基于迁移学习的民航发动机小样本故障诊断
2022-01-07钟诗胜张永健
付 松,钟诗胜,林 琳,张永健
(哈尔滨工业大学 机电工程学院,黑龙江 哈尔滨 150001)
0 引言
作为一类高价值复杂装备,航空发动机的运行状态与飞机飞行的安全性息息相关。更重要的是,由于长期在高温、高压等恶劣环境下运行,航空发动机气路部件极易发生各种故障[1]。因此,必须对航空发动机进行有效的故障诊断,以确保其安全可靠地运行。作为航空发动机健康管理的一项关键技术,故障诊断利用监控得到的发动机气路参数实现对航空发动机的气路故障进行精确定位和诊断,不仅可以帮助工作人员及时快速地掌握发动机的工作状态,还能为发动机的维修时机预测、维修方案制定、维修成本预估提供有力的支持。
目前,航空发动机气路故障诊断方法大致可以分为基于模型的故障诊断方法和基于数据驱动的故障诊断方法2类[2]。基于模型的故障诊断方法需要建立发动机精确的物理数学模型来描述发动机的工作特性,如基于非线性最小二乘的故障诊断方法、基于卡尔曼滤波的故障诊断方法等[3-4]。然而,由于对导致发动机故障原因缺乏足够的领域知识,导致无法建立精确的物理数学模型,尤其是对航空发动机这类大型复杂设备而言,其先验知识更是十分匮乏,而且获取十分困难,导致基于模型的故障诊断方法在实际过程中往往不可用。此外,航空发动机在实际运维过程中受到大量随机因素的影响,导致花费大量资源建立的模型难以满足航空发动机的实际运维需求。
与基于模型的故障诊断方法相比,数据驱动的故障诊断方法直接从常规收集的历史运维数据中导出故障诊断模型,而不依赖任何领域知识,且计算过程简单,具有较强的泛化性[5-6]。同时,数据驱动故障诊断方法还可以实时更新,对机器的运行工况有很好的适应性。因此,基于数据驱动的故障诊断方法在工业领域得到了广泛应用和推广。近年来,随着深度学习的快速发展,深度学习能自动地从高维、冗余的复杂数据中提取出具有代表性的深度特征,使其成为了最主流的基于数据驱动的故障诊断方法之一。
基于深度学习的故障诊断方法主要利用深度神经网络学习输入数据的深度特征,然后对这些学习得到的深度特征进行分类。基于深度学习的故障诊断方法能够有效提高故障诊断精度,这归功于深度神经网络从大量的带标签的样本中学习到丰富的特征表示的能力[7-10]。然而,航空发动机属于高可靠性的工业产品,其发生故障的频率非常低,在实际飞行过程中故障案例较少。故障样本的缺乏导致直接利用深度神经网络对发动机进行故障分类不可行。
为了能够在小样本条件下,实现精确的航空发动机气路故障诊断,并获得较好的泛化性,受深度学习启发,本文基于航空发动机的真实运维数据,提出一种基于深度自动编码器(Deep Auto-Encoder,DAE)与支持向量机(Support Vector Machine,SVM)相结合的航空发动机小样本故障诊断方法。针对航空发动机实际故障样本少的问题,通过DAE迁移学习建立发动机状态特征提取模型,而后利用建立的发动机状态模型提取故障数据样本的特征,并利用SVM实现小样本分类;此外,为了使DAE模型能够提取出更优的深度特征,本文提出一种基于单个AE特征提取能力优化DAE隐藏层节点数的方法。
1 方法
