受者需求量的那一部分信息。站在受者的角度看,冗余度就是对信息有序向和确定性的一种可预见程度的计量,信息量与冗余度成反比[13]。冗余信息起的作用就是把高信息量进行缓冲,高信息量的信息往往是“曲高和寡”,它会使受者感到与之前的经验不符合从而产生一种疏远的感情,使传递的难度增高。冗余信息可以让信息源头保持新鲜感和熟悉感,而且能够把人们对新鲜信息的注意唤醒,还可以消除不确定性。因此,信息的冗余度就是受者对信息的确定性和有序性的可遇见程度的一种比例。比如当我们在向某人传达一种与他预期不符或者相反的信息时,在引出正式的消息之前,我们总会先说一些与之不相关的话,比如说如“我现在要告诉你一件事……”这些话其实不是废话,而是冗余信息,它能把高信息量信息对接受者的刺激性冲淡,从而减轻受者的理解负担。
信息冗余度的作用是:抗干扰,克服信息传递中的噪音。例如嘈杂的环境或同音的词语等,这些都会干扰信息的传递,从而造成信息损耗。如果要把这些干扰克服,必须要重复一遍或者解释关键信息,从而使信息的冗余度增加。例如,在介绍姓氏时通常说“我姓李,木子李”。因为“lǐ”音有很多同音字,为了使这种同音干扰降低,就有必要把信息的冗余度增加,减少噪音,来确保信息畅通[14]。
唐玉柱[15]认为在有地点状语词组出现时,there和该地点状语词组共指一个方位,所以there符合冗余信息的特征,可以视做一种冗余信息。因此本研究将从BNC语料库中抽取常见的18个方位介词构成结构b的语句(每个介词的语句总量见表2),把结构b转换成结构a,分成两个不同的文本:结构a为文本a,结构b为文本b,如介词on引导的结构b抽取了62句,这62句构成文本b,把结构b转换成结构a的文本则构成文本a。分别计算出每一个介词的结构a文本冗余度(R a)和结构b文本冗余度(R b),然后进行对比分析。
(四)冗余度计算
a.给定一个文本总词数为N,假设每个词仅出现一次,互不重复,则文本不确定性最大,该文本的最大信息量H0为:

b.但实际文本中不同词总数为n,某些词会重复出现,降低了不确定性。因此,文本信息量H∞需要将每个不重复的词的信息量进行综合计算:

通过以上公式(3)(4)(5),分别计算出R a和R b,其数据见表2。为具体说明冗余度的计算过程,笔者选取方位介词in的R a和R b进行演算。
第一步,把介词in引导的结构b文本输入到语料库检索软件AntConc中,并用它统计文本的N和n,得到N=19,n=12。然后用AntConc统计每个词的词频,例如“the”出现频率为3次,“and”2次,“in”一次。
第二步,按照公式(3)计算结构a最大信息量H0=log219≈4.25bit;
第四步,基于公式(5)得出R a=1-3.47/4.25≈18.35%。
同理可得R b≈13.75%。
如表2是18个常见方位介词引导的结构b文本的冗余度R b,和转换后的结构a文本的冗余度R a的统计表(此表的R a、R b全部由excel计算得出)。

