实现宏单元高质量自动摆放的约束
2022-01-09陈力颖陈旭洲刘宏伟
陈力颖,陈旭洲,李 勇,刘宏伟
(1.天津工业大学电子与信息工程学院,天津 300387;2.天津工业大学天津市光电检测技术与系统重点实验室,天津 300387;3.台州国晶智芯科技有限公司,浙江台州 318014)
随着现在芯片工艺技术的飞速发展,单一芯片所包含模块越来越多,设计复杂性也大大增加[1]。布图规划(Floorplan)在大规模芯片设计中起着至关重要的作用,芯片所包含的模块越多,Floorplan 的重要性就越能得到体现,所以确定各个宏单元(Macro)在芯片上的位置就成为Floorplan 的首要任务。Macro 的位置决定着芯片的可利用面积、布线空间和模块间通信距离,进而影响芯片的性能、良品率和可靠性[2],但是在芯片设计自动化的大背景下,这项工作仍然由人工进行。工程师在Macro 放置过程中需要综合多种因素,不断尝试迭代得出最优方案。这项工作不仅耗时巨大,且计算量巨大,无法得出最优方案。各大电子设计自动化(EDA)工具厂商也提出相应的解决方案,但是由于没有优秀的约束而很少被使用[3]。
为解决人工放置Macro 出现的结果不理想问题,本文以Innovus 软件的超级命令PlanDesign 为基础,共设计2 种约束方案:方案1 为基于Module 约束的Macro 摆放,首要考虑标准单元与Macro 的连接情况;方案2 为基于Macro 约束的Macro 摆放,首要考虑Macro 摆放形状。
为验证2 种约束方案的好坏,与已经流片的布图规划在标准单元摆放(Place)后的时序情况、时间、功耗、时钟树关键节点分布进行对比。其中芯片包含144个Macro,约1 500 万门,芯片面积约为5 mm×5 mm。
1 宏单元的自动摆放
1.1 宏单元放置规则
对于绝大多数设计,Macro 的摆放规则基本相同[4]。Macro 尽可能摆放在与之通信的输入输出口(I/O)的位置附近[5]。通常对于关键Macro,它们不仅面积较大,还需要与其他Macro 进行数据交换,与标准单元进行数据交换或通过I/O 与芯片外的各种器件进行通讯[6-7]。因此摆放在相应数据端口附近,有利于减小互连线长度,减少线上延时,并且节约布线资源[8]。大型Macro靠近core 的边缘和角落放置也有利于提升芯片利用率。
为了保证有足够的布线空间,Macro 与Macro 之间要留有一定空隙,特别是在Macro 的空隙有端口的时候更是如此[9-10]。通常,需要通过相邻Marco 边界上端口的多少来决定留有多大的空隙比较合适[11]。Macro与Macro 之间的空隙要使用Soft Placement Blockage 进行覆盖。Macro 空隙示意如图1 所示。对于一般设计,线长超过200 nm 就可能出现transition 违例;对于横跨Macro 的互连线来说,如果Macro 之间留出空隙就可以在空隙中插入Buffer 来修正违例。Soft Placement Blockage 可以防止标准单元将空隙完全填充,为Buffer插入留出空间。
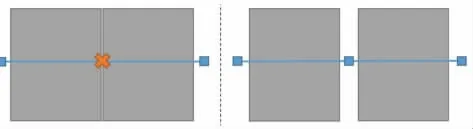
图1 Macro 空隙示意图Fig.1 Diagram of macro void
对Macro 进行适当的翻转以保证Macro 摆放在合适的角度[12]。在考量Macro 摆放的角度时,不仅仅考虑空间摆放的因素,还要根据端口的连接关系与互连模块的位置来决定[13]。存储模块的端口方向尽可能朝向芯片内部,因为中间的标准单元需要与存储模块进行数据交换,存在互连关系。在实际设计时,不仅要根据端口与标准单元之间的连接关系,还要考虑Macro 与Macro 之间的互连关系进行综合判断[14]。
1.2 PlanDesign 流程
PlanDesign 是Innovus 专门为Macro 摆放自动化设计的超级命令,可以根据所给的约束条件自动摆放Macro[15]。命令可分为基于Module 和基于Macro 的2 种摆放模式,不同的模式下所得到的结果不同,但都会综合如线长、面积等因素经过大量计算得出最优结果。
但是单独使用PlanDesign 命令所得到的结果并不理想[16]。在使用PlanDesign 命令之前,需要对工具人为设置一些约束。约束的核心是种子(seed),在设计中一般选取关键器件作为种子,让PlanDesign 按照选取的种子去摆放Macro。种子的选取可以为Hard Macro,也可以为Hierarchical Modules。选取种子之后,需要在种子上施加约束。可施加的约束包含Module 的长宽比、Module 的利用率、Macro 与Macro 之间的最小间距等。工具会综合种子的选择、种子上的约束还有其他Floorplan 约束进行摆放。
对于大量Macro,工具会使用一种特殊的摆放引擎Mix Placer 来确定Module 的位置。Mix Placer 会使用很短的时间粗略地摆放一遍Macro 和标准单元,工具基于这个粗略的摆放结果来确定Module 位置,然后采用虚拟墙(Virtual Wall)把Module 推向芯片边界,再重新细致得去摆放Macro。因为考虑到了标准单元的分布,所以通常来说结果会更好[17-18]。图2 为PlanDesign工作流程。
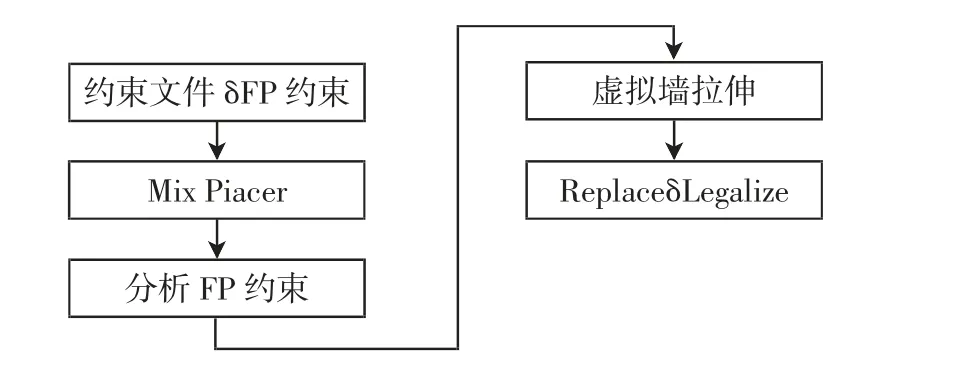
图2 PlanDesign 工作流程Fig.2 Workflow of PlanDesign
2 自动摆放约束条件
设计芯片为正方形,包含2 个模拟单元:PLL 与RTC。先将模拟单元固定并且用CutRow 对其进行隔离,之后指定I/O 单元的位置。由于时钟树综合需要,将关键Module 放置在指定区域并且设置为region。完成后的Floorplan 如图3 所示,并在此基础上进行实验。