如图1所示为本文提出的发动机气路故障诊断方法的原理图,主要包括两个过程:①利用基于DAE迁移学习建立发动机状态特征提取模型;②利用支持向量机对状态特征进行分类。在获得航空发动机的正常样本数据组和故障征候数据样本组后,本文以足够多的正常样本对DAE模型进行训练。待DAE模型训练完成,将其迁移到故障样本的特征提取任务中并保持不变,建立民航发动机状态特征映射模型。当提取当次发动机故障征候样本的深度特征时,将故障征候样本组作为所建立的发动机状态特征模型的输入,通过发动机状态特征提取模型得到的输出即为故障征候样本的深度特征。最后利用支持向量机对提取的特征进行分类。
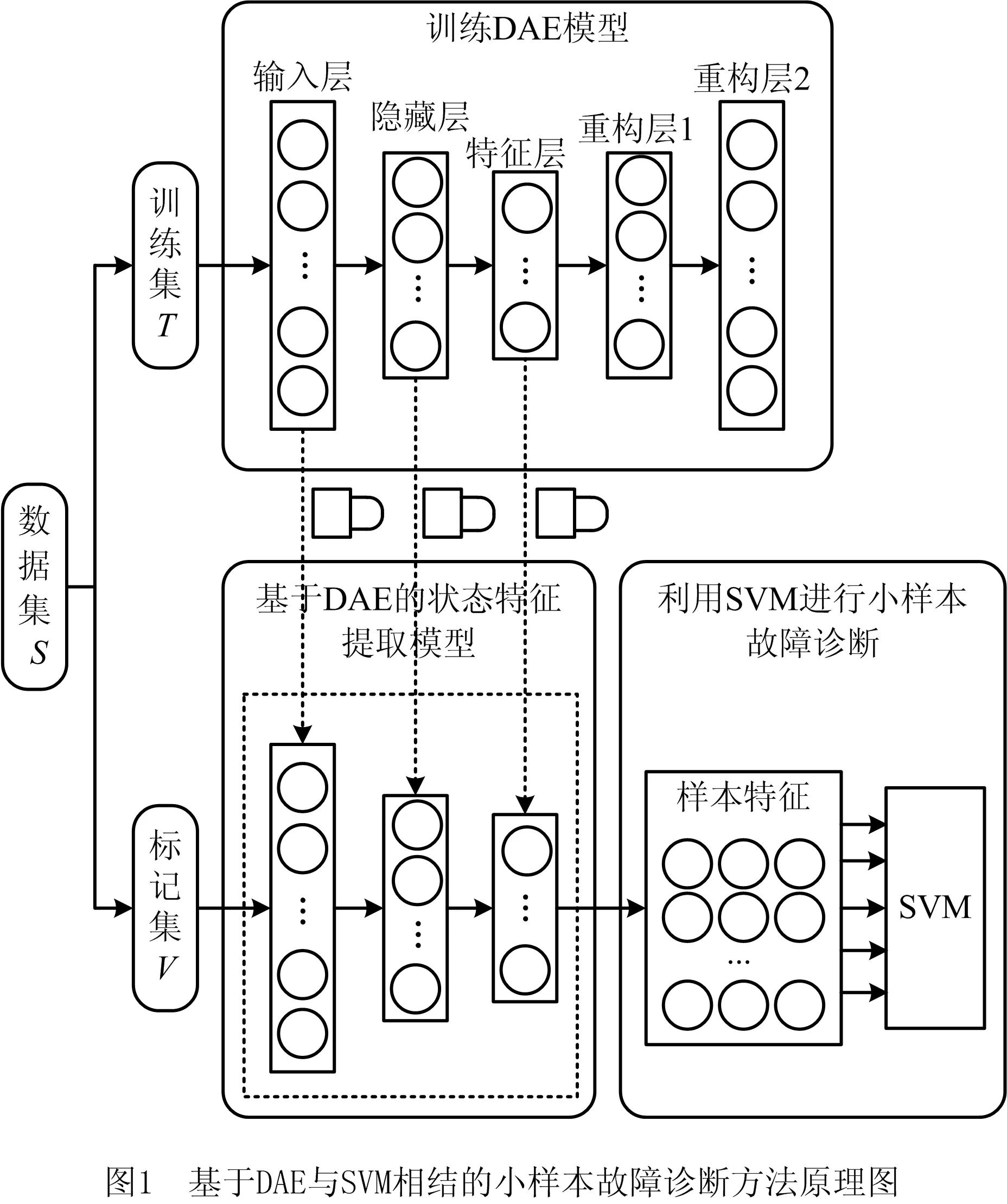
1.1 基于DAE迁移学习的发动机状态特征提取模型
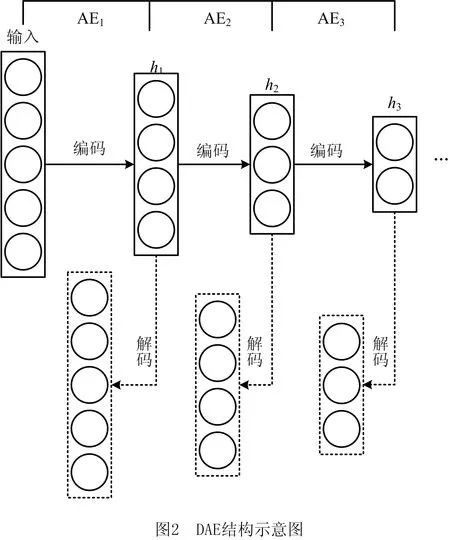
DAE[11]是Hinton于2006年提出的一种深度无监督学习算法,由浅层—自动偏码器(Auto-Encoder,AE)堆叠而成,如图2所示。每个AE[12]均由一个编码器和一个解码器组成,其结构如图3所示。很多文献对AE进行了详细的描述,AE的简要介绍如下:
(1)将输入向量x∈Rn通过编码器映射为隐藏表示h∈Rm,如式(1)所示:
h(x)=Sf(W·x+b)。
(1)
式中:W表示权重矩阵,b表示偏置向量,Sf表示非线性激活函数。
(2)将隐藏表示h∈Rm通过解码器重构原始输入向量,如式(2)所示:
z=Sg(W′·h+b′)。
(2)
式中:W′是权重矩阵,b′表示偏置向量,Sg表示非线性激活函数,z表示重构的输入数据。
(3)通过训练集D训练DAE以寻找最优参数θ={W,b;W′,b′},使得重构数据z和原始输入数据x的误差最小。
与AE相比,DAE具有更强的特征提取能力,能够提取出输入数据的深层特征。DAE训练方式为无监督逐层训练,即首先训练第一个AE,然后将第一个AE的隐层作为下一个AE的输入,训练第二个AE,依次直到所有AE训练完成。一旦DAE训练完成,最后一个AE隐藏层的输出即为输入数据的深度特征。

DAE能够有效提取输入样本的深度特征的前提是每种类别的训练样本足够多。然而,民航发动机在实际运行过程中故障样本较少而正常样本足够多,是典型的类不平衡。如果直接利用DAE进行特征提取,就会受到类不均衡的严重影响,导致无法有效提取故障样本的特征。最好的解决方法是增加每个故障类别的训练样本数,使网络学习到更具有鲁棒性和代表性的特征。显然,这种方法对于民航发动机真实运维数据是不可行的。
除了增加发动机故障样本外,迁移学习也是一个可行的用于提升人工智能辅助诊断性能的途径。迁移学习是一种解决问题的思想。它不局限于特定的算法或者模型,其目的是将源域中学习到的知识或训练好的模型应用到目标域[13]。因此,本文利用迁移学习来解决民航发动机故障诊断中面临的故障样本不足的问题。
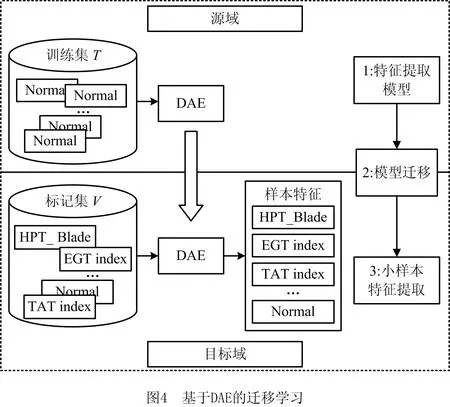
针对发动机正常样本足够多而故障样本较少的特点,本文使用的迁移学习思想是直接将在源域(这里是大量正常样本)中学习到的特征表示模型迁移到目标域(这里是少量的故障样本),如图4所示。具体地,首先,仅使用大量发动机正常样本构成的源域对DAE进行训练;然后,将训练完成的DAE模型迁移到由多种类型但每种类型的样本数较少的目标域中,并进行特征提取。最后,针对本文所关心的小样本分类问题,选用支持向量机进行分类。与其他分类器相比,SVM在小样本的条件下有较好的分类效果。
1.2 基于单个AE特征提取能力的DAE隐藏层节点数的确定方法