表2 18个常见方位介词的R a、R b统计
从表2中发现,R a全部大于R b,说明结构b转换成结构a时,there的加入可以使存在句的冗余度增加,有效地降低了受者在理解存在句时的噪音。
二、AP2+VP2+NP2结构分析
英语的第一种存在句就是表示存在时经常用到的“There be”句型,另一种存在句就是常规句式NP2+VP2+AP2的倒装句式AP2+VP2+NP2。顾阳[16]把Under the roof is an old man类似的方位倒装结构视作存在结构,是因为这个结构跟汉语的存在句结构是一样的,语序上是一样的。使用倒装句式的前提条件是AP2一定是旧信息,NP2一定是新信息。从认知角度上来看倒装句式AP2+VP2+NP2,它遵循了大脑处理信息的规律:先旧信息后新信息。AP2是旧信息,所以它在句子线性位置上应当处于前位;NP2是新信息,所以它在句子线性位置上应当处于后位。通过处于前位的AP2使受者在大脑中激活并建立信息连接点或背景,这是为新信息NP2的引进而创造条件[17]。
(一)结构b在语料库中的分布
AP2作为地点状语时位于结构b句首时,引导的介词的信息量、观察频数、已知信息频数、语体分布如表3:此表全部语料来自BNC语料库,已知信息通过人工校对得出。信息量冗余度根据公式(1)(5)计算得出。根据BNC语料库中的数据,人工校对得出结构b在口语、学术、小说三个文体中的分布。
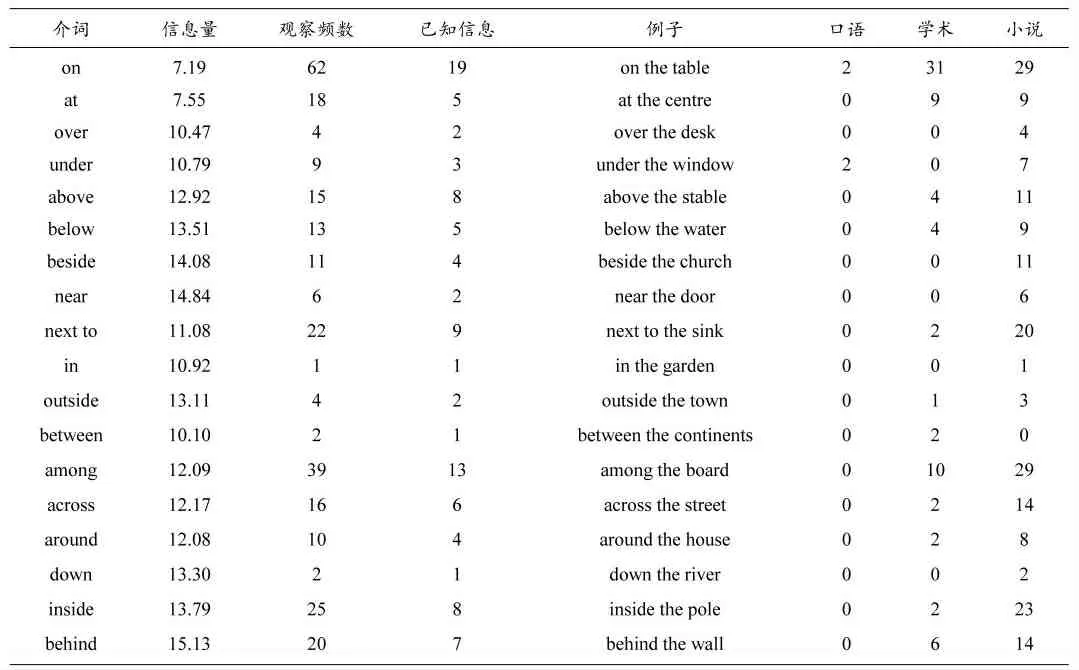
表3 引导结构b的介词及其信息量、已知信息、文体分布
表3中共观察18个介词引导结构b的存在句,在BNC语料库中一共观察结构b的语句279条。结构b在书面语体、学术文体和小说中的出现频率处于高位,279条语句中只有4条出现在口语中,频率很低仅为1.4%。
(二)结构a与结构b对比分析
徐盛恒认为信息单位有五种基本的信息类型:零位信息、已知信息、相关信息、混合信息、新信息。
零位信息:起引导作用的信息,如“There be”存在句中的There就是零位信息,它在句子中起引导信息的作用。
已知信息:指在当前的事件中,一些行为、事物、状态等已经在上文中提到过的信息,但是它们在这个发生的事件中没有新涉及。
相关信息:受者经过逻辑运算由已知信息推知的信息。
新信息:当前的事件指作信息状态分析的语句所提及的事件,在这一事件中新涉及的新主客体或新提到的行为、事物、状态都是新信息。
混合信息:一个语句过长包括了若干个信息内容单位,在其中有部分单位可能是不同的信息状态,它们混合在一起,成为已知信息和新信息混在一起的混合信息。
这五种信息类型表现信息状态时可能不同。这些信息状态根据其已知性(giveness)和新信息性(newness)程度的不同,可排成如下的梯度(零位信息不考虑其已知性程度)):
零位信息<已知信息<相关信息<混合信息<新信息
结构b引导的存在句地点状语AP由已知信息和相关信息组成,如例句1a),2a):
1a)He sat at the kitchen table.On the table was that day’s newspaper,and the previous day’s,neither unfolded.
例句1a)中的第二个小句中的地点状语On the table,table在前句中已经提到过并不是新信息而是已知信息。
2a)Before her was a narrow ledge,scarcely more than a metre wide.On the left was the overhanging face of the cliff,beneath which it would be impossible to stand upright.
例句2a)中第二个小句中的地点状语On the left,是由前句的地点名称ledge推知出来的。本研究所有结构b的语句都从BNC语料库中筛选得出,句首的地点状语由已知信息和相关信息组成(其中已知信息为100条,相关信息为179条)。结构a中There位于句首,there属于信息量比较小的词,被称为零位信息(徐盛恒),它在信息结构中的作用,是引导出另一个信息;它自身没有多大的信息量,但由于它的指引,人们注意到一个即将来临的信息的出现。
结构b的句首是地点状语,为已知信息和相关信息。和结构a的零位信息There位于句首处于句首的作用有相同之处:两种存在句都是以信息量小的词开始来引入后面大信息量的NP。但是经过人工校对,发现结构b中有64.2%的地点状语是相关信息,信息量大于there。因为结构b的句首为地点状语,地点名词为已知信息或相关信息,所以应把there的信息量与引导AP携带方位信息的介词的信息量相比较。there的信息量是9.23bit,根据表(3)结构b中18个介词只有on、at两个介词的信息量小于there,其他16个介词的信息量大于或远大于there,并且根据表(2)由于there的加入,使存在句的冗余度增加。说明结构a相对于结构b的优势是,第一:句首为信息量较小的词there,从而方便引出后面信息量大的NP(NP一般为新信息),这样的语序适合受者理解。第二:there加入使存在句的冗余度增大降低了噪音,并且there作为一个冗余信息位于句首起一个缓冲的作用,就如在和受者说话的时候一般,在引入一个新信息的时候,通常先会说:“你听我说,……”there的作用和“你听我说”一样起一个缓冲的作用,让受者更容易理解。虽然结构b遵循了从旧信息到新信息的认知规律[18],但是地点状语AP通常较长并且信息量大,位于句首不符合大脑加工、组织信息时的另一个规律:由简单到复杂。为了解决这个问题There出场取代了地点状语AP。There指代处所与表示处所的AP在语义上和句法功能上的作用相同,并且形式简短正适合这个位置,可用来代替AP指称处所。
信息学的原理其实也蕴含在语言的经济原则中。在接受者可以理解的基础上,信息的发出者总是希望用越少的语言符号来表述越多的意义。交际双方共同追求、互动的结果其实就是这种经济原则。一方面是在不影响消息内容的同时希望减少语言符号的个数,另一方面则是尽量让双方都熟悉的词用在更多语境中,从而使这些词获得习惯的用法。虽然结构a比结构b多一个符号there,似乎违背了语言的经济原则,但是因为there的信息量比较小,因此结构a看似多余的符号there位于句首的功能即为减轻受者的理解负担。
三、“There be”存在句问卷调查研究的设计
(一)研究对象
本研究的对象分为两组,第一组随机抽取了某大学英语专业的研究生,共38人。第二组随机抽取了居于长沙的英美等国家的母语者共30人,这些母语者在长沙的学校或教育机构任外教并且都受过高等教育。
(二)研究问题
本研究拟通过问卷调查,选择题和填空相结合的形式,通过网络平台发送,一共发放75份收回68份[19]。归纳出母语者和二语习得者在选用“There be”存在句时的偏好,以及文体的选择。
因为结构b存在句的结构与汉语存在句的结构相同且语序上也相同,所以二语习得被试者将会受汉语的影响,从而导致结果偏差。因此本研究主要参考母语被试者的数据结果。
具体研究问题如下:
为了获得更多的数据使研究更具说服力,本研究分别设置了三个都是表示存在的图片,图1桌上有一个苹果、图2水里有一尾鱼在游、图3花园里有很多花,三个图分别对应选择题1、2、3。受试者根据图片从表示存在的结构a和结构b选择对应的描述。这三个图片所对应的问题用来分析受试者在表达存在时所用句型的偏好。