图3 完成后的FloorplanFig.3 Floorplan after completion
2.1 基于Module 的约束条件
根据设计要求,Macro 与Macro 之间必须留有15~20 μm 的间距(不包含halo)。首先需要在约束文件外进行setPlanDesignMode 设置,来规定Macro 之间、Macro 边界之间的距离和工具运行状态。
以下为setPlanDesignMode 设置命令:

基于Module 的约束要尽可能将所有非人为干预的Module 设置为种子。工具会依据逻辑连接关系将与Module 连接的一组Macro 摆放在一起。但是工具并不会考虑Macro 的摆放位置。经过反复实验,得到如下最佳约束效果。
约束1:理论上Macro 摆放在core 的四周,中间尽可能的形成方形区域有利于绕线,由于芯片长宽比为1∶1,所以设置Module 长宽比为1∶1,使工具尽可能地为中心留出方形区域。约束2:将摆放后的关键Module设置为fence,但是由于有些单元需要横跨很长的区域进行连接,所以其余非关键Module 不设置任何约束。约束3:关键Module 的利用率设置为70%左右,为了使标准单元更为密集,需要高于Floorplan 利用率。由于本设计Floorplan 利用率为70%,所以关键Module的利用率设置为75%。约束4:通过Module 与边界距离的设定可以强行将Module 推到芯片中央,使标准单元位置相对集中,有利于时序。
以下为一个关键Module 的约束条件:

根据以上约束摆放后的结果如图4 所示。由图4可以看到工具对Macro 进行了适当的翻转,且中心尽可能的留出了方形。虽然Macro 之间存在少量dead area,但是Macro 与Macro 之间、Macro 与标准单元之间通信距离更短,更有利于芯片时序收敛。

图4 基于Module 的摆放结果Fig.4 Placement results based on Module
2.2 基于Macro 的约束条件
使用Macro 作为种子时,可以设定Macro 的方向、上下左右的间距等,可人为进行干预的条件不多。但是经过实验发现,由于Macro 的大小、形状不同,所以种子选取时,不同形状的Macro 至少需要一个作为种子。并且将关键的Macro 不作为种子的选择,需要手动放置在合适位置并设置为Fix,并进行约束。
约束1:根据设计要求设置Macro 上下左右的间距值。约束2:设置Macro 方向,使出PIN 方向朝向芯片中心。约束3:设置Macro 到core 边界的最小距离。
以下为一个Macro 的约束条件:

基于Macro 的约束摆放结果如图5 所示。

图5 基于Macro 的摆放结果Fig.5 Placement results based on Macro
由图5 可知,手动微调后可以看出Macro 摆放相较于基于Module 的约束要更加整齐,但是连接关系不如前者。
3 结果对比
将2 种约束摆放后的Floorplan 与已经流片测试成功的Floorplan 进行对比。三者都进行相同的电源规划与电源绕线(PPPR)。芯片一共8 层,Macro 电源引脚位于M4 层,其中M6 层给Followpin 与竖向Macro供电,宽度10 μm,间距70 μm。M7 层给M6 层与横向Macro 供电,其余层数为绕线留出空间。
以下对通过标准单元摆放(Place)之后的setup的大小、时间、功耗以及时钟关键节点分布进行比较分析。
3.1 setup 检查结果与时间对比
Floorplan 的质量直接影响Place 之后的时序。3 种Floorplan 之后setup 检查结果如表1—表3 所示。

表1 原始setup 结果Tab.1 Original setup result

表2 Muduel 约束setup 结果Tab.2 Muduel constraint setup result
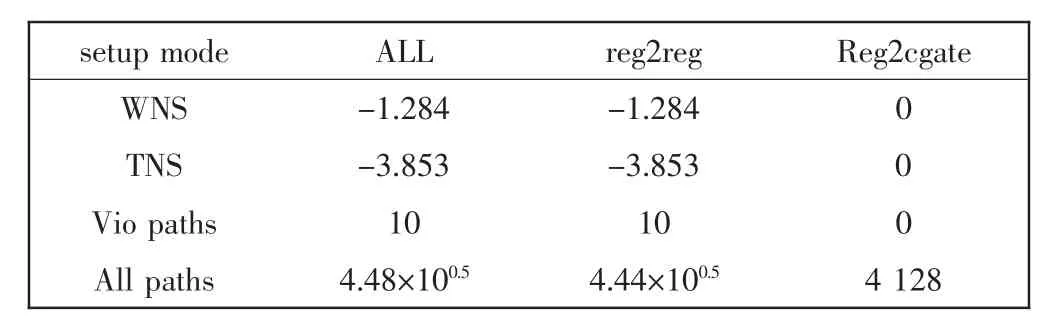
表3 Macro 约束setup 结果Tab.3 Macro constraint setup result
由表1—表3 可见,无论是基于Module 约束的Floorplan,还是基于Macro 约束的Floorplan,其setup结果均接近于原始结果。
原始Floorplan 是经过多日多次运行flow 迭代产生的,耗费大量时间。而另2 种自动摆放的Floorplan分别仅耗时30 min 和34 min。单纯对摆放时间对比,不考虑质量情况下,设计包含的144 个Macro,人为进行摆放至少需要2.5 h,可见时间消耗大约为自动摆放的5 倍80%。如果考虑迭代时间,则减少Floorplan 阶段的时间更加可观,这就为以后手动修改电路(ECO)工作留出足够的时间。
3.2 功耗对比
由于在自动摆放Macro 时充分考虑了逻辑单元的连接情况,所以相较于原始Floorplan 有连接关系的Macro 之间距离更近,Place 之后标准单元与标准单元更近,所以线长更短,工具修复前时序情况更好,更好的时序使得时序修复时低阈值电压的单元和所插入的Buffer 更少。表4 为功耗时比结果。由表4 可见,2种约束功耗分别为原始功耗的95%与96.7%。

表4 功耗对比Tab.4 Comparison of power consumption
3.3 时钟关键节点分布对比
Place 之后的时钟关键节点分布直接关系到时钟树的质量,进而影响到功耗与芯片性能。本文对比3种Floorplan 主时钟sink 的上一级节点,也就是sink扇出点的位置,结果如图6 所示。

图6 时钟节点对比Fig.6 Comparison of clock node
由图6 可见,原始Floorplan 与基于Macro 约束的Floorplan 主时钟分为2 组散开,而基于Module 约束的Floorplan 是汇聚成一组进行散开。对于时钟树综合基于Module 约束的Floorplan 要更好。这也体现出基于Module 的Floorplan 对逻辑连接性的考虑要更多。
4 结 论
(1)通过本文提出的约束条件自动摆放的Floorplan 与传统人工摆放的原始Floorplan 相比,时间节省约80%,如果考虑质量,时间节省更为明显。
(2)Place 之后的时序与原始Floorplan 的时序无恶化情况,功耗分别降低5%和3.3%;时钟节点分布与原始Floorplan 相同或更为密集。