隐藏层和输出层神经元数是影响DAE特征学习能力的两个重要因素。然而,如何设计合适的神经元数使得DAE的特征学习性能达到最佳,一直是一个非常困难的问题。在当前的方法中基本上是通过大量的实验试探,根据实验结果来探寻最优的神经元数。为解决该问题,本文提出一种基于单个AE特征提取能力确定DAE隐藏层最优节点数的方法。由图2可知,DAE的核心就是通过堆叠多个AE的方式来挖掘原始数据中的深度特征。因此,可以认为在堆叠过程中每个AE特征提取能力越强,则最终所构建的DAE的特征提取能力就越强。本文将从单个AE的特征学习能力的角度来分析DAE的特征学习能力。
由图3可以看出,AE通过编码过程将输入样本信息压缩在隐层中,通过解码过程使隐藏层重构输入得到重构数据,而训练AE的目的是尽可能地使输入数据与输出数据相同。因此,AE特征学习能力主要取决于其能否有效地重构输入。重构误差越小,表明AE特征学习能力越强。为了合理地比较原始输入数据与重构数据之间的重构误差,本文将使用均方根误差(RMSE)和失真度(DD)来衡量它们的差异,其定义分别如下:

(3)
RMSE越小,表示重构数据与原始输入数据之间的差异越小,从而AE的特征提取能力越强。
(2)失真度根据文献[14]中的定义,本文采用相对均方差值定义失真度,具体如式(4)所示:
(4)
失真度S越小,表示重构数据与原始数据之间的差异越小,AE的特征提取能力越强。
根据上述方法,可以很好地比较不同隐藏层节点数下AE特征提取能力的好坏。而后本文将选取单个AE特征提取能力最好的隐藏层节点数作为DAE模型的隐藏层节点数。对于DAE模型的输出层节点数,根据DAE模型原理可知,DAE是由多个AE堆叠而成,DAE的输出层即为最后一个AE的隐藏层,可以利用同样的方法进行确定。综上,可以建立具有最优隐藏层和输出层神经元数的DAE模型。
2 发动机数据分析
2.1 OEM气路参数分析
原始设备制造商(Original Equipment Manufacturer, OEM)数据是OEM解算的一种偏差数据,通常用来监测航空发动机的性能状态。如图5所示为OEM返回给航空公司的客户通知报告(Customer Notification Report, CNR)。可以看出,OEM主要使用DEGT、DFF、DN2和EGTM四个气路性能参数对气路故障进行指征[15]。通常,EGTM被用来预测发动机的剩余寿命,而DEGT、DN2、DFF的变化趋势用来监控发动机的状态[16]。因此,本文也选取上述4个参数作为气路故障指征参数,以某CFM56-7B系列的航空发动机队为样本机队,并以其OEM数据为基础,建立民航发动机气路故障诊断模型。
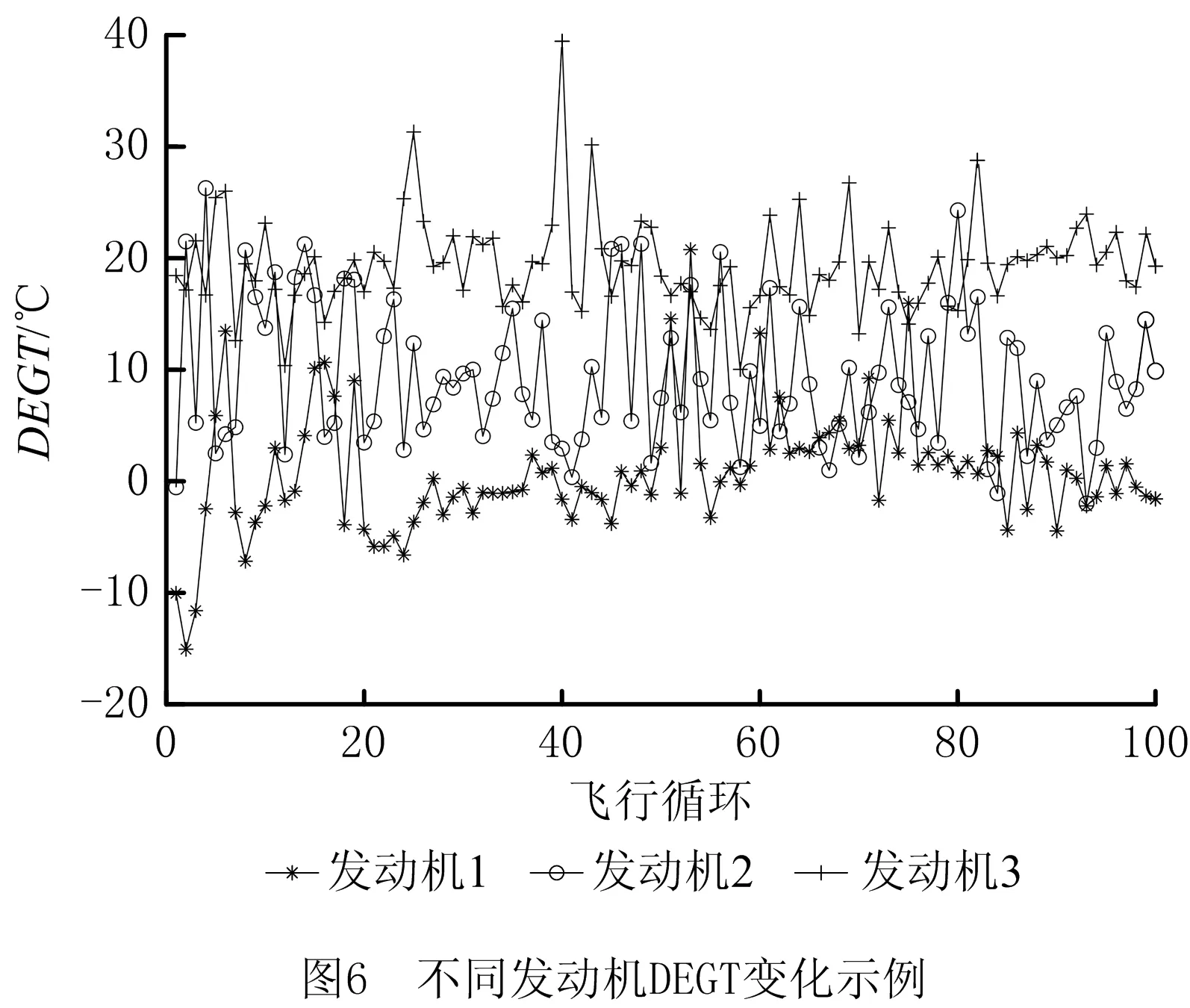
由于民航发动机工作环境复杂,导致测量并经过计算的性能参数存在大量随机噪声,这些噪声会对故障诊断造成一定影响。另一方面,民航发动机是典型的复杂机械设备,由多个单元体组成。由于单元体的制造误差、装配误差以及运行工况不同,导致每个发动机个体之间存在着较大的差异[17]。如图6所示为CFM56-7B系列的3台新发投入使用时最早100个循环中DEGT气路参数变化图,从图中可以看出,即使是型号相同、状态相似的发动机,其DEGT值的变化都有较大差异。因此,运用OEM数据建立发动机气路故障诊断模型时,必须消除噪声,弱化因个体差异对故障诊断造成的影响。
2.2 故障征候数据预处理