图1 桌上有一个苹果

图2 水里有一尾鱼在游

图3 花园里有很多花
填空题4:选择的原因是什么?
选择题5:在什么情况下选择用结构a句型,口语?写作?口语和写作?
选择题6:在什么情况下选择用结构b句型,口语?写作?口语和写作?
(三)研究工具
本研究主要以定量研究为主,英语专业研究生为A组对照组,母语者为B组实验组。主要研究工具:网络调查问卷,SPSS26软件等。
(四)研究过程
将问卷链接发送给英语专业研究生共38人,母语者共30人,匿名作答后收回。调查问卷旨在分析受试者在选用“There be”存在句的偏好以及文体的分布。
(五)研究结果分析
图4、图5表示对照组A组的调查结果:二语习得者在选择题1、2、3中选择结构a的频率分别是92.11%、84.21%、89.47%。他们在文体选择题5和6中,口语选择结构a为5.26%,写作选结构a为28.95%,口语和写作为65.79%,结构b分别为60.53%、23.68%、15.79%。
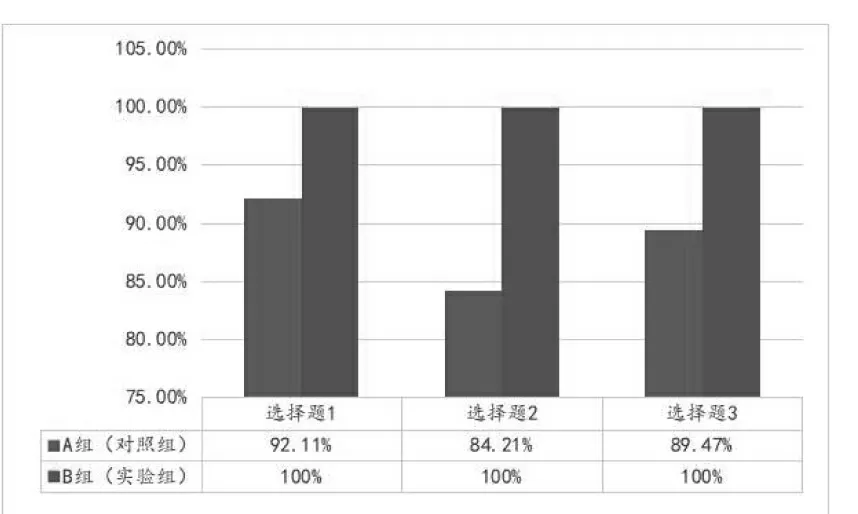
图4 选择题1、2、3调查结果