结合CNR对样本机队的实际运维数据进行分析,可以发现民航发动机在发生气路故障前的一段时间内其气路性能参数会出现明显的变化趋势。图7所示为某发动机被OEM厂家确诊为排气温度指示故障后,其气路性能参数DEGT在故障点前的300个连续飞行循环的数值变化趋势,其中T2为故障时刻,T1为报警时刻。通过对图中的变化趋势进行直线拟合,可以发现DEGT在T1时刻到T2时刻之间的变化趋势发生了明显的突变现象。通过对不同的气路性能参数进行类似的分析,当发动机出现不同气路故障类型时,其对应的气路性能参数会呈现明显的变化趋势。因此,本文将气路性能参数的这种变化趋势作为民航发动机的气路故障指征。具体气路故障征候数据的预处理过程如下:
假设民航发动机气路监控参数X={x1,x2,x3,…,xn},xi表示具体的监控性能参数,故障征候样本具体构造过程如下:
步骤1首先获取故障确认点前性能参数xi的m个连续飞行循环数据,如式(5)所示:
(5)
步骤2按照时间顺序,将每个性能参数m个采样数据进行分组,将离故障确认点最近的一组选为故障征候组,其余各组为正常组。
设Yi={ym,ym-1,…,y1}表示监控参数xi的m个连续飞行循环数据,如果每组r个飞行循环,则每个性能参数小偏差序列将会被分成k个子序列,

(6)
(7)
式中:Yi,2,…,Yi,k表示气路性能参数xn的正常数据组,Yi,1表示气路性能参数xi的故障征候数据组。
步骤3令Fj={Y1j,Y2j,…,Ynj},j=1,2,3,…,k,Yij表示性能参数xi分组后的第j组飞行数据。当且仅当j=1时,F1={Y11,Y21,…,Yn1}表示故障样本。
步骤4对不同的故障模式进行标记,假设有a1,a2,a3,…,an等n种故障模式,将所有正常样本标记为“0”,故障模式a1标记为“1”,故障模式a2标记为“2”……。
2.3 数据收集
分析OEM厂家的故障预报数据,其选取的故障征候循环数(图7中T1和T2时刻之间的飞行循环数)从5到130不等,且只有少数故障征候循环数超过10,因此,选取10个循环作为故障指征数据的区间段能够满足大部分的故障诊断需求。通过对样本机队的发动机维修报告和CNR分析整理,按照本文故障指征预处理方法,本文共获取了30组排气温度指示(EGT Indication)故障案例样本,22组进口总温指示(TAT Indication)故障案例样本、20组HPT叶片烧蚀(HPT_Blade)故障和3 268组正常样本,如表1所示。


表1 故障类别分布
3 实验结果及分析
本章将利用收集的实际发动机运维数据对本文提出的故障诊断方法进行验证,鉴于本文所收集的数据量,选择两个AE堆叠形成DAE模型。首先,通过1.2节所提出的方法对DAE模型的隐藏层神经元数和输出层神经元数进行优化。然后基于优化后的DAE模型和SVM进行故障诊断,并以分类正确率(Accuracy)和召回率(Recall)对故障诊断结果进行评价,计算公式如式(8)和式(9)所示:
(8)
(9)
式中:TP表示分类器将正常样本分类正确的数量,TN表示分类器将故障样本分类正确的数量,FN表示分类器将正常样本分类为故障样本的数量,FP表示分类器将故障样本分类为正常样本的数量。
本章所有实验中的相关算法均采用Python语言(3.6版本)以及谷歌开源的Tensor Flow(1.13.1版本)工具箱[*]进行编程实现,所采用的计算机平台配置为英特尔i5-6300型处理器。其中,Tensor Flow 是由美国谷歌公司所开发的基于张量流图的开源机器学习库,具有自动求解反向梯度以进行模型参数(权值和偏置)优化的功能,适用于深度学习算法的快速研发。同时,Tensor Flow 工具箱能够支持基于图像处理单元的大规模快速矩阵运算,极大地缩短了AE和DAE算法所需要的训练时间。
3.1 DAE隐藏层节点数的确定
AE的输入层节点数由输入数据的维数决定,本实验中输入数据的维数为40,因此将AE的输入层节点数设为40。为了充分分析不同隐藏层神经元数下AE的特征学习能力,依次将隐层节点数设为10~200(以10为间隔)进行实验。然后,利用提出的两个评价指标DD和RMSE对AE的特征学习能力进行评估。为了在同一标准下进行比较,当研究隐藏层节点数对AE特征提取能力的影响时,保证其他参数不变。关于AE的相关参数设置:学习率设为0.001,迭代次数设为300,节点激活函数使用softplus函数。算法1描述了获取不同隐藏层节点数下AE的DD和RMSE具体过程。
算法1获取不同隐藏层节点下AE的DD和RMSE。
2: 输出:重构误差集R和失真度集D
3: 输入层inputLayer←(输入层神经元节点数n_nodes=n)
4: 隐藏层(编码)encoderLayer←Dense(神经元节点数n_nodes=t,激活函数=softplus)(inputLayer)
5: 输出层(解码)decoderLayer←Dense(神经元节点数n_nodes=n,激活函数=softplus)( encoderLayer)
6: AE模型←Model(inputLayer,decoderLayer)
7: encoder模型←Model(inputLayer,encoderLayer)
8: R←[]
9: D←[]
10: for t = n1:n2: n3do
11:AE.compile(optimizer='adam', loss='mean_squared_error')
12: AE.optimizer.lr.assign(0.001)
13: AE.fit(X)
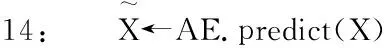
15:Xf←encoder. predict(X)
15: reconstructError←[]
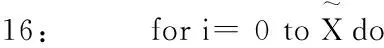
18: end for
21:end for
22: Return R, D
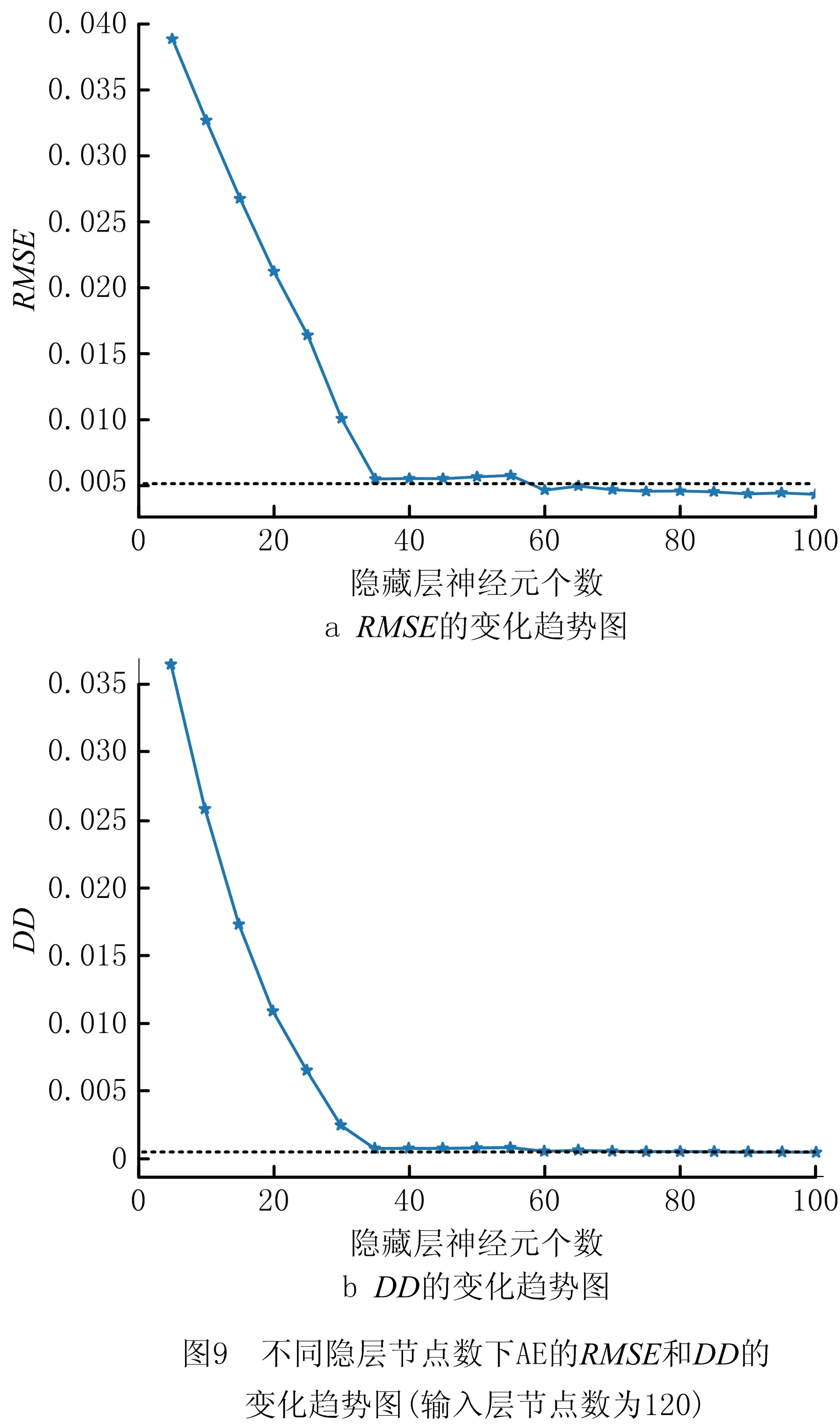
根据算法1得到的实验结果如表2所示,表中给出了由实验得到的不同隐层节点数下AE重构原始输入数据的DD(DD过小,将其乘以放大倍数104)和RMSE,图8是将表2中的数据用折线图表示。从图8中可以看出,当隐藏层节点数从10变化到30时,随着隐层节点数增加,DD和RMSE快速减小;当隐层节点数由30增加到120时,随着隐层节点数的增加,DD和RMSE缓慢减小;当隐藏层节点数大于120时,随着隐层节点数的增加,DD和RMSE在某个范围内呈震荡变化。由于本文采用的是真实的燃气轮机运行数据,实验结果存在一定的误差。当隐藏节点数为120,在误差允许的范围内,可以认为DD和RMSE均已不再变化。因此,本文将选取120作为DAE模型隐藏层的节点数。
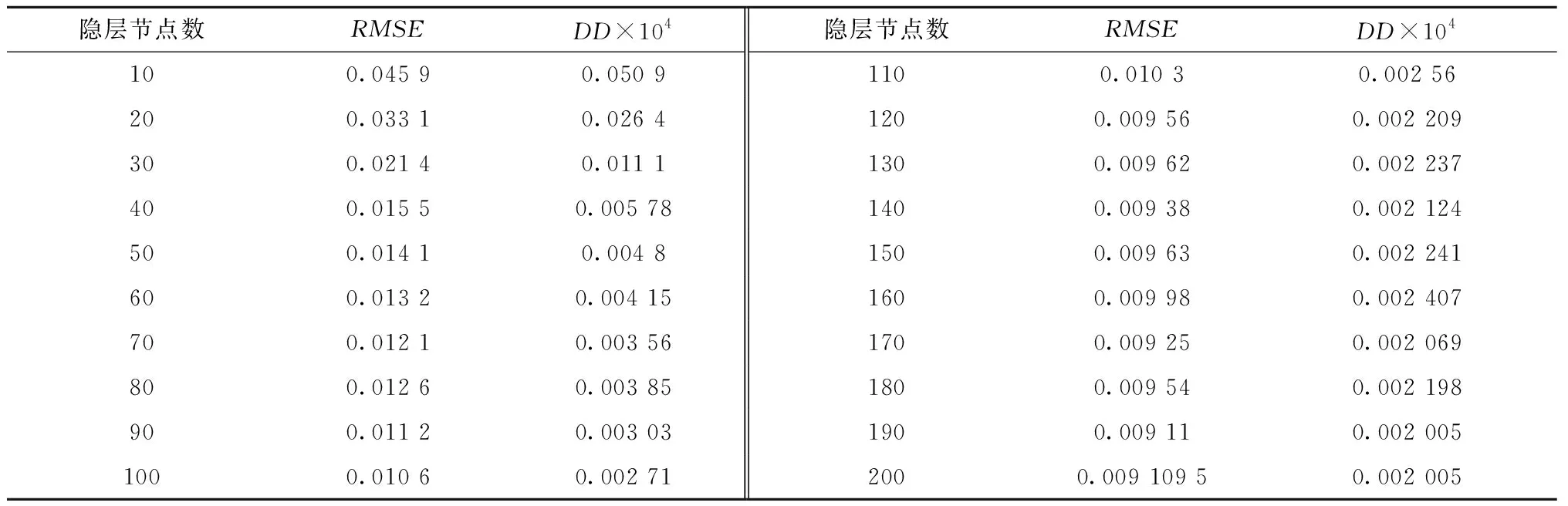
表2 不同隐藏层节点AE的RMSE和DD对比(输入层节点数为40)

3.2 DAE输出层节点数的确定