图5 A组、B组文体调查结果
实验组B组的调查结果:母语者在选择题1、2、3中选择结构a的频率都是100%。他们在文体选择题5和6中,口语选择结构a为0%,写作选结构a为0%,口语和写作为100%,结构b分别为0%、86.67%、13.33%。
本文用SPSS软件对两组调查结果数据进行独立样本t检验,从而分析两组调查结果数据之间的差异性,表4是对照组A组与实验组B组调查结果之间进行检验的结果。A、B两组在选择题上显著性P>0.05,说明A、B两组选择题的调查结果之间不具有显著性。A、B两组结构a和结构b的文体分布调查结果之间的显著性都小于0.05(P<0.05),说明A、B两组结构a和结构b文体分布调查结果之间都具有显著性。

表4 A组与B组调查结果之间显著性分析
在填空题4中,A组:94%的二语习得者选择结构a的原因是习惯的表达,3%的原因是容易理解,剩余3%的原因是固定的搭配。B组:38%的母语者选择结构a的原因是简单的表达,17%的原因是容易理解,22%的原因是更好的表达,23%的原因是通常的用法。
观察选择题1、2、3调查结果,发现A组选择结构a来描述图片的频率比较高,说明在表达存在时,二语习得者偏向于使用结构a。而B组母语者则完全偏向使用结构a,频率高达100%。选择题1、2、3和填空题4的调查结果佐证了结构a相对结构b更加简单。
在选择题1、2、3中,两组的选择比较相近,但在文体选择中两组之间有比较大的出入。A组中,二语习得者只在口语中选择使用结构a的频率为5.26%,只在写作中选结构a是28.95%,在写作和口语中都用的频率是65.79%。选择结构b的频率分别为60.53%、23.68%、15.79%。在二语习得者中,60.53%只在口语中使用结构b来表达存在,原因可能是结构b更接近中文存在句的语序。
在B组中所有母语者在口语中和写作中都会用到结构a的句型。86.67%的母语者只在写作中使用结构b的句型,说明母语者在使用存在句时,绝大部分人只在写作中考虑使用结构b这种句型来表达存在。只有13.33%的母语者考虑在口语中或写作中使用结构b来表达存在。说明结构b这种句型,绝大多数母语者只在写作中使用,契合了结构b在BNC语料库中的文体分布。
四、结论
本研究介绍了信息量和冗余度的概念,借助了它们两个作为数据指标,阐述了在“there be”存在句中there的功能和位于句首的原因以及优势,并用问卷调查加以佐证。
本研究发现:a.由于存在句一般是引出新信息,新信息的信息量比较大。结构a there位于句首信息量比结构b的位于句首的介词信息量要小,符合大脑加工、组织信息时的一个规律:由简单到复杂。所以there位于句首的功能就是利于受者理解。b.“there be”结构是一种冗余结构,there使存在句的冗余度增大有效地降低了受者在理解存在句时的噪音,并且there是冗余信息位于句首能冲淡高信息量NP1对受者的影响,使理解难度降低。c.在BNC语料库中,绝大部分结构b只出现在书面文体,并且通过问卷调查佐证了,大多数母语者也在只有写作中偏向使用结构b。
主语从句、强调句等句首it的功能是否和“there be”存在句句首there的功能相同将在之后的研究中探究。
注释:
①本文主要研究There+VP1+NP1+AP1(结构a)与同义结构AP2+VP2+NP2(结构b)这两种结构,VP1和VP2仅指be动词。
②信息量度量的是一个具体事件发生所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。