由图2可知,DAE的输出层就是最后一个AE的隐藏层。首先利用3.1节所确定的第一个AE模型(输入层节点数设为40,隐藏层节点数设为120)对原始数据集进行转化,转化后的数据集中每个样本的维数变为120,具体转化过程如算法1中的Xf所示。然后将另一个AE输入层设为120,选取该AE模型最优的隐藏层节点数,即为DAE模型的输出层节点数,训练该AE模型所使用的训练集为转化后的数据集。本实验将AE隐藏层节点数分别设为5、10、15、20、25、30、35、40、50、55、60、65、70、75、80、85、90、95和100,依次进行实验,其余相关参数设置与前文保持一致,算法流程如算法1所示。实验结果如表3和图9所示。
如图9所示,在初始阶段,DD和RMSE随着隐层节点数的增加而快速减小;而当隐藏层节点数增加到35后,DD和RMSE不再随着隐层节点数的增加而减小,而是在很小的范围内呈震荡变化。在误差允许的范围内,可以认为当隐藏层节点数到35以后,DD和RMSE不再发生变化。因此,当AE输入层节点数为120,隐藏层节点数设为35,AE的特征提取能力最好。因此,本文将DAE模型的输出层节点数设为35。
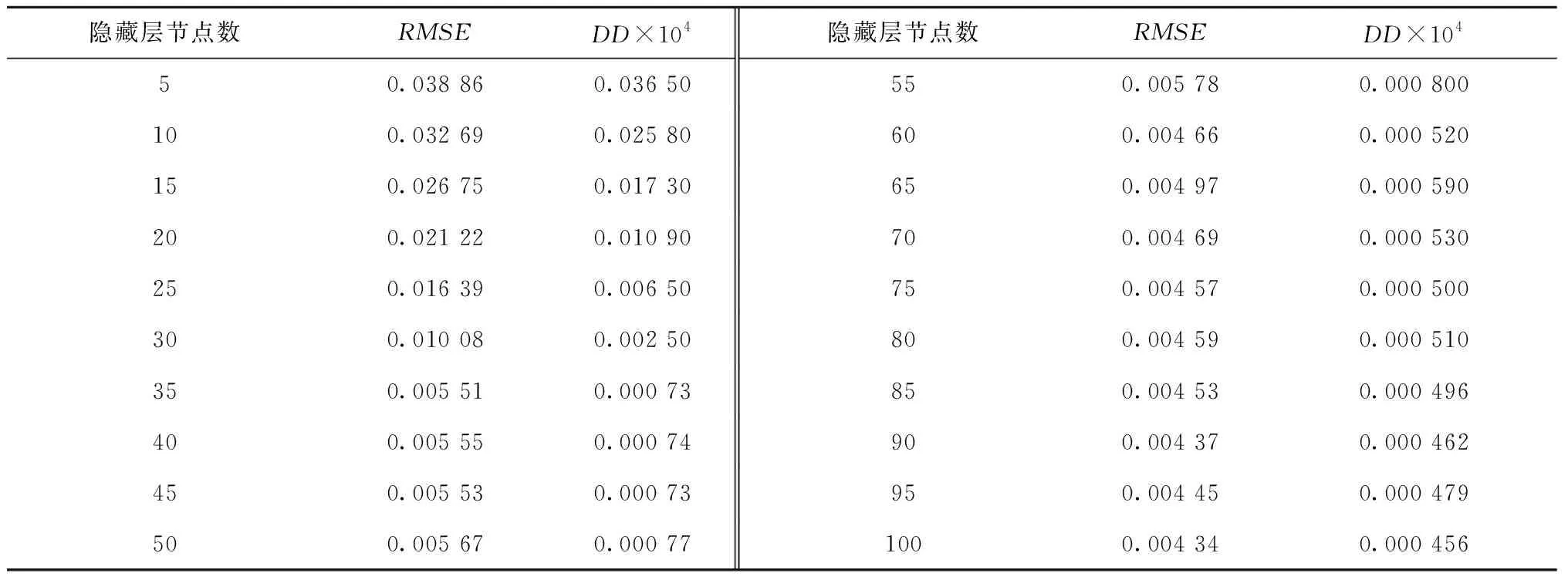
表3 不同输出节点数下AE的失真度和RSME(输入层节点数为120)
3.3 基于DAE迁移学习的发动机状态特征映射模型的合理性验证
本文基于DAE迁移学习建立发动机状态特征提取模型的目的是将发动机原始的状态特征映射到新的特征空间,以提高发动机状态数据的辨识度。由于发动机故障样本的缺乏,本文首先在源域中对DAE进行预训练,而后将预训练后的DAE模型迁移到故障识别任务中并保持不变,建立发动机状态特征提取模型。正常样本和故障样本都来自发动机的气路监测,它们之间具有一定的联系且具有一定相似性,因此,它们具有可迁移性。利用迁移学习建立的发动机状态特征提取模型的合理性,将通过以下实验进行验证。
(1) 同种故障类型样本间差异性减小验证
图10a和图10c描述了归一化后的正常样本和TAT指示故障样本(每类随机选取5个样本)。通过观察样本,可以发现原始样本存在大量的数据噪声,并且即使同型号发动机在发生同一类故障时,也存在较大的个体差异。将这些样本通过本文建立的状态特征提取模型映射到新的特征空间中,如图10b和图10d所示。通过对比,在特征空间中,同类样本基本都聚合在一起,样本的个体差异性和数据噪声得到了很好的消除。实验结果证明了将原始状态数据通过所建立的发动机状态特征提取模型映射到新的特征空间中,可以很好地消除发动机原始数据中存在的数据噪声和个体差异性。此外,本文所提出的状态特征提取模型还对原始样本进行了降维处理,有效降低了样本的复杂性。
(2) 不同故障类型样本间的差异性增大


尽管图10较好地描述了同种故障类型样本间的差异性,以及原始样本中存在的数据噪声在新的特征空间中得到了很好的消除,却没有明确地反映在新的特征空间中不同故障类型样本间的差异性是否得到增强。因此,本文随机选取了68组正常样本、30组EGT指示故障样本、22组TAT指示故障样本以及20组HTP叶片烧蚀故障样本,并利用本文所建立的发动机状态特征提取模型对其进行特征提取,然后对所得到的深度特征进行了分析,部分分析结果如图11所示。为了更好地可视化不同故障类型在新特征空间中的可分性,本文将不同维度上的特征进行组合,并通过三维视图进行展示。直观分析图11不难发现,结合第11维、26维和29维特征可以较好地分离出正常样本,而结合第22维、26维和29维特征可以很好地分离出TAT指示故障样本。实验结果证明,原始数据通过本文建立的发动机状态特征模型映射到新的特征空间中后,具有较高的辨识度。
综合上述实验结果表明,本文采用DAE迁移学习建立的发动机状态特征提取模型,将发动机原始状态数据映射到低维特征空间中,可以在消除数据噪声和个体差异性的同时,还具有较高的辨识度。因此,本文建立的发动机状态提取模型的合理性得以证明,同时上述实验结果也证明了本文所提出方法的可行性。
3.4 基于DAE与SVM的小样本故障诊断方法实验验证
通过上述实验可以确定DAE模型的隐藏层和输出层节点个数,而输入层节点个数由原始样本数据的维数确定。因此,本文DAE模型输入层节点个数为40,隐藏层节点个数为120,输出层节点个数为35,其他相关参数设置如下:学习率设为0.001,迭代次数设为200,节点激活函数使用softplus函数。待DAE所有参数设置完成后,首先利用随机选取的3 000组正常样本构成训练集对DAE模型进行训练,而后利用训练好的DAE模型对有所有故障样本组成的标记集进行特征提取,最后利用SVM对得到的特征进行分类测试,具体过程如算法2所示。此外,训练和测试SVM的样本分布如表4所示,支持向量机核函数选用多项式核。
算法2基于DAE迁移学习与SVM相结合的故障诊断。
2:输出:故障分类结果Acc和 Recall
3: 输入层inputLayer←(输入层神经元节点数n_nodes=40)
4: 隐藏层1(编码)encoderLayer1←Dense(神经元节点数n_nodes=120,激活函数=softplus)(inputLayer)
5: 隐藏层2(编码)encoderLayer2←Dense(神经元节点数n_nodes=35,激活函数=softplus)(encoderLayer1)
6: 重构层1(解码)decoderLayer1←Dense(神经元节点数n_nodes=120,激活函数=softplus)(encoderLayer2)
7: 重构层2(解码)decoderLayer2←Dense(神经元节点数n_nodes=40,激活函数=softplus)(decoderLayer1)
8:DAE模型←Model(inputLayer,decoderLayer2)
9: encoder模型←Model(inputLayer, encoderLayer2)
10: DAE.fit(Xtrain)
11:Xf←encoder. predict(Xtag)
12: XtrainSVM, XtestSVM←Xf
13: Ytrain_label←[zeros(200, 1), ones(20, 1), ones(10, 1)*2, ones(10, 1)*3]
14: Ytest_label←[zeros(68, 1), ones(10, 1), ones(10, 1)*2, ones(10, 1)*3]
15: SVM.fit(XtrainSVM, Ytrain_label)
16: Ypredict_label←SVM.predict(XtestSVM)
17: Acc←accuracy_score(Ytest_label,Ypredict_label)
18: Recall←recall_score(Ytest_label,Ypredict_label)
19: Return Acc, Recall
为了证明所提故障诊断方法的优越性,本文进行了7组对比实验。第1组对比实验使用SVM直接对原始标记集数据进行分类;第2组对比实验使用DAE和Softmax分类器组成的监督型深度神经网络(在DAE的输出层直接连接一个Softmax分类器)直接对原始数据进行分类;第3组到~6组对比实验中使用的方法与实验组相同,但随机组合了DAE的隐藏层和输出层神经元节点数;第7组实验是实验组,即:用本文提出的方法进行故障诊断。为了消除算法的随机性,每组实验重复10次,取10次实验的平均值作为最终的诊断结果,如表5所示。
由表5可以看出,上述7组实验在训练集上的训练精度都能达到100%,但是在测试集上的测试精度存在着明显的差异。第5组、第7组实验结果的测试精度最好,而第2组实验结果的测试精度最差。第2组实验完全不能检测出3种故障类型,这是因为故障样本数量太少,导致网络训练时出现了过拟合问题,再次证明了样本数量对监督型深度神经网络的重要性。其次,SVM方法的测试精度也较差,尤其是对HPT故障不能识别,这是因为原始序列样本中参数属性之间存在冗余以及存在大量的噪声,导致SVM分类效果较差。

表4 训练和测试SVM的特征集分布
对比表5中后5组实验的故障识别率,第5组、第7组实验对故障的识别能力明显优于第3、4、6组实验。后5组实验唯一的区别在于DAE的隐藏层和输出层节点数不同,在第3、4、5、6组实验中DAE的隐藏层和输出层节点数是随机组合,而在第7组实验中DAE模型的隐藏层和输出层节点数则是通过所提出的基于单个DAE特征提取能力进行确定的。虽然第5组和第7组实验结果均具有非常高的故障识别率,并且两组实验的测试结果非常接近,但是第5组中实验中DAE模型的输出层节点数是第7组实验中DAE模型的输出层节点数的两倍。显然,第5组实验中的DAE模型要比第7组实验中的DAE模型更加复杂。因此,综合比较而言,第7组实验中的DAE模型具有更优的性能。上述实验结果可以证明DAE的隐藏层和输出层节点数对最终所提取的特征有较大的影响,并且本文所提出的基于单个AE特征提取能力优化DAE隐藏层和输出层节点数的方法是有效的。
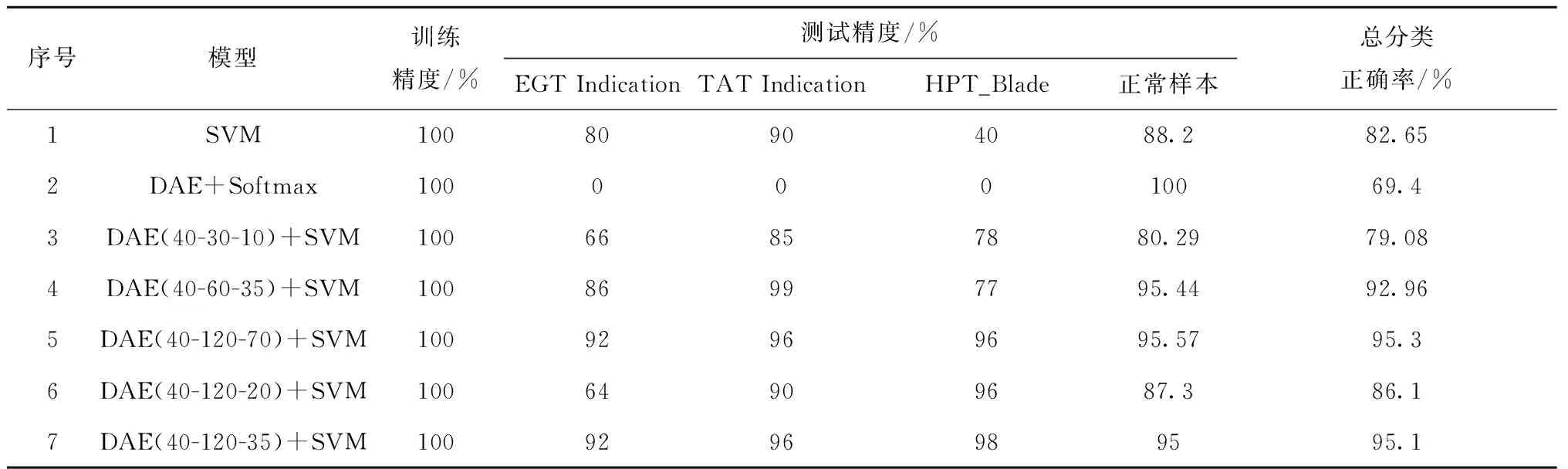
表5 不同模型的故障诊断结果比较
4 结束语
针对民航发动机气路故障诊断过程中的OEM数据噪声明显、故障样本不足的问题,本文提出一种基于DAE与SVM相结合的民航发动机小样本故障诊断方法,并通过某航空公司CFM56-7B系列机队的实际飞行数据对该方法进行了验证。实验证明,所提方法具有可靠的实用性,能对民航发动机气路故障进行较好的诊断。通过研究,还得出如下结论:
(1)尽管两个数据集存在一定的差异,本文基于DAE迁移学习方法建立的发动机状态特征提取模型,可以有效地提取故障样本的深度特征。
(2)提出的基于单个AE特征学习能力确定DAE隐藏层和输出层神经元个数的方法可以有效地对DAE隐藏层和输出层神经元个数进行优化,为优化DAE隐藏层和输出层神经元个数提供了新思路。
(3)对于本文提出的3种故障模式,当DAE模型的结构为40-120-35时,故障诊断的诊断效果最好。
未来计划收集更多故障类型,来更加全面地验证本文方法。除此以外,对本文方法进行改进,使其能应用在飞机通信寻址与报告系统(Aircraft Communications Addressing and Reporting System,ACARS)数据上也是本文未来的研究方向。与OEM数据相比,ACARS数据参数关系更加复杂,并且参数种类更多,这两个特点使其更适合于作为发动机故障诊断的数据源。基于ACARS数据对航空发动机进行故障诊断是一个具有挑战性的研究领域。
